 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKick Bad Guys Out! Zero-Knowledge-Proof-Based Anomaly Detection in Federated Learning
Oct 06, 2023



Federated learning (FL) systems are vulnerable to malicious clients that submit poisoned local models to achieve their adversarial goals, such as preventing the convergence of the global model or inducing the global model to misclassify some data. Many existing defense mechanisms are impractical in real-world FL systems, as they require prior knowledge of the number of malicious clients or rely on re-weighting or modifying submissions. This is because adversaries typically do not announce their intentions before attacking, and re-weighting might change aggregation results even in the absence of attacks. To address these challenges in real FL systems, this paper introduces a cutting-edge anomaly detection approach with the following features: i) Detecting the occurrence of attacks and performing defense operations only when attacks happen; ii) Upon the occurrence of an attack, further detecting the malicious client models and eliminating them without harming the benign ones; iii) Ensuring honest execution of defense mechanisms at the server by leveraging a zero-knowledge proof mechanism. We validate the superior performance of the proposed approach with extensive experiments.
FedAIoT: A Federated Learning Benchmark for Artificial Intelligence of Things
Sep 29, 2023



There is a significant relevance of federated learning (FL) in the realm of Artificial Intelligence of Things (AIoT). However, most existing FL works are not conducted on datasets collected from authentic IoT devices that capture unique modalities and inherent challenges of IoT data. In this work, we introduce FedAIoT, an FL benchmark for AIoT to fill this critical gap. FedAIoT includes eight datatsets collected from a wide range of IoT devices. These datasets cover unique IoT modalities and target representative applications of AIoT. FedAIoT also includes a unified end-to-end FL framework for AIoT that simplifies benchmarking the performance of the datasets. Our benchmark results shed light on the opportunities and challenges of FL for AIoT. We hope FedAIoT could serve as an invaluable resource to foster advancements in the important field of FL for AIoT. The repository of FedAIoT is maintained at https://github.com/AIoT-MLSys-Lab/FedAIoT.
Federated Orthogonal Training: Mitigating Global Catastrophic Forgetting in Continual Federated Learning
Sep 03, 2023



Federated Learning (FL) has gained significant attraction due to its ability to enable privacy-preserving training over decentralized data. Current literature in FL mostly focuses on single-task learning. However, over time, new tasks may appear in the clients and the global model should learn these tasks without forgetting previous tasks. This real-world scenario is known as Continual Federated Learning (CFL). The main challenge of CFL is Global Catastrophic Forgetting, which corresponds to the fact that when the global model is trained on new tasks, its performance on old tasks decreases. There have been a few recent works on CFL to propose methods that aim to address the global catastrophic forgetting problem. However, these works either have unrealistic assumptions on the availability of past data samples or violate the privacy principles of FL. We propose a novel method, Federated Orthogonal Training (FOT), to overcome these drawbacks and address the global catastrophic forgetting in CFL. Our algorithm extracts the global input subspace of each layer for old tasks and modifies the aggregated updates of new tasks such that they are orthogonal to the global principal subspace of old tasks for each layer. This decreases the interference between tasks, which is the main cause for forgetting. We empirically show that FOT outperforms state-of-the-art continual learning methods in the CFL setting, achieving an average accuracy gain of up to 15% with 27% lower forgetting while only incurring a minimal computation and communication cost.
SLoRA: Federated Parameter Efficient Fine-Tuning of Language Models
Aug 12, 2023



