 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLoRA-FA: Memory-efficient Low-rank Adaptation for Large Language Models Fine-tuning
Aug 07, 2023



The low-rank adaptation (LoRA) method can largely reduce the amount of trainable parameters for fine-tuning large language models (LLMs), however, it still requires expensive activation memory to update low-rank weights. Reducing the number of LoRA layers or using activation recomputation could harm the fine-tuning performance or increase the computational overhead. In this work, we present LoRA-FA, a memory-efficient fine-tuning method that reduces the activation memory without performance degradation and expensive recomputation. LoRA-FA chooses to freeze the projection-down weight of $A$ and update the projection-up weight of $B$ in each LoRA layer. It ensures the change of model weight reside in a low-rank space during LLMs fine-tuning, while eliminating the requirement to store full-rank input activations. We conduct extensive experiments across multiple model types (RoBERTa, T5, LLaMA) and model scales. Our results show that LoRA-FA can always achieve close fine-tuning accuracy across different tasks compared to full parameter fine-tuning and LoRA. Furthermore, LoRA-FA can reduce the overall memory cost by up to 1.4$\times$ compared to LoRA.
Eva: A General Vectorized Approximation Framework for Second-order Optimization
Aug 04, 2023



Second-order optimization algorithms exhibit excellent convergence properties for training deep learning models, but often incur significant computation and memory overheads. This can result in lower training efficiency than the first-order counterparts such as stochastic gradient descent (SGD). In this work, we present a memory- and time-efficient second-order algorithm named Eva with two novel techniques: 1) we construct the second-order information with the Kronecker factorization of small stochastic vectors over a mini-batch of training data to reduce memory consumption, and 2) we derive an efficient update formula without explicitly computing the inverse of matrices using the Sherman-Morrison formula. We further extend Eva to a general vectorized approximation framework to improve the compute and memory efficiency of two existing second-order algorithms (FOOF and Shampoo) without affecting their convergence performance. Extensive experimental results on different models and datasets show that Eva reduces the end-to-end training time up to 2.05x and 2.42x compared to first-order SGD and second-order algorithms (K-FAC and Shampoo), respectively.
Evaluation and Optimization of Gradient Compression for Distributed Deep Learning
Jun 15, 2023To accelerate distributed training, many gradient compression methods have been proposed to alleviate the communication bottleneck in synchronous stochastic gradient descent (S-SGD), but their efficacy in real-world applications still remains unclear. In this work, we first evaluate the efficiency of three representative compression methods (quantization with Sign-SGD, sparsification with Top-k SGD, and low-rank with Power-SGD) on a 32-GPU cluster. The results show that they cannot always outperform well-optimized S-SGD or even worse due to their incompatibility with three key system optimization techniques (all-reduce, pipelining, and tensor fusion) in S-SGD. To this end, we propose a novel gradient compression method, called alternate compressed Power-SGD (ACP-SGD), which alternately compresses and communicates low-rank matrices. ACP-SGD not only significantly reduces the communication volume, but also enjoys the three system optimizations like S-SGD. Compared with Power-SGD, the optimized ACP-SGD can largely reduce the compression and communication overheads, while achieving similar model accuracy. In our experiments, ACP-SGD achieves an average of 4.06x and 1.43x speedups over S-SGD and Power-SGD, respectively, and it consistently outperforms other baselines across different setups (from 8 GPUs to 64 GPUs and from 1Gb/s Ethernet to 100Gb/s InfiniBand).
FedML Parrot: A Scalable Federated Learning System via Heterogeneity-aware Scheduling on Sequential and Hierarchical Training
Mar 03, 2023



Federated Learning (FL) enables collaborations among clients for train machine learning models while protecting their data privacy. Existing FL simulation platforms that are designed from the perspectives of traditional distributed training, suffer from laborious code migration between simulation and production, low efficiency, low GPU utility, low scalability with high hardware requirements and difficulty of simulating stateful clients. In this work, we firstly demystify the challenges and bottlenecks of simulating FL, and design a new FL system named as FedML \texttt{Parrot}. It improves the training efficiency, remarkably relaxes the requirements on the hardware, and supports efficient large-scale FL experiments with stateful clients by: (1) sequential training clients on devices; (2) decomposing original aggregation into local and global aggregation on devices and server respectively; (3) scheduling tasks to mitigate straggler problems and enhance computing utility; (4) distributed client state manager to support various FL algorithms. Besides, built upon our generic APIs and communication interfaces, users can seamlessly transform the simulation into the real-world deployment without modifying codes. We evaluate \texttt{Parrot} through extensive experiments for training diverse models on various FL datasets to demonstrate that \texttt{Parrot} can achieve simulating over 1000 clients (stateful or stateless) with flexible GPU devices setting ($4 \sim 32$) and high GPU utility, 1.2 $\sim$ 4 times faster than FedScale, and 10 $\sim$ 100 times memory saving than FedML. And we verify that \texttt{Parrot} works well with homogeneous and heterogeneous devices in three different clusters. Two FL algorithms with stateful clients and four algorithms with stateless clients are simulated to verify the wide adaptability of \texttt{Parrot} to different algorithms.
