 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoT Rerailer: Enhancing the Reliability of Large Language Models in Complex Reasoning Tasks through Error Detection and Correction
Aug 25, 2024Chain-of-Thought (CoT) prompting enhances Large Language Models (LLMs) complex reasoning abilities by generating intermediate steps. However, these steps can introduce hallucinations and accumulate errors. We propose the CoT Rerailer to address these challenges, employing self-consistency and multi-agent debate systems to identify and rectify errors in the reasoning process. The CoT Rerailer first selects the most logically correct Reasoning Path (RP) using consistency checks and critical evaluation by automated agents. It then engages a multi-agent debate system to propose and validate corrections to ensure the generation of an error-free intermediate logical path. The corrected steps are then used to generate a revised reasoning chain to further reduce hallucinations and enhance answer quality. We demonstrate the effectiveness of our approach across diverse question-answering datasets in various knowledge domains. The CoT Rerailer enhances the reliability of LLM-generated reasoning, contributing to more trustworthy AI driven decision-making processes.
Are handcrafted filters helpful for attributing AI-generated images?
Jul 23, 2024Recently, a vast number of image generation models have been proposed, which raises concerns regarding the misuse of these artificial intelligence (AI) techniques for generating fake images. To attribute the AI-generated images, existing schemes usually design and train deep neural networks (DNNs) to learn the model fingerprints, which usually requires a large amount of data for effective learning. In this paper, we aim to answer the following two questions for AI-generated image attribution, 1) is it possible to design useful handcrafted filters to facilitate the fingerprint learning? and 2) how we could reduce the amount of training data after we incorporate the handcrafted filters? We first propose a set of Multi-Directional High-Pass Filters (MHFs) which are capable to extract the subtle fingerprints from various directions. Then, we propose a Directional Enhanced Feature Learning network (DEFL) to take both the MHFs and randomly-initialized filters into consideration. The output of the DEFL is fused with the semantic features to produce a compact fingerprint. To make the compact fingerprint discriminative among different models, we propose a Dual-Margin Contrastive (DMC) loss to tune our DEFL. Finally, we propose a reference based fingerprint classification scheme for image attribution. Experimental results demonstrate that it is indeed helpful to use our MHFs for attributing the AI-generated images. The performance of our proposed method is significantly better than the state-of-the-art for both the closed-set and open-set image attribution, where only a small amount of images are required for training.
Cover-separable Fixed Neural Network Steganography via Deep Generative Models
Jul 16, 2024



Image steganography is the process of hiding secret data in a cover image by subtle perturbation. Recent studies show that it is feasible to use a fixed neural network for data embedding and extraction. Such Fixed Neural Network Steganography (FNNS) demonstrates favorable performance without the need for training networks, making it more practical for real-world applications. However, the stego-images generated by the existing FNNS methods exhibit high distortion, which is prone to be detected by steganalysis tools. To deal with this issue, we propose a Cover-separable Fixed Neural Network Steganography, namely Cs-FNNS. In Cs-FNNS, we propose a Steganographic Perturbation Search (SPS) algorithm to directly encode the secret data into an imperceptible perturbation, which is combined with an AI-generated cover image for transmission. Through accessing the same deep generative models, the receiver could reproduce the cover image using a pre-agreed key, to separate the perturbation in the stego-image for data decoding. such an encoding/decoding strategy focuses on the secret data and eliminates the disturbance of the cover images, hence achieving a better performance. We apply our Cs-FNNS to the steganographic field that hiding secret images within cover images. Through comprehensive experiments, we demonstrate the superior performance of the proposed method in terms of visual quality and undetectability. Moreover, we show the flexibility of our Cs-FNNS in terms of hiding multiple secret images for different receivers.
Causal Inference with Latent Variables: Recent Advances and Future Prospectives
Jun 20, 2024Causality lays the foundation for the trajectory of our world. Causal inference (CI), which aims to infer intrinsic causal relations among variables of interest, has emerged as a crucial research topic. Nevertheless, the lack of observation of important variables (e.g., confounders, mediators, exogenous variables, etc.) severely compromises the reliability of CI methods. The issue may arise from the inherent difficulty in measuring the variables. Additionally, in observational studies where variables are passively recorded, certain covariates might be inadvertently omitted by the experimenter. Depending on the type of unobserved variables and the specific CI task, various consequences can be incurred if these latent variables are carelessly handled, such as biased estimation of causal effects, incomplete understanding of causal mechanisms, lack of individual-level causal consideration, etc. In this survey, we provide a comprehensive review of recent developments in CI with latent variables. We start by discussing traditional CI techniques when variables of interest are assumed to be fully observed. Afterward, under the taxonomy of circumvention and inference-based methods, we provide an in-depth discussion of various CI strategies to handle latent variables, covering the tasks of causal effect estimation, mediation analysis, counterfactual reasoning, and causal discovery. Furthermore, we generalize the discussion to graph data where interference among units may exist. Finally, we offer fresh aspects for further advancement of CI with latent variables, especially new opportunities in the era of large language models (LLMs).
Through the Theory of Mind's Eye: Reading Minds with Multimodal Video Large Language Models
Jun 19, 2024



