 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFedCM: Federated Learning with Client-level Momentum
Jun 21, 2021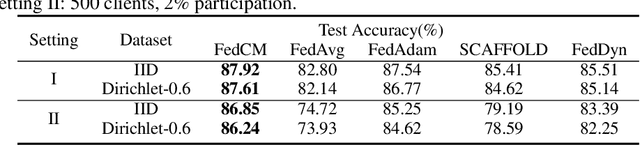
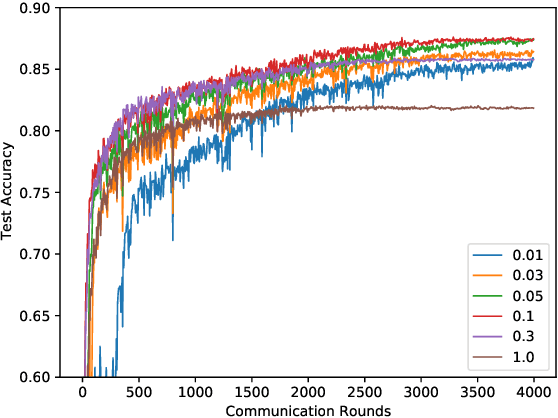
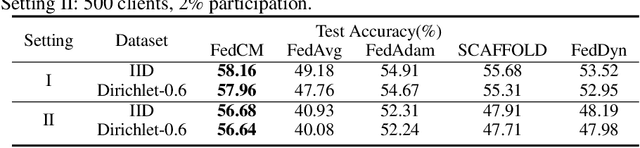
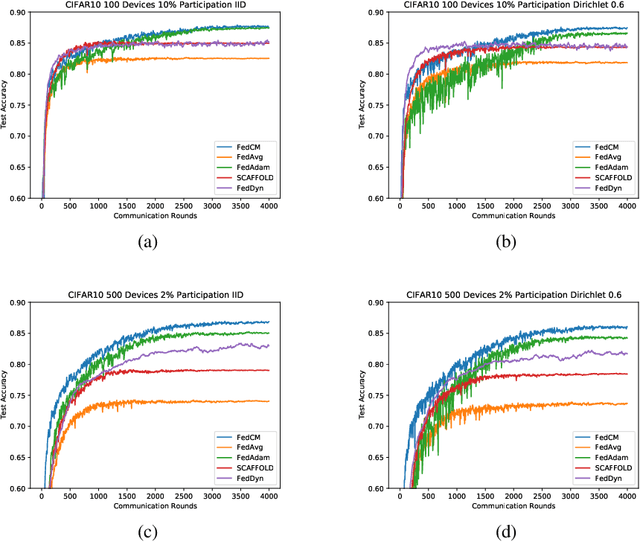
Federated Learning is a distributed machine learning approach which enables model training without data sharing. In this paper, we propose a new federated learning algorithm, Federated Averaging with Client-level Momentum (FedCM), to tackle problems of partial participation and client heterogeneity in real-world federated learning applications. FedCM aggregates global gradient information in previous communication rounds and modifies client gradient descent with a momentum-like term, which can effectively correct the bias and improve the stability of local SGD. We provide theoretical analysis to highlight the benefits of FedCM. We also perform extensive empirical studies and demonstrate that FedCM achieves superior performance in various tasks and is robust to different levels of client numbers, participation rate and client heterogeneity.