Decoupling the All-Reduce Primitive for Accelerating Distributed Deep Learning
Feb 24, 2023Communication scheduling has been shown to be effective in accelerating distributed training, which enables all-reduce communications to be overlapped with backpropagation computations. This has been commonly adopted in popular distributed deep learning frameworks. However, there exist two fundamental problems: (1) excessive startup latency proportional to the number of workers for each all-reduce operation; (2) it only achieves sub-optimal training performance due to the dependency and synchronization requirement of the feed-forward computation in the next iteration. We propose a novel scheduling algorithm, DeAR, that decouples the all-reduce primitive into two continuous operations, which overlaps with both backpropagation and feed-forward computations without extra communications. We further design a practical tensor fusion algorithm to improve the training performance. Experimental results with five popular models show that DeAR achieves up to 83% and 15% training speedup over the state-of-the-art solutions on a 64-GPU cluster with 10Gb/s Ethernet and 100Gb/s InfiniBand interconnects, respectively.
An Efficient Split Fine-tuning Framework for Edge and Cloud Collaborative Learning
Nov 30, 2022



To enable the pre-trained models to be fine-tuned with local data on edge devices without sharing data with the cloud, we design an efficient split fine-tuning (SFT) framework for edge and cloud collaborative learning. We propose three novel techniques in this framework. First, we propose a matrix decomposition-based method to compress the intermediate output of a neural network to reduce the communication volume between the edge device and the cloud server. Second, we eliminate particular links in the model without affecting the convergence performance in fine-tuning. Third, we implement our system atop PyTorch to allow users to easily extend their existing training scripts to enjoy the efficient edge and cloud collaborative learning. Experiments results on 9 NLP datasets show that our framework can reduce the communication traffic by 96 times with little impact on the model accuracy.
EASNet: Searching Elastic and Accurate Network Architecture for Stereo Matching
Jul 20, 2022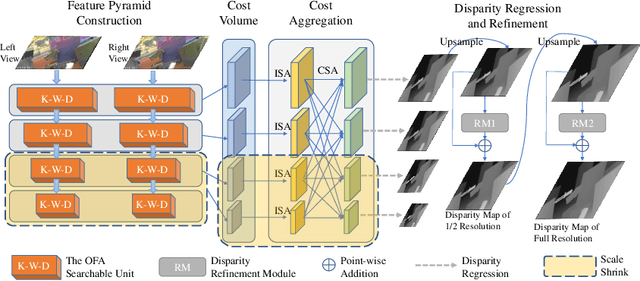
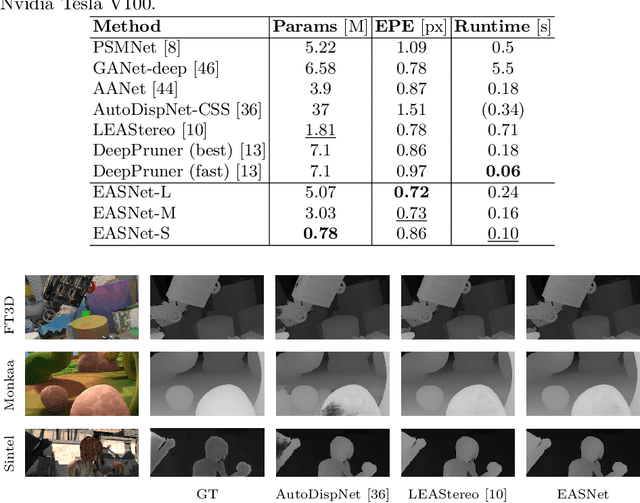
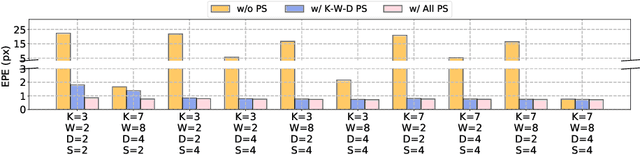
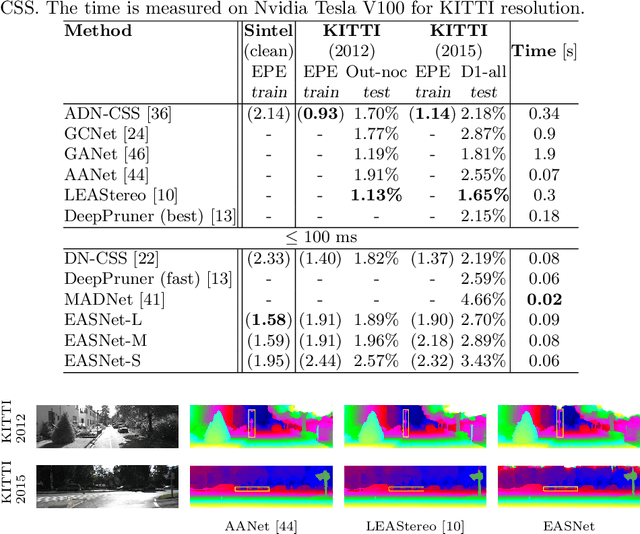
