 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCosyVoice 2: Scalable Streaming Speech Synthesis with Large Language Models
Dec 13, 2024



In our previous work, we introduced CosyVoice, a multilingual speech synthesis model based on supervised discrete speech tokens. By employing progressive semantic decoding with two popular generative models, language models (LMs) and Flow Matching, CosyVoice demonstrated high prosody naturalness, content consistency, and speaker similarity in speech in-context learning. Recently, significant progress has been made in multi-modal large language models (LLMs), where the response latency and real-time factor of speech synthesis play a crucial role in the interactive experience. Therefore, in this report, we present an improved streaming speech synthesis model, CosyVoice 2, which incorporates comprehensive and systematic optimizations. Specifically, we introduce finite-scalar quantization to improve the codebook utilization of speech tokens. For the text-speech LM, we streamline the model architecture to allow direct use of a pre-trained LLM as the backbone. In addition, we develop a chunk-aware causal flow matching model to support various synthesis scenarios, enabling both streaming and non-streaming synthesis within a single model. By training on a large-scale multilingual dataset, CosyVoice 2 achieves human-parity naturalness, minimal response latency, and virtually lossless synthesis quality in the streaming mode. We invite readers to listen to the demos at https://funaudiollm.github.io/cosyvoice2.
Anti-Forgetting Adaptation for Unsupervised Person Re-identification
Nov 22, 2024



Regular unsupervised domain adaptive person re-identification (ReID) focuses on adapting a model from a source domain to a fixed target domain. However, an adapted ReID model can hardly retain previously-acquired knowledge and generalize to unseen data. In this paper, we propose a Dual-level Joint Adaptation and Anti-forgetting (DJAA) framework, which incrementally adapts a model to new domains without forgetting source domain and each adapted target domain. We explore the possibility of using prototype and instance-level consistency to mitigate the forgetting during the adaptation. Specifically, we store a small number of representative image samples and corresponding cluster prototypes in a memory buffer, which is updated at each adaptation step. With the buffered images and prototypes, we regularize the image-to-image similarity and image-to-prototype similarity to rehearse old knowledge. After the multi-step adaptation, the model is tested on all seen domains and several unseen domains to validate the generalization ability of our method. Extensive experiments demonstrate that our proposed method significantly improves the anti-forgetting, generalization and backward-compatible ability of an unsupervised person ReID model.
CTC-Assisted LLM-Based Contextual ASR
Nov 10, 2024



Contextual ASR or hotword customization holds substantial practical value. Despite the impressive performance of current end-to-end (E2E) automatic speech recognition (ASR) systems, they often face challenges in accurately recognizing rare words. Typical E2E contextual ASR models commonly feature complex architectures and decoding mechanisms, limited in performance and susceptible to interference from distractor words. With large language model (LLM)-based ASR models emerging as the new mainstream, we propose a CTC-Assisted LLM-Based Contextual ASR model with an efficient filtering algorithm. By using coarse CTC decoding results to filter potential relevant hotwords and incorporating them into LLM prompt input, our model attains WER/B-WER of 1.27%/3.67% and 2.72%/8.02% on the Librispeech test-clean and test-other sets targeting on recognizing rare long-tail words, demonstrating significant improvements compared to the baseline LLM-based ASR model, and substantially surpassing other related work. More remarkably, with the help of the large language model and proposed filtering algorithm, our contextual ASR model still performs well with 2000 biasing words.
Enhancing Low-Resource ASR through Versatile TTS: Bridging the Data Gap
Oct 22, 2024



While automatic speech recognition (ASR) systems have achieved remarkable performance with large-scale datasets, their efficacy remains inadequate in low-resource settings, encompassing dialects, accents, minority languages, and long-tail hotwords, domains with significant practical relevance. With the advent of versatile and powerful text-to-speech (TTS) models, capable of generating speech with human-level naturalness, expressiveness, and diverse speaker profiles, leveraging TTS for ASR data augmentation provides a cost-effective and practical approach to enhancing ASR performance. Comprehensive experiments on an unprecedentedly rich variety of low-resource datasets demonstrate consistent and substantial performance improvements, proving that the proposed method of enhancing low-resource ASR through a versatile TTS model is highly effective and has broad application prospects. Furthermore, we delve deeper into key characteristics of synthesized speech data that contribute to ASR improvement, examining factors such as text diversity, speaker diversity, and the volume of synthesized data, with text diversity being studied for the first time in this work. We hope our findings provide helpful guidance and reference for the practical application of TTS-based data augmentation and push the advancement of low-resource ASR one step further.
Long-distance Geomagnetic Navigation in GNSS-denied Environments with Deep Reinforcement Learning
Oct 21, 2024



