 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint Device Activity Detection, Channel Estimation and Signal Detection for Massive Grant-free Access via BiGAMP
Apr 03, 2023



Massive access has been challenging for the fifth generation (5G) and beyond since the abundance of devices causes communication overload to skyrocket. In an uplink massive access scenario, device traffic is sporadic in any given coherence time. Thus, channels across the antennas of each device exhibit correlation, which can be characterized by the row sparse channel matrix structure. In this work, we develop a bilinear generalized approximate message passing (BiGAMP) algorithm based on the row sparse channel matrix structure. This algorithm can jointly detect device activities, estimate channels, and detect signals in massive multiple-input multiple-output (MIMO) systems by alternating updates between channel matrices and signal matrices. The signal observation provides additional information for performance improvement compared to the existing algorithms. We further analyze state evolution (SE) to measure the performance of the proposed algorithm and characterize the convergence condition for SE. Moreover, we perform theoretical analysis on the error probability of device activity detection, the mean square error of channel estimation, and the symbol error rate of signal detection. The numerical results demonstrate the superiority of the proposed algorithm over the state-of-the-art methods in DADCE-SD, and the numerical results are relatively close to the theoretical analysis results.
Grouped Adaptive Loss Weighting for Person Search
Sep 23, 2022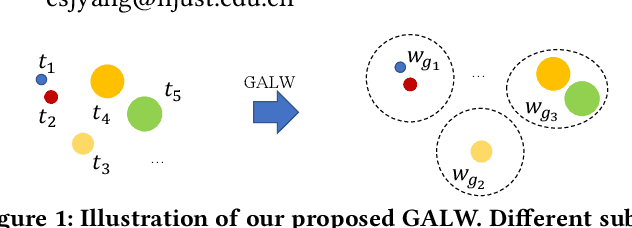
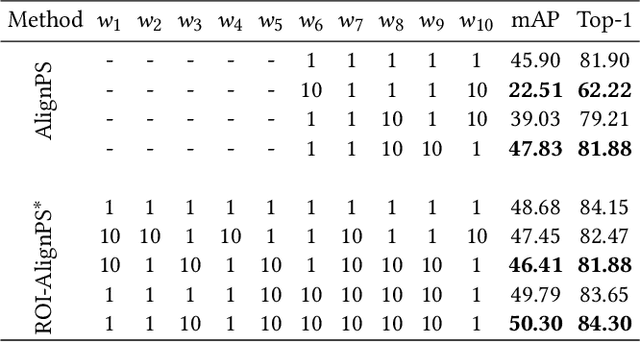
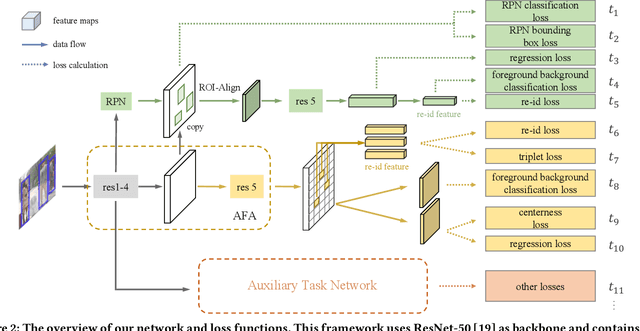
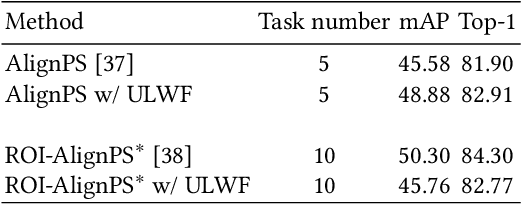
Person search is an integrated task of multiple sub-tasks such as foreground/background classification, bounding box regression and person re-identification. Therefore, person search is a typical multi-task learning problem, especially when solved in an end-to-end manner. Recently, some works enhance person search features by exploiting various auxiliary information, e.g. person joint keypoints, body part position, attributes, etc., which brings in more tasks and further complexifies a person search model. The inconsistent convergence rate of each task could potentially harm the model optimization. A straightforward solution is to manually assign different weights to different tasks, compensating for the diverse convergence rates. However, given the special case of person search, i.e. with a large number of tasks, it is impractical to weight the tasks manually. To this end, we propose a Grouped Adaptive Loss Weighting (GALW) method which adjusts the weight of each task automatically and dynamically. Specifically, we group tasks according to their convergence rates. Tasks within the same group share the same learnable weight, which is dynamically assigned by considering the loss uncertainty. Experimental results on two typical benchmarks, CUHK-SYSU and PRW, demonstrate the effectiveness of our method.
