 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Surgical Situational Awareness with Signed Distance Field: A Pilot Study in Virtual Reality
Mar 03, 2023



The introduction of image-guided surgical navigation (IGSN) has greatly benefited technically demanding surgical procedures by providing real-time support and guidance to the surgeon during surgery. To develop effective IGSN, a careful selection of the information provided to the surgeon is needed. However, identifying optimal feedback modalities is challenging due to the broad array of available options. To address this problem, we have developed an open-source library that facilitates the development of multimodal navigation systems in a wide range of surgical procedures relying on medical imaging data. To provide guidance, our system calculates the minimum distance between the surgical instrument and the anatomy and then presents this information to the user through different mechanisms. The real-time performance of our approach is achieved by calculating Signed Distance Fields at initialization from segmented anatomical volumes. Using this framework, we developed a multimodal surgical navigation system to help surgeons navigate anatomical variability in a skull-base surgery simulation environment. Three different feedback modalities were explored: visual, auditory, and haptic. To evaluate the proposed system, a pilot user study was conducted in which four clinicians performed mastoidectomy procedures with and without guidance. Each condition was assessed using objective performance and subjective workload metrics. This pilot user study showed improvements in procedural safety without additional time or workload. These results demonstrate our pipeline's successful use case in the context of mastoidectomy.
Fully Immersive Virtual Reality for Skull-base Surgery: Surgical Training and Beyond
Feb 27, 2023Purpose: A fully immersive virtual reality system (FIVRS), where surgeons can practice procedures on virtual anatomies, is a scalable and cost-effective alternative to cadaveric training. The fully digitized virtual surgeries can also be used to assess the surgeon's skills automatically using metrics that are otherwise hard to collect in reality. Thus, we present FIVRS, a virtual reality (VR) system designed for skull-base surgery, which combines high-fidelity surgical simulation software with a real hardware setup. Methods: FIVRS integrates software and hardware features to allow surgeons to use normal clinical workflows for VR. FIVRS uses advanced rendering designs and drilling algorithms for realistic surgery. We also design a head-mounted display with ergonomics similar to that of surgical microscopes. A plethora of digitized data of VR surgery are recorded, including eye gaze, motion, force and video of the surgery for post-analysis. A user-friendly interface is also designed to ease the learning curve of using FIVRS. Results: We present results from a user study involving surgeons to showcase the efficacy FIVRS and its generated data. Conclusion: We present FIVRS, a fully immersive VR system for skull base surgery. FIVRS features a realistic software simulation coupled with modern hardware for improved realism. The system is completely open-source and provides feature-rich data in an industry-standard format.
TAToo: Vision-based Joint Tracking of Anatomy and Tool for Skull-base Surgery
Dec 29, 2022Purpose: Tracking the 3D motion of the surgical tool and the patient anatomy is a fundamental requirement for computer-assisted skull-base surgery. The estimated motion can be used both for intra-operative guidance and for downstream skill analysis. Recovering such motion solely from surgical videos is desirable, as it is compliant with current clinical workflows and instrumentation. Methods: We present Tracker of Anatomy and Tool (TAToo). TAToo jointly tracks the rigid 3D motion of patient skull and surgical drill from stereo microscopic videos. TAToo estimates motion via an iterative optimization process in an end-to-end differentiable form. For robust tracking performance, TAToo adopts a probabilistic formulation and enforces geometric constraints on the object level. Results: We validate TAToo on both simulation data, where ground truth motion is available, as well as on anthropomorphic phantom data, where optical tracking provides a strong baseline. We report sub-millimeter and millimeter inter-frame tracking accuracy for skull and drill, respectively, with rotation errors below 1{\deg}. We further illustrate how TAToo may be used in a surgical navigation setting. Conclusion: We present TAToo, which simultaneously tracks the surgical tool and the patient anatomy in skull-base surgery. TAToo directly predicts the motion from surgical videos, without the need of any markers. Our results show that the performance of TAToo compares favorably to competing approaches. Future work will include fine-tuning of our depth network to reach a 1 mm clinical accuracy goal desired for surgical applications in the skull base.
