 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeARMP: Autoregressive Motion Planning for Quadruped Locomotion and Navigation in Complex Indoor Environments
Mar 28, 2023Generating natural and physically feasible motions for legged robots has been a challenging problem due to its complex dynamics. In this work, we introduce a novel learning-based framework of autoregressive motion planner (ARMP) for quadruped locomotion and navigation. Our method can generate motion plans with an arbitrary length in an autoregressive fashion, unlike most offline trajectory optimization algorithms for a fixed trajectory length. To this end, we first construct the motion library by solving a dense set of trajectory optimization problems for diverse scenarios and parameter settings. Then we learn the motion manifold from the dataset in a supervised learning fashion. We show that the proposed ARMP can generate physically plausible motions for various tasks and situations. We also showcase that our method can be successfully integrated with the recent robot navigation frameworks as a low-level controller and unleash the full capability of legged robots for complex indoor navigation.
Learning a Single Policy for Diverse Behaviors on a Quadrupedal Robot using Scalable Motion Imitation
Mar 27, 2023



Learning various motor skills for quadrupedal robots is a challenging problem that requires careful design of task-specific mathematical models or reward descriptions. In this work, we propose to learn a single capable policy using deep reinforcement learning by imitating a large number of reference motions, including walking, turning, pacing, jumping, sitting, and lying. On top of the existing motion imitation framework, we first carefully design the observation space, the action space, and the reward function to improve the scalability of the learning as well as the robustness of the final policy. In addition, we adopt a novel adaptive motion sampling (AMS) method, which maintains a balance between successful and unsuccessful behaviors. This technique allows the learning algorithm to focus on challenging motor skills and avoid catastrophic forgetting. We demonstrate that the learned policy can exhibit diverse behaviors in simulation by successfully tracking both the training dataset and out-of-distribution trajectories. We also validate the importance of the proposed learning formulation and the adaptive motion sampling scheme by conducting experiments.
On Designing a Learning Robot: Improving Morphology for Enhanced Task Performance and Learning
Mar 23, 2023As robots become more prevalent, optimizing their design for better performance and efficiency is becoming increasingly important. However, current robot design practices overlook the impact of perception and design choices on a robot's learning capabilities. To address this gap, we propose a comprehensive methodology that accounts for the interplay between the robot's perception, hardware characteristics, and task requirements. Our approach optimizes the robot's morphology holistically, leading to improved learning and task execution proficiency. To achieve this, we introduce a Morphology-AGnostIc Controller (MAGIC), which helps with the rapid assessment of different robot designs. The MAGIC policy is efficiently trained through a novel PRIvileged Single-stage learning via latent alignMent (PRISM) framework, which also encourages behaviors that are typical of robot onboard observation. Our simulation-based results demonstrate that morphologies optimized holistically improve the robot performance by 15-20% on various manipulation tasks, and require 25x less data to match human-expert made morphology performance. In summary, our work contributes to the growing trend of learning-based approaches in robotics and emphasizes the potential in designing robots that facilitate better learning.
Residual Physics Learning and System Identification for Sim-to-real Transfer of Policies on Buoyancy Assisted Legged Robots
Mar 16, 2023The light and soft characteristics of Buoyancy Assisted Lightweight Legged Unit (BALLU) robots have a great potential to provide intrinsically safe interactions in environments involving humans, unlike many heavy and rigid robots. However, their unique and sensitive dynamics impose challenges to obtaining robust control policies in the real world. In this work, we demonstrate robust sim-to-real transfer of control policies on the BALLU robots via system identification and our novel residual physics learning method, Environment Mimic (EnvMimic). First, we model the nonlinear dynamics of the actuators by collecting hardware data and optimizing the simulation parameters. Rather than relying on standard supervised learning formulations, we utilize deep reinforcement learning to train an external force policy to match real-world trajectories, which enables us to model residual physics with greater fidelity. We analyze the improved simulation fidelity by comparing the simulation trajectories against the real-world ones. We finally demonstrate that the improved simulator allows us to learn better walking and turning policies that can be successfully deployed on the hardware of BALLU.