Transfer learning via fine-tuning pre-trained transformer models has gained significant success in delivering state-of-the-art results across various NLP tasks. In the absence of centralized data, Federated Learning (FL) can benefit from distributed and private data of the FL edge clients for fine-tuning. However, due to the limited communication, computation, and storage capabilities of edge devices and the huge sizes of popular transformer models, efficient fine-tuning is crucial to make federated training feasible. This work explores the opportunities and challenges associated with applying parameter efficient fine-tuning (PEFT) methods in different FL settings for language tasks. Specifically, our investigation reveals that as the data across users becomes more diverse, the gap between fully fine-tuning the model and employing PEFT methods widens. To bridge this performance gap, we propose a method called SLoRA, which overcomes the key limitations of LoRA in high heterogeneous data scenarios through a novel data-driven initialization technique. Our experimental results demonstrate that SLoRA achieves performance comparable to full fine-tuning, with significant sparse updates with approximately $\sim 1\%$ density while reducing training time by up to $90\%$.
mL-BFGS: A Momentum-based L-BFGS for Distributed Large-Scale Neural Network Optimization
Jul 25, 2023Quasi-Newton methods still face significant challenges in training large-scale neural networks due to additional compute costs in the Hessian related computations and instability issues in stochastic training. A well-known method, L-BFGS that efficiently approximates the Hessian using history parameter and gradient changes, suffers convergence instability in stochastic training. So far, attempts that adapt L-BFGS to large-scale stochastic training incur considerable extra overhead, which offsets its convergence benefits in wall-clock time. In this paper, we propose mL-BFGS, a lightweight momentum-based L-BFGS algorithm that paves the way for quasi-Newton (QN) methods in large-scale distributed deep neural network (DNN) optimization. mL-BFGS introduces a nearly cost-free momentum scheme into L-BFGS update and greatly reduces stochastic noise in the Hessian, therefore stabilizing convergence during stochastic optimization. For model training at a large scale, mL-BFGS approximates a block-wise Hessian, thus enabling distributing compute and memory costs across all computing nodes. We provide a supporting convergence analysis for mL-BFGS in stochastic settings. To investigate mL-BFGS potential in large-scale DNN training, we train benchmark neural models using mL-BFGS and compare performance with baselines (SGD, Adam, and other quasi-Newton methods). Results show that mL-BFGS achieves both noticeable iteration-wise and wall-clock speedup.
Don't Memorize; Mimic The Past: Federated Class Incremental Learning Without Episodic Memory
Jul 17, 2023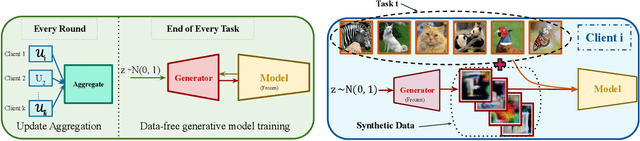
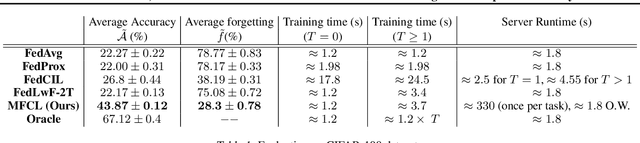

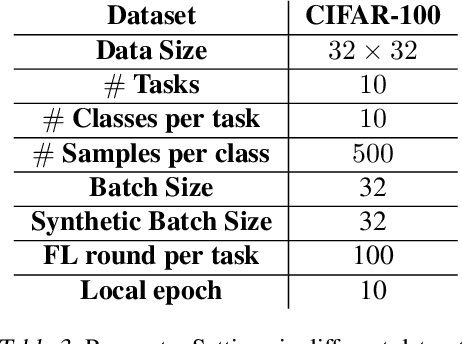
Deep learning models are prone to forgetting information learned in the past when trained on new data. This problem becomes even more pronounced in the context of federated learning (FL), where data is decentralized and subject to independent changes for each user. Continual Learning (CL) studies this so-called \textit{catastrophic forgetting} phenomenon primarily in centralized settings, where the learner has direct access to the complete training dataset. However, applying CL techniques to FL is not straightforward due to privacy concerns and resource limitations. This paper presents a framework for federated class incremental learning that utilizes a generative model to synthesize samples from past distributions instead of storing part of past data. Then, clients can leverage the generative model to mitigate catastrophic forgetting locally. The generative model is trained on the server using data-free methods at the end of each task without requesting data from clients. Therefore, it reduces the risk of data leakage as opposed to training it on the client's private data. We demonstrate significant improvements for the CIFAR-100 dataset compared to existing baselines.
FedMultimodal: A Benchmark For Multimodal Federated Learning
Jun 20, 2023Over the past few years, Federated Learning (FL) has become an emerging machine learning technique to tackle data privacy challenges through collaborative training. In the Federated Learning algorithm, the clients submit a locally trained model, and the server aggregates these parameters until convergence. Despite significant efforts that have been made to FL in fields like computer vision, audio, and natural language processing, the FL applications utilizing multimodal data streams remain largely unexplored. It is known that multimodal learning has broad real-world applications in emotion recognition, healthcare, multimedia, and social media, while user privacy persists as a critical concern. Specifically, there are no existing FL benchmarks targeting multimodal applications or related tasks. In order to facilitate the research in multimodal FL, we introduce FedMultimodal, the first FL benchmark for multimodal learning covering five representative multimodal applications from ten commonly used datasets with a total of eight unique modalities. FedMultimodal offers a systematic FL pipeline, enabling end-to-end modeling framework ranging from data partition and feature extraction to FL benchmark algorithms and model evaluation. Unlike existing FL benchmarks, FedMultimodal provides a standardized approach to assess the robustness of FL against three common data corruptions in real-life multimodal applications: missing modalities, missing labels, and erroneous labels. We hope that FedMultimodal can accelerate numerous future research directions, including designing multimodal FL algorithms toward extreme data heterogeneity, robustness multimodal FL, and efficient multimodal FL. The datasets and benchmark results can be accessed at: https://github.com/usc-sail/fed-multimodal.
FedMLSecurity: A Benchmark for Attacks and Defenses in Federated Learning and LLMs
Jun 08, 2023



