 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSRPL-SFDA: SAM-Guided Reliable Pseudo-Labels for Source-Free Domain Adaptation in Medical Image Segmentation
Jun 11, 2025Domain Adaptation (DA) is crucial for robust deployment of medical image segmentation models when applied to new clinical centers with significant domain shifts. Source-Free Domain Adaptation (SFDA) is appealing as it can deal with privacy concerns and access constraints on source-domain data during adaptation to target-domain data. However, SFDA faces challenges such as insufficient supervision in the target domain with unlabeled images. In this work, we propose a Segment Anything Model (SAM)-guided Reliable Pseudo-Labels method for SFDA (SRPL-SFDA) with three key components: 1) Test-Time Tri-branch Intensity Enhancement (T3IE) that not only improves quality of raw pseudo-labels in the target domain, but also leads to SAM-compatible inputs with three channels to better leverage SAM's zero-shot inference ability for refining the pseudo-labels; 2) A reliable pseudo-label selection module that rejects low-quality pseudo-labels based on Consistency of Multiple SAM Outputs (CMSO) under input perturbations with T3IE; and 3) A reliability-aware training procedure in the unlabeled target domain where reliable pseudo-labels are used for supervision and unreliable parts are regularized by entropy minimization. Experiments conducted on two multi-domain medical image segmentation datasets for fetal brain and the prostate respectively demonstrate that: 1) SRPL-SFDA effectively enhances pseudo-label quality in the unlabeled target domain, and improves SFDA performance by leveraging the reliability-aware training; 2) SRPL-SFDA outperformed state-of-the-art SFDA methods, and its performance is close to that of supervised training in the target domain. The code of this work is available online: https://github.com/HiLab-git/SRPL-SFDA.
Elicit and Enhance: Advancing Multimodal Reasoning in Medical Scenarios
May 29, 2025Effective clinical decision-making depends on iterative, multimodal reasoning across diverse sources of evidence. The recent emergence of multimodal reasoning models has significantly transformed the landscape of solving complex tasks. Although such models have achieved notable success in mathematics and science, their application to medical domains remains underexplored. In this work, we propose \textit{MedE$^2$}, a two-stage post-training pipeline that elicits and then enhances multimodal reasoning for medical domains. In Stage-I, we fine-tune models using 2,000 text-only data samples containing precisely orchestrated reasoning demonstrations to elicit reasoning behaviors. In Stage-II, we further enhance the model's reasoning capabilities using 1,500 rigorously curated multimodal medical cases, aligning model reasoning outputs with our proposed multimodal medical reasoning preference. Extensive experiments demonstrate the efficacy and reliability of \textit{MedE$^2$} in improving the reasoning performance of medical multimodal models. Notably, models trained with \textit{MedE$^2$} consistently outperform baselines across multiple medical multimodal benchmarks. Additional validation on larger models and under inference-time scaling further confirms the robustness and practical utility of our approach.
Graph Mamba for Efficient Whole Slide Image Understanding
May 23, 2025Whole Slide Images (WSIs) in histopathology present a significant challenge for large-scale medical image analysis due to their high resolution, large size, and complex tile relationships. Existing Multiple Instance Learning (MIL) methods, such as Graph Neural Networks (GNNs) and Transformer-based models, face limitations in scalability and computational cost. To bridge this gap, we propose the WSI-GMamba framework, which synergistically combines the relational modeling strengths of GNNs with the efficiency of Mamba, the State Space Model designed for sequence learning. The proposed GMamba block integrates Message Passing, Graph Scanning & Flattening, and feature aggregation via a Bidirectional State Space Model (Bi-SSM), achieving Transformer-level performance with 7* fewer FLOPs. By leveraging the complementary strengths of lightweight GNNs and Mamba, the WSI-GMamba framework delivers a scalable solution for large-scale WSI analysis, offering both high accuracy and computational efficiency for slide-level classification.
