 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInsights on representational similarity in neural networks with canonical correlation
Oct 23, 2018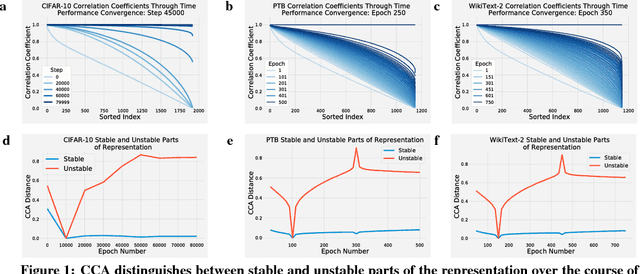
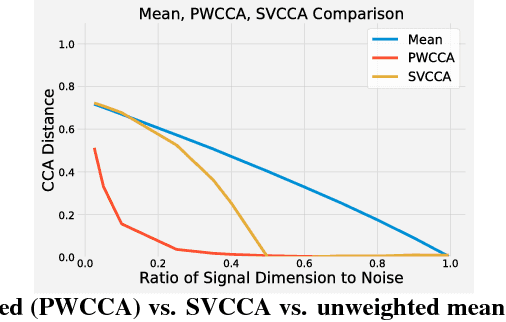
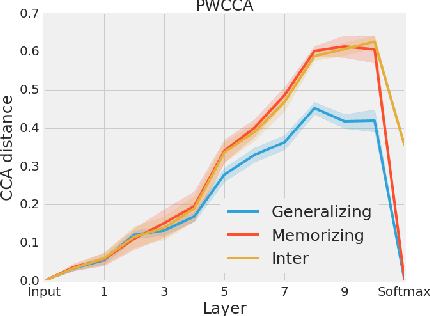
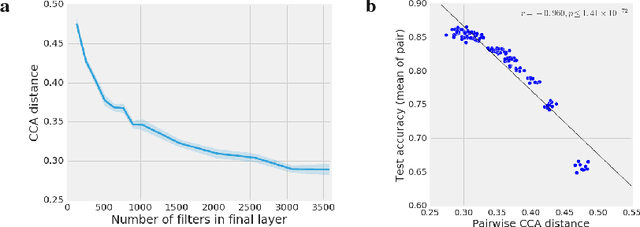
Comparing different neural network representations and determining how representations evolve over time remain challenging open questions in our understanding of the function of neural networks. Comparing representations in neural networks is fundamentally difficult as the structure of representations varies greatly, even across groups of networks trained on identical tasks, and over the course of training. Here, we develop projection weighted CCA (Canonical Correlation Analysis) as a tool for understanding neural networks, building off of SVCCA, a recently proposed method (Raghu et al., 2017). We first improve the core method, showing how to differentiate between signal and noise, and then apply this technique to compare across a group of CNNs, demonstrating that networks which generalize converge to more similar representations than networks which memorize, that wider networks converge to more similar solutions than narrow networks, and that trained networks with identical topology but different learning rates converge to distinct clusters with diverse representations. We also investigate the representational dynamics of RNNs, across both training and sequential timesteps, finding that RNNs converge in a bottom-up pattern over the course of training and that the hidden state is highly variable over the course of a sequence, even when accounting for linear transforms. Together, these results provide new insights into the function of CNNs and RNNs, and demonstrate the utility of using CCA to understand representations.
