 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntroducing Semantics into Speech Encoders
Nov 15, 2022



Recent studies find existing self-supervised speech encoders contain primarily acoustic rather than semantic information. As a result, pipelined supervised automatic speech recognition (ASR) to large language model (LLM) systems achieve state-of-the-art results on semantic spoken language tasks by utilizing rich semantic representations from the LLM. These systems come at the cost of labeled audio transcriptions, which is expensive and time-consuming to obtain. We propose a task-agnostic unsupervised way of incorporating semantic information from LLMs into self-supervised speech encoders without labeled audio transcriptions. By introducing semantics, we improve existing speech encoder spoken language understanding performance by over 10\% on intent classification, with modest gains in named entity resolution and slot filling, and spoken question answering FF1 score by over 2\%. Our unsupervised approach achieves similar performance as supervised methods trained on over 100 hours of labeled audio transcripts, demonstrating the feasibility of unsupervised semantic augmentations to existing speech encoders.
SUPERB @ SLT 2022: Challenge on Generalization and Efficiency of Self-Supervised Speech Representation Learning
Oct 16, 2022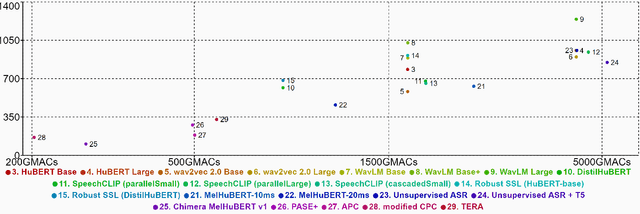
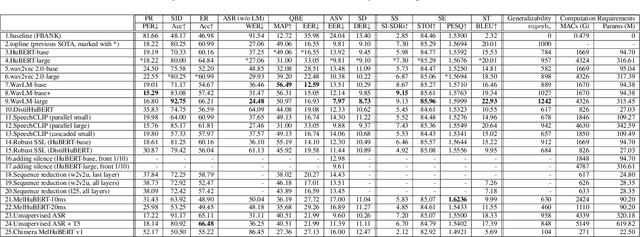
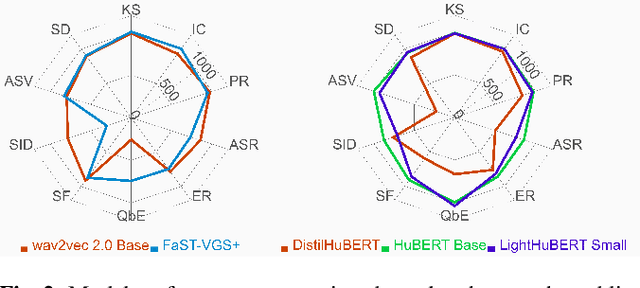
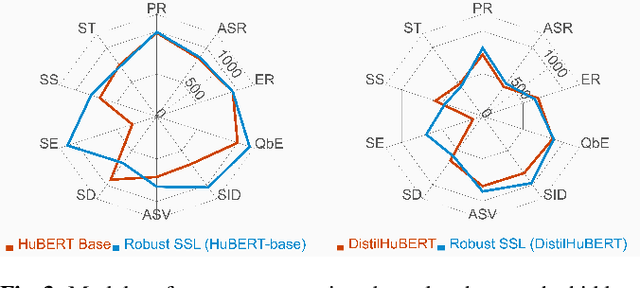
We present the SUPERB challenge at SLT 2022, which aims at learning self-supervised speech representation for better performance, generalization, and efficiency. The challenge builds upon the SUPERB benchmark and implements metrics to measure the computation requirements of self-supervised learning (SSL) representation and to evaluate its generalizability and performance across the diverse SUPERB tasks. The SUPERB benchmark provides comprehensive coverage of popular speech processing tasks, from speech and speaker recognition to audio generation and semantic understanding. As SSL has gained interest in the speech community and showed promising outcomes, we envision the challenge to uplevel the impact of SSL techniques by motivating more practical designs of techniques beyond task performance. We summarize the results of 14 submitted models in this paper. We also discuss the main findings from those submissions and the future directions of SSL research.
