 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Contrastive Learning: Synthetic Data Enables List-wise Training with Multiple Levels of Relevance
Mar 29, 2025Recent advancements in large language models (LLMs) have allowed the augmentation of information retrieval (IR) pipelines with synthetic data in various ways. Yet, the main training paradigm remains: contrastive learning with binary relevance labels and the InfoNCE loss, where one positive document is compared against one or more negatives. This objective treats all documents that are not explicitly annotated as relevant on an equally negative footing, regardless of their actual degree of relevance, thus (a) missing subtle nuances that are useful for ranking and (b) being susceptible to annotation noise. To overcome this limitation, in this work we forgo real training documents and annotations altogether and use open-source LLMs to directly generate synthetic documents that answer real user queries according to several different levels of relevance. This fully synthetic ranking context of graduated relevance, together with an appropriate list-wise loss (Wasserstein distance), enables us to train dense retrievers in a way that better captures the ranking task. Experiments on various IR datasets show that our proposed approach outperforms conventional training with InfoNCE by a large margin. Without using any real documents for training, our dense retriever significantly outperforms the same retriever trained through self-supervision. More importantly, it matches the performance of the same retriever trained on real, labeled training documents of the same dataset, while being more robust to distribution shift and clearly outperforming it when evaluated zero-shot on the BEIR dataset collection.
Enhancing the Ranking Context of Dense Retrieval Methods through Reciprocal Nearest Neighbors
May 25, 2023Sparse annotation poses persistent challenges to training dense retrieval models, such as the problem of false negatives, i.e. unlabeled relevant documents that are spuriously used as negatives in contrastive learning, distorting the training signal. To alleviate this problem, we introduce evidence-based label smoothing, a computationally efficient method that prevents penalizing the model for assigning high relevance to false negatives. To compute the target relevance distribution over candidate documents within the ranking context of a given query, candidates most similar to the ground truth are assigned a non-zero relevance probability based on the degree of their similarity to the ground-truth document(s). As a relevance estimate we leverage an improved similarity metric based on reciprocal nearest neighbors, which can also be used independently to rerank candidates in post-processing. Through extensive experiments on two large-scale ad hoc text retrieval datasets we demonstrate that both methods can improve the ranking effectiveness of dense retrieval models.
Parameter-efficient Modularised Bias Mitigation via AdapterFusion
Feb 13, 2023



Large pre-trained language models contain societal biases and carry along these biases to downstream tasks. Current in-processing bias mitigation approaches (like adversarial training) impose debiasing by updating a model's parameters, effectively transferring the model to a new, irreversible debiased state. In this work, we propose a novel approach to develop stand-alone debiasing functionalities separate from the model, which can be integrated into the model on-demand, while keeping the core model untouched. Drawing from the concept of AdapterFusion in multi-task learning, we introduce DAM (Debiasing with Adapter Modules) - a debiasing approach to first encapsulate arbitrary bias mitigation functionalities into separate adapters, and then add them to the model on-demand in order to deliver fairness qualities. We conduct a large set of experiments on three classification tasks with gender, race, and age as protected attributes. Our results show that DAM improves or maintains the effectiveness of bias mitigation, avoids catastrophic forgetting in a multi-attribute scenario, and maintains on-par task performance, while granting parameter-efficiency and easy switching between the original and debiased models.
Unsupervised Multivariate Time-Series Transformers for Seizure Identification on EEG
Jan 03, 2023



Epilepsy is one of the most common neurological disorders, typically observed via seizure episodes. Epileptic seizures are commonly monitored through electroencephalogram (EEG) recordings due to their routine and low expense collection. The stochastic nature of EEG makes seizure identification via manual inspections performed by highly-trained experts a tedious endeavor, motivating the use of automated identification. The literature on automated identification focuses mostly on supervised learning methods requiring expert labels of EEG segments that contain seizures, which are difficult to obtain. Motivated by these observations, we pose seizure identification as an unsupervised anomaly detection problem. To this end, we employ the first unsupervised transformer-based model for seizure identification on raw EEG. We train an autoencoder involving a transformer encoder via an unsupervised loss function, incorporating a novel masking strategy uniquely designed for multivariate time-series data such as EEG. Training employs EEG recordings that do not contain any seizures, while seizures are identified with respect to reconstruction errors at inference time. We evaluate our method on three publicly available benchmark EEG datasets for distinguishing seizure vs. non-seizure windows. Our method leads to significantly better seizure identification performance than supervised learning counterparts, by up to 16% recall, 9% accuracy, and 9% Area under the Receiver Operating Characteristics Curve (AUC), establishing particular benefits on highly imbalanced data. Through accurate seizure identification, our method could facilitate widely accessible and early detection of epilepsy development, without needing expensive label collection or manual feature extraction.