Radar SLAM: A Robust SLAM System for All Weather Conditions
Apr 12, 2021


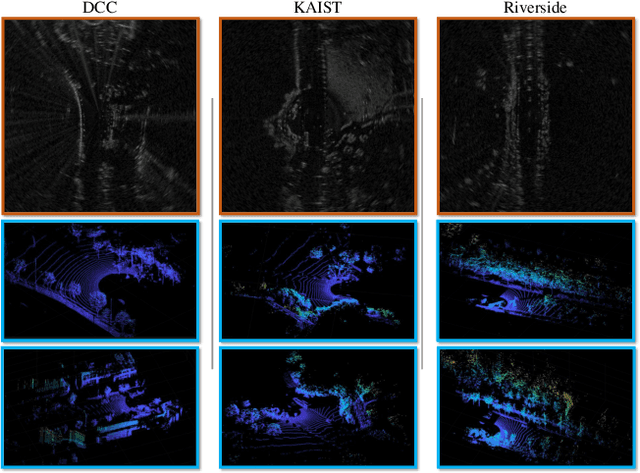
A Simultaneous Localization and Mapping (SLAM) system must be robust to support long-term mobile vehicle and robot applications. However, camera and LiDAR based SLAM systems can be fragile when facing challenging illumination or weather conditions which degrade their imagery and point cloud data. Radar, whose operating electromagnetic spectrum is less affected by environmental changes, is promising although its distinct sensing geometry and noise characteristics bring open challenges when being exploited for SLAM. % However, there are still open challenges since most existing visual and LiDAR SLAM systems do not operate in bad weathers. This paper studies the use of a Frequency Modulated Continuous Wave radar for SLAM in large-scale outdoor environments. We propose a full radar SLAM system, including a novel radar motion tracking algorithm that leverages radar geometry for reliable feature tracking. It also optimally compensates motion distortion and estimates pose by joint optimization. Its loop closure component is designed to be simple yet efficient for radar imagery by capturing and exploiting structural information of the surrounding environment. % while a scheme to reject ambiguous loop closure candidates is also designed specifically for radar. Extensive experiments on three public radar datasets, ranging from city streets and residential areas to countryside and highways, show competitive accuracy and reliability performance of the proposed radar SLAM system compared to the state-of-the-art LiDAR, vision and radar methods. The results show that our system is technically viable in achieving reliable SLAM in extreme weather conditions, e.g. heavy snow and dense fog, demonstrating the promising potential of using radar for all-weather localization and mapping.
How Sensitive are Meta-Learners to Dataset Imbalance?
Apr 12, 2021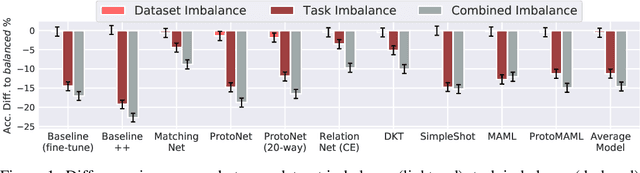
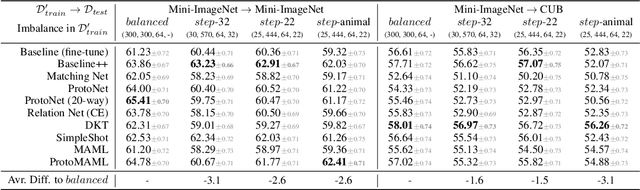
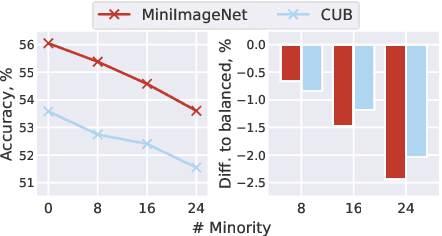
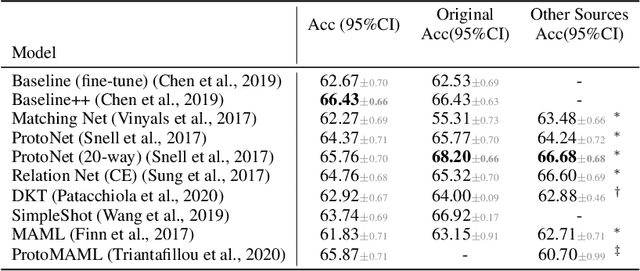
Meta-Learning (ML) has proven to be a useful tool for training Few-Shot Learning (FSL) algorithms by exposure to batches of tasks sampled from a meta-dataset. However, the standard training procedure overlooks the dynamic nature of the real-world where object classes are likely to occur at different frequencies. While it is generally understood that imbalanced tasks harm the performance of supervised methods, there is no significant research examining the impact of imbalanced meta-datasets on the FSL evaluation task. This study exposes the magnitude and extent of this problem. Our results show that ML methods are more robust against meta-dataset imbalance than imbalance at the task-level with a similar imbalance ratio ($\rho<20$), with the effect holding even in long-tail datasets under a larger imbalance ($\rho=65$). Overall, these results highlight an implicit strength of ML algorithms, capable of learning generalizable features under dataset imbalance and domain-shift. The code to reproduce the experiments is released under an open-source license.
