 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgentic Discovery with Active Hypothesis Exploration for Visual Recognition
Apr 14, 2026We introduce HypoExplore, an agentic framework that formulates neural architecture discovery for visual recognition as a hypothesis-driven scientific inquiry. Given a human-specified high-level research direction, HypoExplore ideates, implements, evaluates, and improves neural architectures through evolutionary branching. New hypotheses are created using a large language model by selecting a parent hypothesis to build upon, guided by a dual strategy that balances exploiting validated principles with resolving uncertain ones. Our proposed framework maintains a Trajectory Tree that records the lineage of all proposed architectures, and a Hypothesis Memory Bank that actively tracks confidence scores acquired through experimental evidence. After each experiment, multiple feedback agents analyze the results from different perspectives and consolidate their findings into hypothesis confidence updates. Our framework is tested on discovering lightweight vision architectures on CIFAR-10, with the best achieving 94.11% accuracy evolved from a root node baseline that starts at 18.91%, and generalizes to CIFAR-100 and Tiny-ImageNet. We further demonstrate applicability to a specialized domain by conducting independent architecture discovery runs on MedMNIST, which yield a state-of-the-art performance. We show that hypothesis confidence scores grow increasingly predictive as evidence accumulates, and that the learned principles transfer across independent evolutionary lineages, suggesting that HypoExplore not only discovers stronger architectures, but can help build a genuine understanding of the design space.
Beyond Referring Expressions: Scenario Comprehension Visual Grounding
Apr 02, 2026Existing visual grounding benchmarks primarily evaluate alignment between image regions and literal referring expressions, where models can often succeed by matching a prominent named category. We explore a complementary and more challenging setting of scenario-based visual grounding, where the target must be inferred from roles, intentions, and relational context rather than explicit naming. We introduce Referring Scenario Comprehension (RSC), a benchmark designed for this setting. The queries in this benchmark are paragraph-length texts that describe object roles, user goals, and contextual cues, including deliberate references to distractor objects that often require deep understanding to resolve. Each instance is annotated with interpretable difficulty tags for uniqueness, clutter, size, overlap, and position which expose distinct failure modes and support fine-grained analysis. RSC contains approximately 31k training examples, 4k in-domain test examples, and a 3k out-of-distribution split with unseen object categories. We further propose ScenGround, a curriculum reasoning method serving as a reference point for this setting, combining supervised warm-starting with difficulty-aware reinforcement learning. Experiments show that scenario-based queries expose systematic failures in current models that standard benchmarks do not reveal, and that curriculum training improves performance on challenging slices and transfers to standard benchmarks.
ProxyThinker: Test-Time Guidance through Small Visual Reasoners
May 30, 2025Recent advancements in reinforcement learning with verifiable rewards have pushed the boundaries of the visual reasoning capabilities in large vision-language models (LVLMs). However, training LVLMs with reinforcement fine-tuning (RFT) is computationally expensive, posing a significant challenge to scaling model size. In this work, we propose ProxyThinker, an inference-time technique that enables large models to inherit the visual reasoning capabilities from small, slow-thinking visual reasoners without any training. By subtracting the output distributions of base models from those of RFT reasoners, ProxyThinker modifies the decoding dynamics and successfully elicits the slow-thinking reasoning demonstrated by the emerged sophisticated behaviors such as self-verification and self-correction. ProxyThinker consistently boosts performance on challenging visual benchmarks on spatial, mathematical, and multi-disciplinary reasoning, enabling untuned base models to compete with the performance of their full-scale RFT counterparts. Furthermore, our implementation efficiently coordinates multiple language models with parallelism techniques and achieves up to 38 $\times$ faster inference compared to previous decoding-time methods, paving the way for the practical deployment of ProxyThinker. Code is available at https://github.com/MrZilinXiao/ProxyThinker.
Evaluating Text-to-Image Synthesis with a Conditional Fréchet Distance
Mar 27, 2025



Evaluating text-to-image synthesis is challenging due to misalignment between established metrics and human preferences. We propose cFreD, a metric based on the notion of Conditional Fr\'echet Distance that explicitly accounts for both visual fidelity and text-prompt alignment. Existing metrics such as Inception Score (IS), Fr\'echet Inception Distance (FID) and CLIPScore assess either image quality or image-text alignment but not both which limits their correlation with human preferences. Scoring models explicitly trained to replicate human preferences require constant updates and may not generalize to novel generation techniques or out-of-domain inputs. Through extensive experiments across multiple recently proposed text-to-image models and diverse prompt datasets, we demonstrate that cFreD exhibits a higher correlation with human judgments compared to statistical metrics, including metrics trained with human preferences. Our findings validate cFreD as a robust, future-proof metric for the systematic evaluation of text-to-image models, standardizing benchmarking in this rapidly evolving field. We release our evaluation toolkit and benchmark in the appendix.
PropTest: Automatic Property Testing for Improved Visual Programming
Mar 25, 2024



