 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Unified Structured Query Understanding Framework for Industrial Semantic Search
May 22, 2026Query understanding in large-scale industrial search systems is typically implemented as a cascade of disparate, task-specific components. While individually optimizable, this fragmented architecture incurs high maintenance overhead and results in inconsistent behaviors, particularly for long-tail queries. In this work, we propose and deploy a unified structured query understanding system that consolidates these heterogeneous functions into a single Small Language Model (SLM) that performs schema-constrained generation. To address the data bottlenecks inherent in unified modeling, we introduce Query Illuminator, a dual-purpose framework serving as: (i) a teacher model for high-quality auto-annotation and distillation, and (ii) a surrogate judge for scalable evaluation where human labels are scarce. We validate this approach through extensive offline and online tests within LinkedIn's Job Search system. Furthermore, we demonstrate the framework's horizontal extensibility through a cross-domain case study on People Search. The results show improved user engagement and reduced operational costs, achieved while satisfying strict low-latency serving constraints on limited GPU resources.
Grounded Token Initialization for New Vocabulary in LMs for Generative Recommendation
Apr 02, 2026Language models (LMs) are increasingly extended with new learnable vocabulary tokens for domain-specific tasks, such as Semantic-ID tokens in generative recommendation. The standard practice initializes these new tokens as the mean of existing vocabulary embeddings, then relies on supervised fine-tuning to learn their representations. We present a systematic analysis of this strategy: through spectral and geometric diagnostics, we show that mean initialization collapses all new tokens into a degenerate subspace, erasing inter-token distinctions that subsequent fine-tuning struggles to fully recover. These findings suggest that \emph{token initialization} is a key bottleneck when extending LMs with new vocabularies. Motivated by this diagnosis, we propose the \emph{Grounded Token Initialization Hypothesis}: linguistically grounding novel tokens in the pretrained embedding space before fine-tuning better enables the model to leverage its general-purpose knowledge for novel-token domains. We operationalize this hypothesis as GTI (Grounded Token Initialization), a lightweight grounding stage that, prior to fine-tuning, maps new tokens to distinct, semantically meaningful locations in the pretrained embedding space using only paired linguistic supervision. Despite its simplicity, GTI outperforms both mean initialization and existing auxiliary-task adaptation methods in the majority of evaluation settings across multiple generative recommendation benchmarks, including industry-scale and public datasets. Further analyses show that grounded embeddings produce richer inter-token structure that persists through fine-tuning, corroborating the hypothesis that initialization quality is a key bottleneck in vocabulary extension.
SAGE: Scalable AI Governance & Evaluation
Feb 08, 2026Evaluating relevance in large-scale search systems is fundamentally constrained by the governance gap between nuanced, resource-constrained human oversight and the high-throughput requirements of production systems. While traditional approaches rely on engagement proxies or sparse manual review, these methods often fail to capture the full scope of high-impact relevance failures. We present \textbf{SAGE} (Scalable AI Governance \& Evaluation), a framework that operationalizes high-quality human product judgment as a scalable evaluation signal. At the core of SAGE is a bidirectional calibration loop where natural-language \emph{Policy}, curated \emph{Precedent}, and an \emph{LLM Surrogate Judge} co-evolve. SAGE systematically resolves semantic ambiguities and misalignments, transforming subjective relevance judgment into an executable, multi-dimensional rubric with near human-level agreement. To bridge the gap between frontier model reasoning and industrial-scale inference, we apply teacher-student distillation to transfer high-fidelity judgments into compact student surrogates at \textbf{92$\times$} lower cost. Deployed within LinkedIn Search ecosystems, SAGE guided model iteration through simulation-driven development, distilling policy-aligned models for online serving and enabling rapid offline evaluation. In production, it powered policy oversight that measured ramped model variants and detected regressions invisible to engagement metrics. Collectively, these drove a \textbf{0.25\%} lift in LinkedIn daily active users.
High Fidelity Textual User Representation over Heterogeneous Sources via Reinforcement Learning
Feb 07, 2026Effective personalization on large-scale job platforms requires modeling members based on heterogeneous textual sources, including profiles, professional data, and search activity logs. As recommender systems increasingly adopt Large Language Models (LLMs), creating unified, interpretable, and concise representations from heterogeneous sources becomes critical, especially for latency-sensitive online environments. In this work, we propose a novel Reinforcement Learning (RL) framework to synthesize a unified textual representation for each member. Our approach leverages implicit user engagement signals (e.g., clicks, applies) as the primary reward to distill salient information. Additionally, the framework is complemented by rule-based rewards that enforce formatting and length constraints. Extensive offline experiments across multiple LinkedIn products, one of the world's largest job platforms, demonstrate significant improvements in key downstream business metrics. This work provides a practical, labeling-free, and scalable solution for constructing interpretable user representations that are directly compatible with LLM-based systems.
Semantic Search At LinkedIn
Feb 07, 2026Semantic search with large language models (LLMs) enables retrieval by meaning rather than keyword overlap, but scaling it requires major inference efficiency advances. We present LinkedIn's LLM-based semantic search framework for AI Job Search and AI People Search, combining an LLM relevance judge, embedding-based retrieval, and a compact Small Language Model trained via multi-teacher distillation to jointly optimize relevance and engagement. A prefill-oriented inference architecture co-designed with model pruning, context compression, and text-embedding hybrid interactions boosts ranking throughput by over 75x under a fixed latency constraint while preserving near-teacher-level NDCG, enabling one of the first production LLM-based ranking systems with efficiency comparable to traditional approaches and delivering significant gains in quality and user engagement.