NOMA for Next-generation Massive IoT: Performance Potential and Technology Directions
Apr 11, 2021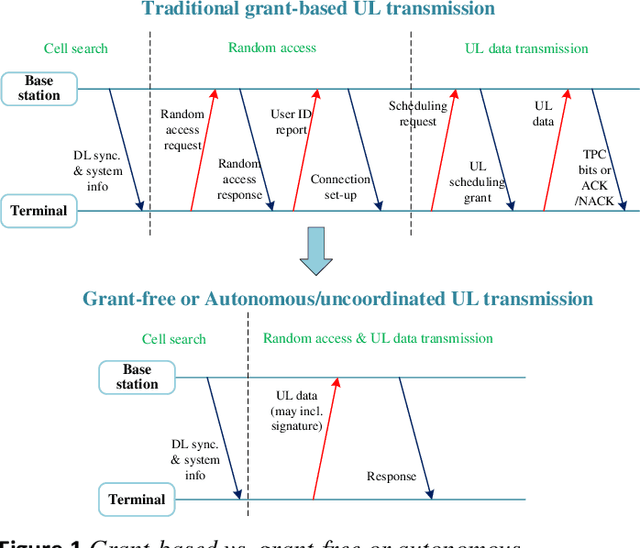
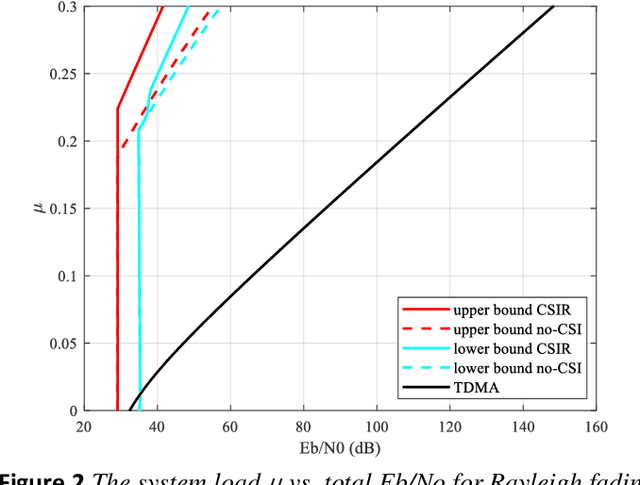
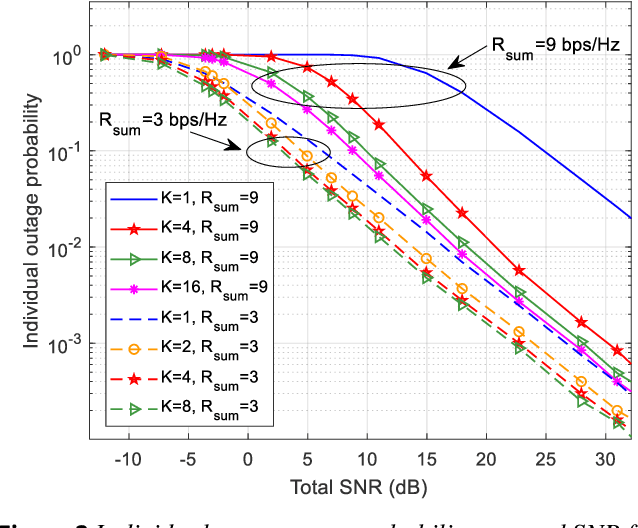
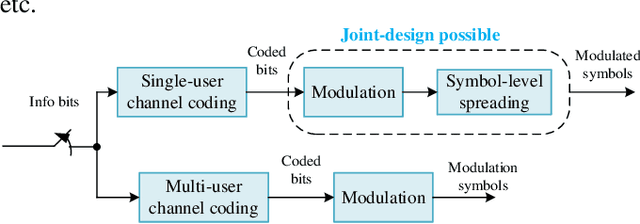
Broader applications of the Internet of Things (IoT) are expected in the forthcoming 6G system, although massive IoT is already a key scenario in 5G, predominantly relying on physical layer solutions inherited from 4G LTE and primarily using orthogonal multiple access (OMA). In 6G IoT, supporting a massive number of connections will be required for diverse services of the vertical sectors, prompting fundamental studies on how to improve the spectral efficiency of the system. One of the key enabling technologies is non-orthogonal multiple access (NOMA). This paper consists of two parts. In the first part, finite block length theory and the diversity order of multi-user systems will be used to show the significant potential of NOMA compared to traditional OMA. The supremacy of NOMA over OMA is particularly pronounced for asynchronous contention-based systems relying on imperfect link adaptation, which are commonly assumed for massive IoT systems. To approach these performance bounds, in the second part of the paper, several promising technology directions are proposed for 6G massive IoT, including linear spreading, joint spreading & modulation, multi-user channel coding in the context of various techniques for practical uncoordinated transmissions, cell-free operations, etc., from the perspective of NOMA.
