 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGuiding a Diffusion Model by Swapping Its Tokens
Apr 09, 2026Classifier-Free Guidance (CFG) is a widely used inference-time technique to boost the image quality of diffusion models. Yet, its reliance on text conditions prevents its use in unconditional generation. We propose a simple method to enable CFG-like guidance for both conditional and unconditional generation. The key idea is to generate a perturbed prediction via simple token swap operations, and use the direction between it and the clean prediction to steer sampling towards higher-fidelity distributions. In practice, we swap pairs of most semantically dissimilar token latents in either spatial or channel dimensions. Unlike existing methods that apply perturbation in a global or less constrained manner, our approach selectively exchanges and recomposes token latents, allowing finer control over perturbation and its influence on generated samples. Experiments on MS-COCO 2014, MS-COCO 2017, and ImageNet datasets demonstrate that the proposed Self-Swap Guidance (SSG), when applied to popular diffusion models, outperforms previous condition-free methods in image fidelity and prompt alignment under different set-ups. Its fine-grained perturbation granularity also improves robustness, reducing side-effects across a wider range of perturbation strengths. Overall, SSG extends CFG to a broader scope of applications including both conditional and unconditional generation, and can be readily inserted into any diffusion model as a plug-in to gain immediate improvements.
Cross-Architecture Distillation Made Simple with Redundancy Suppression
Jul 29, 2025We describe a simple method for cross-architecture knowledge distillation, where the knowledge transfer is cast into a redundant information suppression formulation. Existing methods introduce sophisticated modules, architecture-tailored designs, and excessive parameters, which impair their efficiency and applicability. We propose to extract the architecture-agnostic knowledge in heterogeneous representations by reducing the redundant architecture-exclusive information. To this end, we present a simple redundancy suppression distillation (RSD) loss, which comprises cross-architecture invariance maximisation and feature decorrelation objectives. To prevent the student from entirely losing its architecture-specific capabilities, we further design a lightweight module that decouples the RSD objective from the student's internal representations. Our method is devoid of the architecture-specific designs and complex operations in the pioneering method of OFA. It outperforms OFA on CIFAR-100 and ImageNet-1k benchmarks with only a fraction of their parameter overhead, which highlights its potential as a simple and strong baseline to the cross-architecture distillation community.
Harnessing Joint Rain-/Detail-aware Representations to Eliminate Intricate Rains
Apr 18, 2024



Recent advances in image deraining have focused on training powerful models on mixed multiple datasets comprising diverse rain types and backgrounds. However, this approach tends to overlook the inherent differences among rainy images, leading to suboptimal results. To overcome this limitation, we focus on addressing various rainy images by delving into meaningful representations that encapsulate both the rain and background components. Leveraging these representations as instructive guidance, we put forth a Context-based Instance-level Modulation (CoI-M) mechanism adept at efficiently modulating CNN- or Transformer-based models. Furthermore, we devise a rain-/detail-aware contrastive learning strategy to help extract joint rain-/detail-aware representations. By integrating CoI-M with the rain-/detail-aware Contrastive learning, we develop CoIC, an innovative and potent algorithm tailored for training models on mixed datasets. Moreover, CoIC offers insight into modeling relationships of datasets, quantitatively assessing the impact of rain and details on restoration, and unveiling distinct behaviors of models given diverse inputs. Extensive experiments validate the efficacy of CoIC in boosting the deraining ability of CNN and Transformer models. CoIC also enhances the deraining prowess remarkably when real-world dataset is included.
* 21 pages, 14 figures
TRNR: Task-Driven Image Rain and Noise Removal with a Few Images Based on Patch Analysis
Dec 03, 2021

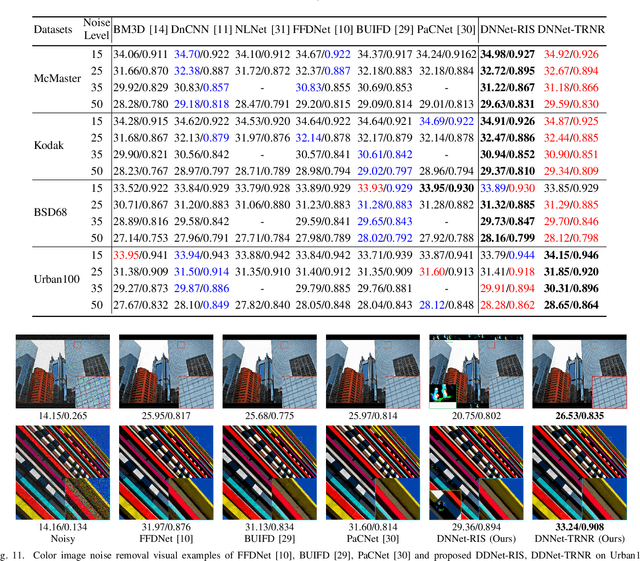

The recent prosperity of learning-based image rain and noise removal is mainly due to the well-designed neural network architectures and large labeled datasets. However, we find that current image rain and noise removal methods result in low utilization of images. To alleviate the reliance on large labeled datasets, we propose the task-driven image rain and noise removal (TRNR) based on the introduced patch analysis strategy. The patch analysis strategy provides image patches with various spatial and statistical properties for training and has been verified to increase the utilization of images. Further, the patch analysis strategy motivates us to consider learning image rain and noise removal task-driven instead of data-driven. Therefore we introduce the N-frequency-K-shot learning task for TRNR. Each N-frequency-K-shot learning task is based on a tiny dataset containing NK image patches sampled by the patch analysis strategy. TRNR enables neural networks to learn from abundant N-frequency-K-shot learning tasks other than from adequate data. To verify the effectiveness of TRNR, we build a light Multi-Scale Residual Network (MSResNet) with about 0.9M parameters to learn image rain removal and use a simple ResNet with about 1.2M parameters dubbed DNNet for blind gaussian noise removal with a few images (for example, 20.0% train-set of Rain100H). Experimental results demonstrate that TRNR enables MSResNet to learn better from fewer images. In addition, MSResNet and DNNet utilizing TRNR have obtained better performance than most recent deep learning methods trained data-driven on large labeled datasets. These experimental results have confirmed the effectiveness and superiority of the proposed TRNR. The codes of TRNR will be public soon.