Predicting the Generalization Gap in Deep Networks with Margin Distributions
Sep 28, 2018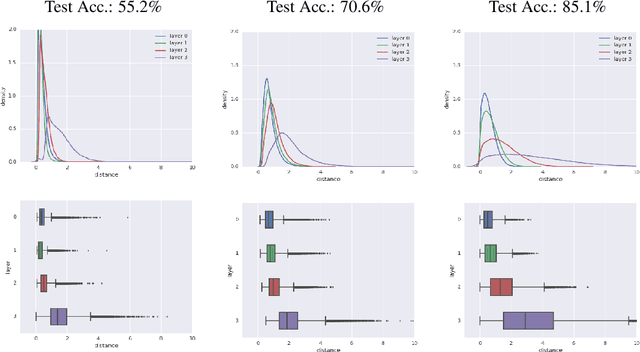
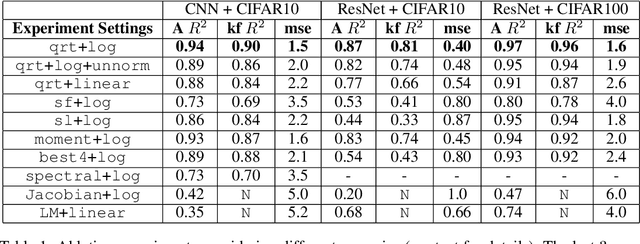
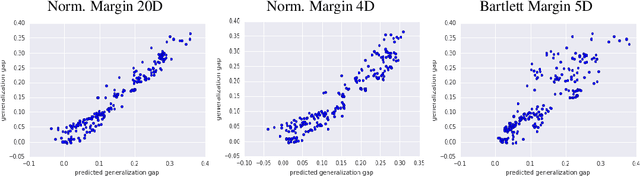
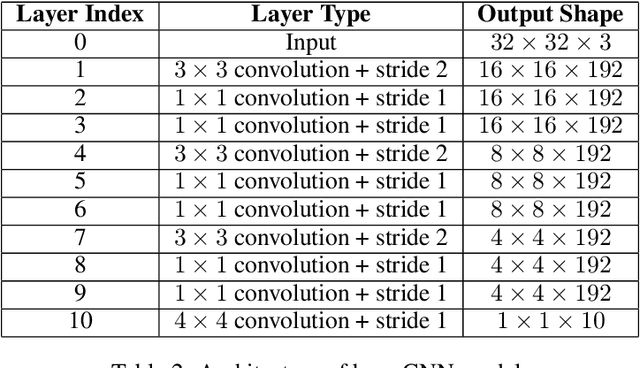
As shown in recent research, deep neural networks can perfectly fit randomly labeled data, but with very poor accuracy on held out data. This phenomenon indicates that loss functions such as cross-entropy are not a reliable indicator of generalization. This leads to the crucial question of how generalization gap should be predicted from the training data and network parameters. In this paper, we propose such a measure, and conduct extensive empirical studies on how well it can predict the generalization gap. Our measure is based on the concept of margin distribution, which are the distances of training points to the decision boundary. We find that it is necessary to use margin distributions at multiple layers of a deep network. On the CIFAR-10 and the CIFAR-100 datasets, our proposed measure correlates very strongly with the generalization gap. In addition, we find the following other factors to be of importance: normalizing margin values for scale independence, using characterizations of margin distribution rather than just the margin (closest distance to decision boundary), and working in log space instead of linear space (effectively using a product of margins rather than a sum). Our measure can be easily applied to feedforward deep networks with any architecture and may point towards new training loss functions that could enable better generalization.