Semantic Disentangling Generalized Zero-Shot Learning
Jan 27, 2021

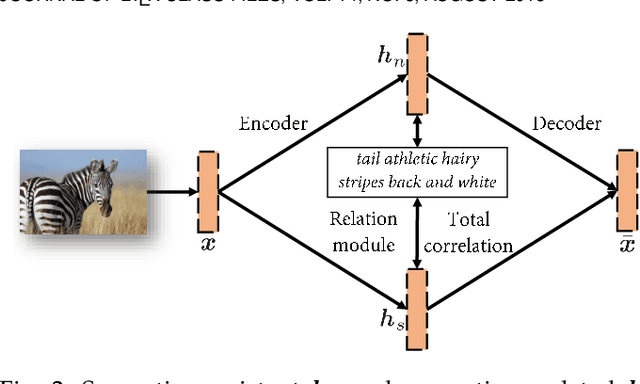
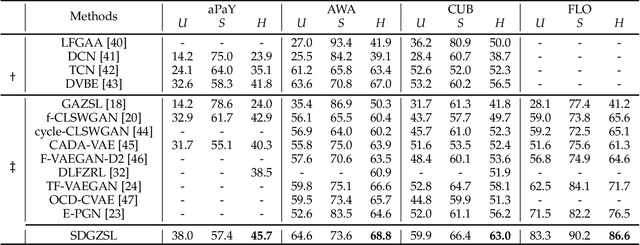
Generalized Zero-Shot Learning (GZSL) aims to recognize images from both seen and unseen categories. Most GZSL methods typically learn to synthesize CNN visual features for the unseen classes by leveraging entire semantic information, e.g., tags and attributes, and the visual features of the seen classes. Within the visual features, we define two types of features that semantic-consistent and semantic-unrelated to represent the characteristics of images annotated in attributes and less informative features of images respectively. Ideally, the semantic-unrelated information is impossible to transfer by semantic-visual relationship from seen classes to unseen classes, as the corresponding characteristics are not annotated in the semantic information. Thus, the foundation of the visual feature synthesis is not always solid as the features of the seen classes may involve semantic-unrelated information that could interfere with the alignment between semantic and visual modalities. To address this issue, in this paper, we propose a novel feature disentangling approach based on an encoder-decoder architecture to factorize visual features of images into these two latent feature spaces to extract corresponding representations. Furthermore, a relation module is incorporated into this architecture to learn semantic-visual relationship, whilst a total correlation penalty is applied to encourage the disentanglement of two latent representations. The proposed model aims to distill quality semantic-consistent representations that capture intrinsic features of seen images, which are further taken as the generation target for unseen classes. Extensive experiments conducted on seven GZSL benchmark datasets have verified the state-of-the-art performance of the proposal.