Visual Programming has emerged as an alternative to end-to-end black-box visual reasoning models. This type of methods leverage Large Language Models (LLMs) to decompose a problem and generate the source code for an executable computer program. This strategy has the advantage of offering an interpretable reasoning path and does not require finetuning a model with task-specific data. We propose PropTest, a general strategy that improves visual programming by further using an LLM to generate code that tests for visual properties in an initial round of proposed solutions. Particularly, our method tests for data-type consistency, as well as syntactic and semantic properties in the generated solutions. Our proposed solution outperforms baselines and achieves comparable results to state-of-the-art methods while using smaller and publicly available LLMs (CodeLlama-7B and WizardCoder-15B). This is demonstrated across different benchmarks on visual question answering and referring expression comprehension, showing the efficacy of our approach in enhancing the performance and generalization of visual reasoning tasks. Specifically, PropTest improves ViperGPT by obtaining 48.66% accuracy (+8.3%) on the A-OKVQA benchmark and 52.8% (+3.3%) on the RefCOCO+ benchmark using CodeLlama-7B.
Multi-Modality Multi-Loss Fusion Network
Aug 01, 2023In this work we investigate the optimal selection and fusion of features across multiple modalities and combine these in a neural network to improve emotion detection. We compare different fusion methods and examine the impact of multi-loss training within the multi-modality fusion network, identifying useful findings relating to subnet performance. Our best model achieves state-of-the-art performance for three datasets (CMU-MOSI, CMU-MOSEI and CH-SIMS), and outperforms the other methods in most metrics. We have found that training on multimodal features improves single modality testing and designing fusion methods based on dataset annotation schema enhances model performance. These results suggest a roadmap towards an optimized feature selection and fusion approach for enhancing emotion detection in neural networks.
Multimodal Event Graphs: Towards Event Centric Understanding of Multimodal World
Jun 14, 2022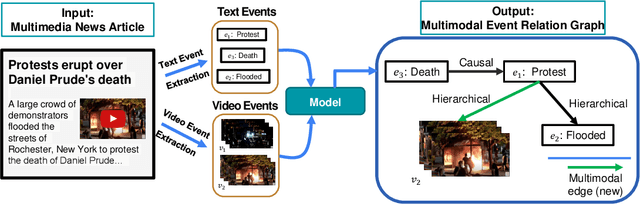
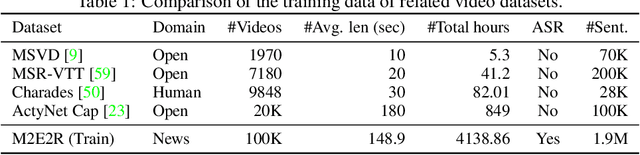
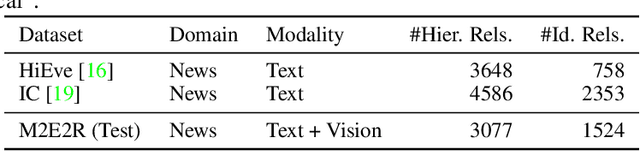

Understanding how events described or shown in multimedia content relate to one another is a critical component to developing robust artificially intelligent systems which can reason about real-world media. While much research has been devoted to event understanding in the text, image, and video domains, none have explored the complex relations that events experience across domains. For example, a news article may describe a `protest' event while a video shows an `arrest' event. Recognizing that the visual `arrest' event is a subevent of the broader `protest' event is a challenging, yet important problem that prior work has not explored. In this paper, we propose the novel task of MultiModal Event Event Relations to recognize such cross-modal event relations. We contribute a large-scale dataset consisting of 100k video-news article pairs, as well as a benchmark of densely annotated data. We also propose a weakly supervised multimodal method which integrates commonsense knowledge from an external knowledge base (KB) to predict rich multimodal event hierarchies. Experiments show that our model outperforms a number of competitive baselines on our proposed benchmark. We also perform a detailed analysis of our model's performance and suggest directions for future research.