Learning to Transfer In-Hand Manipulations Using a Greedy Shape Curriculum
Mar 14, 2023In-hand object manipulation is challenging to simulate due to complex contact dynamics, non-repetitive finger gaits, and the need to indirectly control unactuated objects. Further adapting a successful manipulation skill to new objects with different shapes and physical properties is a similarly challenging problem. In this work, we show that natural and robust in-hand manipulation of simple objects in a dynamic simulation can be learned from a high quality motion capture example via deep reinforcement learning with careful designs of the imitation learning problem. We apply our approach on both single-handed and two-handed dexterous manipulations of diverse object shapes and motions. We then demonstrate further adaptation of the example motion to a more complex shape through curriculum learning on intermediate shapes morphed between the source and target object. While a naive curriculum of progressive morphs often falls short, we propose a simple greedy curriculum search algorithm that can successfully apply to a range of objects such as a teapot, bunny, bottle, train, and elephant.
Cascaded Compositional Residual Learning for Complex Interactive Behaviors
Dec 17, 2022



Real-world autonomous missions often require rich interaction with nearby objects, such as doors or switches, along with effective navigation. However, such complex behaviors are difficult to learn because they involve both high-level planning and low-level motor control. We present a novel framework, Cascaded Compositional Residual Learning (CCRL), which learns composite skills by recursively leveraging a library of previously learned control policies. Our framework learns multiplicative policy composition, task-specific residual actions, and synthetic goal information simultaneously while freezing the prerequisite policies. We further explicitly control the style of the motion by regularizing residual actions. We show that our framework learns joint-level control policies for a diverse set of motor skills ranging from basic locomotion to complex interactive navigation, including navigating around obstacles, pushing objects, crawling under a table, pushing a door open with its leg, and holding it open while walking through it. The proposed CCRL framework leads to policies with consistent styles and lower joint torques, which we successfully transfer to a real Unitree A1 robot without any additional fine-tuning.
ViNL: Visual Navigation and Locomotion Over Obstacles