Learning Audio-Visual embedding for Wild Person Verification
Sep 09, 2022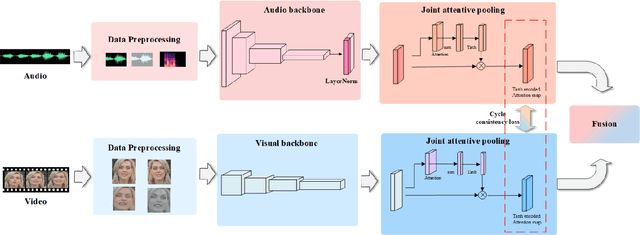
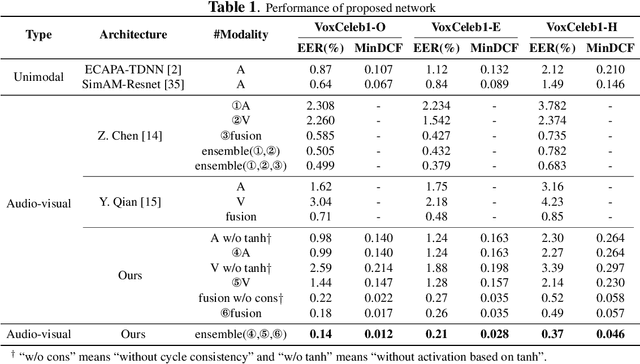
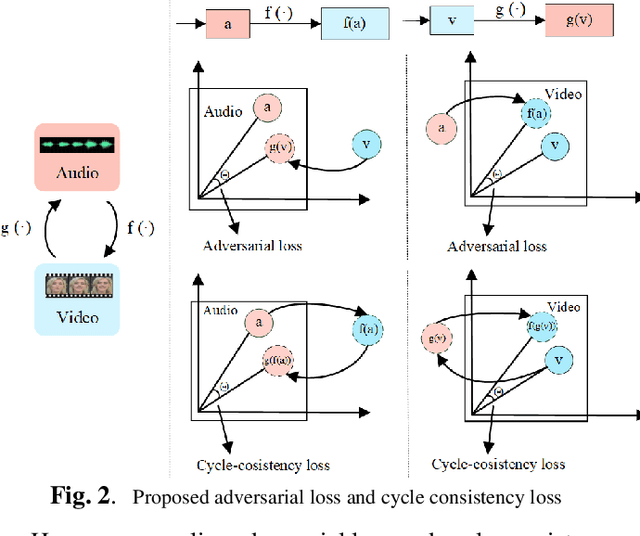
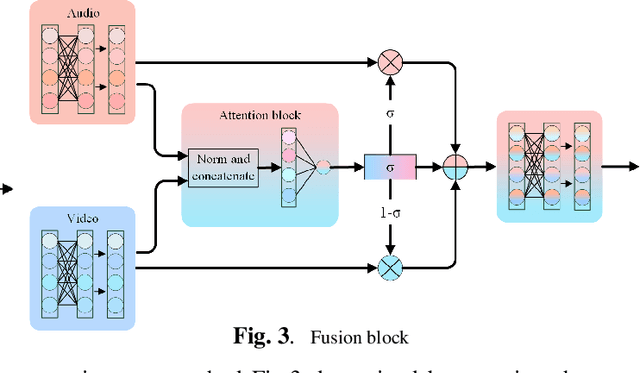
It has already been observed that audio-visual embedding can be extracted from these two modalities to gain robustness for person verification. However, the aggregator that used to generate a single utterance representation from each frame does not seem to be well explored. In this article, we proposed an audio-visual network that considers aggregator from a fusion perspective. We introduced improved attentive statistics pooling for the first time in face verification. Then we find that strong correlation exists between modalities during pooling, so joint attentive pooling is proposed which contains cycle consistency to learn the implicit inter-frame weight. Finally, fuse the modality with a gated attention mechanism. All the proposed models are trained on the VoxCeleb2 dev dataset and the best system obtains 0.18\%, 0.27\%, and 0.49\% EER on three official trail lists of VoxCeleb1 respectively, which is to our knowledge the best-published results for person verification. As an analysis, visualization maps are generated to explain how this system interact between modalities.
