 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeV-STC: A Time-Efficient Multi-Vehicle Coordinated Trajectory Planning Approach
Apr 24, 2026Coordinating the motions of multiple autonomous vehicles (AVs) requires planning frameworks that ensure safety while making efficient use of space and time. This paper presents a new approach, termed variable-time-step spatio-temporal corridor (V-STC), that enhances the temporal efficiency of multi-vehicle coordination. An optimization model is formulated to construct a V-STC for each AV, in which both the spatial configuration of the corridor cubes and their time durations are treated as decision variables. By allowing the corridor's spatial position and time step to vary, the constructed V-STC reduces the overall temporal occupancy of each AV while maintaining collision-free separation in the spatio-temporal domain. Based on the generated V-STC, a dynamically feasible trajectory is then planned independently for each AV. Simulation studies demonstrate that the proposed method achieves safe multi-vehicle coordination and yields more time-efficient motion compared with existing STC approaches.
MO-MIX: Multi-Objective Multi-Agent Cooperative Decision-Making With Deep Reinforcement Learning
Feb 28, 2026Deep reinforcement learning (RL) has been applied extensively to solve complex decision-making problems. In many real-world scenarios, tasks often have several conflicting objectives and may require multiple agents to cooperate, which are the multi-objective multi-agent decision-making problems. However, only few works have been conducted on this intersection. Existing approaches are limited to separate fields and can only handle multi-agent decision-making with a single objective, or multi-objective decision-making with a single agent. In this paper, we propose MO-MIX to solve the multi-objective multi-agent reinforcement learning (MOMARL) problem. Our approach is based on the centralized training with decentralized execution (CTDE) framework. A weight vector representing preference over the objectives is fed into the decentralized agent network as a condition for local action-value function estimation, while a mixing network with parallel architecture is used to estimate the joint action-value function. In addition, an exploration guide approach is applied to improve the uniformity of the final non-dominated solutions. Experiments demonstrate that the proposed method can effectively solve the multi-objective multi-agent cooperative decision-making problem and generate an approximation of the Pareto set. Our approach not only significantly outperforms the baseline method in all four kinds of evaluation metrics, but also requires less computational cost.
* 15 pages, 10 figures, published in IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI)
Multi-Dimensional Visual Data Recovery: Scale-Aware Tensor Modeling and Accelerated Randomized Computation
Feb 13, 2026The recently proposed fully-connected tensor network (FCTN) decomposition has demonstrated significant advantages in correlation characterization and transpositional invariance, and has achieved notable achievements in multi-dimensional data processing and analysis. However, existing multi-dimensional data recovery methods leveraging FCTN decomposition still have room for further enhancement, particularly in computational efficiency and modeling capability. To address these issues, we first propose a FCTN-based generalized nonconvex regularization paradigm from the perspective of gradient mapping. Then, reliable and scalable multi-dimensional data recovery models are investigated, where the model formulation is shifted from unquantized observations to coarse-grained quantized observations. Based on the alternating direction method of multipliers (ADMM) framework, we derive efficient optimization algorithms with convergence guarantees to solve the formulated models. To alleviate the computational bottleneck encountered when processing large-scale multi-dimensional data, fast and efficient randomized compression algorithms are devised in virtue of sketching techniques in numerical linear algebra. These dimensionality-reduction techniques serve as the computational acceleration core of our proposed algorithm framework. Theoretical results on approximation error upper bounds and convergence analysis for the proposed method are derived. Extensive numerical experiments illustrate the effectiveness and superiority of the proposed algorithm over other state-of-the-art methods in terms of quantitative metrics, visual quality, and running time.
