 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Low Rank Training of Deep Neural Networks
Sep 27, 2022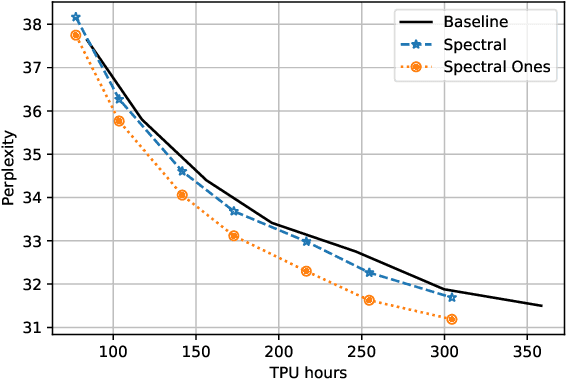

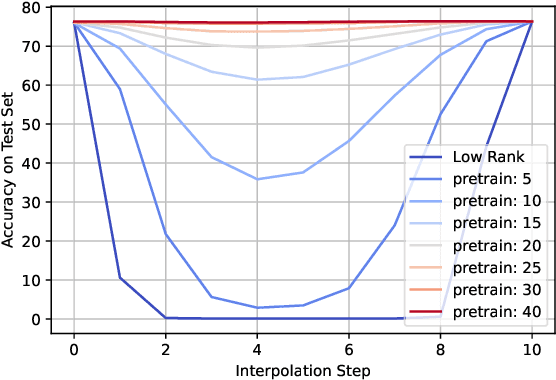
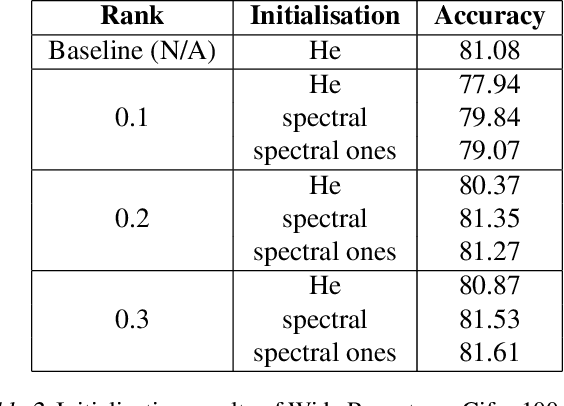
Training deep neural networks in low rank, i.e. with factorised layers, is of particular interest to the community: it offers efficiency over unfactorised training in terms of both memory consumption and training time. Prior work has focused on low rank approximations of pre-trained networks and training in low rank space with additional objectives, offering various ad hoc explanations for chosen practice. We analyse techniques that work well in practice, and through extensive ablations on models such as GPT2 we provide evidence falsifying common beliefs in the field, hinting in the process at exciting research opportunities that still need answering.
Prioritized Training on Points that are Learnable, Worth Learning, and Not Yet Learnt
Jun 16, 2022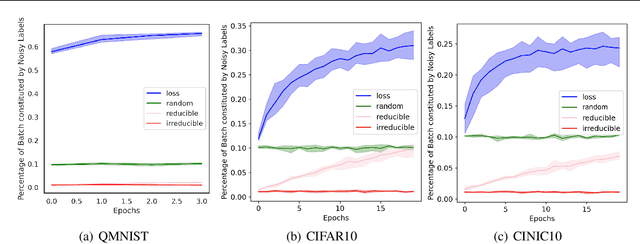
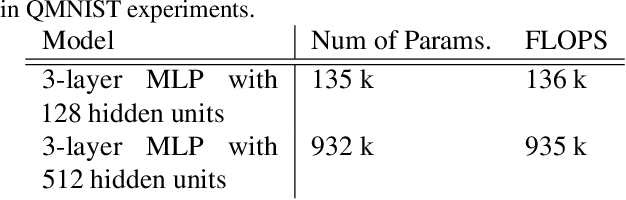
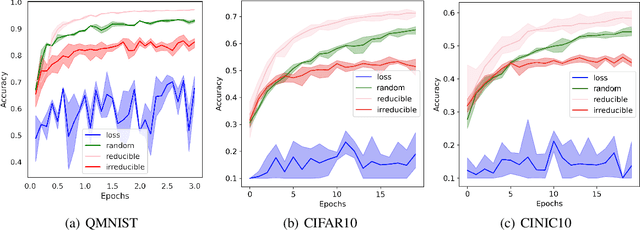
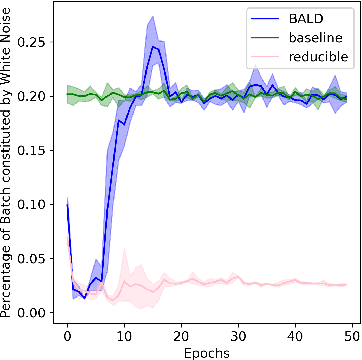
Training on web-scale data can take months. But most computation and time is wasted on redundant and noisy points that are already learnt or not learnable. To accelerate training, we introduce Reducible Holdout Loss Selection (RHO-LOSS), a simple but principled technique which selects approximately those points for training that most reduce the model's generalization loss. As a result, RHO-LOSS mitigates the weaknesses of existing data selection methods: techniques from the optimization literature typically select 'hard' (e.g. high loss) points, but such points are often noisy (not learnable) or