DTG-SSOD: Dense Teacher Guidance for Semi-Supervised Object Detection
Jul 12, 2022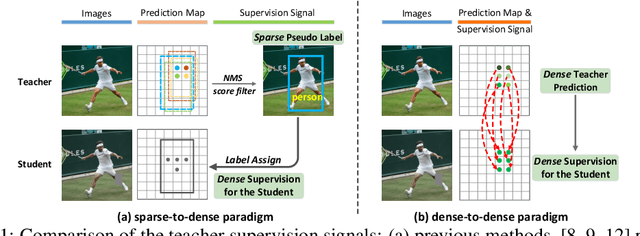
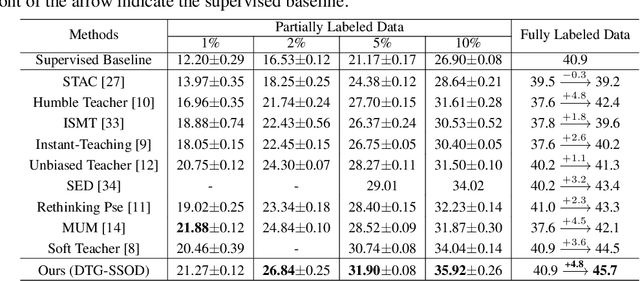
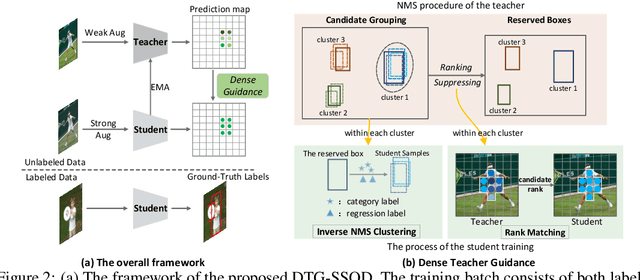
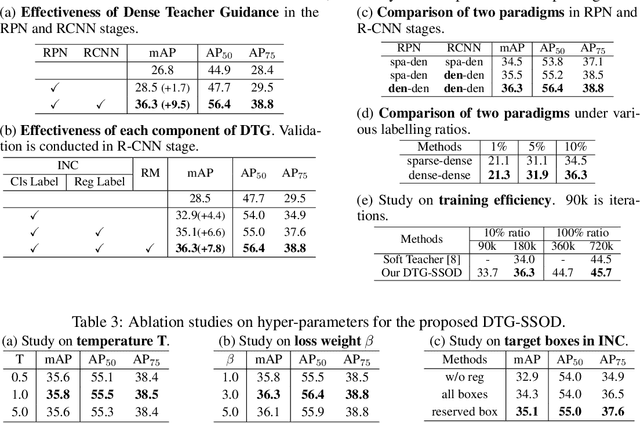
The Mean-Teacher (MT) scheme is widely adopted in semi-supervised object detection (SSOD). In MT, the sparse pseudo labels, offered by the final predictions of the teacher (e.g., after Non Maximum Suppression (NMS) post-processing), are adopted for the dense supervision for the student via hand-crafted label assignment. However, the sparse-to-dense paradigm complicates the pipeline of SSOD, and simultaneously neglects the powerful direct, dense teacher supervision. In this paper, we attempt to directly leverage the dense guidance of teacher to supervise student training, i.e., the dense-to-dense paradigm. Specifically, we propose the Inverse NMS Clustering (INC) and Rank Matching (RM) to instantiate the dense supervision, without the widely used, conventional sparse pseudo labels. INC leads the student to group candidate boxes into clusters in NMS as the teacher does, which is implemented by learning grouping information revealed in NMS procedure of the teacher. After obtaining the same grouping scheme as the teacher via INC, the student further imitates the rank distribution of the teacher over clustered candidates through Rank Matching. With the proposed INC and RM, we integrate Dense Teacher Guidance into Semi-Supervised Object Detection (termed DTG-SSOD), successfully abandoning sparse pseudo labels and enabling more informative learning on unlabeled data. On COCO benchmark, our DTG-SSOD achieves state-of-the-art performance under various labelling ratios. For example, under 10% labelling ratio, DTG-SSOD improves the supervised baseline from 26.9 to 35.9 mAP, outperforming the previous best method Soft Teacher by 1.9 points.
