 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvA: An Evidence-First Audio Understanding Paradigm for LALMs
Mar 29, 2026Large Audio Language Models (LALMs) still struggle in complex acoustic scenes because they often fail to preserve task-relevant acoustic evidence before reasoning begins. We call this failure the evidence bottleneck: state-of-the-art systems show larger deficits in evidence extraction than in downstream reasoning, suggesting that the main limitation lies in upstream perception rather than reasoning policy. To address this problem, we propose EvA (Evidence-First Audio), a dual-path architecture that combines Whisper and CED-Base through non-compressive, time-aligned fusion. EvA first aggregates intermediate CED layers to preserve multi-scale acoustic cues, then aligns the aggregated CED features to the Whisper timeline and adds the two streams without changing sequence length. We also build EvA-Perception, a large-scale open-source training set with about 54K event-ordered captions (150 h) and about 500K QA pairs. Under a unified zero-shot protocol, EvA achieves the best open-source Perception scores on MMAU, MMAR, and MMSU, and improves over Kimi-Audio-7B on all reported metrics, with the largest gains on perception-heavy splits. These results support the evidence-first hypothesis: stronger audio understanding depends on preserving acoustic evidence before reasoning.
FISHER: A Foundation Model for Multi-Modal Industrial Signal Comprehensive Representation
Jul 22, 2025With the rapid deployment of SCADA systems, how to effectively analyze industrial signals and detect abnormal states is an urgent need for the industry. Due to the significant heterogeneity of these signals, which we summarize as the M5 problem, previous works only focus on small sub-problems and employ specialized models, failing to utilize the synergies between modalities and the powerful scaling law. However, we argue that the M5 signals can be modeled in a unified manner due to the intrinsic similarity. As a result, we propose FISHER, a Foundation model for multi-modal Industrial Signal compreHEnsive Representation. To support arbitrary sampling rates, FISHER considers the increment of sampling rate as the concatenation of sub-band information. Specifically, FISHER takes the STFT sub-band as the modeling unit and adopts a teacher student SSL framework for pre-training. We also develop the RMIS benchmark, which evaluates the representations of M5 industrial signals on multiple health management tasks. Compared with top SSL models, FISHER showcases versatile and outstanding capabilities with a general performance gain up to 5.03%, along with much more efficient scaling curves. We also investigate the scaling law on downstream tasks and derive potential avenues for future works. FISHER is now open-sourced on https://github.com/jianganbai/FISHER
AnoPatch: Towards Better Consistency in Machine Anomalous Sound Detection
Jun 17, 2024



Large pre-trained models have demonstrated dominant performances in multiple areas, where the consistency between pre-training and fine-tuning is the key to success. However, few works reported satisfactory results of pre-trained models for the machine anomalous sound detection (ASD) task. This may be caused by the inconsistency of the pre-trained model and the inductive bias of machine audio, resulting in inconsistency in data and architecture. Thus, we propose AnoPatch which utilizes a ViT backbone pre-trained on AudioSet and fine-tunes it on machine audio. It is believed that machine audio is more related to audio datasets than speech datasets, and modeling it from patch level suits the sparsity of machine audio. As a result, AnoPatch showcases state-of-the-art (SOTA) performances on the DCASE 2020 ASD dataset and the DCASE 2023 ASD dataset. We also compare multiple pre-trained models and empirically demonstrate that better consistency yields considerable improvement.
MFA-Conformer: Multi-scale Feature Aggregation Conformer for Automatic Speaker Verification
Mar 29, 2022
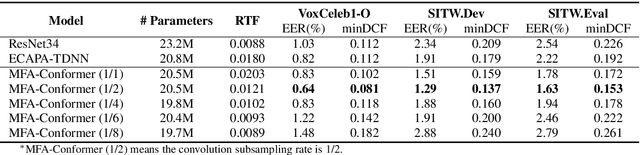
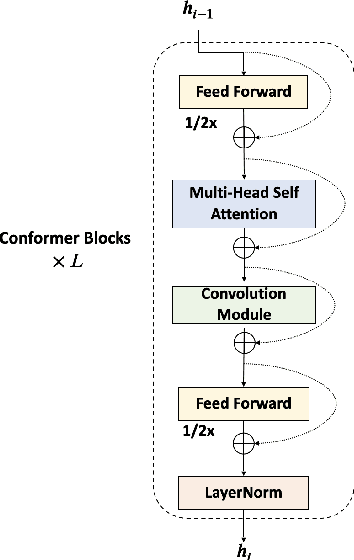
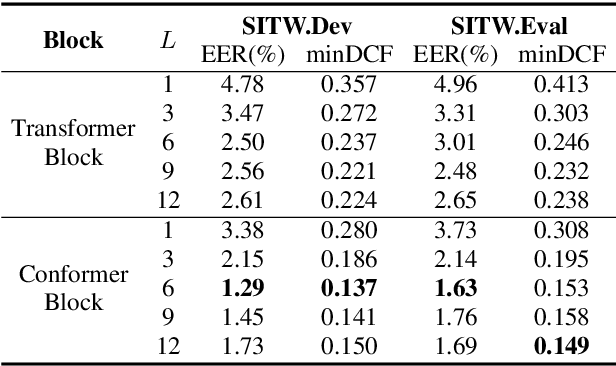
In this paper, we present Multi-scale Feature Aggregation Conformer (MFA-Conformer), an easy-to-implement, simple but effective backbone for automatic speaker verification based on the Convolution-augmented Transformer (Conformer). The architecture of the MFA-Conformer is inspired by recent state-of-the-art models in speech recognition and speaker verification. Firstly, we introduce a convolution sub-sampling layer to decrease the computational cost of the model. Secondly, we adopt Conformer blocks which combine Transformers and convolution neural networks (CNNs) to capture global and local features effectively. Finally, the output feature maps from all Conformer blocks are concatenated to aggregate multi-scale representations before final pooling. We evaluate the MFA-Conformer on the widely used benchmarks. The best system obtains 0.64%, 1.29% and 1.63% EER on VoxCeleb1-O, SITW.Dev, and SITW.Eval set, respectively. MFA-Conformer significantly outperforms the popular ECAPA-TDNN systems in both recognition performance and inference speed. Last but not the least, the ablation studies clearly demonstrate that the combination of global and local feature learning can lead to robust and accurate speaker embedding extraction. We will release the code for future works to do comparison.
VRM-Phase I VKW system description of long-short video customizable keyword wakeup challenge
Oct 18, 2021Keyword wakeup technology has always been a research hotspot in speech processing, but many related works were done on different datasets. We organized a Chinese long-short video keyword wakeup challenge (Video Keyword Wakeup Challenge, VKW) for testing the ability of each participating team to build a keyword wakeup system under the public dataset. All submitted systems not only need to support the setting of multiple different keywords, but also need to support the wakeup of any costumed keyword.This paper mainly describes the basic situation of the VKW challenge and the experimental results of some participating teams.