less task-relevant. Conversely, curriculum learning prioritizes 'easy' points, but such points need not be trained on once learned. In contrast, RHO-LOSS selects points that are learnable, worth learning, and not yet learnt. RHO-LOSS trains in far fewer steps than prior art, improves accuracy, and speeds up training on a wide range of datasets, hyperparameters, and architectures (MLPs, CNNs, and BERT). On the large web-scraped image dataset Clothing-1M, RHO-LOSS trains in 18x fewer steps and reaches 2% higher final accuracy than uniform data shuffling.
Prioritized training on points that are learnable, worth learning, and not yet learned
Jul 06, 2021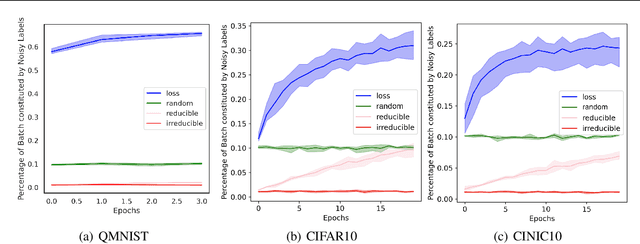
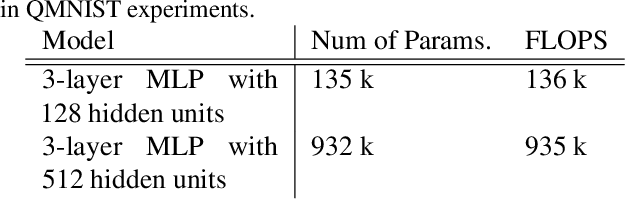
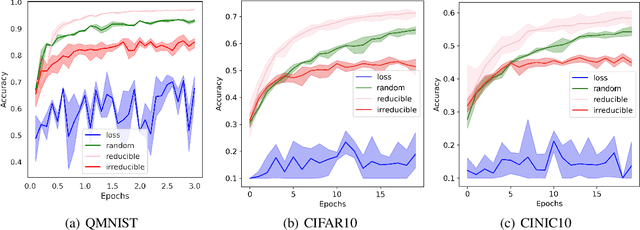
We introduce Goldilocks Selection, a technique for faster model training which selects a sequence of training points that are "just right". We propose an information-theoretic acquisition function -- the reducible validation loss -- and compute it with a small proxy model -- GoldiProx -- to efficiently choose training points that maximize information about a validation set. We show that the "hard" (e.g. high loss) points usually selected in the optimization literature are typically noisy, while the "easy" (e.g. low noise) samples often prioritized for curriculum learning confer less information. Further, points with uncertain labels, typically targeted by active learning, tend to be less relevant to the task. In contrast, Goldilocks Selection chooses points that are "just right" and empirically outperforms the above approaches. Moreover, the selected sequence can transfer to other architectures; practitioners can share and reuse it without the need to recreate it.