Bi-level Alignment for Cross-Domain Crowd Counting
May 12, 2022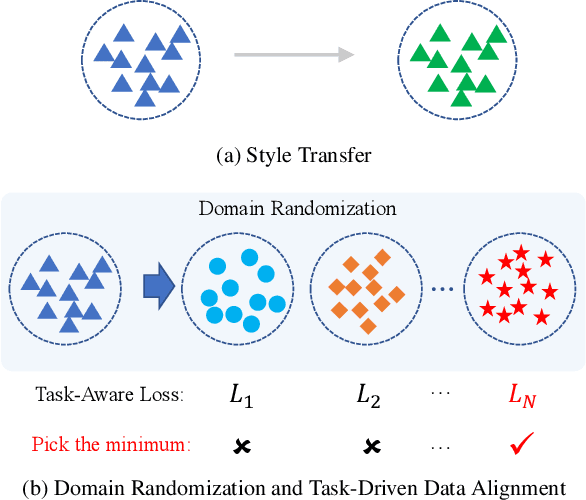

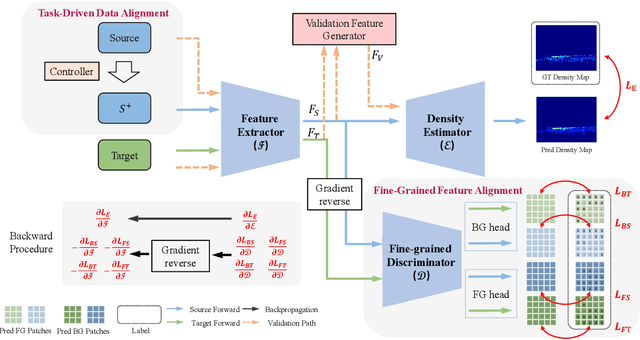
Recently, crowd density estimation has received increasing attention. The main challenge for this task is to achieve high-quality manual annotations on a large amount of training data. To avoid reliance on such annotations, previous works apply unsupervised domain adaptation (UDA) techniques by transferring knowledge learned from easily accessible synthetic data to real-world datasets. However, current state-of-the-art methods either rely on external data for training an auxiliary task or apply an expensive coarse-to-fine estimation. In this work, we aim to develop a new adversarial learning based method, which is simple and efficient to apply. To reduce the domain gap between the synthetic and real data, we design a bi-level alignment framework (BLA) consisting of (1) task-driven data alignment and (2) fine-grained feature alignment. In contrast to previous domain augmentation methods, we introduce AutoML to search for an optimal transform on source, which well serves for the downstream task. On the other hand, we do fine-grained alignment for foreground and background separately to alleviate the alignment difficulty. We evaluate our approach on five real-world crowd counting benchmarks, where we outperform existing approaches by a large margin. Also, our approach is simple, easy to implement and efficient to apply. The code is publicly available at https://github.com/Yankeegsj/BLA.
PseCo: Pseudo Labeling and Consistency Training for Semi-Supervised Object Detection
Mar 30, 2022
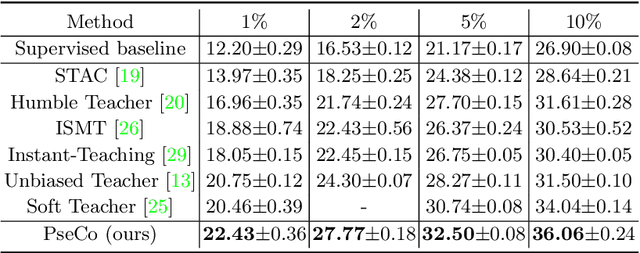
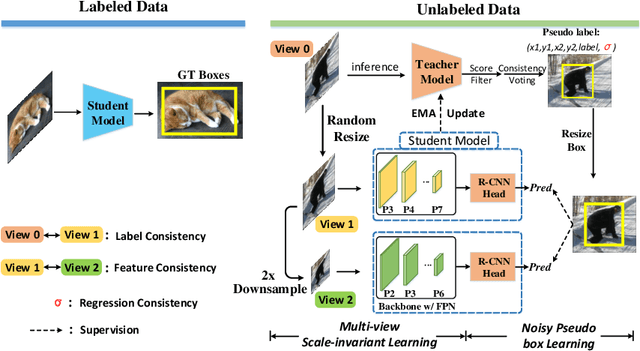
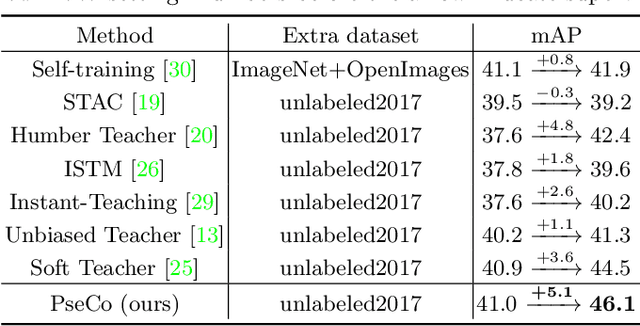
In this paper, we delve into two key techniques in Semi-Supervised Object Detection (SSOD), namely pseudo labeling and consistency training. We observe that these two techniques currently neglect some important properties of object detection, hindering efficient learning on unlabeled data. Specifically, for pseudo labeling, existing works only focus on the classification score yet fail to guarantee the localization precision of pseudo boxes; For consistency training, the widely adopted random-resize training only considers the label-level consistency but misses the feature-level one, which also plays an important role in ensuring the scale invariance. To address the problems incurred by noisy pseudo boxes, we design Noisy Pseudo box