Geomagnetic navigation has drawn increasing attention with its capacity in navigating through complex environments and its independence from external navigation services like global navigation satellite systems (GNSS). Existing studies on geomagnetic navigation, i.e., matching navigation and bionic navigation, rely on pre-stored map or extensive searches, leading to limited applicability or reduced navigation efficiency in unexplored areas. To address the issues with geomagnetic navigation in areas where GNSS is unavailable, this paper develops a deep reinforcement learning (DRL)-based mechanism, especially for long-distance geomagnetic navigation. The designed mechanism trains an agent to learn and gain the magnetoreception capacity for geomagnetic navigation, rather than using any pre-stored map or extensive and expensive searching approaches. Particularly, we integrate the geomagnetic gradient-based parallel approach into geomagnetic navigation. This integration mitigates the over-exploration of the learning agent by adjusting the geomagnetic gradient, such that the obtained gradient is aligned towards the destination. We explore the effectiveness of the proposed approach via detailed numerical simulations, where we implement twin delayed deep deterministic policy gradient (TD3) in realizing the proposed approach. The results demonstrate that our approach outperforms existing metaheuristic and bionic navigation methods in long-distance missions under diverse navigation conditions.
Are Transformers in Pre-trained LM A Good ASR Encoder? An Empirical Study
Sep 26, 2024



In this study, we delve into the efficacy of transformers within pre-trained language models (PLMs) when repurposed as encoders for Automatic Speech Recognition (ASR). Our underlying hypothesis posits that, despite being initially trained on text-based corpora, these transformers possess a remarkable capacity to extract effective features from the input sequence. This inherent capability, we argue, is transferrable to speech data, thereby augmenting the acoustic modeling ability of ASR. Through rigorous empirical analysis, our findings reveal a notable improvement in Character Error Rate (CER) and Word Error Rate (WER) across diverse ASR tasks when transformers from pre-trained LMs are incorporated. Particularly, they serve as an advantageous starting point for initializing ASR encoders. Furthermore, we uncover that these transformers, when integrated into a well-established ASR encoder, can significantly boost performance, especially in scenarios where profound semantic comprehension is pivotal. This underscores the potential of leveraging the semantic prowess embedded within pre-trained transformers to advance ASR systems' capabilities.
Paraformer-v2: An improved non-autoregressive transformer for noise-robust speech recognition
Sep 26, 2024Attention-based encoder-decoder, e.g. transformer and its variants, generates the output sequence in an autoregressive (AR) manner. Despite its superior performance, AR model is computationally inefficient as its generation requires as many iterations as the output length. In this paper, we propose Paraformer-v2, an improved version of Paraformer, for fast, accurate, and noise-robust non-autoregressive speech recognition. In Paraformer-v2, we use a CTC module to extract the token embeddings, as the alternative to the continuous integrate-and-fire module in Paraformer. Extensive experiments demonstrate that Paraformer-v2 outperforms Paraformer on multiple datasets, especially on the English datasets (over 14% improvement on WER), and is more robust in noisy environments.
Exploring SSL Discrete Speech Features for Zipformer-based Contextual ASR
Sep 13, 2024