Time-Dependent Representation for Neural Event Sequence Prediction
Jul 20, 2018
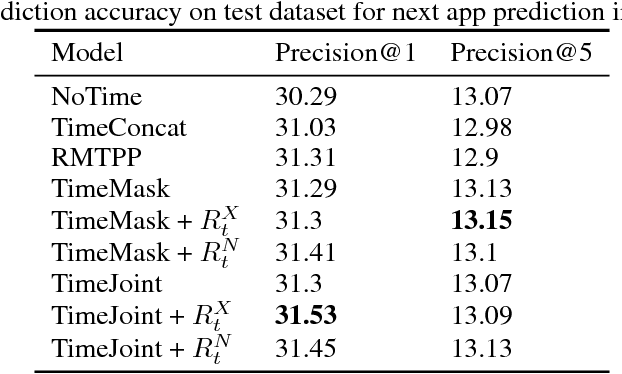
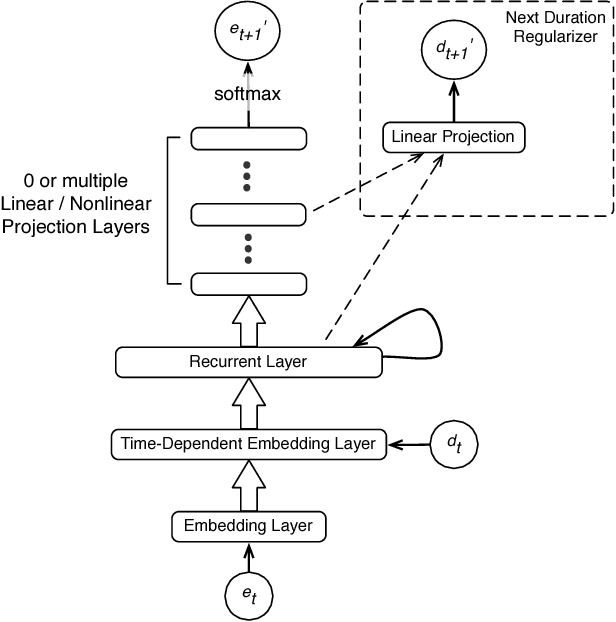
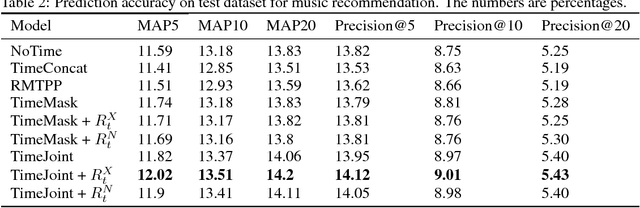
Existing sequence prediction methods are mostly concerned with time-independent sequences, in which the actual time span between events is irrelevant and the distance between events is simply the difference between their order positions in the sequence. While this time-independent view of sequences is applicable for data such as natural languages, e.g., dealing with words in a sentence, it is inappropriate and inefficient for many real world events that are observed and collected at unequally spaced points of time as they naturally arise, e.g., when a person goes to a grocery store or makes a phone call. The time span between events can carry important information about the sequence dependence of human behaviors. In this work, we propose a set of methods for using time in sequence prediction. Because neural sequence models such as RNN are more amenable for handling token-like input, we propose two methods for time-dependent event representation, based on the intuition on how time is tokenized in everyday life and previous work on embedding contextualization. We also introduce two methods for using next event duration as regularization for training a sequence prediction model. We discuss these methods based on recurrent neural nets. We evaluate these methods as well as baseline models on five datasets that resemble a variety of sequence prediction tasks. The experiments revealed that the proposed methods offer accuracy gain over baseline models in a range of settings.
Fast Decoding in Sequence Models using Discrete Latent Variables
Jun 07, 2018

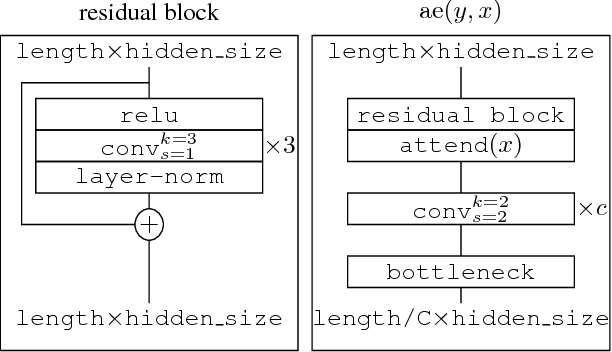
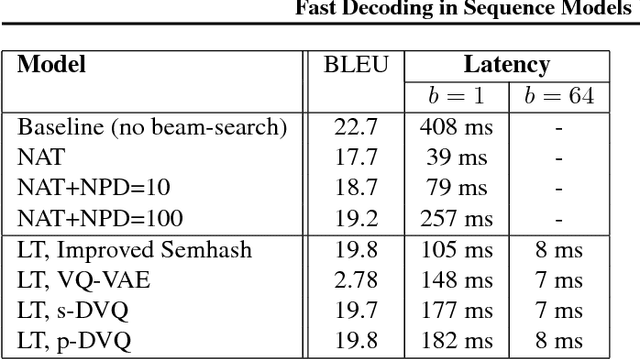
Autoregressive sequence models based on deep neural networks, such as RNNs, Wavenet and the Transformer attain state-of-the-art results on many tasks. However, they are difficult to parallelize and are thus slow at processing long sequences. RNNs lack parallelism both during training and decoding, while architectures like WaveNet and Transformer are much more parallelizable during training, yet still operate