 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat, when, and where? -- Self-Supervised Spatio-Temporal Grounding in Untrimmed Multi-Action Videos from Narrated Instructions
Mar 29, 2023Spatio-temporal grounding describes the task of localizing events in space and time, e.g., in video data, based on verbal descriptions only. Models for this task are usually trained with human-annotated sentences and bounding box supervision. This work addresses this task from a multimodal supervision perspective, proposing a framework for spatio-temporal action grounding trained on loose video and subtitle supervision only, without human annotation. To this end, we combine local representation learning, which focuses on leveraging fine-grained spatial information, with a global representation encoding that captures higher-level representations and incorporates both in a joint approach. To evaluate this challenging task in a real-life setting, a new benchmark dataset is proposed providing dense spatio-temporal grounding annotations in long, untrimmed, multi-action instructional videos for over 5K events. We evaluate the proposed approach and other methods on the proposed and standard downstream tasks showing that our method improves over current baselines in various settings, including spatial, temporal, and untrimmed multi-action spatio-temporal grounding.
DiGeo: Discriminative Geometry-Aware Learning for Generalized Few-Shot Object Detection
Mar 16, 2023



Generalized few-shot object detection aims to achieve precise detection on both base classes with abundant annotations and novel classes with limited training data. Existing approaches enhance few-shot generalization with the sacrifice of base-class performance, or maintain high precision in base-class detection with limited improvement in novel-class adaptation. In this paper, we point out the reason is insufficient Discriminative feature learning for all of the classes. As such, we propose a new training framework, DiGeo, to learn Geometry-aware features of inter-class separation and intra-class compactness. To guide the separation of feature clusters, we derive an offline simplex equiangular tight frame (ETF) classifier whose weights serve as class centers and are maximally and equally separated. To tighten the cluster for each class, we include adaptive class-specific margins into the classification loss and encourage the features close to the class centers. Experimental studies on two few-shot benchmark datasets (VOC, COCO) and one long-tail dataset (LVIS) demonstrate that, with a single model, our method can effectively improve generalization on novel classes without hurting the detection of base classes.
In Defense of Structural Symbolic Representation for Video Event-Relation Prediction
Jan 06, 2023Understanding event relationships in videos requires a model to understand the underlying structures of events, i.e., the event type, the associated argument roles, and corresponding entities) along with factual knowledge needed for reasoning. Structural symbolic representation (SSR) based methods directly take event types and associated argument roles/entities as inputs to perform reasoning. However, the state-of-the-art video event-relation prediction system shows the necessity of using continuous feature vectors from input videos; existing methods based solely on SSR inputs fail completely, event when given oracle event types and argument roles. In this paper, we conduct an extensive empirical analysis to answer the following questions: 1) why SSR-based method failed; 2) how to understand the evaluation setting of video event relation prediction properly; 3) how to uncover the potential of SSR-based methods. We first identify the failure of previous SSR-based video event prediction models to be caused by sub-optimal training settings. Surprisingly, we find that a simple SSR-based model with tuned hyperparameters can actually yield a 20\% absolute improvement in macro-accuracy over the state-of-the-art model. Then through qualitative and quantitative analysis, we show how evaluation that takes only video as inputs is currently unfeasible, and the reliance on oracle event information to obtain an accurate evaluation. Based on these findings, we propose to further contextualize the SSR-based model to an Event-Sequence Model and equip it with more factual knowledge through a simple yet effective way of reformulating external visual commonsense knowledge bases into an event-relation prediction pretraining dataset. The resultant new state-of-the-art model eventually establishes a 25\% Macro-accuracy performance boost.
TempCLR: Temporal Alignment Representation with Contrastive Learning
Dec 28, 2022Video representation learning has been successful in video-text pre-training for zero-shot transfer, where each sentence is trained to be close to the paired video clips in a common feature space. For long videos, given a paragraph of description where the sentences describe different segments of the video, by matching all sentence-clip pairs, the paragraph and the full video are aligned implicitly. However, such unit-level similarity measure may ignore the global temporal context over a long time span, which inevitably limits the generalization ability. In this paper, we propose a contrastive learning framework TempCLR to compare the full video and the paragraph explicitly. As the video/paragraph is formulated as a sequence of clips/sentences, under the constraint of their temporal order, we use dynamic time warping to compute the minimum cumulative cost over sentence-clip pairs as the sequence-level distance. To explore the temporal dynamics, we break the consistency of temporal order by shuffling the video clips or sentences according to the temporal granularity. In this way, we obtain the representations for clips/sentences, which perceive the temporal information and thus facilitate the sequence alignment. In addition to pre-training on the video and paragraph, our approach can also generalize on the matching between different video instances. We evaluate our approach on video retrieval, action step localization, and few-shot action recognition, and achieve consistent performance gain over all three tasks. Detailed ablation studies are provided to justify the approach design.
