 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLoopFM: Learning frOm HistOrical RePresentations of Foundation Model for Recommendation
May 28, 2026Knowledge distillation (KD) transfers a single scalar prediction from a large foundation model (FM) to compact vertical models (VMs), suffering from diminishing transfer ratio -- the fraction of FM improvement captured by the VM -- as a single scalar cannot convey the rich intermediate knowledge that larger FMs learn. To address this bottleneck, we propose LoopFM (Learning frOm HistOrical ReP*resentations of FM), a framework that opens a high-bandwidth transfer channel by structuring FM intermediate embeddings as input features (e.g., user history sequence) for downstream VMs, without requiring real-time FM inference at serving and architectural coupling between FM and VM. We provide a theoretical framework for LoopFM with a gain decomposition and transfer-ratio analysis. On three public benchmarks, LoopFM demonstrates strong AUC improvements (e.g., 6\%+ on TaobaoAd) and complementary knowledge transfer capability with KD. On industrial-scale systems (billions of examples, trillion-parameter FMs), LoopFM approximately doubles the knowledge transfer ratio on top of KD, delivering a +0.5\% conversion improvement in Y1H1, and a +1.03\% and +1.22\% conversion improvement from two individual launches respectively in Y1H2.
LoKA: Low-precision Kernel Applications for Recommendation Models At Scale
May 11, 2026Recent GPU generations deliver significantly higher FLOPs using lower-precision arithmetic, such as FP8. While successfully applied to large language models (LLMs), its adoption in large recommendation models (LRMs) has been limited. This is because LRMs are numerically sensitive, dominated by small matrix multiplications (GEMMs) followed by normalization, and trained in communication-intensive environments. Applying FP8 directly to LRMs often degrades model quality and prolongs training time. These challenges are inherent to LRM workloads and cannot be resolved merely by introducing better FP8 kernels. Instead, a system-model co-design approach is needed to successfully integrate FP8. We present LoKA (Low-precision Kernel Applications), a framework that makes FP8 practical for LRMs through three principles: profile under realistic distributions to know where low precision is safe, co-design model components with hardware to expand where it is safe, and orchestrate across kernel libraries to maximize the gains. Concretely, LoKA Probe is a statistically grounded, online benchmarking method that learns activation and weight statistics, and quantifies per-layer errors. This process pinpoints safe and unsafe, fast and slow sites for FP8 adoption. LoKA Mods is a set of reusable model adaptations that improve both numerical stability and execution efficiency with FP8. LoKA Dispatch is a runtime that leverages the statistical insights from LoKA Probe to select the fastest FP8 kernel that satisfies the accuracy requirements.
Kunlun: Establishing Scaling Laws for Massive-Scale Recommendation Systems through Unified Architecture Design
Feb 13, 2026Deriving predictable scaling laws that govern the relationship between model performance and computational investment is crucial for designing and allocating resources in massive-scale recommendation systems. While such laws are established for large language models, they remain challenging for recommendation systems, especially those processing both user history and context features. We identify poor scaling efficiency as the main barrier to predictable power-law scaling, stemming from inefficient modules with low Model FLOPs Utilization (MFU) and suboptimal resource allocation. We introduce Kunlun, a scalable architecture that systematically improves model efficiency and resource allocation. Our low-level optimizations include Generalized Dot-Product Attention (GDPA), Hierarchical Seed Pooling (HSP), and Sliding Window Attention. Our high-level innovations feature Computation Skip (CompSkip) and Event-level Personalization. These advances increase MFU from 17% to 37% on NVIDIA B200 GPUs and double scaling efficiency over state-of-the-art methods. Kunlun is now deployed in major Meta Ads models, delivering significant production impact.
Meta Lattice: Model Space Redesign for Cost-Effective Industry-Scale Ads Recommendations
Dec 15, 2025The rapidly evolving landscape of products, surfaces, policies, and regulations poses significant challenges for deploying state-of-the-art recommendation models at industry scale, primarily due to data fragmentation across domains and escalating infrastructure costs that hinder sustained quality improvements. To address this challenge, we propose Lattice, a recommendation framework centered around model space redesign that extends Multi-Domain, Multi-Objective (MDMO) learning beyond models and learning objectives. Lattice addresses these challenges through a comprehensive model space redesign that combines cross-domain knowledge sharing, data consolidation, model unification, distillation, and system optimizations to achieve significant improvements in both quality and cost-efficiency. Our deployment of Lattice at Meta has resulted in 10% revenue-driving top-line metrics gain, 11.5% user satisfaction improvement, 6% boost in conversion rate, with 20% capacity saving.
External Large Foundation Model: How to Efficiently Serve Trillions of Parameters for Online Ads Recommendation
Feb 26, 2025



Ads recommendation is a prominent service of online advertising systems and has been actively studied. Recent studies indicate that scaling-up and advanced design of the recommendation model can bring significant performance improvement. However, with a larger model scale, such prior studies have a significantly increasing gap from industry as they often neglect two fundamental challenges in industrial-scale applications. First, training and inference budgets are restricted for the model to be served, exceeding which may incur latency and impair user experience. Second, large-volume data arrive in a streaming mode with data distributions dynamically shifting, as new users/ads join and existing users/ads leave the system. We propose the External Large Foundation Model (ExFM) framework to address the overlooked challenges. Specifically, we develop external distillation and a data augmentation system (DAS) to control the computational cost of training/inference while maintaining high performance. We design the teacher in a way like a foundation model (FM) that can serve multiple students as vertical models (VMs) to amortize its building cost. We propose Auxiliary Head and Student Adapter to mitigate the data distribution gap between FM and VMs caused by the streaming data issue. Comprehensive experiments on internal industrial-scale applications and public datasets demonstrate significant performance gain by ExFM.