This paper introduces FedMLSecurity, a benchmark that simulates adversarial attacks and corresponding defense mechanisms in Federated Learning (FL). As an integral module of the open-sourced library FedML that facilitates FL algorithm development and performance comparison, FedMLSecurity enhances the security assessment capacity of FedML. FedMLSecurity comprises two principal components: FedMLAttacker, which simulates attacks injected into FL training, and FedMLDefender, which emulates defensive strategies designed to mitigate the impacts of the attacks. FedMLSecurity is open-sourced 1 and is customizable to a wide range of machine learning models (e.g., Logistic Regression, ResNet, GAN, etc.) and federated optimizers (e.g., FedAVG, FedOPT, FedNOVA, etc.). Experimental evaluations in this paper also demonstrate the ease of application of FedMLSecurity to Large Language Models (LLMs), further reinforcing its versatility and practical utility in various scenarios.
GPT-FL: Generative Pre-trained Model-Assisted Federated Learning
Jun 03, 2023



In this work, we propose GPT-FL, a generative pre-trained model-assisted federated learning (FL) framework. At its core, GPT-FL leverages generative pre-trained models to generate diversified synthetic data. These generated data are used to train a downstream model on the server, which is then fine-tuned with private client data under the standard FL framework. We show that GPT-FL consistently outperforms state-of-the-art FL methods in terms of model test accuracy, communication efficiency, and client sampling efficiency. Through comprehensive ablation analysis, we discover that the downstream model generated by synthetic data plays a crucial role in controlling the direction of gradient diversity during FL training, which enhances convergence speed and contributes to the notable accuracy boost observed with GPT-FL. Also, regardless of whether the target data falls within or outside the domain of the pre-trained generative model, GPT-FL consistently achieves significant performance gains, surpassing the results obtained by models trained solely with FL or synthetic data.
Federated Alternate Training (FAT): Leveraging Unannotated Data Silos in Federated Segmentation for Medical Imaging
Apr 18, 2023Federated Learning (FL) aims to train a machine learning (ML) model in a distributed fashion to strengthen data privacy with limited data migration costs. It is a distributed learning framework naturally suitable for privacy-sensitive medical imaging datasets. However, most current FL-based medical imaging works assume silos have ground truth labels for training. In practice, label acquisition in the medical field is challenging as it often requires extensive labor and time costs. To address this challenge and leverage the unannotated data silos to improve modeling, we propose an alternate training-based framework, Federated Alternate Training (FAT), that alters training between annotated data silos and unannotated data silos. Annotated data silos exploit annotations to learn a reasonable global segmentation model. Meanwhile, unannotated data silos use the global segmentation model as a target model to generate pseudo labels for self-supervised learning. We evaluate the performance of the proposed framework on two naturally partitioned Federated datasets, KiTS19 and FeTS2021, and show its promising performance.