Find Someone Who: Visual Commonsense Understanding in Human-Centric Grounding
Dec 14, 2022



From a visual scene containing multiple people, human is able to distinguish each individual given the context descriptions about what happened before, their mental/physical states or intentions, etc. Above ability heavily relies on human-centric commonsense knowledge and reasoning. For example, if asked to identify the "person who needs healing" in an image, we need to first know that they usually have injuries or suffering expressions, then find the corresponding visual clues before finally grounding the person. We present a new commonsense task, Human-centric Commonsense Grounding, that tests the models' ability to ground individuals given the context descriptions about what happened before, and their mental/physical states or intentions. We further create a benchmark, HumanCog, a dataset with 130k grounded commonsensical descriptions annotated on 67k images, covering diverse types of commonsense and visual scenes. We set up a context-object-aware method as a strong baseline that outperforms previous pre-trained and non-pretrained models. Further analysis demonstrates that rich visual commonsense and powerful integration of multi-modal commonsense are essential, which sheds light on future works. Data and code will be available https://github.com/Hxyou/HumanCog.
Understanding ME? Multimodal Evaluation for Fine-grained Visual Commonsense
Nov 10, 2022



Visual commonsense understanding requires Vision Language (VL) models to not only understand image and text but also cross-reference in-between to fully integrate and achieve comprehension of the visual scene described. Recently, various approaches have been developed and have achieved high performance on visual commonsense benchmarks. However, it is unclear whether the models really understand the visual scene and underlying commonsense knowledge due to limited evaluation data resources. To provide an in-depth analysis, we present a Multimodal Evaluation (ME) pipeline to automatically generate question-answer pairs to test models' understanding of the visual scene, text, and related knowledge. We then take a step further to show that training with the ME data boosts the model's performance in standard VCR evaluation. Lastly, our in-depth analysis and comparison reveal interesting findings: (1) semantically low-level information can assist the learning of high-level information but not the opposite; (2) visual information is generally under utilization compared with text.
Video Event Extraction via Tracking Visual States of Arguments
Nov 05, 2022Video event extraction aims to detect salient events from a video and identify the arguments for each event as well as their semantic roles. Existing methods focus on capturing the overall visual scene of each frame, ignoring fine-grained argument-level information. Inspired by the definition of events as changes of states, we propose a novel framework to detect video events by tracking the changes in the visual states of all involved arguments, which are expected to provide the most informative evidence for the extraction of video events. In order to capture the visual state changes of arguments, we decompose them into changes in pixels within objects, displacements of objects, and interactions among multiple arguments. We further propose Object State Embedding, Object Motion-aware Embedding and Argument Interaction Embedding to encode and track these changes respectively. Experiments on various video event extraction tasks demonstrate significant improvements compared to state-of-the-art models. In particular, on verb classification, we achieve 3.49% absolute gains (19.53% relative gains) in F1@5 on Video Situation Recognition.