Learning (NPL) that includes Prediction-guided Label Assignment (PLA) and Positive-proposal Consistency Voting (PCV). PLA relies on model predictions to assign labels and makes it robust to even coarse pseudo boxes; while PCV leverages the regression consistency of positive proposals to reflect the localization quality of pseudo boxes. Furthermore, in consistency training, we propose Multi-view Scale-invariant Learning (MSL) that includes mechanisms of both label- and feature-level consistency, where feature consistency is achieved by aligning shifted feature pyramids between two images with identical content but varied scales. On COCO benchmark, our method, termed PSEudo labeling and COnsistency training (PseCo), outperforms the SOTA (Soft Teacher) by 2.0, 1.8, 2.0 points under 1%, 5%, and 10% labelling ratios, respectively. It also significantly improves the learning efficiency for SSOD, e.g., PseCo halves the training time of the SOTA approach but achieves even better performance.
MFA-Conformer: Multi-scale Feature Aggregation Conformer for Automatic Speaker Verification
Mar 29, 2022
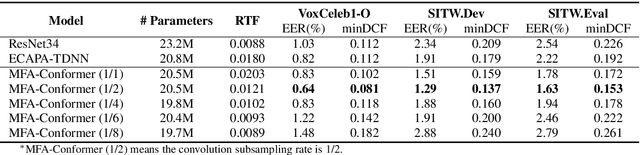
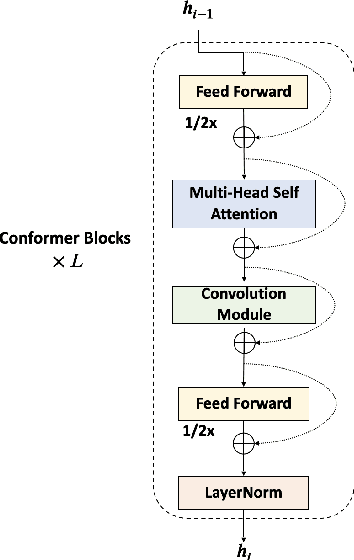
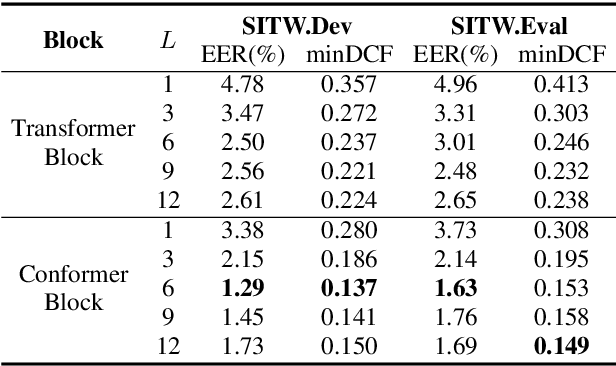
In this paper, we present Multi-scale Feature Aggregation Conformer (MFA-Conformer), an easy-to-implement, simple but effective backbone for automatic speaker verification based on the Convolution-augmented Transformer (Conformer). The architecture of the MFA-Conformer is inspired by recent state-of-the-art models in speech recognition and speaker verification. Firstly, we introduce a convolution sub-sampling layer to decrease the computational cost of the model. Secondly, we adopt Conformer blocks which combine Transformers and convolution neural networks (CNNs) to capture global and local features effectively. Finally, the output feature maps from all Conformer blocks are concatenated to aggregate multi-scale representations before final pooling. We evaluate the MFA-Conformer on the widely used benchmarks. The best system obtains 0.64%, 1.29% and 1.63% EER on VoxCeleb1-O, SITW.Dev, and SITW.Eval set, respectively. MFA-Conformer significantly outperforms the popular ECAPA-TDNN systems in both recognition performance and inference speed. Last but not the least, the ablation studies clearly demonstrate that the combination of global and local feature learning can lead to robust and accurate speaker embedding extraction. We will release the code for future works to do comparison.
