 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLoopFM: Learning frOm HistOrical RePresentations of Foundation Model for Recommendation
May 28, 2026Knowledge distillation (KD) transfers a single scalar prediction from a large foundation model (FM) to compact vertical models (VMs), suffering from diminishing transfer ratio -- the fraction of FM improvement captured by the VM -- as a single scalar cannot convey the rich intermediate knowledge that larger FMs learn. To address this bottleneck, we propose LoopFM (Learning frOm HistOrical ReP*resentations of FM), a framework that opens a high-bandwidth transfer channel by structuring FM intermediate embeddings as input features (e.g., user history sequence) for downstream VMs, without requiring real-time FM inference at serving and architectural coupling between FM and VM. We provide a theoretical framework for LoopFM with a gain decomposition and transfer-ratio analysis. On three public benchmarks, LoopFM demonstrates strong AUC improvements (e.g., 6\%+ on TaobaoAd) and complementary knowledge transfer capability with KD. On industrial-scale systems (billions of examples, trillion-parameter FMs), LoopFM approximately doubles the knowledge transfer ratio on top of KD, delivering a +0.5\% conversion improvement in Y1H1, and a +1.03\% and +1.22\% conversion improvement from two individual launches respectively in Y1H2.
Kunlun: Establishing Scaling Laws for Massive-Scale Recommendation Systems through Unified Architecture Design
Feb 13, 2026Deriving predictable scaling laws that govern the relationship between model performance and computational investment is crucial for designing and allocating resources in massive-scale recommendation systems. While such laws are established for large language models, they remain challenging for recommendation systems, especially those processing both user history and context features. We identify poor scaling efficiency as the main barrier to predictable power-law scaling, stemming from inefficient modules with low Model FLOPs Utilization (MFU) and suboptimal resource allocation. We introduce Kunlun, a scalable architecture that systematically improves model efficiency and resource allocation. Our low-level optimizations include Generalized Dot-Product Attention (GDPA), Hierarchical Seed Pooling (HSP), and Sliding Window Attention. Our high-level innovations feature Computation Skip (CompSkip) and Event-level Personalization. These advances increase MFU from 17% to 37% on NVIDIA B200 GPUs and double scaling efficiency over state-of-the-art methods. Kunlun is now deployed in major Meta Ads models, delivering significant production impact.
Meta Lattice: Model Space Redesign for Cost-Effective Industry-Scale Ads Recommendations
Dec 15, 2025The rapidly evolving landscape of products, surfaces, policies, and regulations poses significant challenges for deploying state-of-the-art recommendation models at industry scale, primarily due to data fragmentation across domains and escalating infrastructure costs that hinder sustained quality improvements. To address this challenge, we propose Lattice, a recommendation framework centered around model space redesign that extends Multi-Domain, Multi-Objective (MDMO) learning beyond models and learning objectives. Lattice addresses these challenges through a comprehensive model space redesign that combines cross-domain knowledge sharing, data consolidation, model unification, distillation, and system optimizations to achieve significant improvements in both quality and cost-efficiency. Our deployment of Lattice at Meta has resulted in 10% revenue-driving top-line metrics gain, 11.5% user satisfaction improvement, 6% boost in conversion rate, with 20% capacity saving.
External Large Foundation Model: How to Efficiently Serve Trillions of Parameters for Online Ads Recommendation
Feb 26, 2025



Ads recommendation is a prominent service of online advertising systems and has been actively studied. Recent studies indicate that scaling-up and advanced design of the recommendation model can bring significant performance improvement. However, with a larger model scale, such prior studies have a significantly increasing gap from industry as they often neglect two fundamental challenges in industrial-scale applications. First, training and inference budgets are restricted for the model to be served, exceeding which may incur latency and impair user experience. Second, large-volume data arrive in a streaming mode with data distributions dynamically shifting, as new users/ads join and existing users/ads leave the system. We propose the External Large Foundation Model (ExFM) framework to address the overlooked challenges. Specifically, we develop external distillation and a data augmentation system (DAS) to control the computational cost of training/inference while maintaining high performance. We design the teacher in a way like a foundation model (FM) that can serve multiple students as vertical models (VMs) to amortize its building cost. We propose Auxiliary Head and Student Adapter to mitigate the data distribution gap between FM and VMs caused by the streaming data issue. Comprehensive experiments on internal industrial-scale applications and public datasets demonstrate significant performance gain by ExFM.
DHEN: A Deep and Hierarchical Ensemble Network for Large-Scale Click-Through Rate Prediction
Mar 11, 2022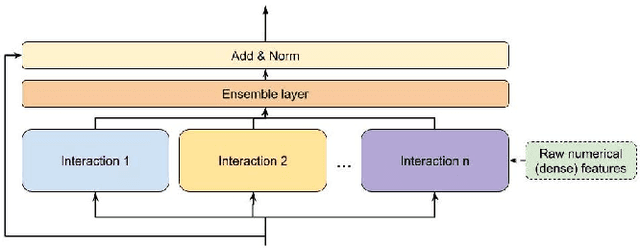
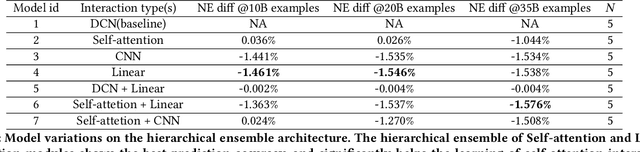
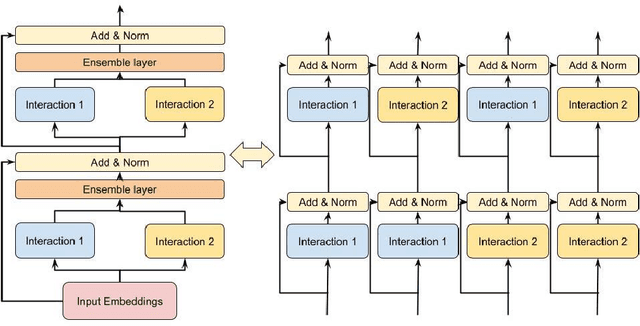

Learning feature interactions is important to the model performance of online advertising services. As a result, extensive efforts have been devoted to designing effective architectures to learn feature interactions. However, we observe that the practical performance of those designs can vary from dataset to dataset, even when the order of interactions claimed to be captured is the same. That indicates different designs may have different advantages and the interactions captured by them have non-overlapping information. Motivated by this observation, we propose DHEN - a deep and hierarchical ensemble architecture that can leverage strengths of heterogeneous interaction modules and learn a hierarchy of the interactions under different orders. To overcome the challenge brought by DHEN's deeper and multi-layer structure in training, we propose a novel co-designed training system that can further improve the training efficiency of DHEN. Experiments of DHEN on large-scale dataset from CTR prediction tasks attained 0.27\% improvement on the Normalized Entropy (NE) of prediction and 1.2x better training throughput than state-of-the-art baseline, demonstrating their effectiveness in practice.