Video in 10 Bits: Few-Bit VideoQA for Efficiency and Privacy
Oct 18, 2022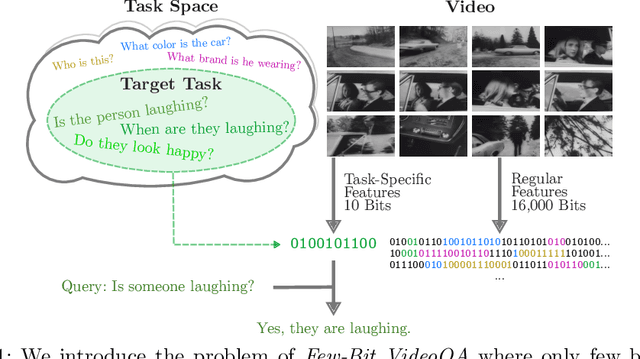

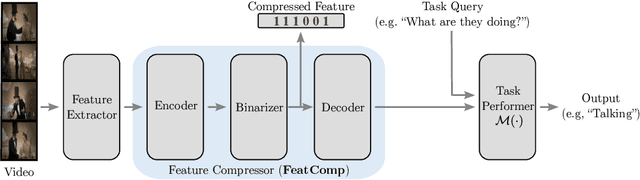
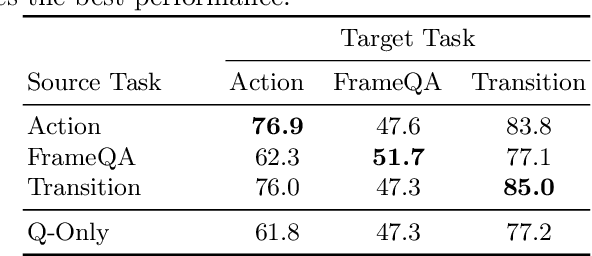
In Video Question Answering (VideoQA), answering general questions about a video requires its visual information. Yet, video often contains redundant information irrelevant to the VideoQA task. For example, if the task is only to answer questions similar to "Is someone laughing in the video?", then all other information can be discarded. This paper investigates how many bits are really needed from the video in order to do VideoQA by introducing a novel Few-Bit VideoQA problem, where the goal is to accomplish VideoQA with few bits of video information (e.g., 10 bits). We propose a simple yet effective task-specific feature compression approach to solve this problem. Specifically, we insert a lightweight Feature Compression Module (FeatComp) into a VideoQA model which learns to extract task-specific tiny features as little as 10 bits, which are optimal for answering certain types of questions. We demonstrate more than 100,000-fold storage efficiency over MPEG4-encoded videos and 1,000-fold over regular floating point features, with just 2.0-6.6% absolute loss in accuracy, which is a surprising and novel finding. Finally, we analyze what the learned tiny features capture and demonstrate that they have eliminated most of the non-task-specific information, and introduce a Bit Activation Map to visualize what information is being stored. This decreases the privacy risk of data by providing k-anonymity and robustness to feature-inversion techniques, which can influence the machine learning community, allowing us to store data with privacy guarantees while still performing the task effectively.
Learning Visual Representation from Modality-Shared Contrastive Language-Image Pre-training
Jul 26, 2022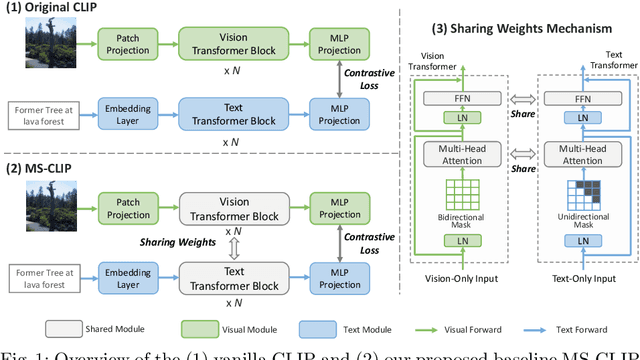
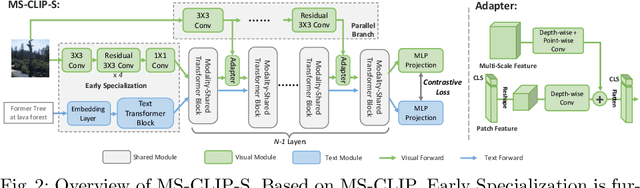
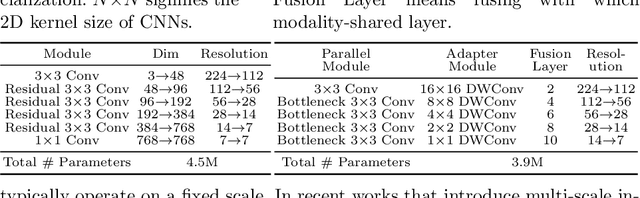
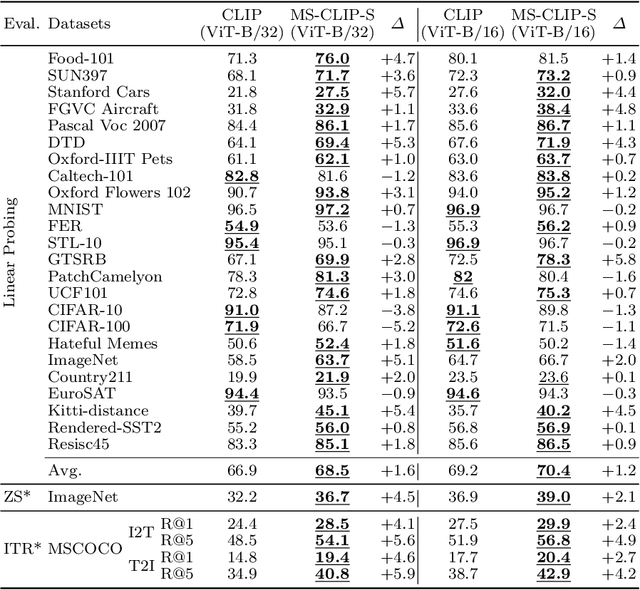
Large-scale multi-modal contrastive pre-training has demonstrated great utility to learn transferable features for a range of downstream tasks by mapping multiple modalities into a shared embedding space. Typically, this has employed separate encoders for each modality. However, recent work suggests that transformers can support learning across multiple modalities and allow knowledge sharing. Inspired by this, we investigate a variety of Modality-Shared Contrastive Language-Image Pre-training (MS-CLIP) frameworks. More specifically, we question how many parameters of a