Exploring Efficient-tuning Methods in Self-supervised Speech Models
Oct 10, 2022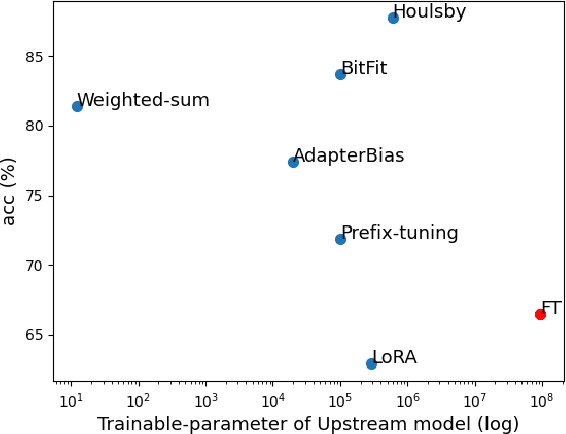
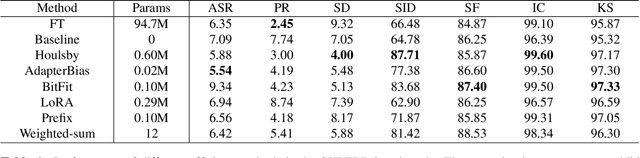
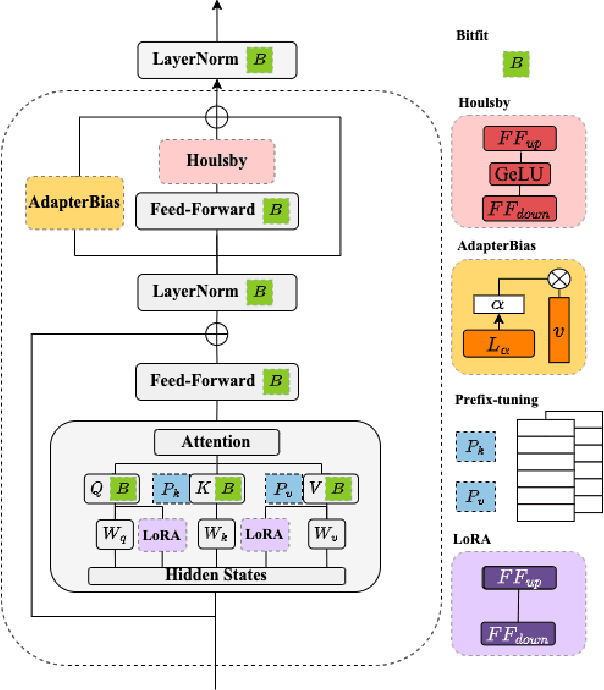
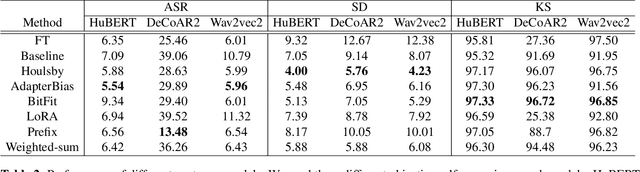
In this study, we aim to explore efficient tuning methods for speech self-supervised learning. Recent studies show that self-supervised learning (SSL) can learn powerful representations for different speech tasks. However, fine-tuning pre-trained models for each downstream task is parameter-inefficient since SSL models are notoriously large with millions of parameters. Adapters are lightweight modules commonly used in NLP to solve this problem. In downstream tasks, the parameters of SSL models are frozen, and only the adapters are trained. Given the lack of studies generally exploring the effectiveness of adapters for self-supervised speech tasks, we intend to fill this gap by adding various adapter modules in pre-trained speech SSL models. We show that the performance parity can be achieved with over 90% parameter reduction, and discussed the pros and cons of efficient tuning techniques. This is the first comprehensive investigation of various adapter types across speech tasks.