Twin-S: A Digital Twin for Skull-base Surgery
Nov 21, 2022



Purpose: Digital twins are virtual interactive models of the real world, exhibiting identical behavior and properties. In surgical applications, computational analysis from digital twins can be used, for example, to enhance situational awareness. Methods: We present a digital twin framework for skull-base surgeries, named Twin-S, which can be integrated within various image-guided interventions seamlessly. Twin-S combines high-precision optical tracking and real-time simulation. We rely on rigorous calibration routines to ensure that the digital twin representation precisely mimics all real-world processes. Twin-S models and tracks the critical components of skull-base surgery, including the surgical tool, patient anatomy, and surgical camera. Significantly, Twin-S updates and reflects real-world drilling of the anatomical model in frame rate. Results: We extensively evaluate the accuracy of Twin-S, which achieves an average 1.39 mm error during the drilling process. We further illustrate how segmentation masks derived from the continuously updated digital twin can augment the surgical microscope view in a mixed reality setting, where bone requiring ablation is highlighted to provide surgeons additional situational awareness. Conclusion: We present Twin-S, a digital twin environment for skull-base surgery. Twin-S tracks and updates the virtual model in real-time given measurements from modern tracking technologies. Future research on complementing optical tracking with higher-precision vision-based approaches may further increase the accuracy of Twin-S.
SyntheX: Scaling Up Learning-based X-ray Image Analysis Through In Silico Experiments
Jun 13, 2022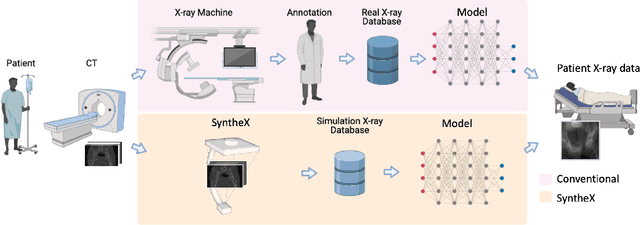

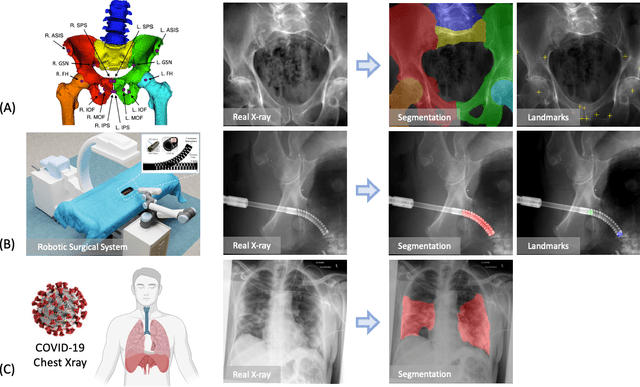

Artificial intelligence (AI) now enables automated interpretation of medical images for clinical use. However, AI's potential use for interventional images (versus those involved in triage or diagnosis), such as for guidance during surgery, remains largely untapped. This is because surgical AI systems are currently trained using post hoc analysis of data collected during live surgeries, which has fundamental and practical limitations, including ethical considerations, expense, scalability, data integrity, and a lack of ground truth. Here, we demonstrate that creating realistic simulated images from human models is a viable alternative and complement to large-scale in situ data collection. We show that training AI image analysis models on realistically synthesized data, combined with contemporary domain generalization or adaptation techniques, results in models that on real data perform comparably to models trained on a precisely matched real data training set. Because synthetic generation of training data from human-based models scales easily, we find that our model transfer paradigm for X-ray image analysis, which we refer to as SyntheX, can even outperform real data-trained models due to the effectiveness of training on a larger dataset. We demonstrate the potential of SyntheX on three clinical tasks: Hip image analysis, surgical robotic tool detection, and COVID-19 lung lesion segmentation. SyntheX provides an opportunity to drastically accelerate the conception, design, and evaluation of intelligent systems for X-ray-based medicine. In addition, simulated image environments provide the opportunity to test novel instrumentation, design complementary surgical approaches, and envision novel techniques that improve outcomes, save time, or mitigate human error, freed from the ethical and practical considerations of live human data collection.