Using DeepSpeed and Megatron to Train Megatron-Turing NLG 530B, A Large-Scale Generative Language Model
Feb 04, 2022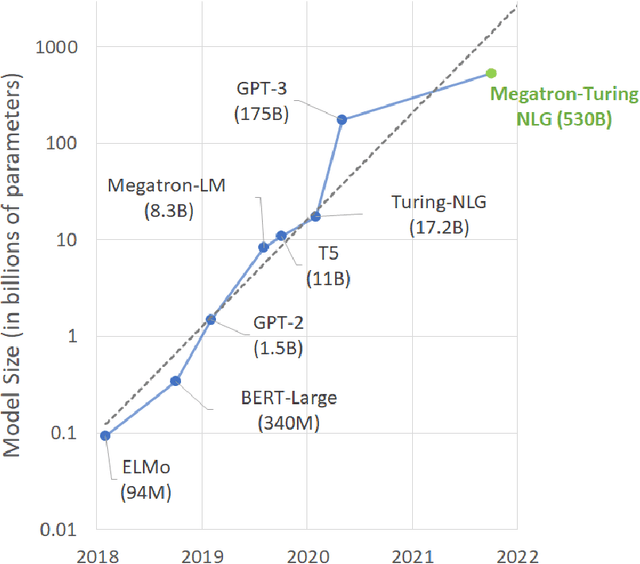
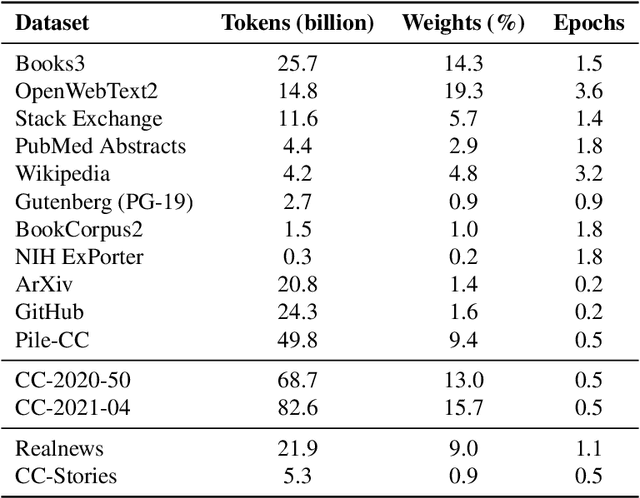
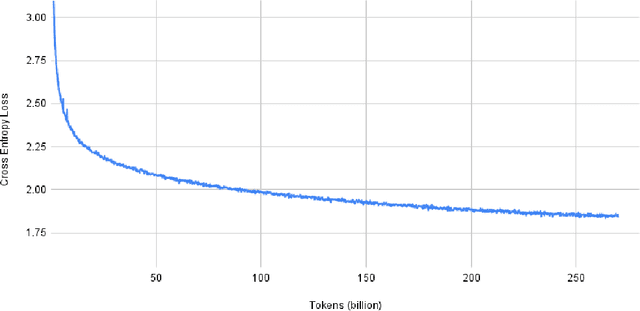
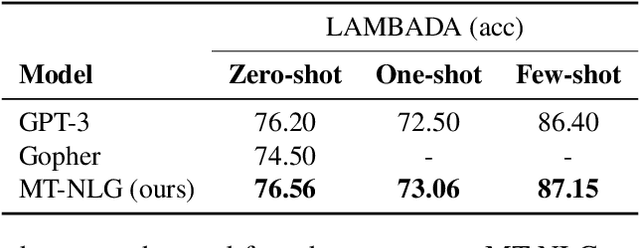
Pretrained general-purpose language models can achieve state-of-the-art accuracies in various natural language processing domains by adapting to downstream tasks via zero-shot, few-shot and fine-tuning techniques. Because of their success, the size of these models has increased rapidly, requiring high-performance hardware, software, and algorithmic techniques to enable training such large models. As the result of a joint effort between Microsoft and NVIDIA, we present details on the training of the largest monolithic transformer based language model, Megatron-Turing NLG 530B (MT-NLG), with 530 billion parameters. In this paper, we first focus on the infrastructure as well as the 3D parallelism methodology used to train this model using DeepSpeed and Megatron. Next, we detail the training process, the design of our training corpus, and our data curation techniques, which we believe is a key ingredient to the success of the model. Finally, we discuss various evaluation results, as well as other interesting observations and new properties exhibited by MT-NLG. We demonstrate that MT-NLG achieves superior zero-, one-, and few-shot learning accuracies on several NLP benchmarks and establishes new state-of-the-art results. We believe that our contributions will help further the development of large-scale training infrastructures, large-scale language models, and natural language generations.