Towards Data Quality Assessment in Online Advertising
Nov 30, 2017
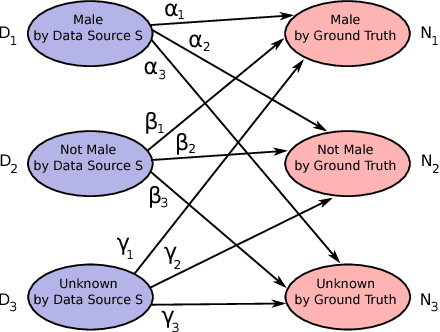
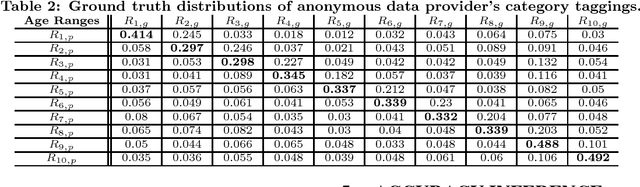
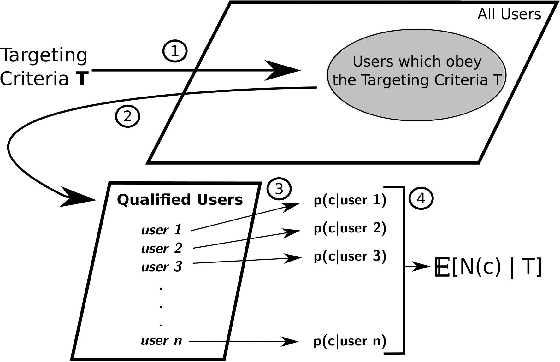
In online advertising, our aim is to match the advertisers with the most relevant users to optimize the campaign performance. In the pursuit of achieving this goal, multiple data sources provided by the advertisers or third-party data providers are utilized to choose the set of users according to the advertisers' targeting criteria. In this paper, we present a framework that can be applied to assess the quality of such data sources in large scale. This framework efficiently evaluates the similarity of a specific data source categorization to that of the ground truth, especially for those cases when the ground truth is accessible only in aggregate, and the user-level information is anonymized or unavailable due to privacy reasons. We propose multiple methodologies within this framework, present some preliminary assessment results, and evaluate how the methodologies compare to each other. We also present two use cases where we can utilize the data quality assessment results: the first use case is targeting specific user categories, and the second one is forecasting the desirable audiences we can reach for an online advertising campaign with pre-set targeting criteria.
* 10 pages, 7 Figures. This work has been presented in the KDD 2016 Workshop on Enterprise Intelligence
Scalable Audience Reach Estimation in Real-time Online Advertising
May 14, 2013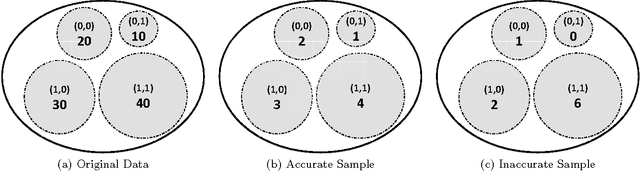

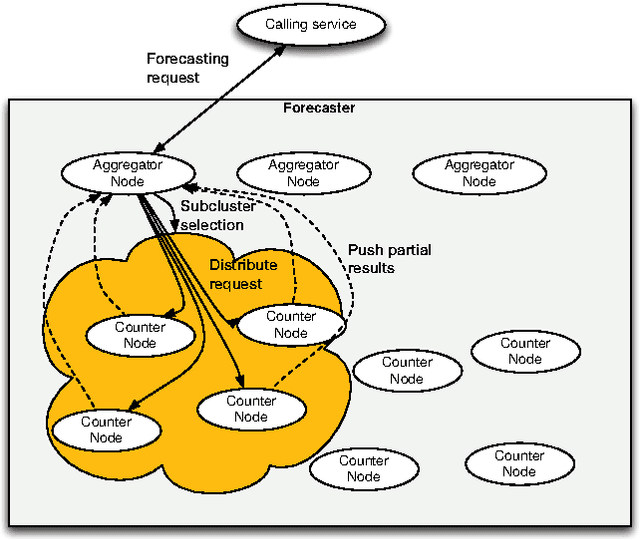
Online advertising has been introduced as one of the most efficient methods of advertising throughout the recent years. Yet, advertisers are concerned about the efficiency of their online advertising campaigns and consequently, would like to restrict their ad impressions to certain websites and/or certain groups of audience. These restrictions, known as targeting criteria, limit the reachability for better performance. This trade-off between reachability and performance illustrates a need for a forecasting system that can quickly predict/estimate (with good accuracy) this trade-off. Designing such a system is challenging due to (a) the huge amount of data to process, and, (b) the need for fast and accurate estimates. In this paper, we propose a distributed fault tolerant system that can generate such estimates fast with good accuracy. The main idea is to keep a small representative sample in memory across multiple machines and formulate the forecasting problem as queries against the sample. The key challenge is to find the best strata across the past data, perform multivariate stratified sampling while ensuring fuzzy fall-back to cover the small minorities. Our results show a significant improvement over the uniform and simple stratified sampling strategies which are currently widely used in the industry.