sequentially during decoding. Inspired by [arxiv:1711.00937], we present a method to extend sequence models using discrete latent variables that makes decoding much more parallelizable. We first auto-encode the target sequence into a shorter sequence of discrete latent variables, which at inference time is generated autoregressively, and finally decode the output sequence from this shorter latent sequence in parallel. To this end, we introduce a novel method for constructing a sequence of discrete latent variables and compare it with previously introduced methods. Finally, we evaluate our model end-to-end on the task of neural machine translation, where it is an order of magnitude faster at decoding than comparable autoregressive models. While lower in BLEU than purely autoregressive models, our model achieves higher scores than previously proposed non-autoregressive translation models.
A Study on Overfitting in Deep Reinforcement Learning
Apr 20, 2018
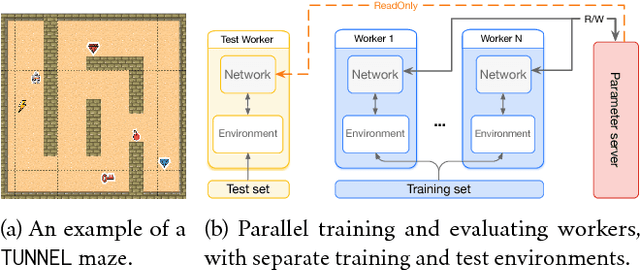
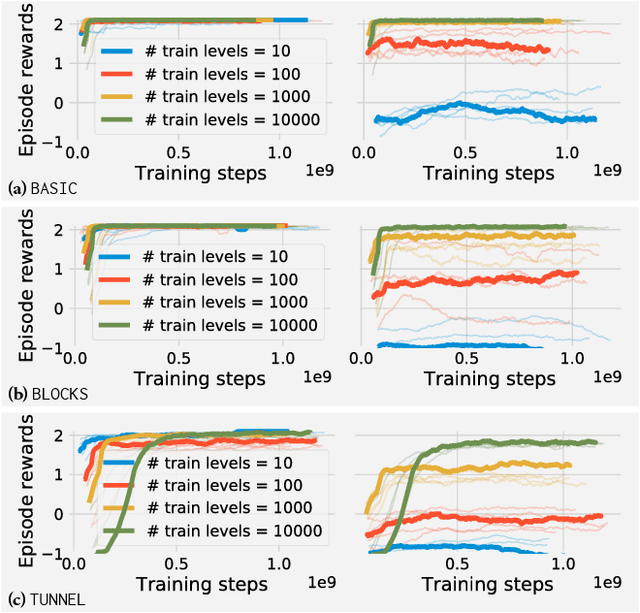

Recent years have witnessed significant progresses in deep Reinforcement Learning (RL). Empowered with large scale neural networks, carefully designed architectures, novel training algorithms and massively parallel computing devices, researchers are able to attack many challenging RL problems. However, in machine learning, more training power comes with a potential risk of more overfitting. As deep RL techniques are being applied to critical problems such as healthcare and finance, it is important to understand the generalization behaviors of the trained agents. In this paper, we conduct a systematic study of standard RL agents and find that they could overfit in various ways. Moreover, overfitting could happen "robustly": commonly used techniques in RL that add stochasticity do not necessarily prevent or detect overfitting. In particular, the same agents and learning algorithms could have drastically different test performance, even when all of them achieve optimal rewards during training. The observations call for more principled and careful evaluation protocols in RL. We conclude with a general discussion on overfitting in RL and a study of the generalization behaviors from the perspective of inductive bias.