Knowledge Distillation for Object Detection via Rank Mimicking and Prediction-guided Feature Imitation
Dec 09, 2021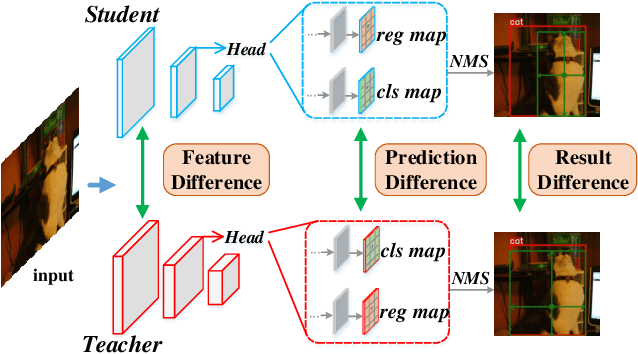
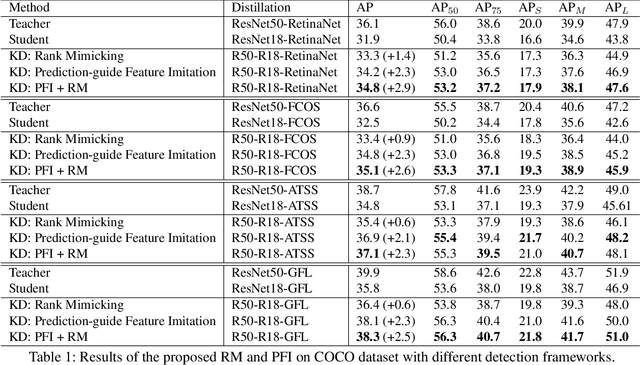
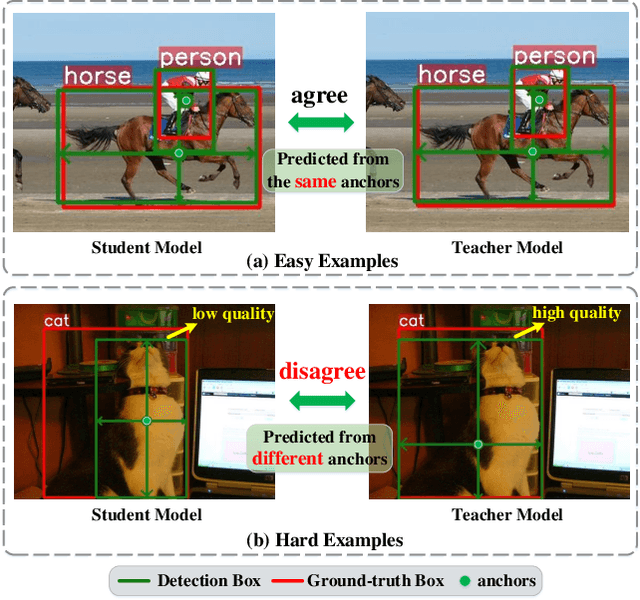
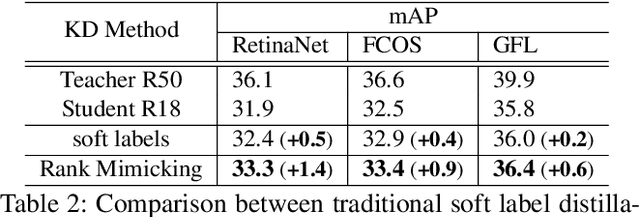
Knowledge Distillation (KD) is a widely-used technology to inherit information from cumbersome teacher models to compact student models, consequently realizing model compression and acceleration. Compared with image classification, object detection is a more complex task, and designing specific KD methods for object detection is non-trivial. In this work, we elaborately study the behaviour difference between the teacher and student detection models, and obtain two intriguing observations: First, the teacher and student rank their detected candidate boxes quite differently, which results in their precision discrepancy. Second, there is a considerable gap between the feature response differences and prediction differences between teacher and student, indicating that equally imitating all the feature maps of the teacher is the sub-optimal choice for improving the student's accuracy. Based on the two observations, we propose Rank Mimicking (RM) and Prediction-guided Feature Imitation (PFI) for distilling one-stage detectors, respectively. RM takes the rank of candidate boxes from teachers as a new form of knowledge to distill, which consistently outperforms the traditional soft label distillation. PFI attempts to correlate feature differences with prediction differences, making feature imitation directly help to improve the student's accuracy. On MS COCO and PASCAL VOC benchmarks, extensive experiments are conducted on various detectors with different backbones to validate the effectiveness of our method. Specifically, RetinaNet with ResNet50 achieves 40.4% mAP in MS COCO, which is 3.5% higher than its baseline, and also outperforms previous KD methods.