Few-Shot Learning with Class Imbalance
Jan 07, 2021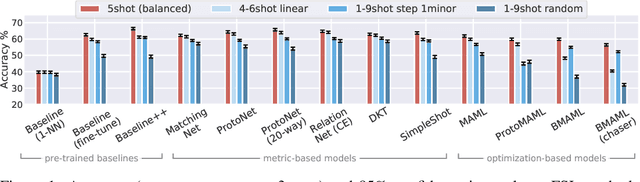
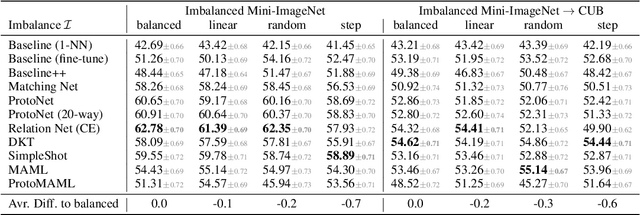
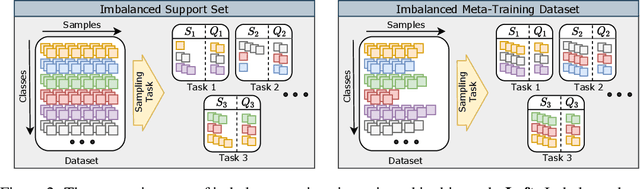
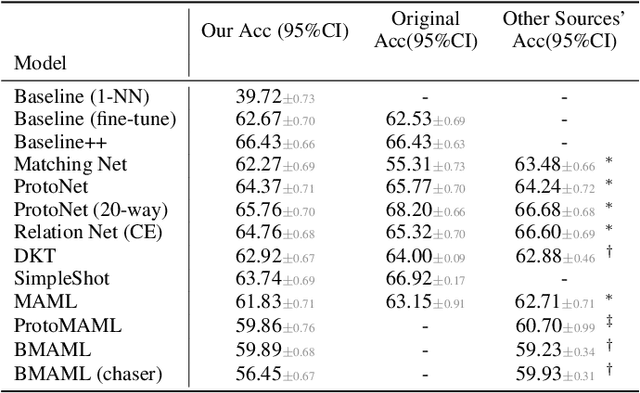
Few-shot learning aims to train models on a limited number of labeled samples given in a support set in order to generalize to unseen samples from a query set. In the standard setup, the support set contains an equal amount of data points for each class. However, this assumption overlooks many practical considerations arising from the dynamic nature of the real world, such as class-imbalance. In this paper, we present a detailed study of few-shot class-imbalance along three axes: meta-dataset vs. task imbalance, effect of different imbalance distributions (linear, step, random), and effect of rebalancing techniques. We extensively compare over 10 state-of-the-art few-shot learning and meta-learning methods using unbalanced tasks and meta-datasets. Our analysis using Mini-ImageNet reveals that 1) compared to the balanced task, the performances on class-imbalance tasks counterparts always drop, by up to $18.0\%$ for optimization-based methods, and up to $8.4$ for metric-based methods, 2) contrary to popular belief, meta-learning algorithms, such as MAML, do not automatically learn to balance by being exposed to imbalanced tasks during (meta-)training time, 3) strategies used to mitigate imbalance in supervised learning, such as oversampling, can offer a stronger solution to the class imbalance problem, 4) the effect of imbalance at the meta-dataset level is less significant than the effect at the task level with similar imbalance magnitude. The code to reproduce the experiments is released under an open-source license.
Watch and Learn: Mapping Language and Noisy Real-world Videos with Self-supervision
Nov 19, 2020
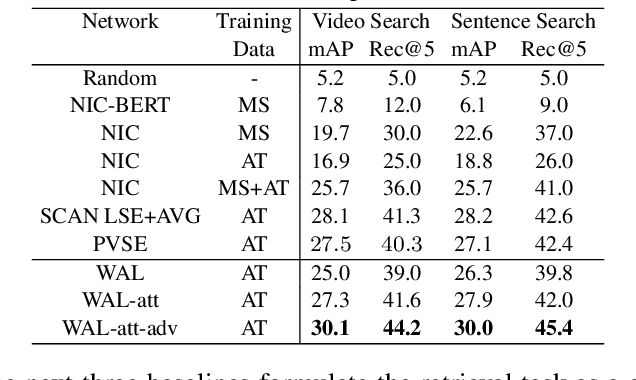
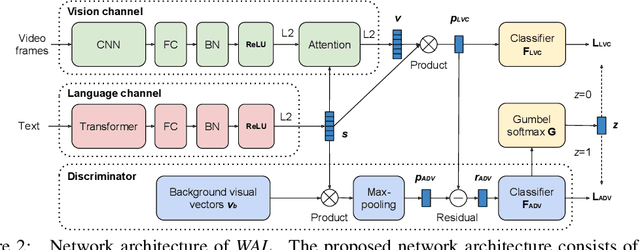
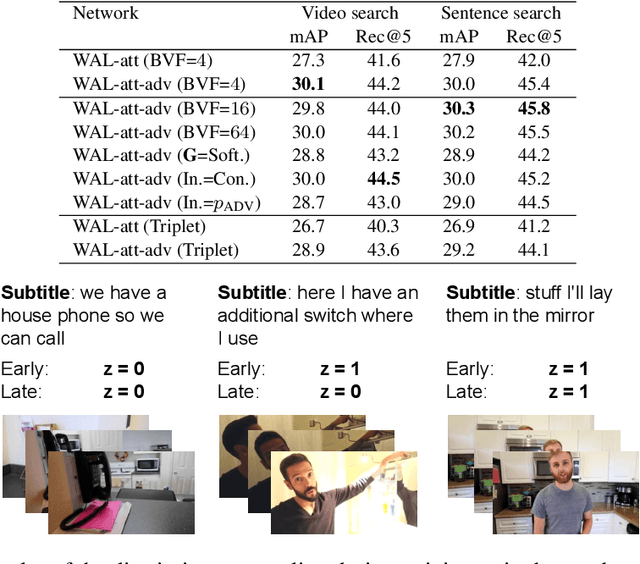
In this paper, we teach machines to understand visuals and natural language by learning the mapping between sentences and noisy video snippets without explicit annotations. Firstly, we define a self-supervised learning framework that captures the cross-modal information. A novel adversarial learning module is then introduced to explicitly handle the noises in the natural videos, where the subtitle sentences are not guaranteed to be strongly corresponded to the video snippets. For training and evaluation, we contribute a new dataset `ApartmenTour' that contains a large number of online videos and subtitles. We carry out experiments on the bidirectional retrieval tasks between sentences and videos, and the results demonstrate that our proposed model achieves the state-of-the-art performance on both retrieval tasks and exceeds several strong baselines. The dataset will be released soon.