DiagnosisArena: Benchmarking Diagnostic Reasoning for Large Language Models
May 20, 2025The emergence of groundbreaking large language models capable of performing complex reasoning tasks holds significant promise for addressing various scientific challenges, including those arising in complex clinical scenarios. To enable their safe and effective deployment in real-world healthcare settings, it is urgently necessary to benchmark the diagnostic capabilities of current models systematically. Given the limitations of existing medical benchmarks in evaluating advanced diagnostic reasoning, we present DiagnosisArena, a comprehensive and challenging benchmark designed to rigorously assess professional-level diagnostic competence. DiagnosisArena consists of 1,113 pairs of segmented patient cases and corresponding diagnoses, spanning 28 medical specialties, deriving from clinical case reports published in 10 top-tier medical journals. The benchmark is developed through a meticulous construction pipeline, involving multiple rounds of screening and review by both AI systems and human experts, with thorough checks conducted to prevent data leakage. Our study reveals that even the most advanced reasoning models, o3-mini, o1, and DeepSeek-R1, achieve only 45.82%, 31.09%, and 17.79% accuracy, respectively. This finding highlights a significant generalization bottleneck in current large language models when faced with clinical diagnostic reasoning challenges. Through DiagnosisArena, we aim to drive further advancements in AIs diagnostic reasoning capabilities, enabling more effective solutions for real-world clinical diagnostic challenges. We provide the benchmark and evaluation tools for further research and development https://github.com/SPIRAL-MED/DiagnosisArena.
Rethinking the generalization of drug target affinity prediction algorithms via similarity aware evaluation
Apr 13, 2025Drug-target binding affinity prediction is a fundamental task for drug discovery. It has been extensively explored in literature and promising results are reported. However, in this paper, we demonstrate that the results may be misleading and cannot be well generalized to real practice. The core observation is that the canonical randomized split of a test set in conventional evaluation leaves the test set dominated by samples with high similarity to the training set. The performance of models is severely degraded on samples with lower similarity to the training set but the drawback is highly overlooked in current evaluation. As a result, the performance can hardly be trusted when the model meets low-similarity samples in real practice. To address this problem, we propose a framework of similarity aware evaluation in which a novel split methodology is proposed to adapt to any desired distribution. This is achieved by a formulation of optimization problems which are approximately and efficiently solved by gradient descent. We perform extensive experiments across five representative methods in four datasets for two typical target evaluations and compare them with various counterpart methods. Results demonstrate that the proposed split methodology can significantly better fit desired distributions and guide the development of models. Code is released at https://github.com/Amshoreline/SAE/tree/main.
PathOrchestra: A Comprehensive Foundation Model for Computational Pathology with Over 100 Diverse Clinical-Grade Tasks
Mar 31, 2025The complexity and variability inherent in high-resolution pathological images present significant challenges in computational pathology. While pathology foundation models leveraging AI have catalyzed transformative advancements, their development demands large-scale datasets, considerable storage capacity, and substantial computational resources. Furthermore, ensuring their clinical applicability and generalizability requires rigorous validation across a broad spectrum of clinical tasks. Here, we present PathOrchestra, a versatile pathology foundation model trained via self-supervised learning on a dataset comprising 300K pathological slides from 20 tissue and organ types across multiple centers. The model was rigorously evaluated on 112 clinical tasks using a combination of 61 private and 51 public datasets. These tasks encompass digital slide preprocessing, pan-cancer classification, lesion identification, multi-cancer subtype classification, biomarker assessment, gene expression prediction, and the generation of structured reports. PathOrchestra demonstrated exceptional performance across 27,755 WSIs and 9,415,729 ROIs, achieving over 0.950 accuracy in 47 tasks, including pan-cancer classification across various organs, lymphoma subtype diagnosis, and bladder cancer screening. Notably, it is the first model to generate structured reports for high-incidence colorectal cancer and diagnostically complex lymphoma-areas that are infrequently addressed by foundational models but hold immense clinical potential. Overall, PathOrchestra exemplifies the feasibility and efficacy of a large-scale, self-supervised pathology foundation model, validated across a broad range of clinical-grade tasks. Its high accuracy and reduced reliance on extensive data annotation underline its potential for clinical integration, offering a pathway toward more efficient and high-quality medical services.