Self-Supervised Speech Representation Learning: A Review
May 21, 2022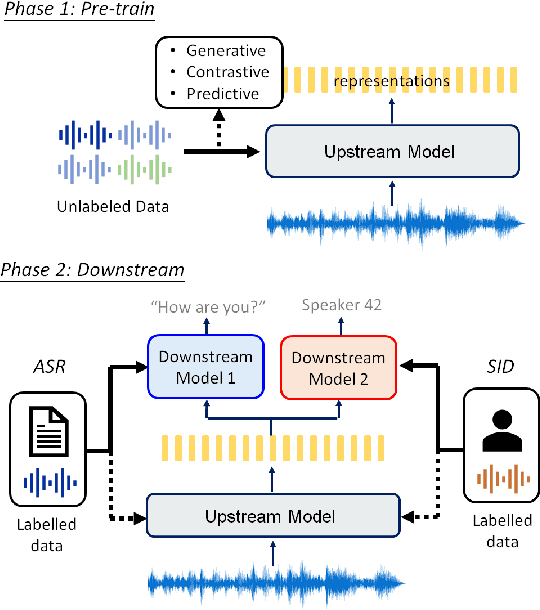
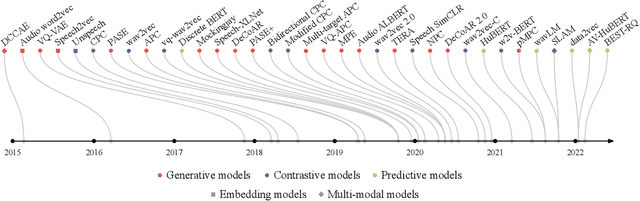
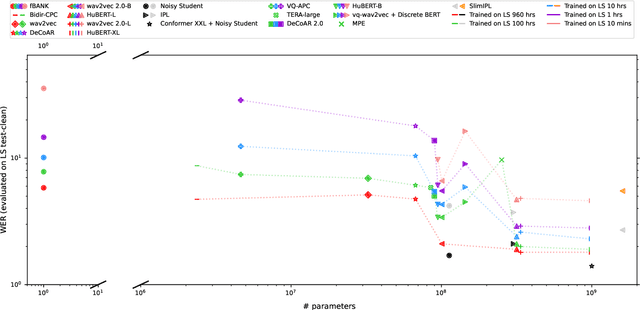
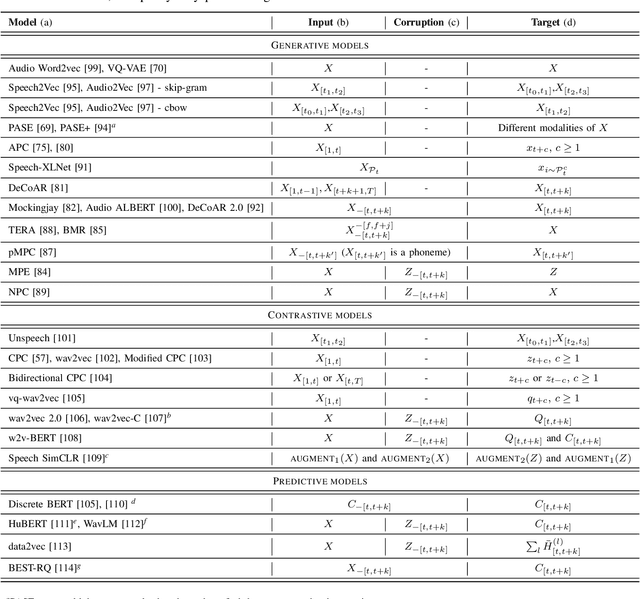
Although supervised deep learning has revolutionized speech and audio processing, it has necessitated the building of specialist models for individual tasks and application scenarios. It is likewise difficult to apply this to dialects and languages for which only limited labeled data is available. Self-supervised representation learning methods promise a single universal model that would benefit a wide variety of tasks and domains. Such methods have shown success in natural language processing and computer vision domains, achieving new levels of performance while reducing the number of labels required for many downstream scenarios. Speech representation learning is experiencing similar progress in three main categories: generative, contrastive, and predictive methods. Other approaches rely on multi-modal data for pre-training, mixing text or visual data streams with speech. Although self-supervised speech representation is still a nascent research area, it is closely related to acoustic word embedding and learning with zero lexical resources, both of which have seen active research for many years. This review presents approaches for self-supervised speech representation learning and their connection to other research areas. Since many current methods focus solely on automatic speech recognition as a downstream task, we review recent efforts on benchmarking learned representations to extend the application beyond speech recognition.