Self-Attention Between Datapoints: Going Beyond Individual Input-Output Pairs in Deep Learning
Jun 04, 2021
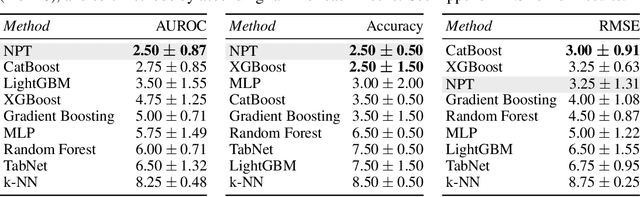
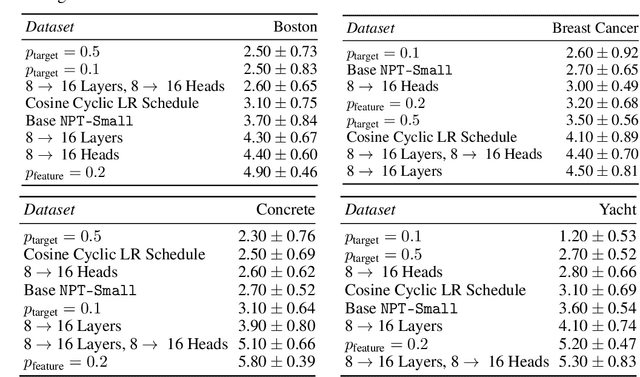
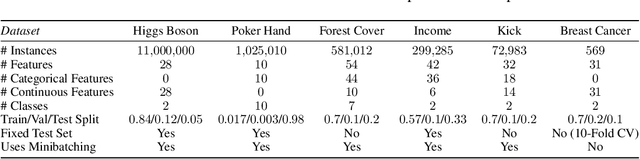
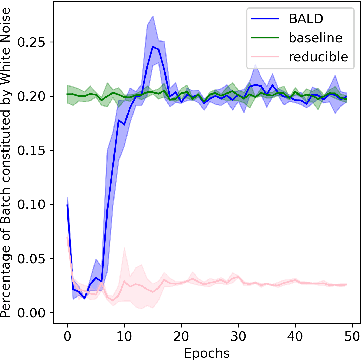
We challenge a common assumption underlying most supervised deep learning: that a model makes a prediction depending only on its parameters and the features of a single input. To this end, we introduce a general-purpose deep learning architecture that takes as input the entire dataset instead of processing one datapoint at a time. Our approach uses self-attention to reason about relationships between datapoints explicitly, which can be seen as realizing non-parametric models using parametric attention mechanisms. However, unlike conventional non-parametric models, we let the model learn end-to-end from the data how to make use of other datapoints for prediction. Empirically, our models solve cross-datapoint lookup and complex reasoning tasks unsolvable by traditional deep learning models. We show highly competitive results on tabular data, early results on CIFAR-10, and give insight into how the model makes use of the interactions between points.
Robustness to Pruning Predicts Generalization in Deep Neural Networks
Mar 10, 2021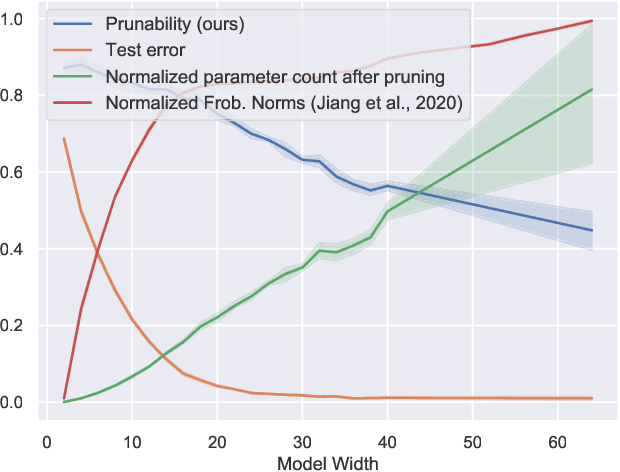
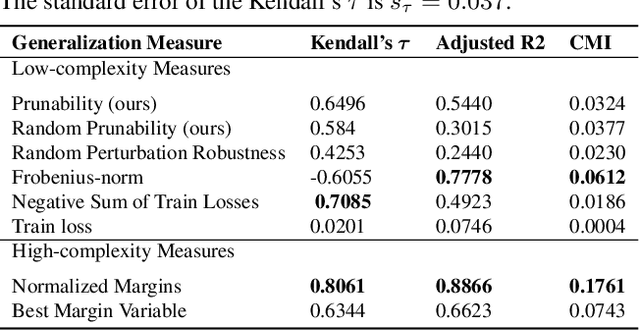
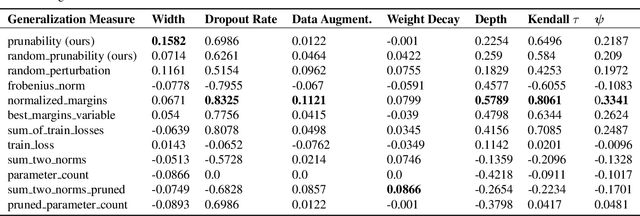
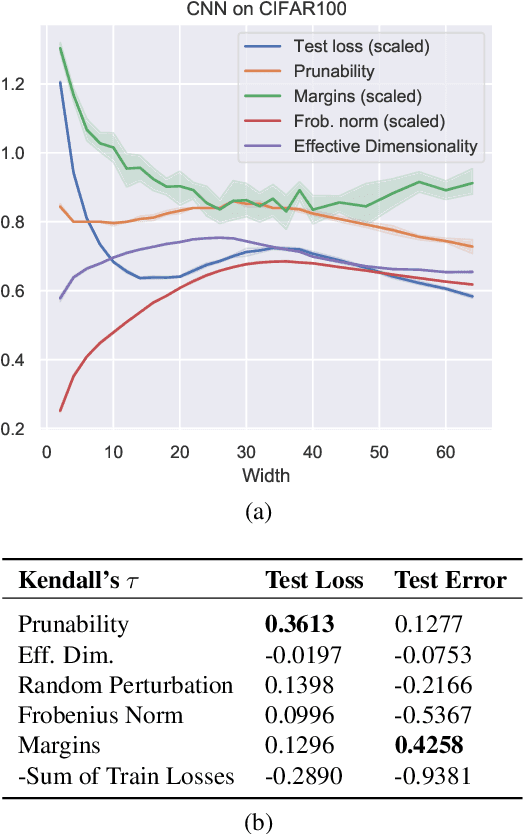