Recent advanced studies have spent considerable human efforts on optimizing network architectures for stereo matching but hardly achieved both high accuracy and fast inference speed. To ease the workload in network design, neural architecture search (NAS) has been applied with great success to various sparse prediction tasks, such as image classification and object detection. However, existing NAS studies on the dense prediction task, especially stereo matching, still cannot be efficiently and effectively deployed on devices of different computing capabilities. To this end, we propose to train an elastic and accurate network for stereo matching (EASNet) that supports various 3D architectural settings on devices with different computing capabilities. Given the deployment latency constraint on the target device, we can quickly extract a sub-network from the full EASNet without additional training while the accuracy of the sub-network can still be maintained. Extensive experiments show that our EASNet outperforms both state-of-the-art human-designed and NAS-based architectures on Scene Flow and MPI Sintel datasets in terms of model accuracy and inference speed. Particularly, deployed on an inference GPU, EASNet achieves a new SOTA 0.73 EPE on the Scene Flow dataset with 100 ms, which is 4.5$\times$ faster than LEAStereo with a better quality model.
Scalable K-FAC Training for Deep Neural Networks with Distributed Preconditioning
Jun 30, 2022

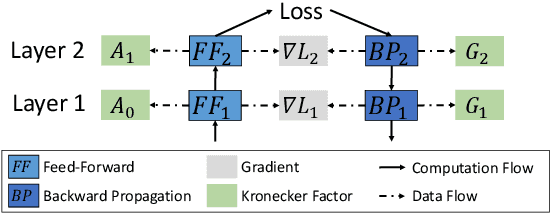
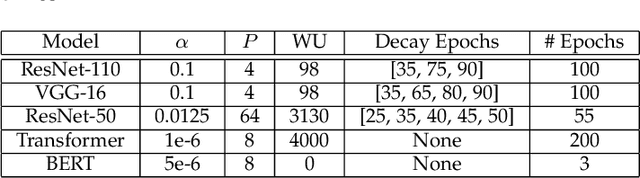
The second-order optimization methods, notably the D-KFAC (Distributed Kronecker Factored Approximate Curvature) algorithms, have gained traction on accelerating deep neural network (DNN) training on GPU clusters. However, existing D-KFAC algorithms require to compute and communicate a large volume of second-order information, i.e., Kronecker factors (KFs), before preconditioning gradients, resulting in large computation and communication overheads as well as a high memory footprint. In this paper, we propose DP-KFAC, a novel distributed preconditioning scheme that distributes the KF constructing tasks at different DNN layers to different workers. DP-KFAC not only retains the convergence property of the existing D-KFAC algorithms but also enables three benefits: reduced computation overhead in constructing KFs, no communication of KFs, and low memory footprint. Extensive experiments on a 64-GPU cluster show that DP-KFAC reduces the computation overhead by 1.55x-1.65x, the communication cost by 2.79x-3.15x, and the memory footprint by 1.14x-1.47x in each second-order update compared to the state-of-the-art D-KFAC methods.