Meta Learning for Natural Language Processing: A Survey
May 03, 2022
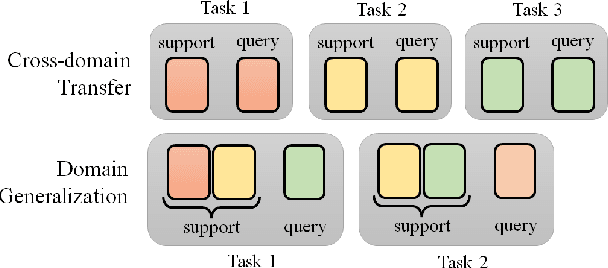

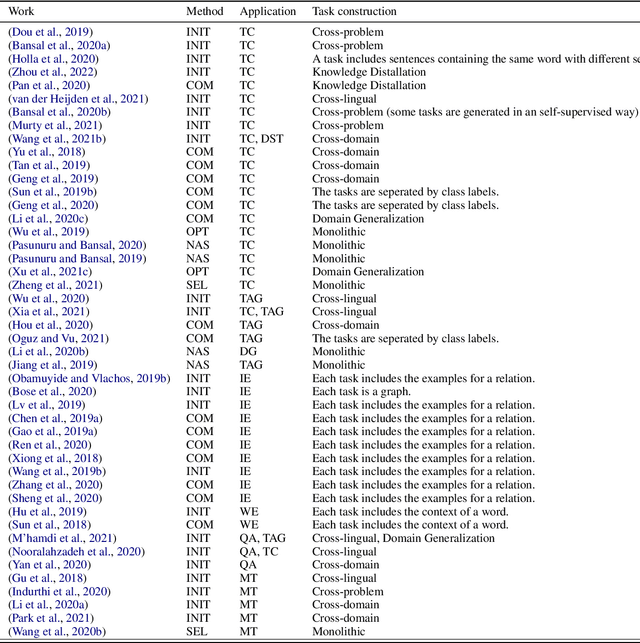
Deep learning has been the mainstream technique in natural language processing (NLP) area. However, the techniques require many labeled data and are less generalizable across domains. Meta-learning is an arising field in machine learning studying approaches to learn better learning algorithms. Approaches aim at improving algorithms in various aspects, including data efficiency and generalizability. Efficacy of approaches has been shown in many NLP tasks, but there is no systematic survey of these approaches in NLP, which hinders more researchers from joining the field. Our goal with this survey paper is to offer researchers pointers to relevant meta-learning works in NLP and attract more attention from the NLP community to drive future innovation. This paper first introduces the general concepts of meta-learning and the common approaches. Then we summarize task construction settings and application of meta-learning for various NLP problems and review the development of meta-learning in NLP community.
DiffCSE: Difference-based Contrastive Learning for Sentence Embeddings
Apr 21, 2022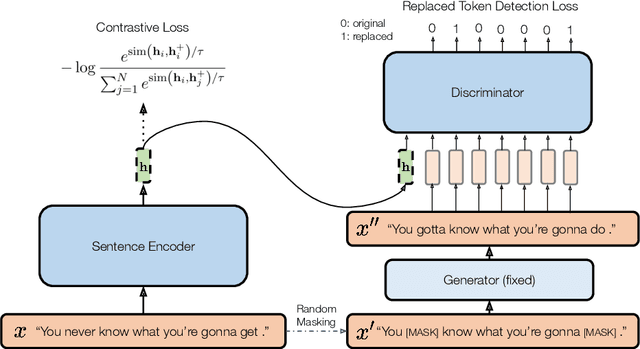
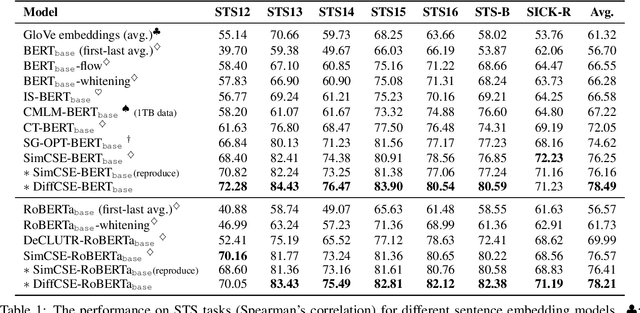
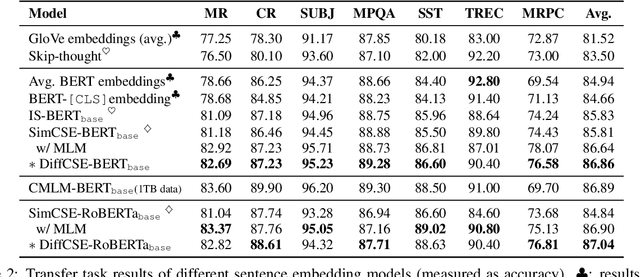
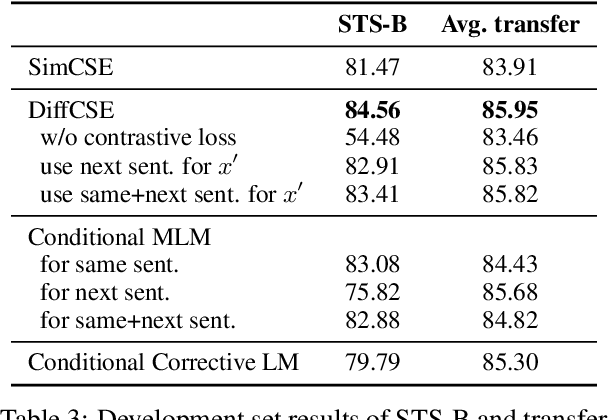
We propose DiffCSE, an unsupervised contrastive learning framework for learning sentence embeddings. DiffCSE learns sentence embeddings that are sensitive to the difference between the original sentence and an edited sentence, where the edited sentence