CODER: An efficient framework for improving retrieval through COntextualized Document Embedding Reranking
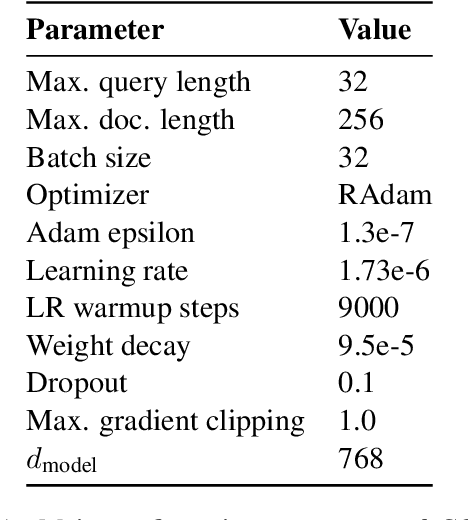
Dec 16, 2021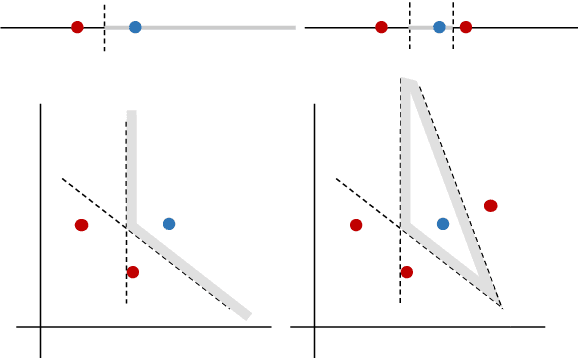
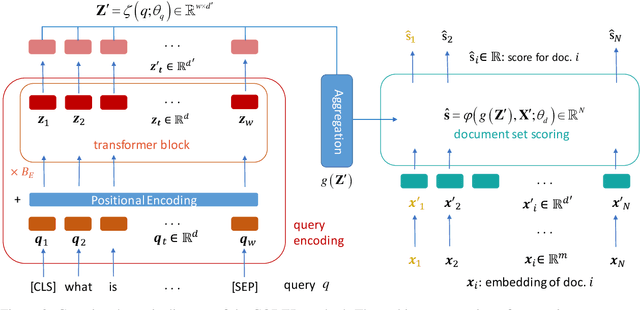
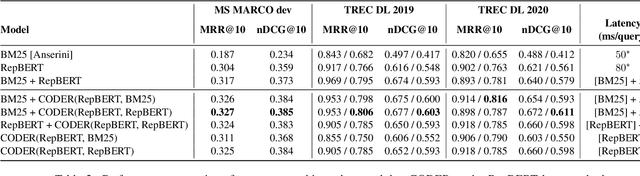
We present a framework for improving the performance of a wide class of retrieval models at minimal computational cost. It utilizes precomputed document representations extracted by a base dense retrieval method and involves training a model to jointly score a large set of retrieved candidate documents for each query, while potentially transforming on the fly the representation of each document in the context of the other candidates as well as the query itself. When scoring a document representation based on its similarity to a query, the model is thus aware of the representation of its "peer" documents. We show that our approach leads to substantial improvement in retrieval performance over the base method and over scoring candidate documents in isolation from one another, as in a pair-wise training setting. Crucially, unlike term-interaction rerankers based on BERT-like encoders, it incurs a negligible computational overhead on top of any first-stage method at run time, allowing it to be easily combined with any state-of-the-art dense retrieval method. Finally, concurrently considering a set of candidate documents for a given query enables additional valuable capabilities in retrieval, such as score calibration and mitigating societal biases in ranking.