Adversarial Attacks and Defences Competition
Mar 31, 2018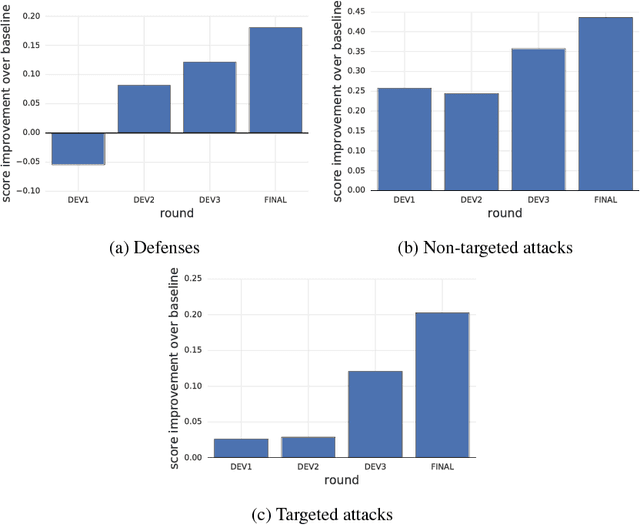
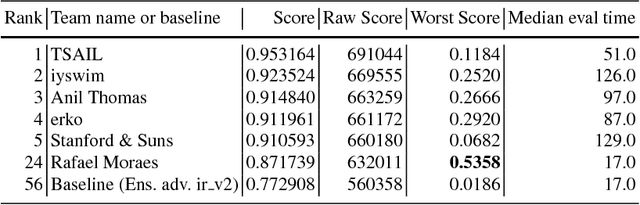
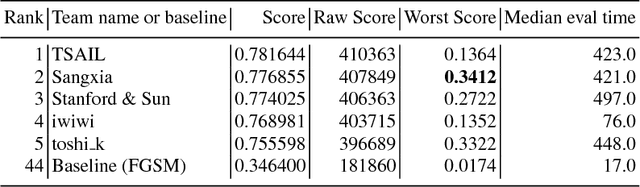
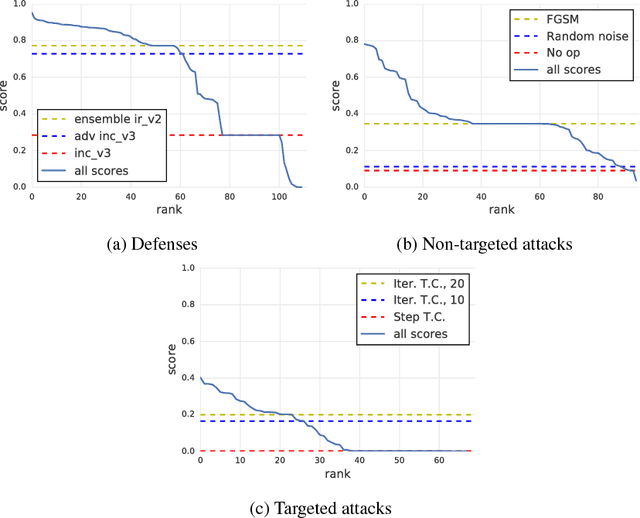
To accelerate research on adversarial examples and robustness of machine learning classifiers, Google Brain organized a NIPS 2017 competition that encouraged researchers to develop new methods to generate adversarial examples as well as to develop new ways to defend against them. In this chapter, we describe the structure and organization of the competition and the solutions developed by several of the top-placing teams.