Virtual Homogeneity Learning: Defending against Data Heterogeneity in Federated Learning
Jun 06, 2022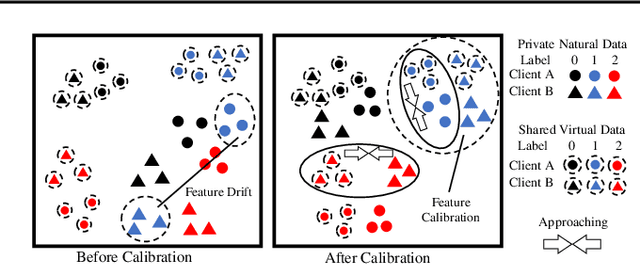
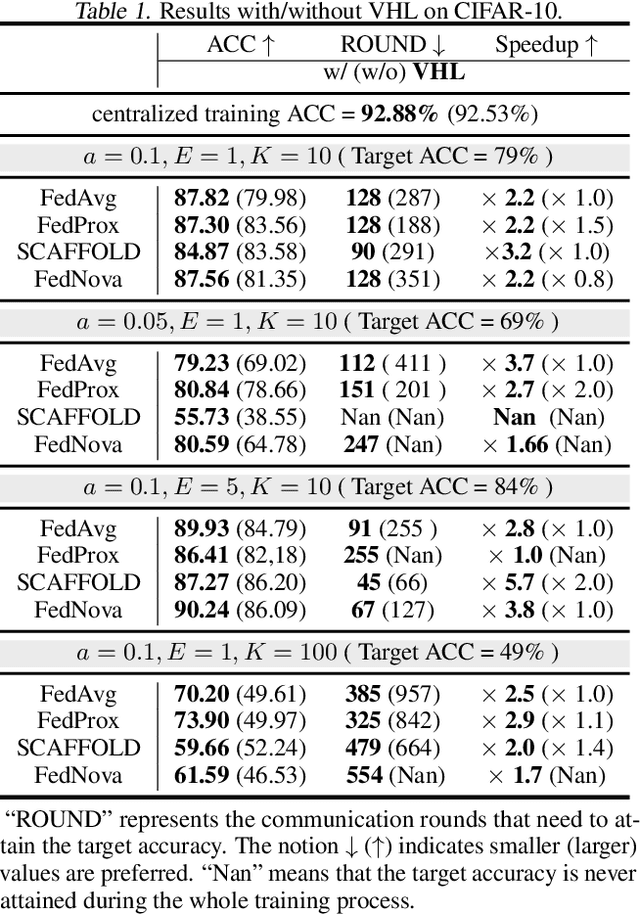
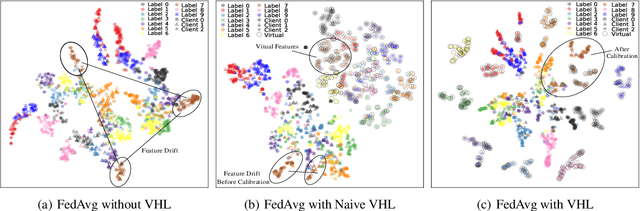
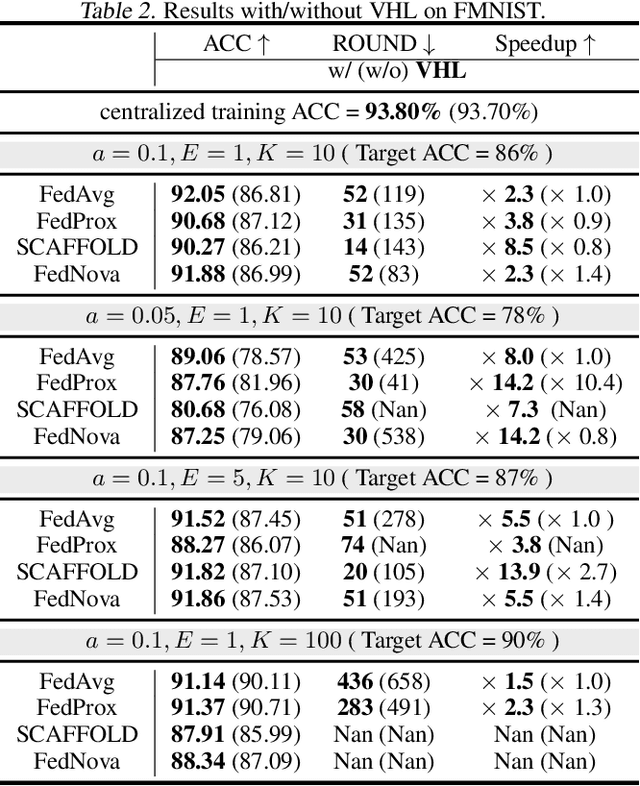
In federated learning (FL), model performance typically suffers from client drift induced by data heterogeneity, and mainstream works focus on correcting client drift. We propose a different approach named virtual homogeneity learning (VHL) to directly "rectify" the data heterogeneity. In particular, VHL conducts FL with a virtual homogeneous dataset crafted to satisfy two conditions: containing no private information and being separable. The virtual dataset can be generated from pure noise shared across clients, aiming to calibrate the features from the heterogeneous clients. Theoretically, we prove that VHL can achieve provable generalization performance on the natural distribution. Empirically, we demonstrate that VHL endows FL with drastically improved convergence speed and generalization performance. VHL is the first attempt towards using a virtual dataset to address data heterogeneity, offering new and effective means to FL.