Extracting Angina Symptoms from Clinical Notes Using Pre-Trained Transformer Architectures
Oct 12, 2020
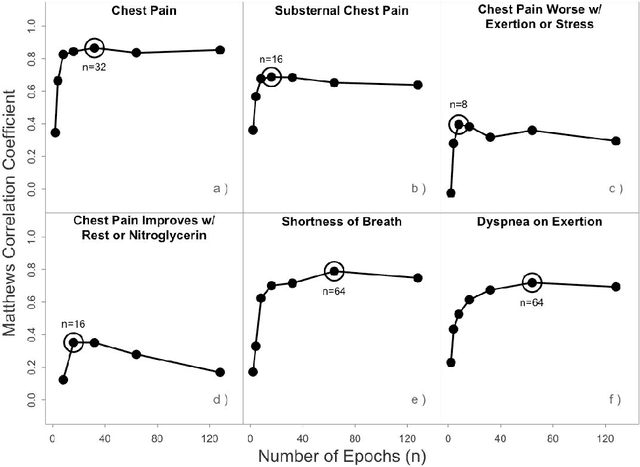
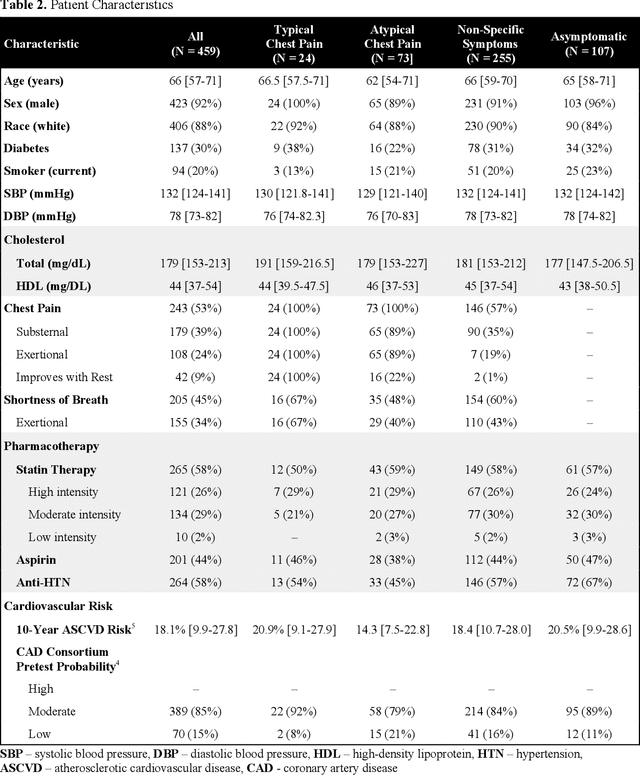
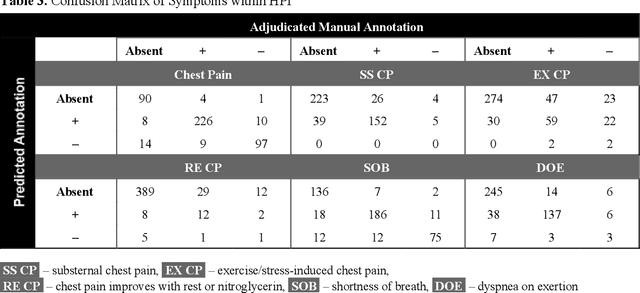
Anginal symptoms can connote increased cardiac risk and a need for change in cardiovascular management. This study evaluated the potential to extract these symptoms from physician notes using the Bidirectional Encoder from Transformers language model fine-tuned on a domain-specific corpus. The history of present illness section of 459 expert annotated primary care physician notes from consecutive patients referred for cardiac testing without known atherosclerotic cardiovascular disease were included. Notes were annotated for positive and negative mentions of chest pain and shortness of breath characterization. The results demonstrate high sensitivity and specificity for the detection of chest pain or discomfort, substernal chest pain, shortness of breath, and dyspnea on exertion. Small sample size limited extracting factors related to provocation and palliation of chest pain. This study provides a promising starting point for the natural language processing of physician notes to characterize clinically actionable anginal symptoms.