is obtained by stochastically masking out the original sentence and then sampling from a masked language model. We show that DiffSCE is an instance of equivariant contrastive learning (Dangovski et al., 2021), which generalizes contrastive learning and learns representations that are insensitive to certain types of augmentations and sensitive to other "harmful" types of augmentations. Our experiments show that DiffCSE achieves state-of-the-art results among unsupervised sentence representation learning methods, outperforming unsupervised SimCSE by 2.3 absolute points on semantic textual similarity tasks.
An Exploration of Prompt Tuning on Generative Spoken Language Model for Speech Processing Tasks
Mar 31, 2022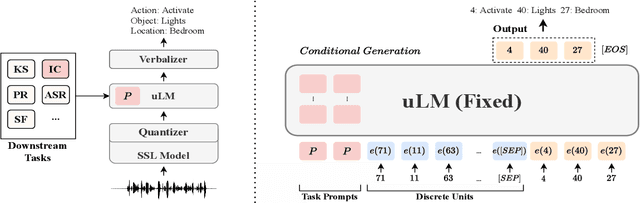
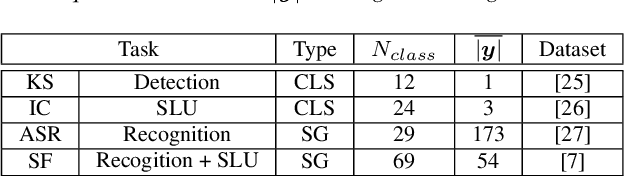
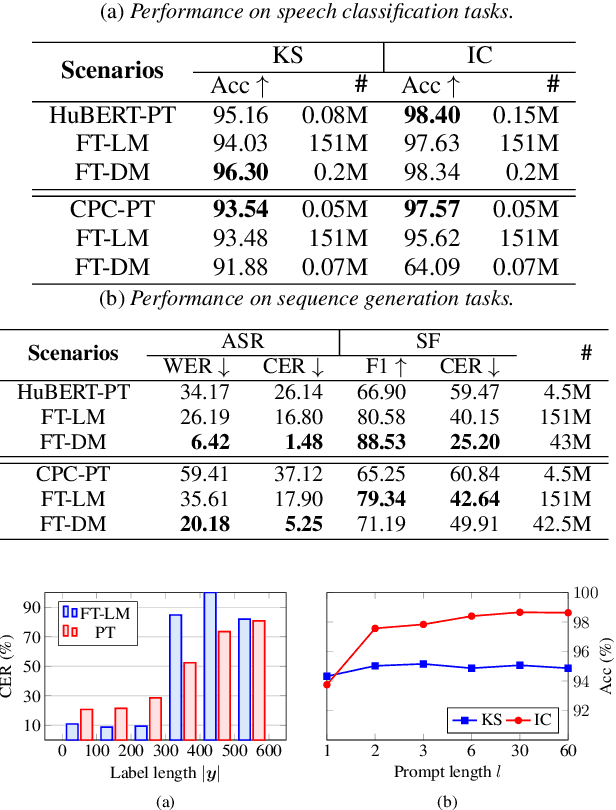
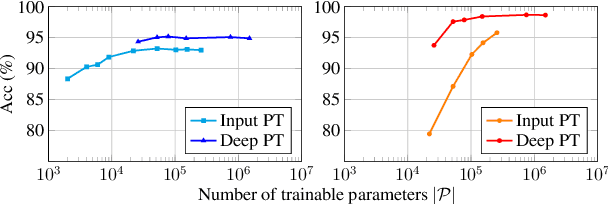
Speech representations learned from Self-supervised learning (SSL) models have been found beneficial for various speech processing tasks. However, utilizing SSL representations usually requires fine-tuning the pre-trained models or designing task-specific downstream models and loss functions, causing much memory usage and human labor. On the other hand, prompting in Natural Language Processing (NLP) is an efficient and widely used technique to leverage pre-trained language models (LMs). Nevertheless, such a paradigm is little studied in the speech community. We report in this paper the first exploration of the prompt tuning paradigm for speech processing tasks based on Generative Spoken Language Model (GSLM). Experiment results show that the prompt tuning technique achieves