Tensor2Tensor for Neural Machine Translation
Mar 16, 2018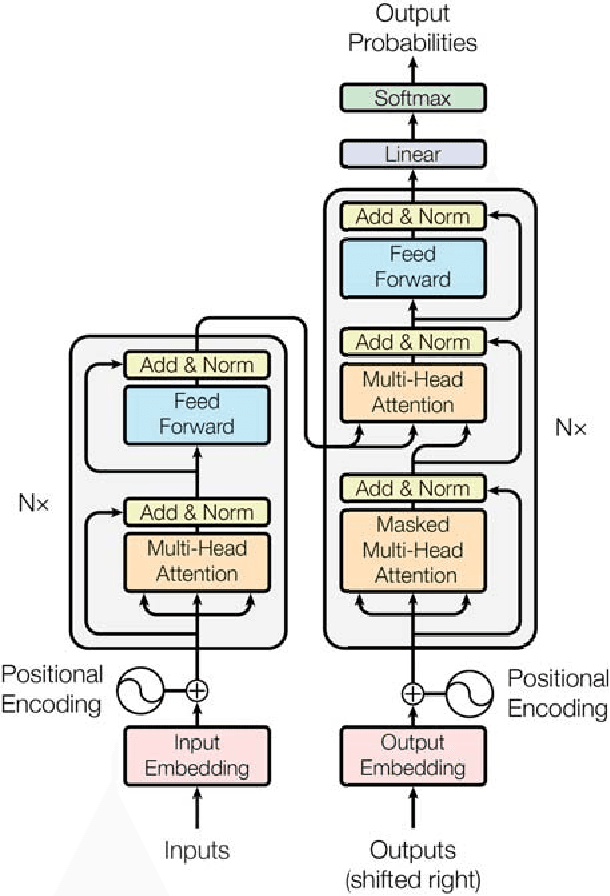
Tensor2Tensor is a library for deep learning models that is well-suited for neural machine translation and includes the reference implementation of the state-of-the-art Transformer model.
Large Margin Deep Networks for Classification
Mar 15, 2018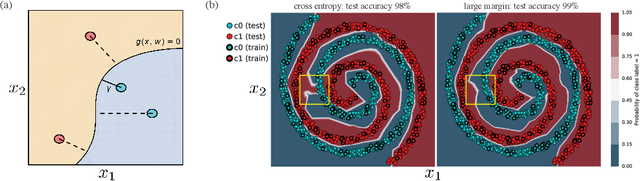
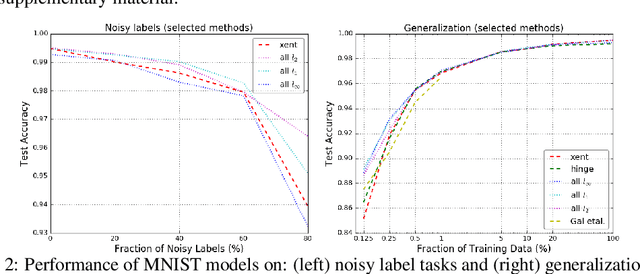
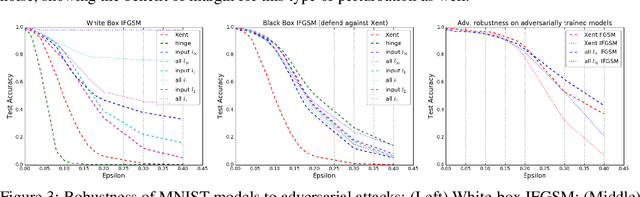
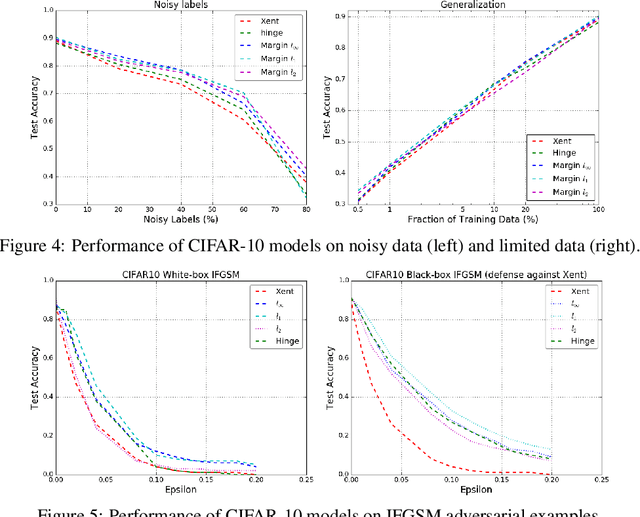
We present a formulation of deep learning that aims at producing a large margin classifier. The notion of margin, minimum distance to a decision boundary, has served as the foundation of several theoretically profound and empirically successful results for both classification and regression tasks. However, most large margin algorithms are applicable only to shallow models with a preset feature representation; and conventional margin methods for neural networks only enforce margin at the output layer. Such methods are therefore not well suited for deep networks. In this work, we propose a novel loss function to impose a margin on any chosen set of layers of a deep network (including input and hidden layers). Our formulation allows choosing any norm on the metric measuring the margin. We demonstrate that the decision boundary obtained by our loss has nice properties compared to standard classification loss