A Transformer-based Framework for Multivariate Time Series Representation Learning
Oct 08, 2020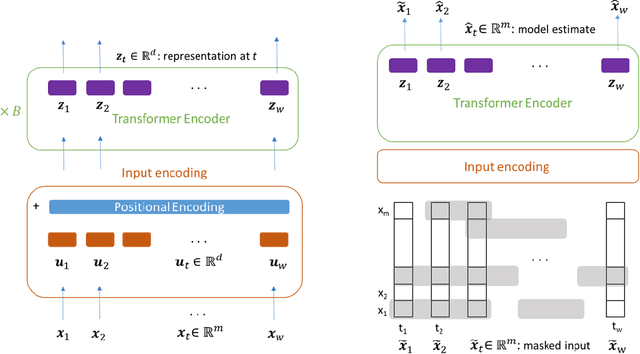
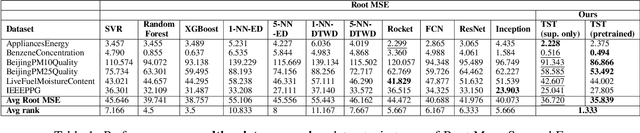
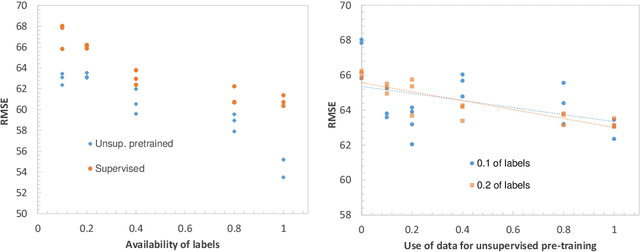
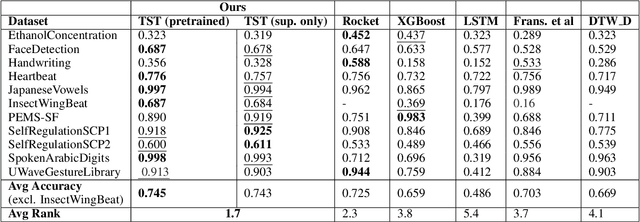
In this work we propose for the first time a transformer-based framework for unsupervised representation learning of multivariate time series. Pre-trained models can be potentially used for downstream tasks such as regression and classification, forecasting and missing value imputation. By evaluating our models on several benchmark datasets for multivariate time series regression and classification, we show that not only does our modeling approach represent the most successful method employing unsupervised learning of multivariate time series presented to date, but also that it exceeds the current state-of-the-art performance of supervised methods; it does so even when the number of training samples is very limited, while offering computational efficiency. Finally, we demonstrate that unsupervised pre-training of our transformer models offers a substantial performance benefit over fully supervised learning, even without leveraging additional unlabeled data, i.e., by reusing the same data samples through the unsupervised objective.