Adaptive Group Collaborative Artificial Bee Colony Algorithm
Dec 02, 2021
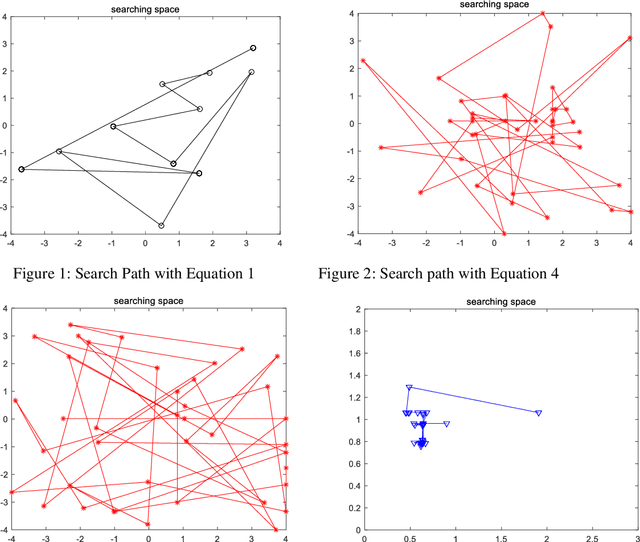
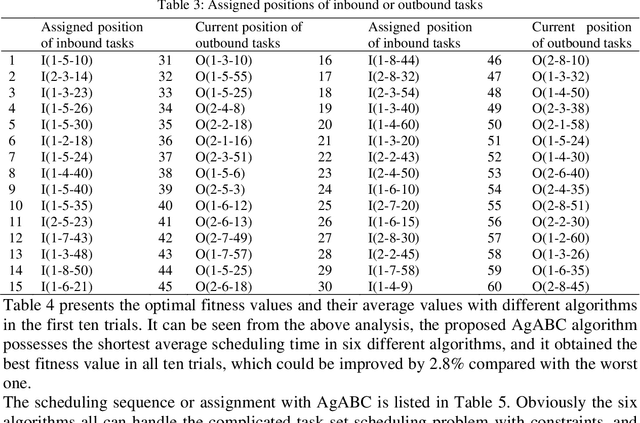
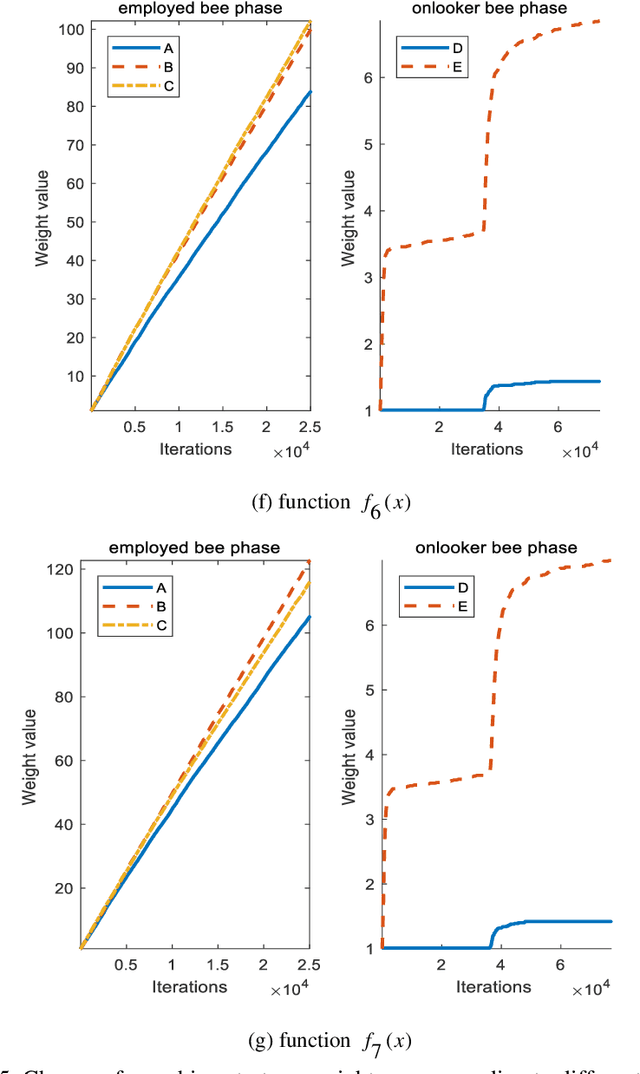
As an effective algorithm for solving complex optimization problems, artificial bee colony (ABC) algorithm has shown to be competitive, but the same as other population-based algorithms, it is poor at balancing the abilities of global searching in the whole solution space (named as exploration) and quick searching in local solution space which is defined as exploitation. For improving the performance of ABC, an adaptive group collaborative ABC (AgABC) algorithm is introduced where the population in different phases is divided to specific groups and different search strategies with different abilities are assigned to the members in groups, and the member or strategy which obtains the best solution will be employed for further searching. Experimental results on benchmark functions show that the proposed algorithm with dynamic mechanism is superior to other algorithms in searching accuracy and stability. Furthermore, numerical experiments show that the proposed method can generate the optimal solution for the complex scheduling problem.