Existing generalization measures that aim to capture a model's simplicity based on parameter counts or norms fail to explain generalization in overparameterized deep neural networks. In this paper, we introduce a new, theoretically motivated measure of a network's simplicity which we call prunability: the smallest \emph{fraction} of the network's parameters that can be kept while pruning without adversely affecting its training loss. We show that this measure is highly predictive of a model's generalization performance across a large set of convolutional networks trained on CIFAR-10, does not grow with network size unlike existing pruning-based measures, and exhibits high correlation with test set loss even in a particularly challenging double descent setting. Lastly, we show that the success of prunability cannot be explained by its relation to known complexity measures based on models' margin, flatness of minima and optimization speed, finding that our new measure is similar to -- but more predictive than -- existing flatness-based measures, and that its predictions exhibit low mutual information with those of other baselines.
Interlocking Backpropagation: Improving depthwise model-parallelism
Oct 08, 2020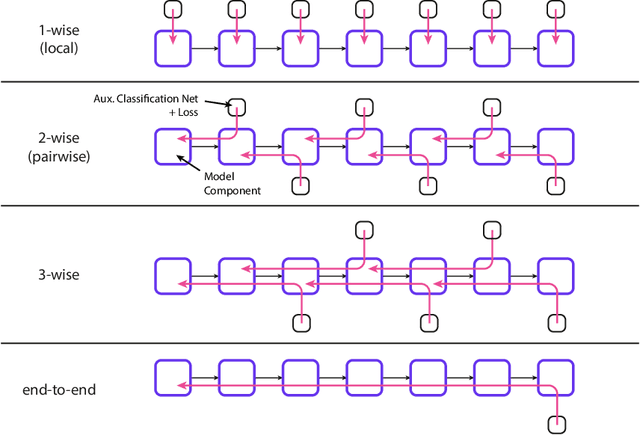

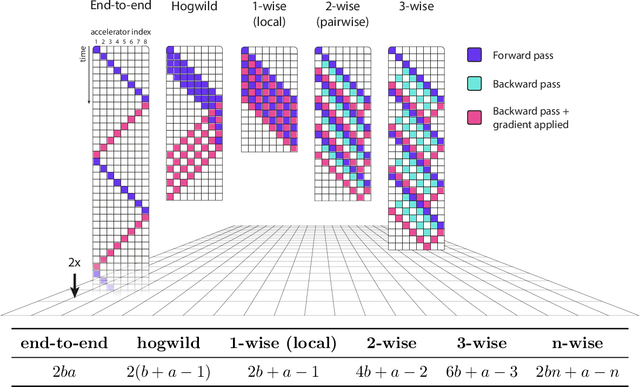
The number of parameters in state of the art neural networks has drastically increased in recent years. This surge of interest in large scale neural networks has motivated the development of new distributed training strategies enabling such models. One such strategy is model-parallel distributed training. Unfortunately, model-parallelism suffers from poor resource utilisation, which leads to wasted resources. In this work, we improve upon recent developments in an idealised model-parallel optimisation setting: local learning. Motivated by poor resource utilisation, we introduce a class of intermediary strategies between local and