functions. Specifically, we show improved empirical results on the MNIST, CIFAR-10 and ImageNet datasets on multiple tasks: generalization from small training sets, corrupted labels, and robustness against adversarial perturbations. The resulting loss is general and complementary to existing data augmentation (such as random/adversarial input transform) and regularization techniques (such as weight decay, dropout, and batch norm).
On Using Backpropagation for Speech Texture Generation and Voice Conversion
Mar 08, 2018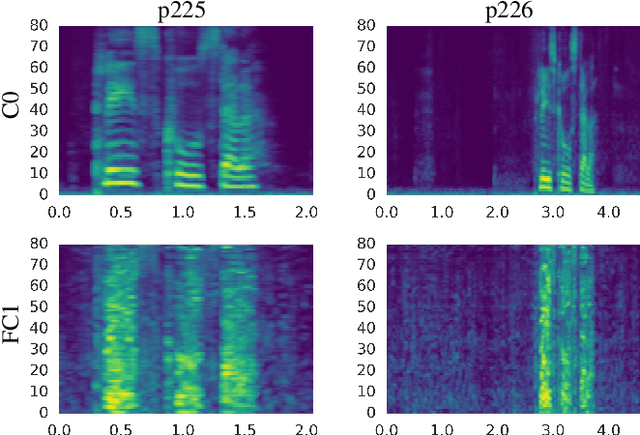
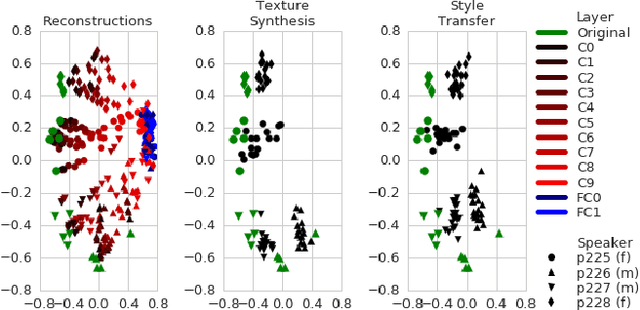
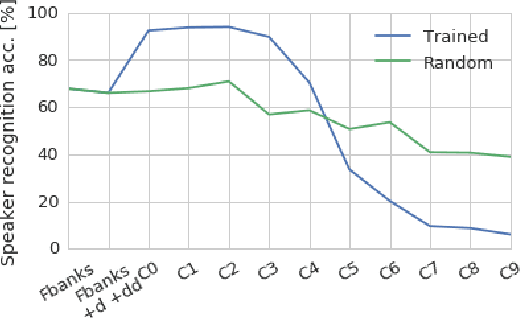
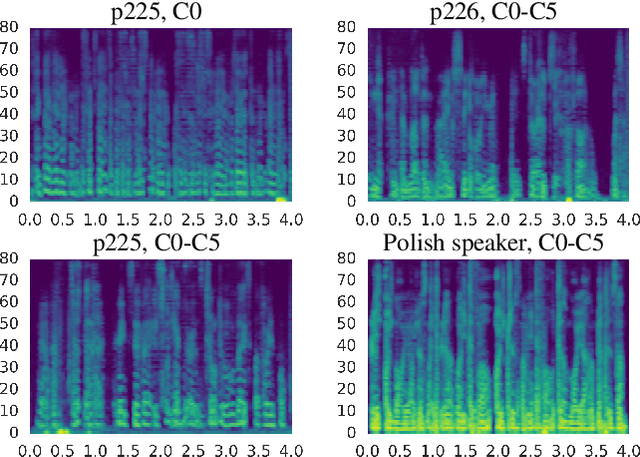
Inspired by recent work on neural network image generation which rely on backpropagation towards the network inputs, we present a proof-of-concept system for speech texture synthesis and voice conversion based on two mechanisms: approximate inversion of the representation learned by a speech recognition neural network, and on matching statistics of neuron activations between different source and target utterances. Similar to image texture synthesis and neural style transfer, the system works by optimizing a cost function with respect to the input waveform samples. To this end we use a differentiable mel-filterbank feature extraction pipeline and train a convolutional CTC speech recognition network. Our system is able to extract speaker characteristics from very limited amounts of target speaker data, as little as a few seconds, and can be used to generate realistic speech babble or reconstruct an utterance in a different voice.