IGDNet: Zero-Shot Robust Underexposed Image Enhancement via Illumination-Guided and Denoising
Jul 03, 2025Current methods for restoring underexposed images typically rely on supervised learning with paired underexposed and well-illuminated images. However, collecting such datasets is often impractical in real-world scenarios. Moreover, these methods can lead to over-enhancement, distorting well-illuminated regions. To address these issues, we propose IGDNet, a Zero-Shot enhancement method that operates solely on a single test image, without requiring guiding priors or training data. IGDNet exhibits strong generalization ability and effectively suppresses noise while restoring illumination. The framework comprises a decomposition module and a denoising module. The former separates the image into illumination and reflection components via a dense connection network, while the latter enhances non-uniformly illuminated regions using an illumination-guided pixel adaptive correction method. A noise pair is generated through downsampling and refined iteratively to produce the final result. Extensive experiments on four public datasets demonstrate that IGDNet significantly improves visual quality under complex lighting conditions. Quantitative results on metrics like PSNR (20.41dB) and SSIM (0.860dB) show that it outperforms 14 state-of-the-art unsupervised methods. The code will be released soon.
SpikeSMOKE: Spiking Neural Networks for Monocular 3D Object Detection with Cross-Scale Gated Coding
Jun 09, 2025Low energy consumption for 3D object detection is an important research area because of the increasing energy consumption with their wide application in fields such as autonomous driving. The spiking neural networks (SNNs) with low-power consumption characteristics can provide a novel solution for this research. Therefore, we apply SNNs to monocular 3D object detection and propose the SpikeSMOKE architecture in this paper, which is a new attempt for low-power monocular 3D object detection. As we all know, discrete signals of SNNs will generate information loss and limit their feature expression ability compared with the artificial neural networks (ANNs).In order to address this issue, inspired by the filtering mechanism of biological neuronal synapses, we propose a cross-scale gated coding mechanism(CSGC), which can enhance feature representation by combining cross-scale fusion of attentional methods and gated filtering mechanisms.In addition, to reduce the computation and increase the speed of training, we present a novel light-weight residual block that can maintain spiking computing paradigm and the highest possible detection performance. Compared to the baseline SpikeSMOKE under the 3D Object Detection, the proposed SpikeSMOKE with CSGC can achieve 11.78 (+2.82, Easy), 10.69 (+3.2, Moderate), and 10.48 (+3.17, Hard) on the KITTI autonomous driving dataset by AP|R11 at 0.7 IoU threshold, respectively. It is important to note that the results of SpikeSMOKE can significantly reduce energy consumption compared to the results on SMOKE. For example,the energy consumption can be reduced by 72.2% on the hard category, while the detection performance is reduced by only 4%. SpikeSMOKE-L (lightweight) can further reduce the amount of parameters by 3 times and computation by 10 times compared to SMOKE.
Exploring the Generalizability of Geomagnetic Navigation: A Deep Reinforcement Learning approach with Policy Distillation
Feb 07, 2025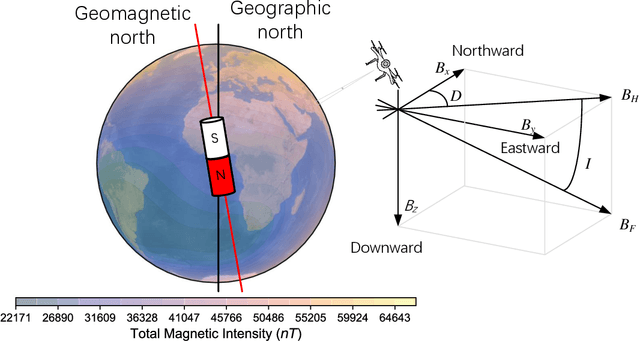
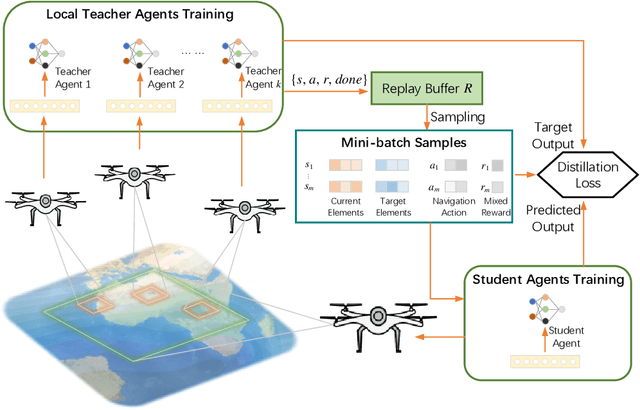
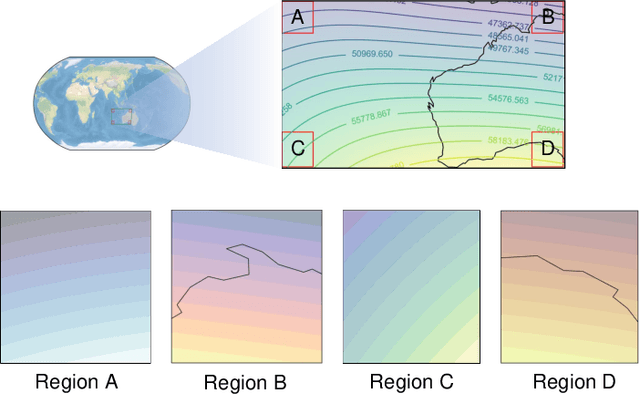