SAGE: SLAM with Appearance and Geometry Prior for Endoscopy
Feb 22, 2022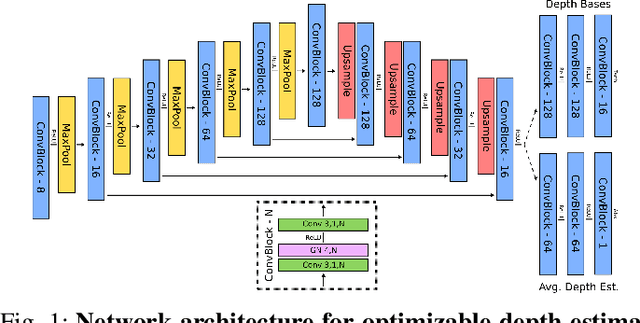
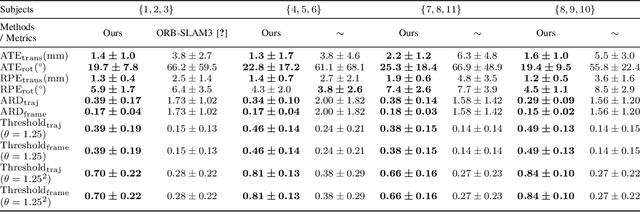
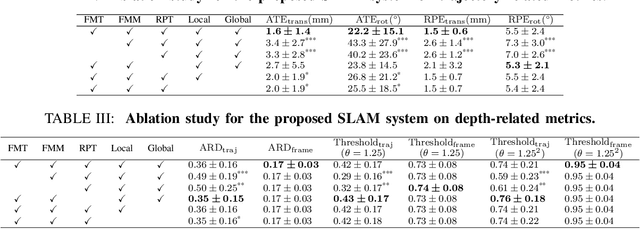
In endoscopy, many applications (e.g., surgical navigation) would benefit from a real-time method that can simultaneously track the endoscope and reconstruct the dense 3D geometry of the observed anatomy from a monocular endoscopic video. To this end, we develop a Simultaneous Localization and Mapping system by combining the learning-based appearance and optimizable geometry priors and factor graph optimization. The appearance and geometry priors are explicitly learned in an end-to-end differentiable training pipeline to master the task of pair-wise image alignment, one of the core components of the SLAM system. In our experiments, the proposed SLAM system is shown to robustly handle the challenges of texture scarceness and illumination variation that are commonly seen in endoscopy. The system generalizes well to unseen endoscopes and subjects and performs favorably compared with a state-of-the-art feature-based SLAM system. The code repository is available at https://github.com/lppllppl920/SAGE-SLAM.git.