global learning referred to as interlocking backpropagation. These strategies preserve many of the compute-efficiency advantages of local optimisation, while recovering much of the task performance achieved by global optimisation. We assess our strategies on both image classification ResNets and Transformer language models, finding that our strategy consistently out-performs local learning in terms of task performance, and out-performs global learning in training efficiency.
SliceOut: Training Transformers and CNNs faster while using less memory
Jul 21, 2020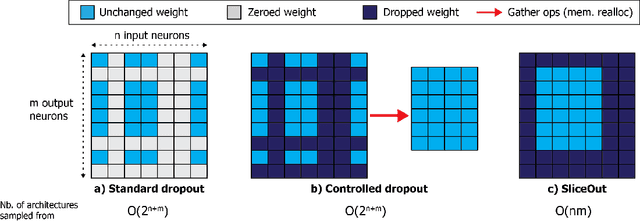
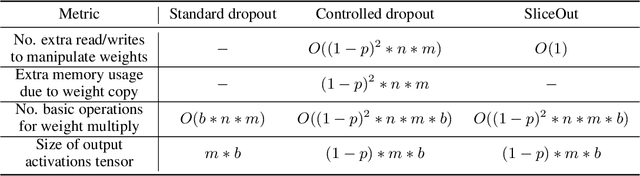
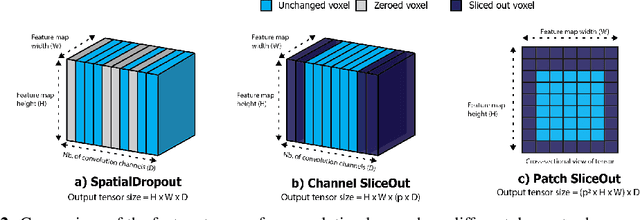
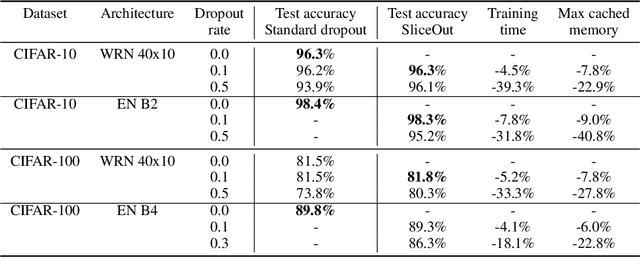
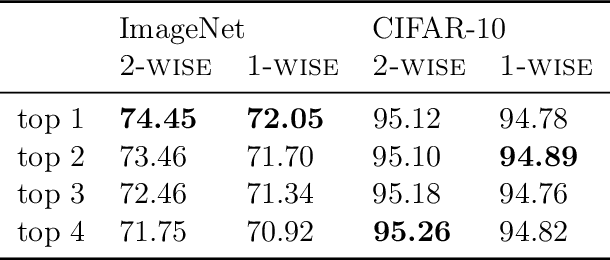
We demonstrate 10-40% speedups and memory reduction with Wide ResNets, EfficientNets, and Transformer models, with minimal to no loss in accuracy, using SliceOut---a new dropout scheme designed to take advantage of GPU memory layout. By dropping contiguous sets of units at random, our method preserves the regularization properties of dropout while allowing for more efficient low-level implementation, resulting in training speedups through (1) fast memory access and matrix multiplication of smaller tensors, and (2) memory savings by avoiding allocating memory to zero units in weight gradients and activations. Despite its simplicity, our method is highly effective. We demonstrate its efficacy at scale with Wide ResNets & EfficientNets on CIFAR10/100 and ImageNet, as well as Transformers on the LM1B dataset. These speedups and memory savings in training can lead to $CO_2$ emissions reduction of up to 40% for training large models.