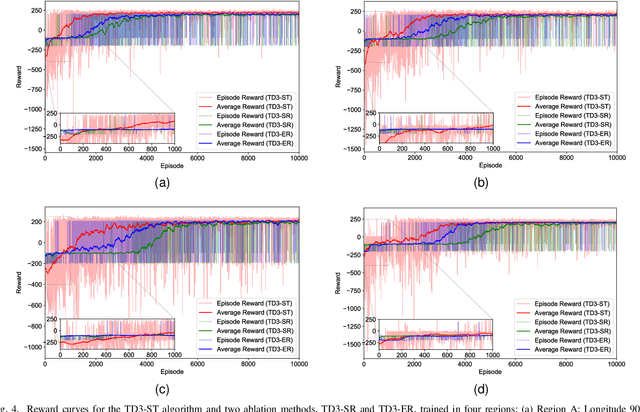
The advancement in autonomous vehicles has empowered navigation and exploration in unknown environments. Geomagnetic navigation for autonomous vehicles has drawn increasing attention with its independence from GPS or inertial navigation devices. While geomagnetic navigation approaches have been extensively investigated, the generalizability of learned geomagnetic navigation strategies remains unexplored. The performance of a learned strategy can degrade outside of its source domain where the strategy is learned, due to a lack of knowledge about the geomagnetic characteristics in newly entered areas. This paper explores the generalization of learned geomagnetic navigation strategies via deep reinforcement learning (DRL). Particularly, we employ DRL agents to learn multiple teacher models from distributed domains that represent dispersed navigation strategies, and amalgamate the teacher models for generalizability across navigation areas. We design a reward shaping mechanism in training teacher models where we integrate both potential-based and intrinsic-motivated rewards. The designed reward shaping can enhance the exploration efficiency of the DRL agent and improve the representation of the teacher models. Upon the gained teacher models, we employ multi-teacher policy distillation to merge the policies learned by individual teachers, leading to a navigation strategy with generalizability across navigation domains. We conduct numerical simulations, and the results demonstrate an effective transfer of the learned DRL model from a source domain to new navigation areas. Compared to existing evolutionary-based geomagnetic navigation methods, our approach provides superior performance in terms of navigation length, duration, heading deviation, and success rate in cross-domain navigation.
Temporal Information Reconstruction and Non-Aligned Residual in Spiking Neural Networks for Speech Classification
Dec 31, 2024



Recently, it can be noticed that most models based on spiking neural networks (SNNs) only use a same level temporal resolution to deal with speech classification problems, which makes these models cannot learn the information of input data at different temporal scales. Additionally, owing to the different time lengths of the data before and after the sub-modules of many models, the effective residual connections cannot be applied to optimize the training processes of these models.To solve these problems, on the one hand, we reconstruct the temporal dimension of the audio spectrum to propose a novel method named as Temporal Reconstruction (TR) by referring the hierarchical processing process of the human brain for understanding speech. Then, the reconstructed SNN model with TR can learn the information of input data at different temporal scales and model more comprehensive semantic information from audio data because it enables the networks to learn the information of input data at different temporal resolutions. On the other hand, we propose the Non-Aligned Residual (NAR) method by analyzing the audio data, which allows the residual connection can be used in two audio data with different time lengths. We have conducted plentiful experiments on the Spiking Speech Commands (SSC), the Spiking Heidelberg Digits (SHD), and the Google Speech Commands v0.02 (GSC) datasets. According to the experiment results, we have achieved the state-of-the-art (SOTA) result 81.02\% on SSC for the test classification accuracy of all SNN models, and we have obtained the SOTA result 96.04\% on SHD for the classification accuracy of all models.