An improved bearing fault detection strategy based on artificial bee colony algorithm
Dec 02, 2021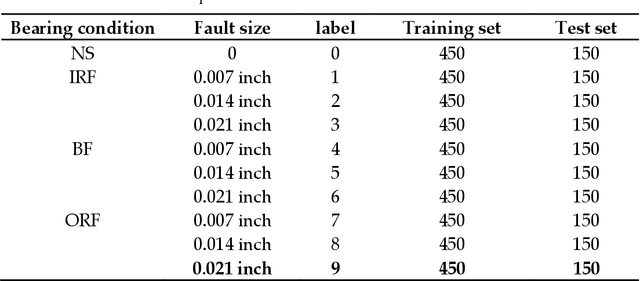

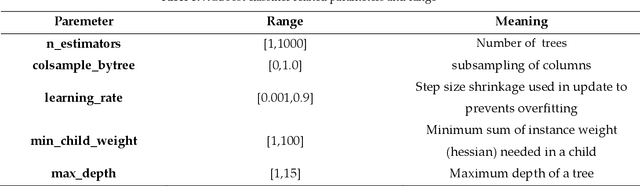
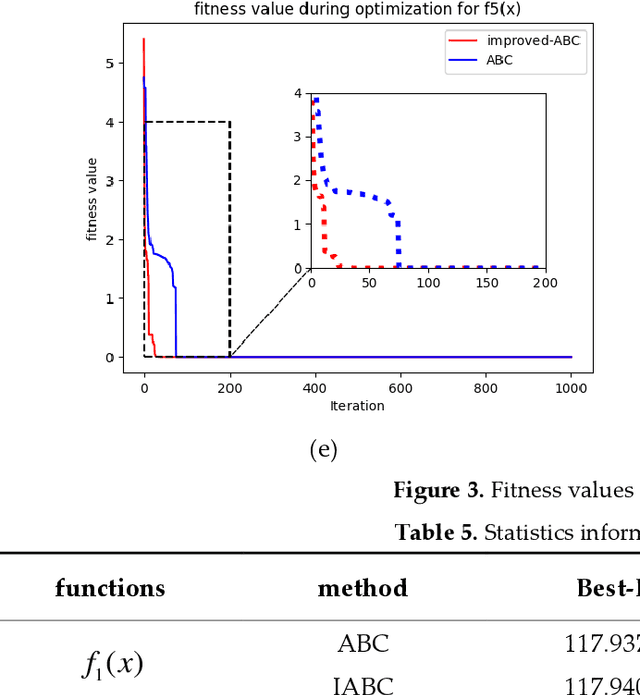
The operating state of bearing directly affects the performance of rotating machinery and how to accurately and decisively extract features from the original vibration signal and recognize the faulty parts as early as possible is very critical. In this study, the one-dimensional ternary model which has been proved to be an effective statistical method in feature selection is introduced and shapelets transformation is proposed to calculate the parameter of it which is also the standard deviation of the transformed shaplets that is usually selected by trial and error. Moreover, XGBoost is used to recognize the faults from the obtained features, and an improved artificial bee colony algorithm(ABC) where the evolution is guided by the importance indices of different search space is proposed to optimize the parameters of XGBoost. Here the value of importance index is related to the probability of optimal solutions in certain space, thus the problem of easily falling into local optimality in traditional ABC could be avoided.The experimental results based on the failure vibration signal samples show that the average accuracy of fault signal recognition can reach 97% which is much higher than the ones corresponding to other extraction strategies, thus the ability of extraction could be improved. And with the improved artificial bee colony algorithm which is used to optimize the parameters of XGBoost, the classification accuracy could be improved from 97.02% to about 98.60% compared with the traditional classification strategy