Can large multimodal models have a human-like ability for emotional and social reasoning, and if so, how does it work? Recent research has discovered emergent theory-of-mind (ToM) reasoning capabilities in large language models (LLMs). LLMs can reason about people's mental states by solving various text-based ToM tasks that ask questions about the actors' ToM (e.g., human belief, desire, intention). However, human reasoning in the wild is often grounded in dynamic scenes across time. Thus, we consider videos a new medium for examining spatio-temporal ToM reasoning ability. Specifically, we ask explicit probing questions about videos with abundant social and emotional reasoning content. We develop a pipeline for multimodal LLM for ToM reasoning using video and text. We also enable explicit ToM reasoning by retrieving key frames for answering a ToM question, which reveals how multimodal LLMs reason about ToM.
Reminding Multimodal Large Language Models of Object-aware Knowledge with Retrieved Tags
Jun 16, 2024Despite recent advances in the general visual instruction-following ability of Multimodal Large Language Models (MLLMs), they still struggle with critical problems when required to provide a precise and detailed response to a visual instruction: (1) failure to identify novel objects or entities, (2) mention of non-existent objects, and (3) neglect of object's attributed details. Intuitive solutions include improving the size and quality of data or using larger foundation models. They show effectiveness in mitigating these issues, but at an expensive cost of collecting a vast amount of new data and introducing a significantly larger model. Standing at the intersection of these approaches, we examine the three object-oriented problems from the perspective of the image-to-text mapping process by the multimodal connector. In this paper, we first identify the limitations of multimodal connectors stemming from insufficient training data. Driven by this, we propose to enhance the mapping with retrieval-augmented tag tokens, which contain rich object-aware information such as object names and attributes. With our Tag-grounded visual instruction tuning with retrieval Augmentation (TUNA), we outperform baselines that share the same language model and training data on 12 benchmarks. Furthermore, we show the zero-shot capability of TUNA when provided with specific datastores.
Learning from Students: Applying t-Distributions to Explore Accurate and Efficient Formats for LLMs
May 06, 2024



Large language models (LLMs) have recently achieved state-of-the-art performance across various tasks, yet due to their large computational requirements, they struggle with strict latency and power demands. Deep neural network (DNN) quantization has traditionally addressed these limitations by converting models to low-precision integer formats. Yet recently alternative formats, such as Normal Float (NF4), have been shown to consistently increase model accuracy, albeit at the cost of increased chip area. In this work, we first conduct a large-scale analysis of LLM weights and activations across 30 networks to conclude most distributions follow a Student's t-distribution. We then derive a new theoretically optimal format, Student Float (SF4), with respect to this distribution, that improves over NF4 across modern LLMs, for example increasing the average accuracy on LLaMA2-7B by 0.76% across tasks. Using this format as a high-accuracy reference, we then propose augmenting E2M1 with two variants of supernormal support for higher model accuracy. Finally, we explore the quality and performance frontier across 11 datatypes, including non-traditional formats like Additive-Powers-of-Two (APoT), by evaluating their model accuracy and hardware complexity. We discover a Pareto curve composed of INT4, E2M1, and E2M1 with supernormal support, which offers a continuous tradeoff between model accuracy and chip area. For example, E2M1 with supernormal support increases the accuracy of Phi-2 by up to 2.19% with 1.22% area overhead, enabling more LLM-based applications to be run at four bits.
Bridging the Fairness Divide: Achieving Group and Individual Fairness in Graph Neural Networks
Apr 26, 2024



Graph neural networks (GNNs) have emerged as a powerful tool for analyzing and learning from complex data structured as graphs, demonstrating remarkable effectiveness in various applications, such as social network analysis, recommendation systems, and drug discovery. However, despite their impressive performance, the fairness problem has increasingly gained attention as a crucial aspect to consider. Existing research in graph learning focuses on either group fairness or individual fairness. However, since each concept provides unique insights into fairness from distinct perspectives, integrating them into a fair graph neural network system is crucial. To the best of our knowledge, no study has yet to comprehensively tackle both individual and group fairness simultaneously. In this paper, we propose a new concept of individual fairness within groups and a novel framework named Fairness for Group and Individual (FairGI), which considers both group fairness and individual fairness within groups in the context of graph learning. FairGI employs the similarity matrix of individuals to achieve individual fairness within groups, while leveraging adversarial learning to address group fairness in terms of both Equal Opportunity and Statistical Parity. The experimental results demonstrate that our approach not only outperforms other state-of-the-art models in terms of group fairness and individual fairness within groups, but also exhibits excellent performance in population-level individual fairness, while maintaining comparable prediction accuracy.
UFID: A Unified Framework for Input-level Backdoor Detection on Diffusion Models
Apr 01, 2024