RADIATE: A Radar Dataset for Automotive Perception
Oct 18, 2020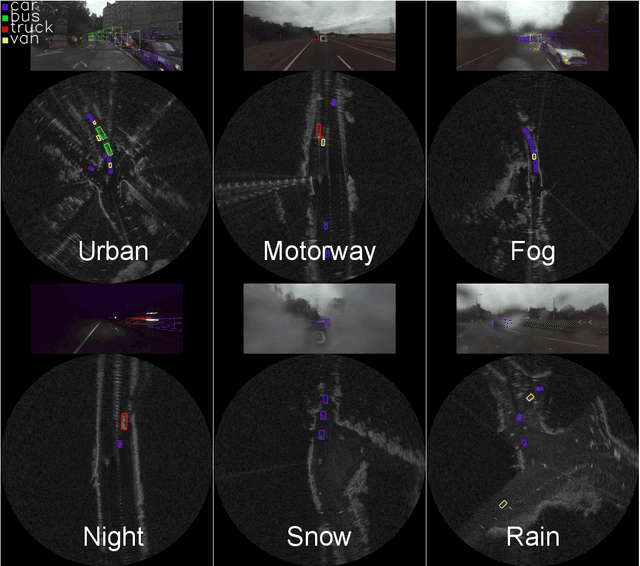

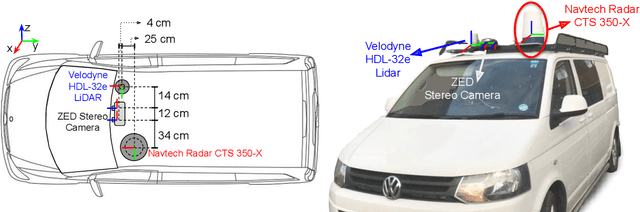
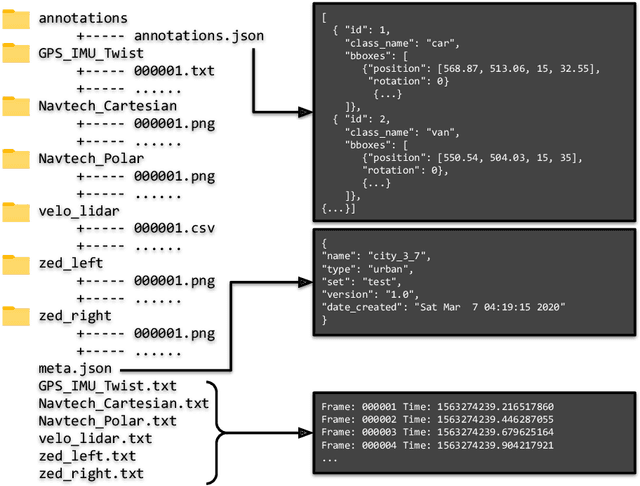
Datasets for autonomous cars are essential for the development and benchmarking of perception systems. However, most existing datasets are captured with camera and LiDAR sensors in good weather conditions. In this paper, we present the RAdar Dataset In Adverse weaThEr (RADIATE), aiming to facilitate research on object detection, tracking and scene understanding using radar sensing for safe autonomous driving. RADIATE includes 3 hours of annotated radar images with more than 200K labelled road actors in total, on average about 4.6 instances per radar image. It covers 8 different categories of actors in a variety of weather conditions (e.g., sun, night, rain, fog and snow) and driving scenarios (e.g., parked, urban, motorway and suburban), representing different levels of challenge. To the best of our knowledge, this is the first public radar dataset which provides high-resolution radar images on public roads with a large amount of road actors labelled. The data collected in adverse weather, e.g., fog and snowfall, is unique. Some baseline results of radar based object detection and recognition are given to show that the use of radar data is promising for automotive applications in bad weather, where vision and LiDAR can fail. RADIATE also has stereo images, 32-channel LiDAR and GPS data, directed at other applications such as sensor fusion, localisation and mapping. The public dataset can be accessed at http://pro.hw.ac.uk/radiate/.