Self-supervised learning (SSL) based discrete speech representations are highly compact and domain adaptable. In this paper, SSL discrete speech features extracted from WavLM models are used as additional cross-utterance acoustic context features in Zipformer-Transducer ASR systems. The efficacy of replacing Fbank features with discrete token features for modelling either cross-utterance contexts (from preceding and future segments), or current utterance's internal contexts alone, or both at the same time, are demonstrated thoroughly on the Gigaspeech 1000-hr corpus. The best Zipformer-Transducer system using discrete tokens based cross-utterance context features outperforms the baseline using utterance internal context only with statistically significant word error rate (WER) reductions of 0.32% to 0.41% absolute (2.78% to 3.54% relative) on the dev and test data. The lowest published WER of 11.15% and 11.14% were obtained on the dev and test sets. Our work is open-source and publicly available at https://github.com/open-creator/icefall/tree/master/egs/gigaspeech/Context\_ASR.
Dataset Distillation for Histopathology Image Classification
Aug 19, 2024Deep neural networks (DNNs) have exhibited remarkable success in the field of histopathology image analysis. On the other hand, the contemporary trend of employing large models and extensive datasets has underscored the significance of dataset distillation, which involves compressing large-scale datasets into a condensed set of synthetic samples, offering distinct advantages in improving training efficiency and streamlining downstream applications. In this work, we introduce a novel dataset distillation algorithm tailored for histopathology image datasets (Histo-DD), which integrates stain normalisation and model augmentation into the distillation progress. Such integration can substantially enhance the compatibility with histopathology images that are often characterised by high colour heterogeneity. We conduct a comprehensive evaluation of the effectiveness of the proposed algorithm and the generated histopathology samples in both patch-level and slide-level classification tasks. The experimental results, carried out on three publicly available WSI datasets, including Camelyon16, TCGA-IDH, and UniToPath, demonstrate that the proposed Histo-DD can generate more informative synthetic patches than previous coreset selection and patch sampling methods. Moreover, the synthetic samples can preserve discriminative information, substantially reduce training efforts, and exhibit architecture-agnostic properties. These advantages indicate that synthetic samples can serve as an alternative to large-scale datasets.
CosyVoice: A Scalable Multilingual Zero-shot Text-to-speech Synthesizer based on Supervised Semantic Tokens
Jul 09, 2024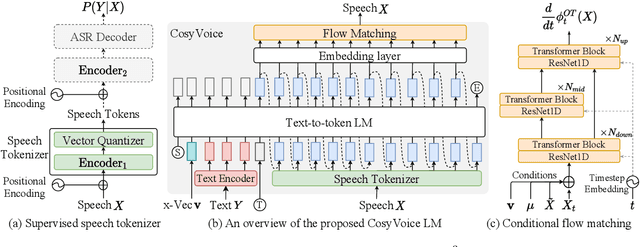

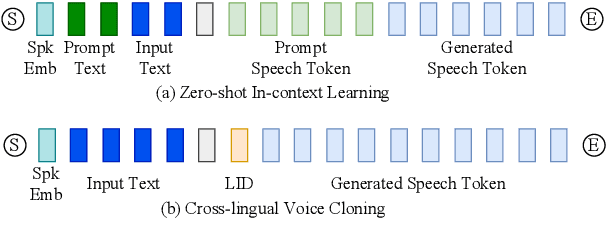
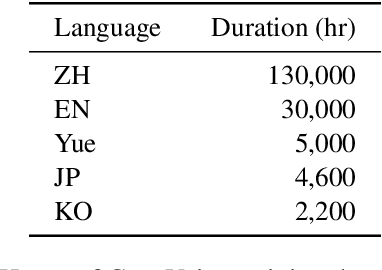
Recent years have witnessed a trend that large language model (LLM) based text-to-speech (TTS) emerges into the mainstream due to their high naturalness and zero-shot capacity. In this paradigm, speech signals are discretized into token sequences, which are modeled by an LLM with text as prompts and reconstructed by a token-based vocoder to waveforms. Obviously, speech tokens play a critical role in LLM-based TTS models. Current speech tokens are learned in an unsupervised manner, which lacks explicit semantic information and alignment to the text. In this paper, we propose to represent speech with supervised semantic tokens, which are derived from a multilingual speech recognition model by inserting vector quantization into the encoder. Based on the tokens, we further propose a scalable zero-shot TTS synthesizer, CosyVoice, which consists of an LLM for text-to-token generation and a conditional flow matching model for token-to-speech synthesis. Experimental results show that supervised semantic tokens significantly outperform existing unsupervised tokens in terms of content consistency and speaker similarity for zero-shot voice cloning. Moreover, we find that utilizing large-scale data further improves the synthesis performance, indicating the scalable capacity of CosyVoice. To the best of our knowledge, this is the first attempt to involve supervised speech tokens into TTS models.