Oct 26, 2022We present Visual Navigation and Locomotion over obstacles (ViNL), which enables a quadrupedal robot to navigate unseen apartments while stepping over small obstacles that lie in its path (e.g., shoes, toys, cables), similar to how humans and pets lift their feet over objects as they walk. ViNL consists of: (1) a visual navigation policy that outputs linear and angular velocity commands that guides the robot to a goal coordinate in unfamiliar indoor environments; and (2) a visual locomotion policy that controls the robot's joints to avoid stepping on obstacles while following provided velocity commands. Both the policies are entirely "model-free", i.e. sensors-to-actions neural networks trained end-to-end. The two are trained independently in two entirely different simulators and then seamlessly co-deployed by feeding the velocity commands from the navigator to the locomotor, entirely "zero-shot" (without any co-training). While prior works have developed learning methods for visual navigation or visual locomotion, to the best of our knowledge, this is the first fully learned approach that leverages vision to accomplish both (1) intelligent navigation in new environments, and (2) intelligent visual locomotion that aims to traverse cluttered environments without disrupting obstacles. On the task of navigation to distant goals in unknown environments, ViNL using just egocentric vision significantly outperforms prior work on robust locomotion using privileged terrain maps (+32.8% success and -4.42 collisions per meter). Additionally, we ablate our locomotion policy to show that each aspect of our approach helps reduce obstacle collisions. Videos and code at http://www.joannetruong.com/projects/vinl.html
Unified State Representation Learning under Data Augmentation
Sep 12, 2022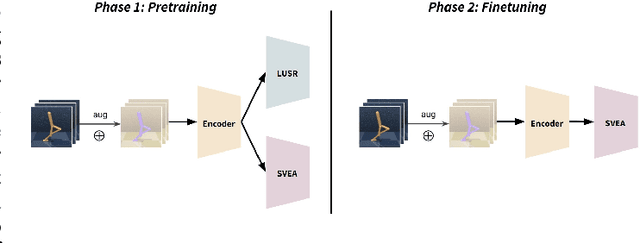
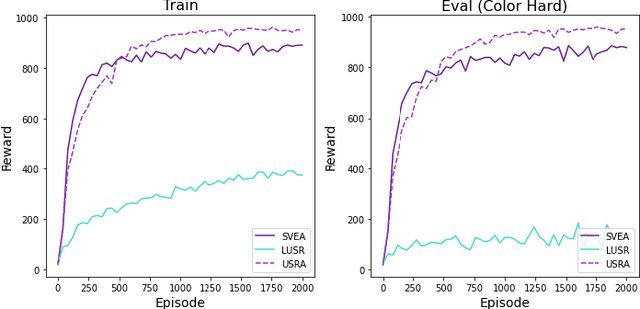
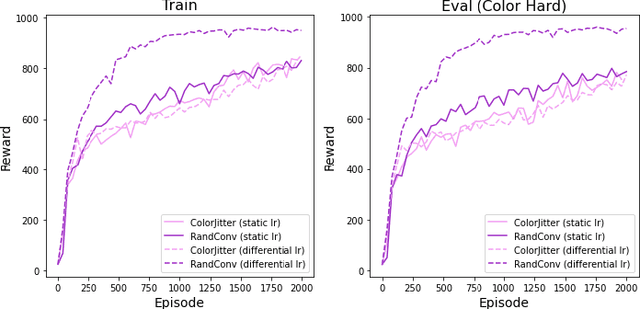
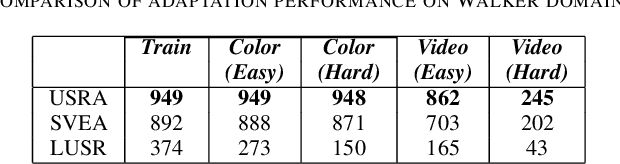
The capacity for rapid domain adaptation is important to increasing the applicability of reinforcement learning (RL) to real world problems. Generalization of RL agents is critical to success in the real world, yet zero-shot policy transfer is a challenging problem since even minor visual changes could make the trained agent completely fail in the new task. We propose USRA: Unified State Representation Learning under Data Augmentation, a representation learning framework that learns a latent unified state representation by performing data augmentations on its observations to improve its ability to generalize to unseen target domains. We showcase the success of our approach on the DeepMind Control Generalization Benchmark for the Walker environment and find that USRA achieves higher sample efficiency and 14.3% better domain adaptation performance compared to the best baseline results.
Human Motion Control of Quadrupedal Robots using Deep Reinforcement Learning
Apr 28, 2022
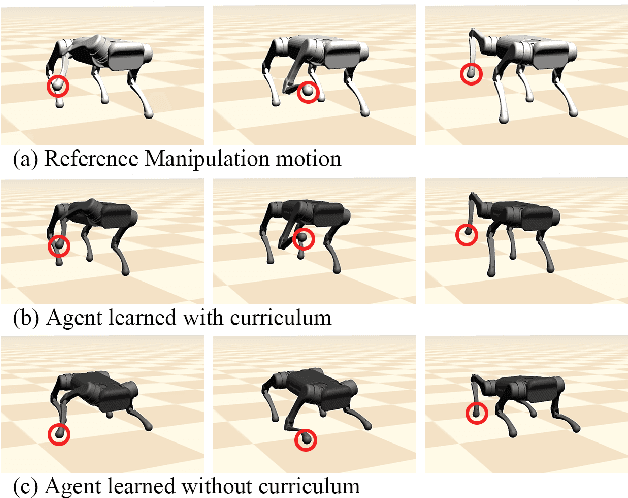
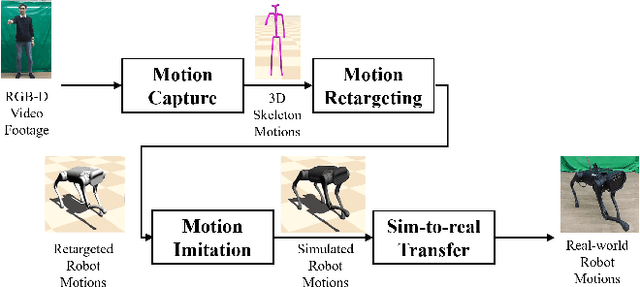
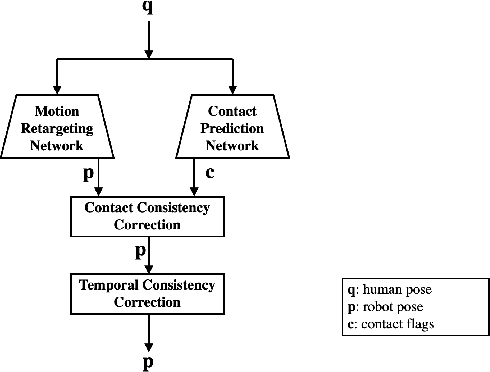