BiteNet: Bidirectional Temporal Encoder Network to Predict Medical Outcomes
Sep 24, 2020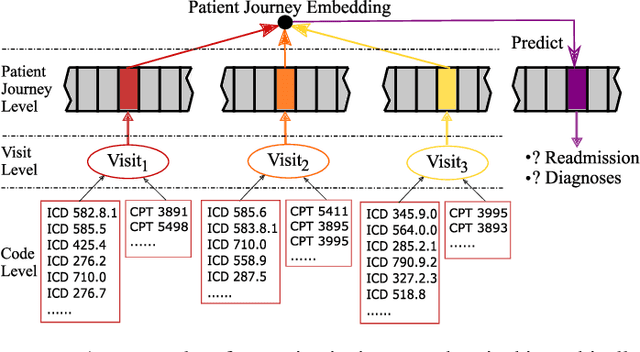
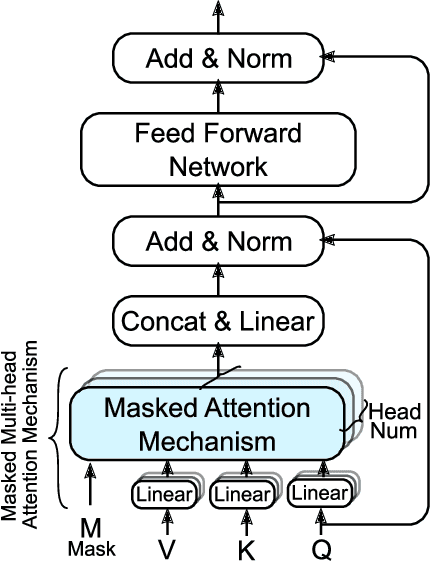
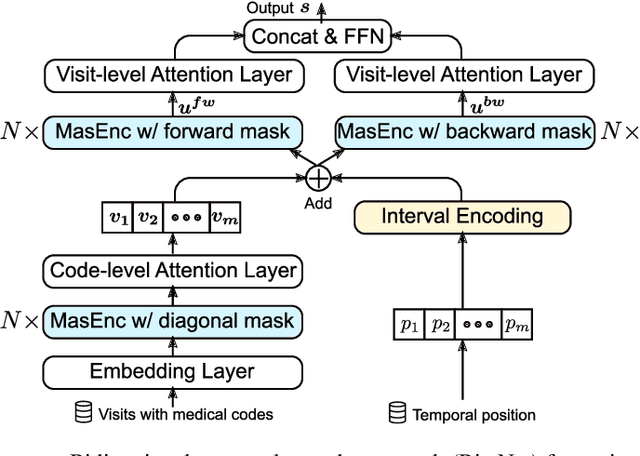
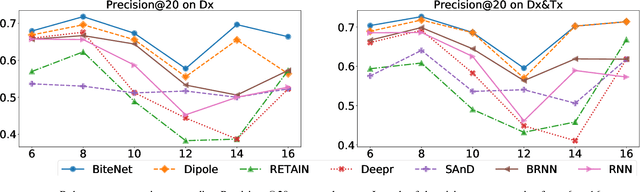
Electronic health records (EHRs) are longitudinal records of a patient's interactions with healthcare systems. A patient's EHR data is organized as a three-level hierarchy from top to bottom: patient journey - all the experiences of diagnoses and treatments over a period of time; individual visit - a set of medical codes in a particular visit; and medical code - a specific record in the form of medical codes. As EHRs begin to amass in millions, the potential benefits, which these data might hold for medical research and medical outcome prediction, are staggering - including, for example, predicting future admissions to hospitals, diagnosing illnesses or determining the efficacy of medical treatments. Each of these analytics tasks requires a domain knowledge extraction method to transform the hierarchical patient journey into a vector representation for further prediction procedure. The representations should embed a sequence of visits and a set of medical codes with a specific timestamp, which are crucial to any downstream prediction tasks. Hence, expressively powerful representations are appealing to boost learning performance. To this end, we propose a novel self-attention mechanism that captures the contextual dependency and temporal relationships within a patient's healthcare journey. An end-to-end bidirectional temporal encoder network (BiteNet) then learns representations of the patient's journeys, based solely on the proposed attention mechanism. We have evaluated the effectiveness of our methods on two supervised prediction and two unsupervised clustering tasks with a real-world EHR dataset. The empirical results demonstrate the proposed BiteNet model produces higher-quality representations than state-of-the-art baseline methods.