Discrete Autoencoders for Sequence Models
Jan 29, 2018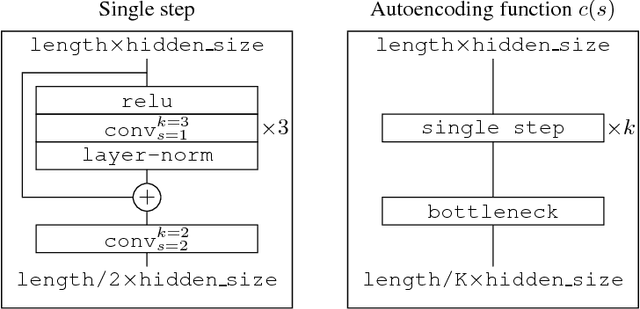
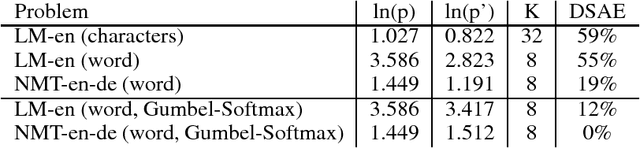
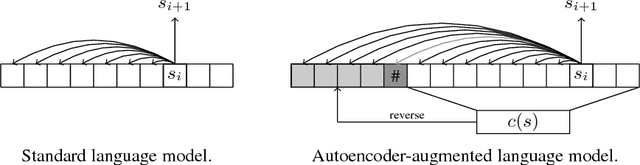
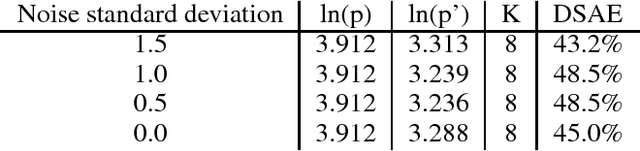
Recurrent models for sequences have been recently successful at many tasks, especially for language modeling and machine translation. Nevertheless, it remains challenging to extract good representations from these models. For instance, even though language has a clear hierarchical structure going from characters through words to sentences, it is not apparent in current language models. We propose to improve the representation in sequence models by augmenting current approaches with an autoencoder that is forced to compress the sequence through an intermediate discrete latent space. In order to propagate gradients though this discrete representation we introduce an improved semantic hashing technique. We show that this technique performs well on a newly proposed quantitative efficiency measure. We also analyze latent codes produced by the model showing how they correspond to words and phrases. Finally, we present an application of the autoencoder-augmented model to generating diverse translations.