Nebula-I: A General Framework for Collaboratively Training Deep Learning Models on Low-Bandwidth Cloud Clusters
May 19, 2022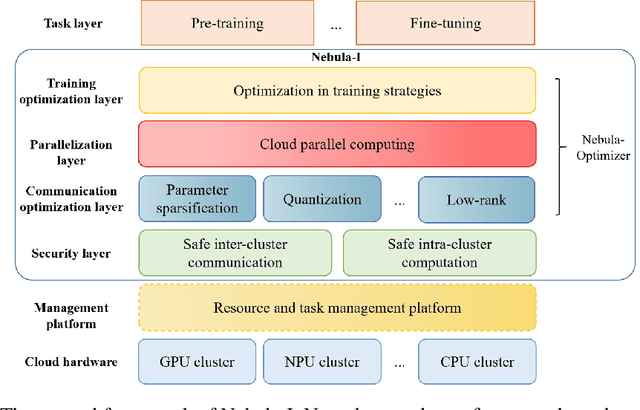
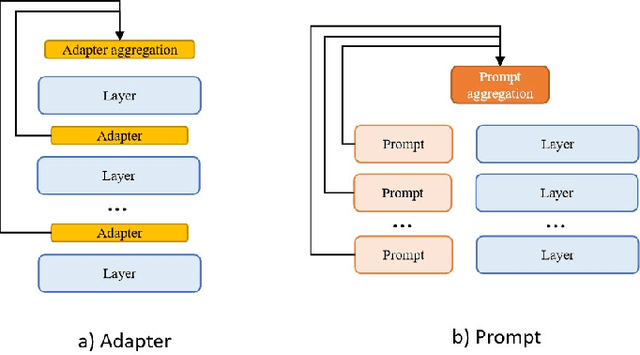
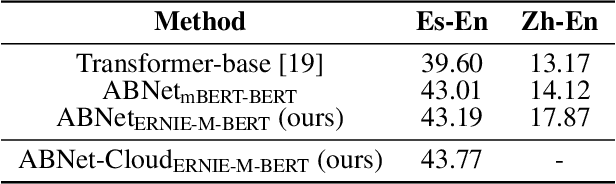
The ever-growing model size and scale of compute have attracted increasing interests in training deep learning models over multiple nodes. However, when it comes to training on cloud clusters, especially across remote clusters, huge challenges are faced. In this work, we introduce a general framework, Nebula-I, for collaboratively training deep learning models over remote heterogeneous clusters, the connections between which are low-bandwidth wide area networks (WANs). We took natural language processing (NLP) as an example to show how Nebula-I works in different training phases that include: a) pre-training a multilingual language model using two remote clusters; and b) fine-tuning a machine translation model using knowledge distilled from pre-trained models, which run through the most popular paradigm of recent deep learning. To balance the accuracy and communication efficiency, in Nebula-I, parameter-efficient training strategies, hybrid parallel computing methods and adaptive communication acceleration techniques are jointly applied. Meanwhile, security strategies are employed to guarantee the safety, reliability and privacy in intra-cluster computation and inter-cluster communication. Nebula-I is implemented with the PaddlePaddle deep learning framework, which can support collaborative training over heterogeneous hardware, e.g. GPU and NPU. Experiments demonstrate that the proposed framework could substantially maximize the training efficiency while preserving satisfactory NLP performance. By using Nebula-I, users can run large-scale training tasks over cloud clusters with minimum developments, and the utility of existed large pre-trained models could be further promoted. We also introduced new state-of-the-art results on cross-lingual natural language inference tasks, which are generated based upon a novel learning framework and Nebula-I.