competitive performance in speech classification tasks with fewer trainable parameters than fine-tuning specialized downstream models. We further study the technique in challenging sequence generation tasks. Prompt tuning also demonstrates its potential, while the limitation and possible research directions are discussed in this paper.
Listen, Adapt, Better WER: Source-free Single-utterance Test-time Adaptation for Automatic Speech Recognition
Mar 27, 2022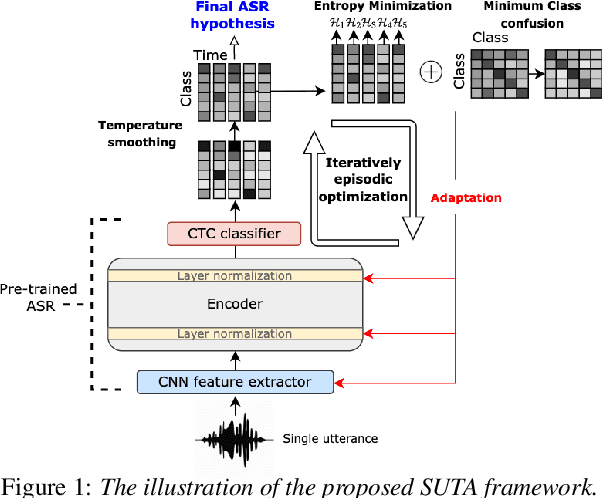

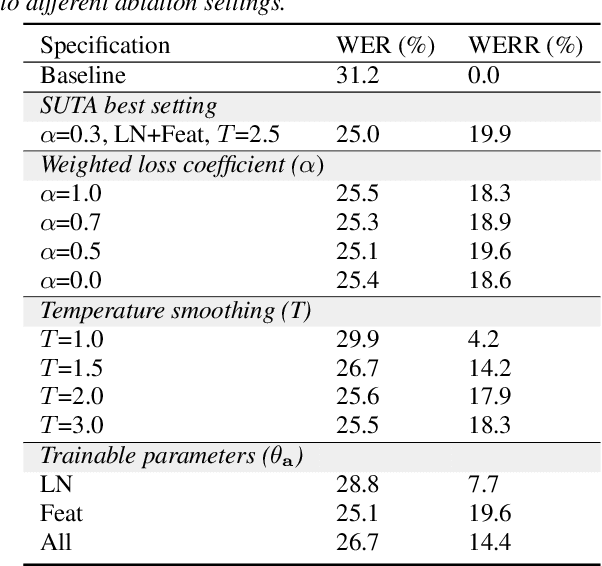
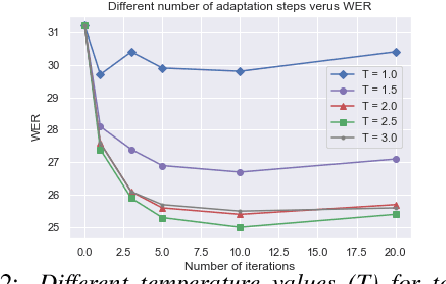
Although deep learning-based end-to-end Automatic Speech Recognition (ASR) has shown remarkable performance in recent years, it suffers severe performance regression on test samples drawn from different data distributions. Test-time Adaptation (TTA), previously explored in the computer vision area, aims to adapt the model trained on source domains to yield better predictions for test samples, often out-of-domain, without accessing the source data. Here, we propose the Single-Utterance Test-time Adaptation (SUTA) framework for ASR, which is the first TTA study in speech area to our best knowledge. The single-utterance TTA is a more realistic setting that does not assume test data are sampled from identical distribution and does not delay on-demand inference due to pre-collection for the batch of adaptation data. SUTA consists of unsupervised objectives with an efficient adaptation strategy. The empirical results demonstrate that SUTA effectively improves the performance of the source ASR model evaluated on multiple out-of-domain target corpora and in-domain test samples.