Interactive Segmentation and Report Generation for CT Images
Mar 05, 2025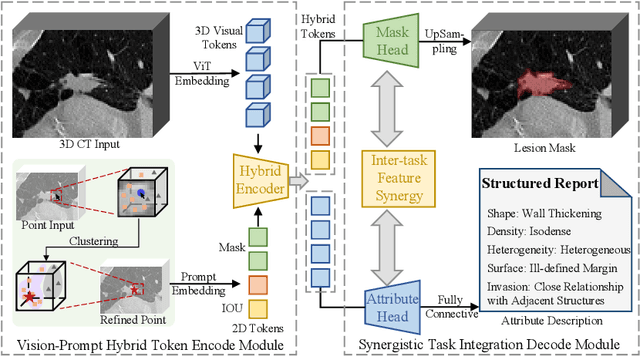
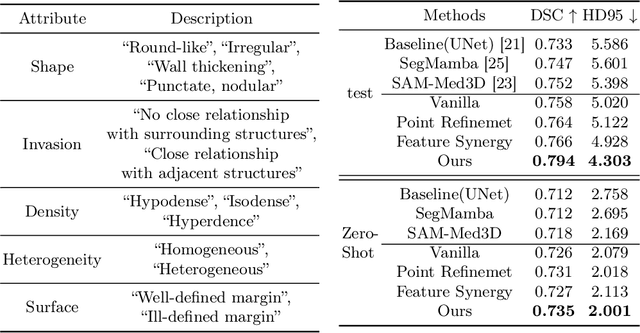

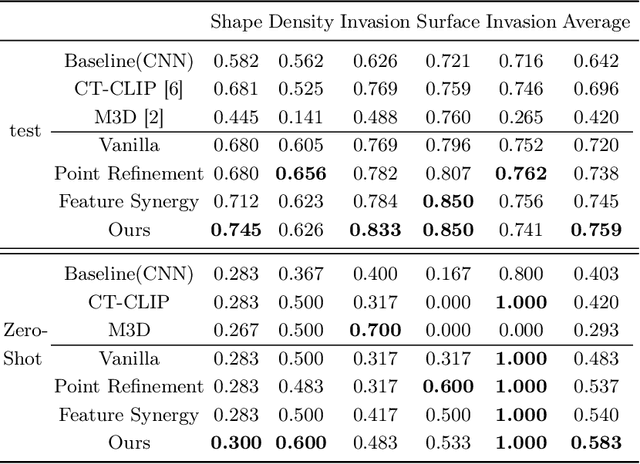
Automated CT report generation plays a crucial role in improving diagnostic accuracy and clinical workflow efficiency. However, existing methods lack interpretability and impede patient-clinician understanding, while their static nature restricts radiologists from dynamically adjusting assessments during image review. Inspired by interactive segmentation techniques, we propose a novel interactive framework for 3D lesion morphology reporting that seamlessly generates segmentation masks with comprehensive attribute descriptions, enabling clinicians to generate detailed lesion profiles for enhanced diagnostic assessment. To our best knowledge, we are the first to integrate the interactive segmentation and structured reports in 3D CT medical images. Experimental results across 15 lesion types demonstrate the effectiveness of our approach in providing a more comprehensive and reliable reporting system for lesion segmentation and capturing. The source code will be made publicly available following paper acceptance.
MedForge: Building Medical Foundation Models Like Open Source Software Development
Feb 22, 2025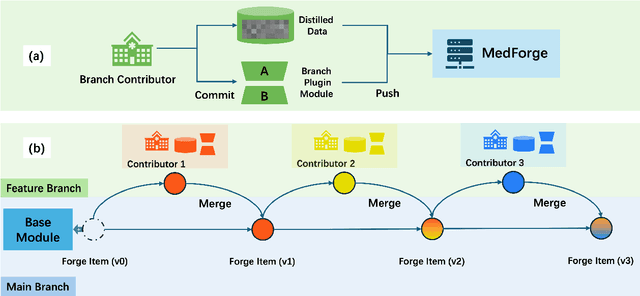
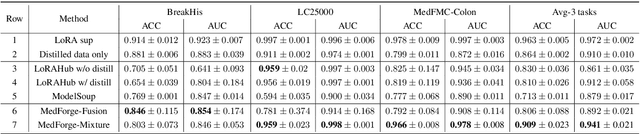
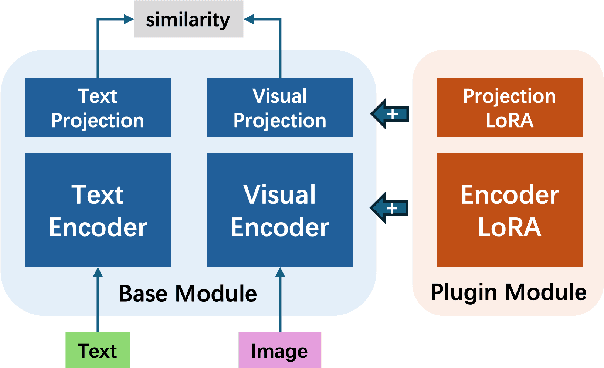
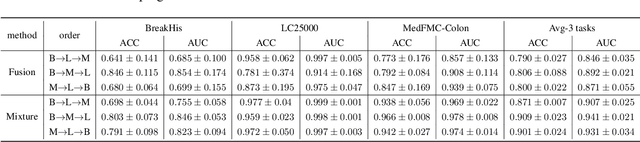
Foundational models (FMs) have made significant strides in the healthcare domain. Yet the data silo challenge and privacy concern remain in healthcare systems, hindering safe medical data sharing and collaborative model development among institutions. The collection and curation of scalable clinical datasets increasingly become the bottleneck for training strong FMs. In this study, we propose Medical Foundation Models Merging (MedForge), a cooperative framework enabling a community-driven medical foundation model development, meanwhile preventing the information leakage of raw patient data and mitigating synchronization model development issues across clinical institutions. MedForge offers a bottom-up model construction mechanism by flexibly merging task-specific Low-Rank Adaptation (LoRA) modules, which can adapt to downstream tasks while retaining original model parameters. Through an asynchronous LoRA module integration scheme, the resulting composite model can progressively enhance its comprehensive performance on various clinical tasks. MedForge shows strong performance on multiple clinical datasets (e.g., breast cancer, lung cancer, and colon cancer) collected from different institutions. Our major findings highlight the value of collaborative foundation models in advancing multi-center clinical collaboration effectively and cohesively. Our code is publicly available at https://github.com/TanZheling/MedForge.
MMXU: A Multi-Modal and Multi-X-ray Understanding Dataset for Disease Progression