A motion-based control interface promises flexible robot operations in dangerous environments by combining user intuitions with the robot's motor capabilities. However, designing a motion interface for non-humanoid robots, such as quadrupeds or hexapods, is not straightforward because different dynamics and control strategies govern their movements. We propose a novel motion control system that allows a human user to operate various motor tasks seamlessly on a quadrupedal robot. We first retarget the captured human motion into the corresponding robot motion with proper semantics using supervised learning and post-processing techniques. Then we apply the motion imitation learning with curriculum learning to develop a control policy that can track the given retargeted reference. We further improve the performance of both motion retargeting and motion imitation by training a set of experts. As we demonstrate, a user can execute various motor tasks using our system, including standing, sitting, tilting, manipulating, walking, and turning, on simulated and real quadrupeds. We also conduct a set of studies to analyze the performance gain induced by each component.
Safe Reinforcement Learning for Legged Locomotion
Mar 05, 2022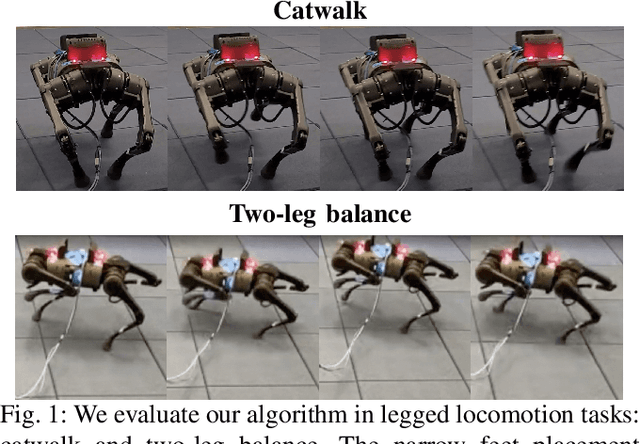
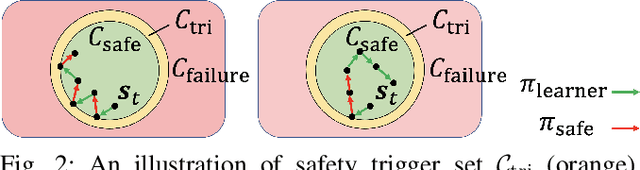


Designing control policies for legged locomotion is complex due to the under-actuated and non-continuous robot dynamics. Model-free reinforcement learning provides promising tools to tackle this challenge. However, a major bottleneck of applying model-free reinforcement learning in real world is safety. In this paper, we propose a safe reinforcement learning framework that switches between a safe recovery policy that prevents the robot from entering unsafe states, and a learner policy that is optimized to complete the task. The safe recovery policy takes over the control when the learner policy violates safety constraints, and hands over the control back when there are no future safety violations. We design the safe recovery policy so that it ensures safety of legged locomotion while minimally intervening in the learning process. Furthermore, we theoretically analyze the proposed framework and provide an upper bound on the task performance. We verify the proposed framework in four locomotion tasks on a simulated and real quadrupedal robot: efficient gait, catwalk, two-leg balance, and pacing. On average, our method achieves 48.6% fewer falls and comparable or better rewards than the baseline methods in simulation. When deployed it on real-world quadruped robot, our training pipeline enables 34% improvement in energy efficiency for the efficient gait, 40.9% narrower of the feet placement in the catwalk, and two times more jumping duration in the two-leg balance. Our method achieves less than five falls over the duration of 115 minutes of hardware time.