Learning to Retrieve for Job Matching
Feb 21, 2024



Web-scale search systems typically tackle the scalability challenge with a two-step paradigm: retrieval and ranking. The retrieval step, also known as candidate selection, often involves extracting standardized entities, creating an inverted index, and performing term matching for retrieval. Such traditional methods require manual and time-consuming development of query models. In this paper, we discuss applying learning-to-retrieve technology to enhance LinkedIns job search and recommendation systems. In the realm of promoted jobs, the key objective is to improve the quality of applicants, thereby delivering value to recruiter customers. To achieve this, we leverage confirmed hire data to construct a graph that evaluates a seeker's qualification for a job, and utilize learned links for retrieval. Our learned model is easy to explain, debug, and adjust. On the other hand, the focus for organic jobs is to optimize seeker engagement. We accomplished this by training embeddings for personalized retrieval, fortified by a set of rules derived from the categorization of member feedback. In addition to a solution based on a conventional inverted index, we developed an on-GPU solution capable of supporting both KNN and term matching efficiently.
LinkSAGE: Optimizing Job Matching Using Graph Neural Networks
Feb 20, 2024



We present LinkSAGE, an innovative framework that integrates Graph Neural Networks (GNNs) into large-scale personalized job matching systems, designed to address the complex dynamics of LinkedIns extensive professional network. Our approach capitalizes on a novel job marketplace graph, the largest and most intricate of its kind in industry, with billions of nodes and edges. This graph is not merely extensive but also richly detailed, encompassing member and job nodes along with key attributes, thus creating an expansive and interwoven network. A key innovation in LinkSAGE is its training and serving methodology, which effectively combines inductive graph learning on a heterogeneous, evolving graph with an encoder-decoder GNN model. This methodology decouples the training of the GNN model from that of existing Deep Neural Nets (DNN) models, eliminating the need for frequent GNN retraining while maintaining up-to-date graph signals in near realtime, allowing for the effective integration of GNN insights through transfer learning. The subsequent nearline inference system serves the GNN encoder within a real-world setting, significantly reducing online latency and obviating the need for costly real-time GNN infrastructure. Validated across multiple online A/B tests in diverse product scenarios, LinkSAGE demonstrates marked improvements in member engagement, relevance matching, and member retention, confirming its generalizability and practical impact.
Towards Data Quality Assessment in Online Advertising
Nov 30, 2017
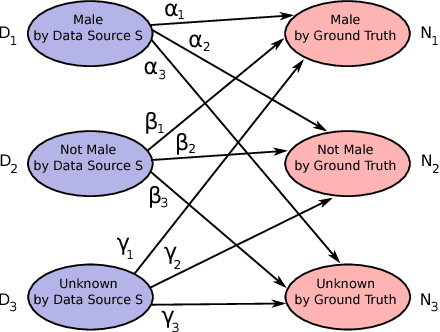
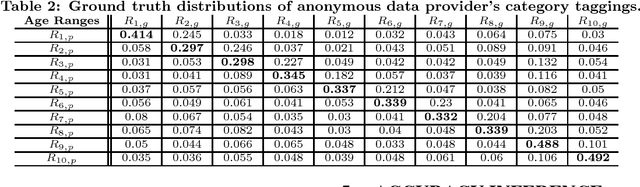
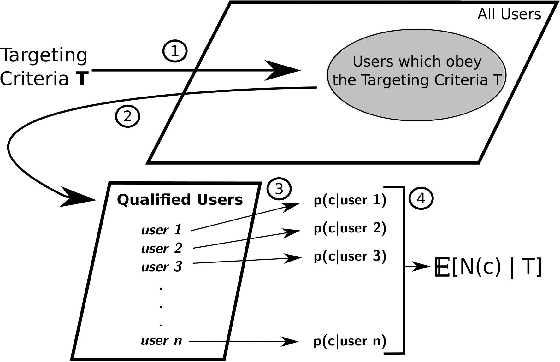
In online advertising, our aim is to match the advertisers with the most relevant users to optimize the campaign performance. In the pursuit of achieving this goal, multiple data sources provided by the advertisers or third-party data providers are utilized to choose the set of users according to the advertisers' targeting criteria. In this paper, we present a framework that can be applied to assess the quality of such data sources in large scale. This framework efficiently evaluates the similarity of a specific data source categorization to that of the ground truth, especially for those cases when the ground truth is accessible only in aggregate, and the user-level information is anonymized or unavailable due to privacy reasons. We propose multiple methodologies within this framework, present some preliminary assessment results, and evaluate how the methodologies compare to each other. We also present two use cases where we can utilize the data quality assessment results: the first use case is targeting specific user categories, and the second one is forecasting the desirable audiences we can reach for an online advertising campaign with pre-set targeting criteria.
* 10 pages, 7 Figures. This work has been presented in the KDD 2016 Workshop on Enterprise Intelligence