Brown University at TREC Deep Learning 2019
Sep 08, 2020
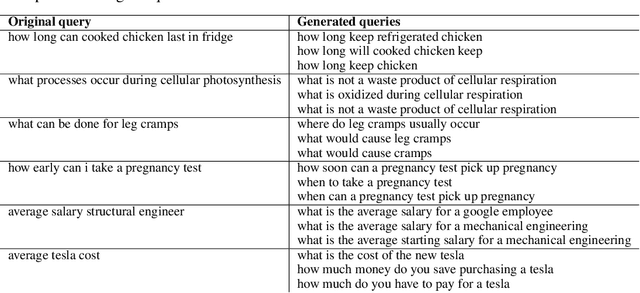
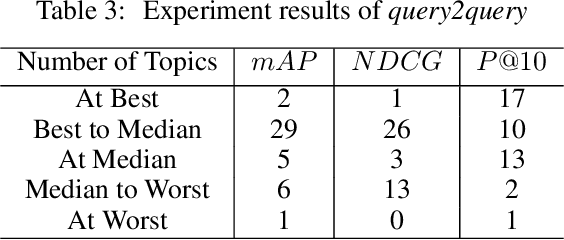
This paper describes Brown University's submission to the TREC 2019 Deep Learning track. We followed a 2-phase method for producing a ranking of passages for a given input query: In the the first phase, the user's query is expanded by appending 3 queries generated by a transformer model which was trained to rephrase an input query into semantically similar queries. The expanded query can exhibit greater similarity in surface form and vocabulary overlap with the passages of interest and can therefore serve as enriched input to any downstream information retrieval method. In the second phase, we use a BERT-based model pre-trained for language modeling but fine-tuned for query - document relevance prediction to compute relevance scores for a set of 1000 candidate passages per query and subsequently obtain a ranking of passages by sorting them based on the predicted relevance scores. According to the results published in the official Overview of the TREC Deep Learning Track 2019, our team ranked 3rd in the passage retrieval task (including full ranking and re-ranking), and 2nd when considering only re-ranking submissions.
Improving Clinical Predictions through Unsupervised Time Series Representation Learning
Dec 02, 2018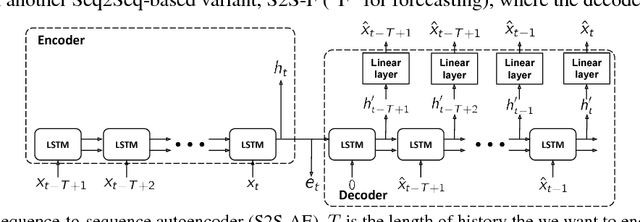

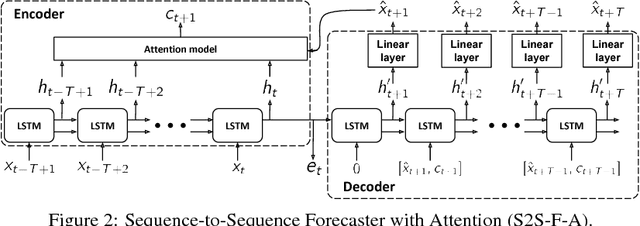
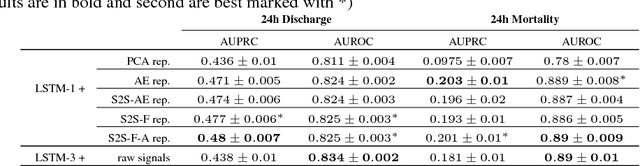
In this work, we investigate unsupervised representation learning on medical time series, which bears the promise of leveraging copious amounts of existing unlabeled data in order to eventually assist clinical decision making. By evaluating on the prediction of clinically relevant outcomes, we show that in a practical setting, unsupervised representation learning can offer clear performance benefits over end-to-end supervised architectures. We experiment with using sequence-to-sequence (Seq2Seq) models in two different ways, as an autoencoder and as a forecaster, and show that the best performance is achieved by a forecasting Seq2Seq model with an integrated attention mechanism, proposed here for the first time in the setting of unsupervised learning for medical time series.