Feb 17, 2025Large vision-language models (LVLMs) have shown great promise in medical applications, particularly in visual question answering (MedVQA) and diagnosis from medical images. However, existing datasets and models often fail to consider critical aspects of medical diagnostics, such as the integration of historical records and the analysis of disease progression over time. In this paper, we introduce MMXU (Multimodal and MultiX-ray Understanding), a novel dataset for MedVQA that focuses on identifying changes in specific regions between two patient visits. Unlike previous datasets that primarily address single-image questions, MMXU enables multi-image questions, incorporating both current and historical patient data. We demonstrate the limitations of current LVLMs in identifying disease progression on MMXU-\textit{test}, even those that perform well on traditional benchmarks. To address this, we propose a MedRecord-Augmented Generation (MAG) approach, incorporating both global and regional historical records. Our experiments show that integrating historical records significantly enhances diagnostic accuracy by at least 20\%, bridging the gap between current LVLMs and human expert performance. Additionally, we fine-tune models with MAG on MMXU-\textit{dev}, which demonstrates notable improvements. We hope this work could illuminate the avenue of advancing the use of LVLMs in medical diagnostics by emphasizing the importance of historical context in interpreting medical images. Our dataset is released at \href{https://github.com/linjiemu/MMXU}{https://github.com/linjiemu/MMXU}.
A Data-Efficient Pan-Tumor Foundation Model for Oncology CT Interpretation
Feb 10, 2025



Artificial intelligence-assisted imaging analysis has made substantial strides in tumor diagnosis and management. Here we present PASTA, a pan-tumor CT foundation model that achieves state-of-the-art performance on 45 of 46 representative oncology tasks -- including lesion segmentation, tumor detection in plain CT, tumor staging, survival prediction, structured report generation, and cross-modality transfer learning, significantly outperforming the second-best models on 35 tasks. This remarkable advancement is driven by our development of PASTA-Gen, an innovative synthetic tumor generation framework that produces a comprehensive dataset of 30,000 CT scans with pixel-level annotated lesions and paired structured reports, encompassing malignancies across ten organs and five benign lesion types. By leveraging this rich, high-quality synthetic data, we overcome a longstanding bottleneck in the development of CT foundation models -- specifically, the scarcity of publicly available, high-quality annotated datasets due to privacy constraints and the substantial labor required for scaling precise data annotation. Encouragingly, PASTA demonstrates exceptional data efficiency with promising practical value, markedly improving performance on various tasks with only a small amount of real-world data. The open release of both the synthetic dataset and PASTA foundation model effectively addresses the challenge of data scarcity, thereby advancing oncological research and clinical translation.