transformer model can be shared across modalities during contrastive pre-training, and rigorously examine architectural design choices that position the proportion of parameters shared along a spectrum. In studied conditions, we observe that a mostly unified encoder for vision and language signals outperforms all other variations that separate more parameters. Additionally, we find that light-weight modality-specific parallel modules further improve performance. Experimental results show that the proposed MS-CLIP approach outperforms vanilla CLIP by up to 13\% relative in zero-shot ImageNet classification (pre-trained on YFCC-100M), while simultaneously supporting a reduction of parameters. In addition, our approach outperforms vanilla CLIP by 1.6 points in linear probing on a collection of 24 downstream vision tasks. Furthermore, we discover that sharing parameters leads to semantic concepts from different modalities being encoded more closely in the embedding space, facilitating the transferring of common semantic structure (e.g., attention patterns) from language to vision. Code is available at \href{https://github.com/Hxyou/MSCLIP}{URL}.
Multimodal Event Graphs: Towards Event Centric Understanding of Multimodal World
Jun 14, 2022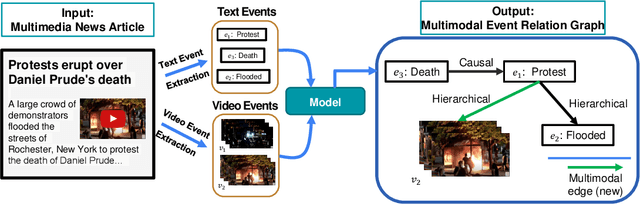
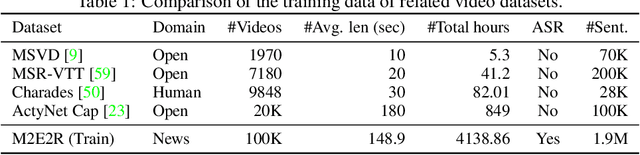
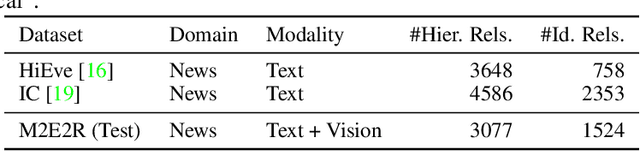

Understanding how events described or shown in multimedia content relate to one another is a critical component to developing robust artificially intelligent systems which can reason about real-world media. While much research has been devoted to event understanding in the text, image, and video domains, none have explored the complex relations that events experience across domains. For example, a news article may describe a `protest' event while a video shows an `arrest' event. Recognizing that the visual `arrest' event is a subevent of the broader `protest' event is a challenging, yet important problem that prior work has not explored. In this paper, we propose the novel task of MultiModal Event Event Relations to recognize such cross-modal event relations. We contribute a large-scale dataset consisting of 100k video-news article pairs, as well as a benchmark of densely annotated data. We also propose a weakly supervised multimodal method which integrates commonsense knowledge from an external knowledge base (KB) to predict rich multimodal event hierarchies. Experiments show that our model outperforms a number of competitive baselines on our proposed benchmark. We also perform a detailed analysis of our model's performance and suggest directions for future research.