Wat zei je? Detecting Out-of-Distribution Translations with Variational Transformers
Jun 08, 2020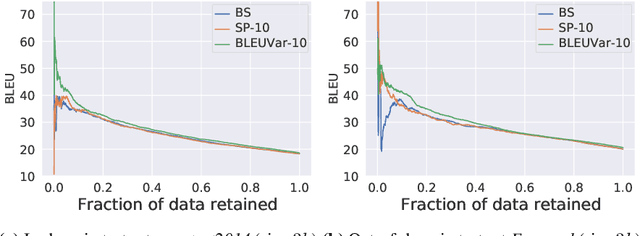
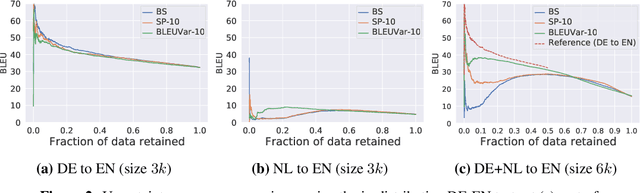
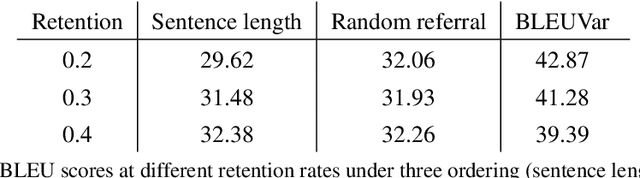
We detect out-of-training-distribution sentences in Neural Machine Translation using the Bayesian Deep Learning equivalent of Transformer models. For this we develop a new measure of uncertainty designed specifically for long sequences of discrete random variables -- i.e. words in the output sentence. Our new measure of uncertainty solves a major intractability in the naive application of existing approaches on long sentences. We use our new measure on a Transformer model trained with dropout approximate inference. On the task of German-English translation using WMT13 and Europarl, we show that with dropout uncertainty our measure is able to identify when Dutch source sentences, sentences which use the same word types as German, are given to the model instead of German.
A Systematic Comparison of Bayesian Deep Learning Robustness in Diabetic Retinopathy Tasks
Dec 22, 2019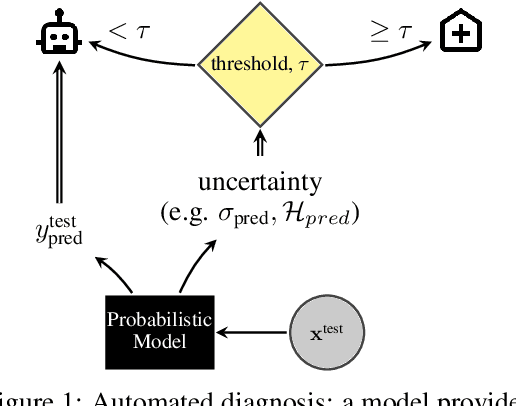
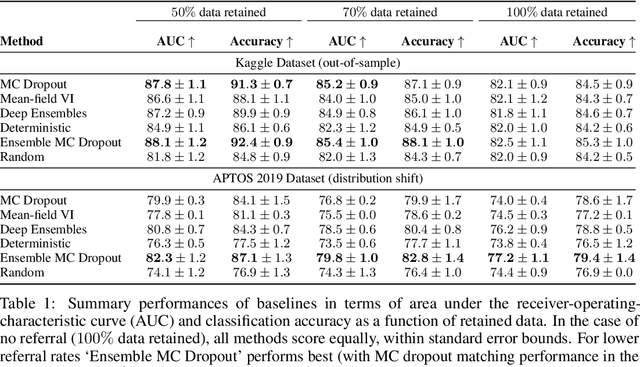
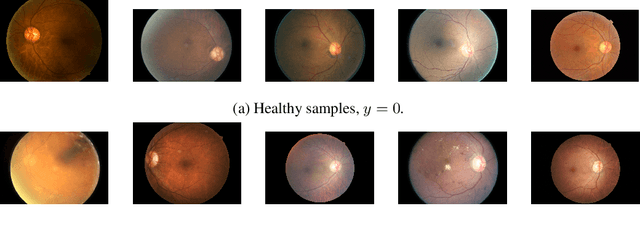
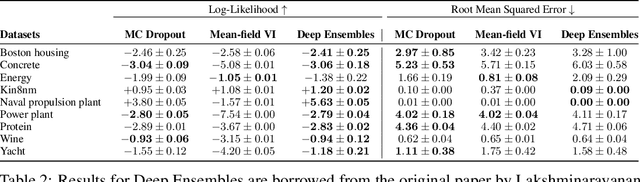
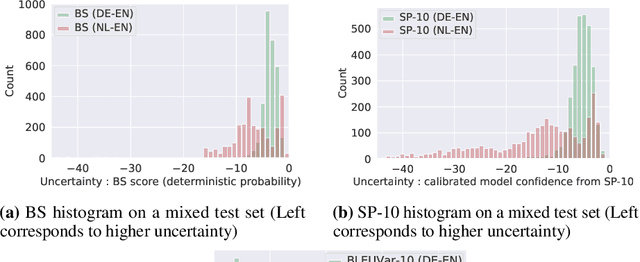
Evaluation of Bayesian deep learning (BDL) methods is challenging. We often seek to evaluate the methods' robustness and scalability, assessing whether new tools give `better' uncertainty estimates than old ones. These evaluations are paramount for practitioners when choosing BDL tools on-top of which they build their applications. Current popular evaluations of BDL methods, such as the UCI experiments, are lacking: Methods that excel with these experiments often fail when used in application such as medical or automotive, suggesting a pertinent need for new benchmarks in the field. We propose a new BDL benchmark with a diverse set of tasks, inspired by a real-world medical imaging application on \emph{diabetic retinopathy diagnosis}. Visual inputs (512x512 RGB images of retinas) are considered, where model uncertainty is used for medical pre-screening---i.e. to refer patients to an expert when model diagnosis is uncertain. Methods are then ranked according to metrics derived from expert-domain to reflect real-world use of model uncertainty in automated diagnosis. We develop multiple tasks that fall under this application, including out-of-distribution detection and robustness to distribution shift. We then perform a systematic comparison of well-tuned BDL techniques on the various tasks. From our comparison we conclude that some current techniques which solve benchmarks such as UCI `overfit' their uncertainty to the dataset---when evaluated on our benchmark these underperform in comparison to simpler baselines. The code for the benchmark, its baselines, and a simple API for evaluating new BDL tools are made available at https://github.com/oatml/bdl-benchmarks.
Learning Sparse Networks Using Targeted Dropout
Jun 05, 2019

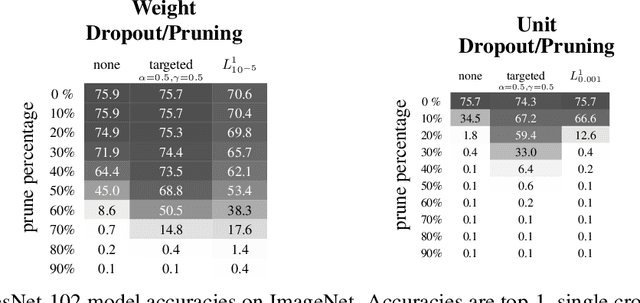
Neural networks are easier to optimise when they have many more weights than are required for modelling the mapping from inputs to outputs. This suggests a two-stage learning procedure that first learns a large net and then prunes away connections or hidden units. But standard training does not necessarily encourage nets to be amenable to pruning. We introduce targeted dropout, a method for training a neural network so that it is robust to subsequent pruning. Before computing the gradients for each weight update, targeted dropout stochastically selects a set of units or weights to be dropped using a simple self-reinforcing sparsity criterion and then computes the gradients for the remaining weights. The resulting network is robust to post hoc pruning of weights or units that frequently occur in the dropped sets. The method improves upon more complicated sparsifying regularisers while being simple to implement and easy to tune.