DUAL: Discrete Spoken Unit Adaptive Learning for Textless Spoken Question Answering
Mar 26, 2022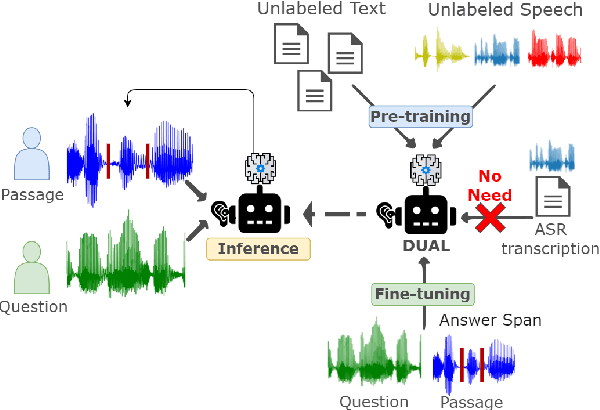
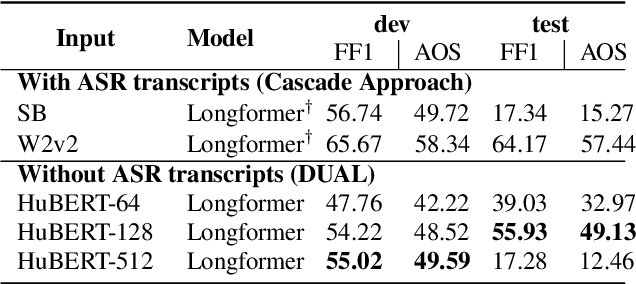
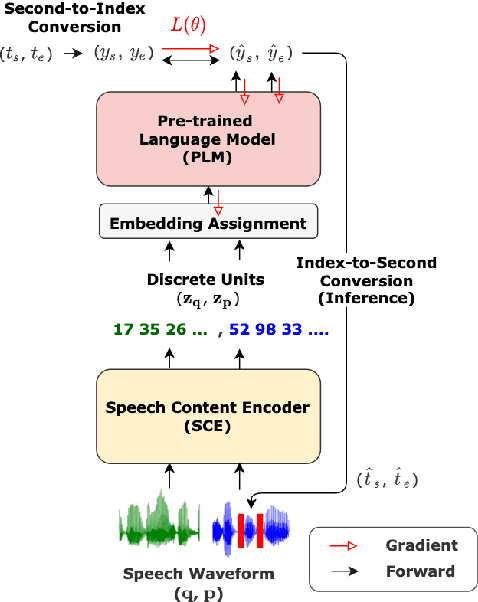
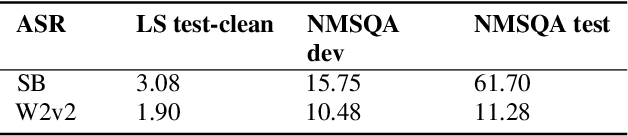
Spoken Question Answering (SQA) is to find the answer from a spoken document given a question, which is crucial for personal assistants when replying to the queries from the users. Existing SQA methods all rely on Automatic Speech Recognition (ASR) transcripts. Not only does ASR need to be trained with massive annotated data that are time and cost-prohibitive to collect for low-resourced languages, but more importantly, very often the answers to the questions include name entities or out-of-vocabulary words that cannot be recognized correctly. Also, ASR aims to minimize recognition errors equally over all words, including many function words irrelevant to the SQA task. Therefore, SQA without ASR transcripts (textless) is always highly desired, although known to be very difficult. This work proposes Discrete Spoken Unit Adaptive Learning (DUAL), leveraging unlabeled data for pre-training and fine-tuned by the SQA downstream task. The time intervals of spoken answers can be directly predicted from spoken documents. We also release a new SQA benchmark corpus, NMSQA, for data with more realistic scenarios. We empirically showed that DUAL yields results comparable to those obtained by cascading ASR and text QA model and robust to real-world data. Our code and model will be open-sourced.