Diffusion Models are vulnerable to backdoor attacks, where malicious attackers inject backdoors by poisoning some parts of the training samples during the training stage. This poses a serious threat to the downstream users, who query the diffusion models through the API or directly download them from the internet. To mitigate the threat of backdoor attacks, there have been a plethora of investigations on backdoor detections. However, none of them designed a specialized backdoor detection method for diffusion models, rendering the area much under-explored. Moreover, these prior methods mainly focus on the traditional neural networks in the classification task, which cannot be adapted to the backdoor detections on the generative task easily. Additionally, most of the prior methods require white-box access to model weights and architectures, or the probability logits as additional information, which are not always practical. In this paper, we propose a Unified Framework for Input-level backdoor Detection (UFID) on the diffusion models, which is motivated by observations in the diffusion models and further validated with a theoretical causality analysis. Extensive experiments across different datasets on both conditional and unconditional diffusion models show that our method achieves a superb performance on detection effectiveness and run-time efficiency. The code is available at https://github.com/GuanZihan/official_UFID.
Img2Loc: Revisiting Image Geolocalization using Multi-modality Foundation Models and Image-based Retrieval-Augmented Generation
Mar 28, 2024
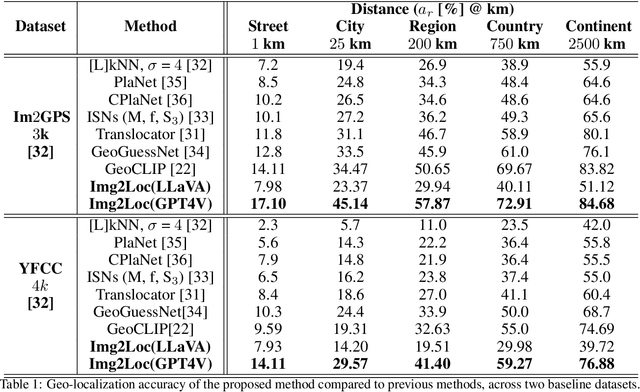
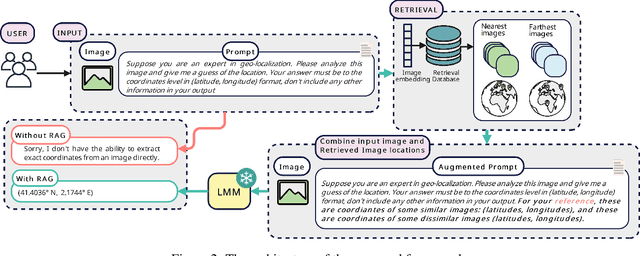
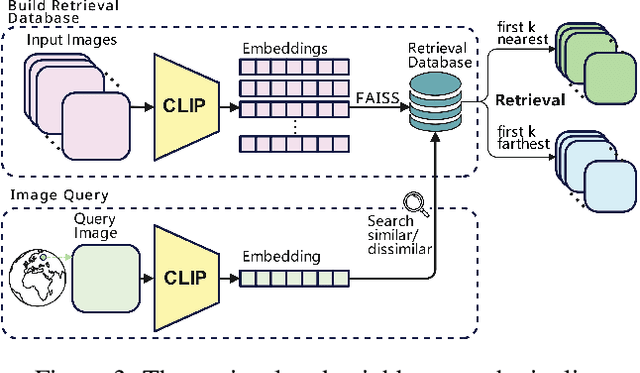
Geolocating precise locations from images presents a challenging problem in computer vision and information retrieval.Traditional methods typically employ either classification, which dividing the Earth surface into grid cells and classifying images accordingly, or retrieval, which identifying locations by matching images with a database of image-location pairs. However, classification-based approaches are limited by the cell size and cannot yield precise predictions, while retrieval-based systems usually suffer from poor search quality and inadequate coverage of the global landscape at varied scale and aggregation levels. To overcome these drawbacks, we present Img2Loc, a novel system that redefines image geolocalization as a text generation task. This is achieved using cutting-edge large multi-modality models like GPT4V or LLaVA with retrieval augmented generation. Img2Loc first employs CLIP-based representations to generate an image-based coordinate query database. It then uniquely combines query results with images itself, forming elaborate prompts customized for LMMs. When tested on benchmark datasets such as Im2GPS3k and YFCC4k, Img2Loc not only surpasses the performance of previous state-of-the-art models but does so without any model training.