Rethinking Generative Zero-Shot Learning: An Ensemble Learning Perspective for Recognising Visual Patches
Aug 07, 2020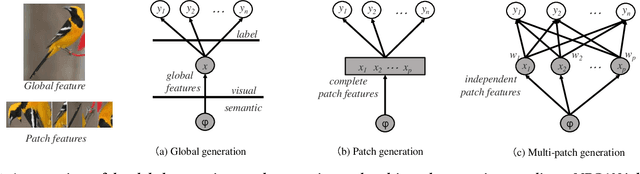
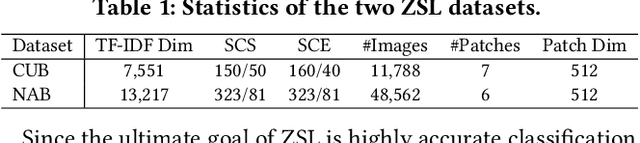
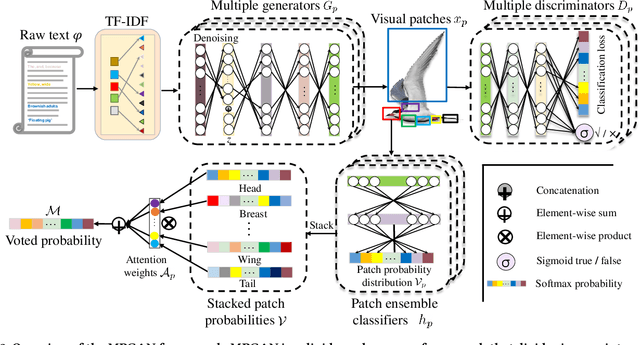
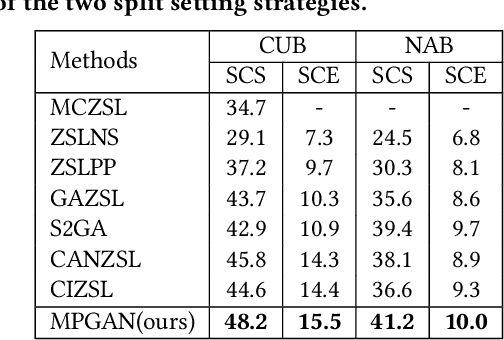
Zero-shot learning (ZSL) is commonly used to address the very pervasive problem of predicting unseen classes in fine-grained image classification and other tasks. One family of solutions is to learn synthesised unseen visual samples produced by generative models from auxiliary semantic information, such as natural language descriptions. However, for most of these models, performance suffers from noise in the form of irrelevant image backgrounds. Further, most methods do not allocate a calculated weight to each semantic patch. Yet, in the real world, the discriminative power of features can be quantified and directly leveraged to improve accuracy and reduce computational complexity. To address these issues, we propose a novel framework called multi-patch generative adversarial nets (MPGAN) that synthesises local patch features and labels unseen classes with a novel weighted voting strategy. The process begins by generating discriminative visual features from noisy text descriptions for a set of predefined local patches using multiple specialist generative models. The features synthesised from each patch for unseen classes are then used to construct an ensemble of diverse supervised classifiers, each corresponding to one local patch. A voting strategy averages the probability distributions output from the classifiers and, given that some patches are more discriminative than others, a discrimination-based attention mechanism helps to weight each patch accordingly. Extensive experiments show that MPGAN has significantly greater accuracy than state-of-the-art methods.