Long-distance Geomagnetic Navigation in GNSS-denied Environments with Deep Reinforcement Learning
Oct 21, 2024



Geomagnetic navigation has drawn increasing attention with its capacity in navigating through complex environments and its independence from external navigation services like global navigation satellite systems (GNSS). Existing studies on geomagnetic navigation, i.e., matching navigation and bionic navigation, rely on pre-stored map or extensive searches, leading to limited applicability or reduced navigation efficiency in unexplored areas. To address the issues with geomagnetic navigation in areas where GNSS is unavailable, this paper develops a deep reinforcement learning (DRL)-based mechanism, especially for long-distance geomagnetic navigation. The designed mechanism trains an agent to learn and gain the magnetoreception capacity for geomagnetic navigation, rather than using any pre-stored map or extensive and expensive searching approaches. Particularly, we integrate the geomagnetic gradient-based parallel approach into geomagnetic navigation. This integration mitigates the over-exploration of the learning agent by adjusting the geomagnetic gradient, such that the obtained gradient is aligned towards the destination. We explore the effectiveness of the proposed approach via detailed numerical simulations, where we implement twin delayed deep deterministic policy gradient (TD3) in realizing the proposed approach. The results demonstrate that our approach outperforms existing metaheuristic and bionic navigation methods in long-distance missions under diverse navigation conditions.
Decentralized Multi-agent Reinforcement Learning based State-of-Charge Balancing Strategy for Distributed Energy Storage System
Aug 29, 2023



This paper develops a Decentralized Multi-Agent Reinforcement Learning (Dec-MARL) method to solve the SoC balancing problem in the distributed energy storage system (DESS). First, the SoC balancing problem is formulated into a finite Markov decision process with action constraints derived from demand balance, which can be solved by Dec-MARL. Specifically, the first-order average consensus algorithm is utilized to expand the observations of the DESS state in a fully-decentralized way, and the initial actions (i.e., output power) are decided by the agents (i.e., energy storage units) according to these observations. In order to get the final actions in the allowable range, a counterfactual demand balance algorithm is proposed to balance the total demand and the initial actions. Next, the agents execute the final actions and get local rewards from the environment, and the DESS steps into the next state. Finally, through the first-order average consensus algorithm, the agents get the average reward and the expended observation of the next state for later training. By the above procedure, Dec-MARL reveals outstanding performance in a fully-decentralized system without any expert experience or constructing any complicated model. Besides, it is flexible and can be extended to other decentralized multi-agent systems straightforwardly. Extensive simulations have validated the effectiveness and efficiency of Dec-MARL.
Model-Assisted Probabilistic Safe Adaptive Control With Meta-Bayesian Learning
Jul 13, 2023



Breaking safety constraints in control systems can lead to potential risks, resulting in unexpected costs or catastrophic damage. Nevertheless, uncertainty is ubiquitous, even among similar tasks. In this paper, we develop a novel adaptive safe control framework that integrates meta learning, Bayesian models, and control barrier function (CBF) method. Specifically, with the help of CBF method, we learn the inherent and external uncertainties by a unified adaptive Bayesian linear regression (ABLR) model, which consists of a forward neural network (NN) and a Bayesian output layer. Meta learning techniques are leveraged to pre-train the NN weights and priors of the ABLR model using data collected from historical similar tasks. For a new control task, we refine the meta-learned models using a few samples, and introduce pessimistic confidence bounds into CBF constraints to ensure safe control. Moreover, we provide theoretical criteria to guarantee probabilistic safety during the control processes. To validate our approach, we conduct comparative experiments in various obstacle avoidance scenarios. The results demonstrate that our algorithm significantly improves the Bayesian model-based CBF method, and is capable for efficient safe exploration even with multiple uncertain constraints.