SUPERB-SG: Enhanced Speech processing Universal PERformance Benchmark for Semantic and Generative Capabilities
Mar 14, 2022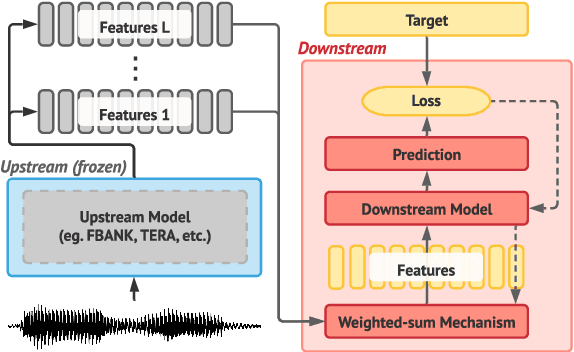
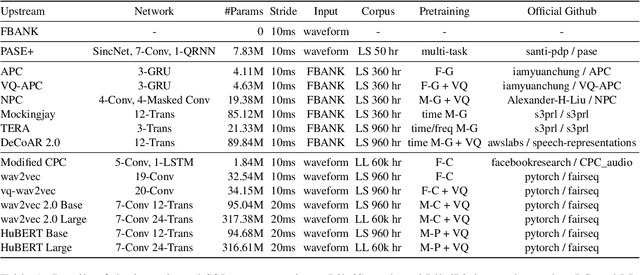
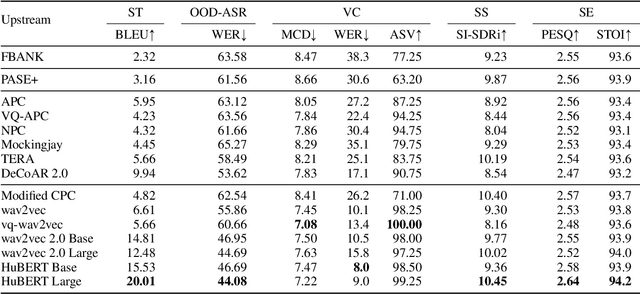
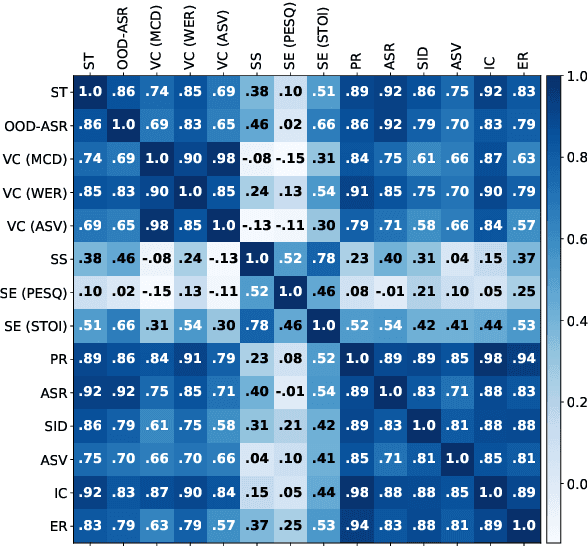
Transfer learning has proven to be crucial in advancing the state of speech and natural language processing research in recent years. In speech, a model pre-trained by self-supervised learning transfers remarkably well on multiple tasks. However, the lack of a consistent evaluation methodology is limiting towards a holistic understanding of the efficacy of such models. SUPERB was a step towards introducing a common benchmark to evaluate pre-trained models across various speech tasks. In this paper, we introduce SUPERB-SG, a new benchmark focused on evaluating the semantic and generative capabilities of pre-trained models by increasing task diversity and difficulty over SUPERB. We use a lightweight methodology to test the robustness of representations learned by pre-trained models under shifts in data domain and quality across different types of tasks. It entails freezing pre-trained model parameters, only using simple task-specific trainable heads. The goal is to be inclusive of all researchers, and encourage efficient use of computational resources. We also show that the task diversity of SUPERB-SG coupled with limited task supervision is an effective recipe for evaluating the generalizability of model representation.