Integrating Artificial Intelligence and Augmented Reality in Robotic Surgery: An Initial dVRK Study Using a Surgical Education Scenario
Jan 02, 2022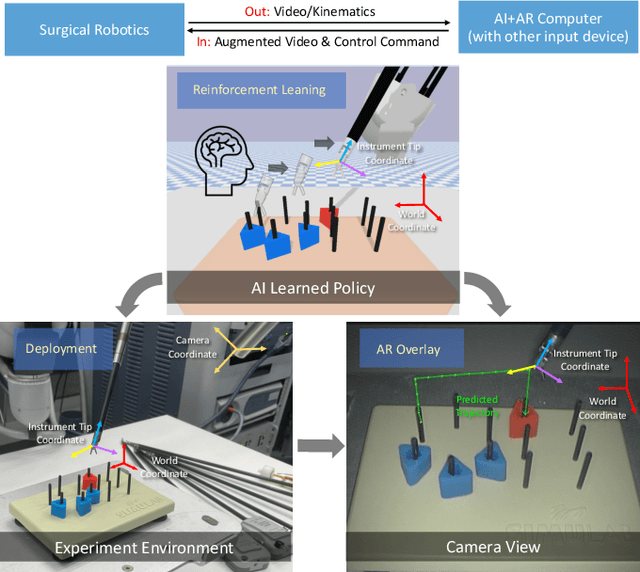
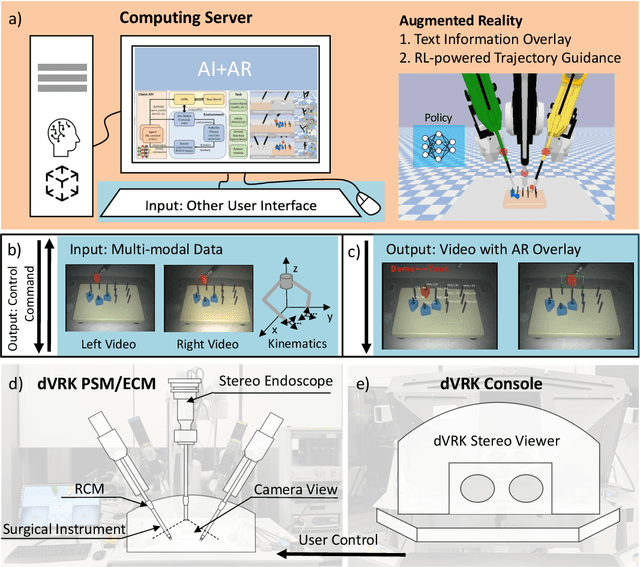

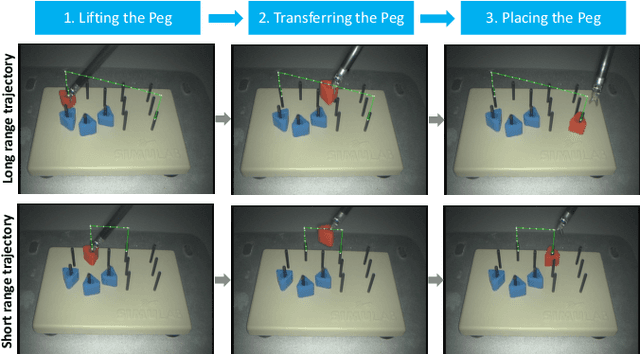
The demand of competent robot assisted surgeons is progressively expanding, because robot-assisted surgery has become progressively more popular due to its clinical advantages. To meet this demand and provide a better surgical education for surgeon, we develop a novel robotic surgery education system by integrating artificial intelligence surgical module and augmented reality visualization. The artificial intelligence incorporates reinforcement leaning to learn from expert demonstration and then generate 3D guidance trajectory, providing surgical context awareness of the complete surgical procedure. The trajectory information is further visualized in stereo viewer in the dVRK along with other information such as text hint, where the user can perceive the 3D guidance and learn the procedure. The proposed system is evaluated through a preliminary experiment on surgical education task peg-transfer, which proves its feasibility and potential as the next generation of robot-assisted surgery education solution.
Temporally Consistent Online Depth Estimation in Dynamic Scenes
Nov 17, 2021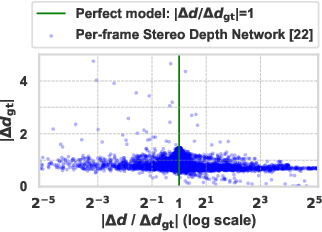
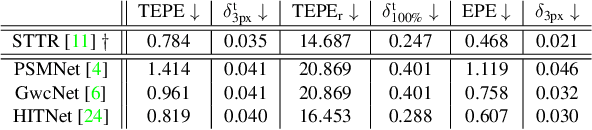
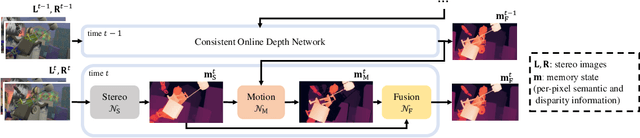
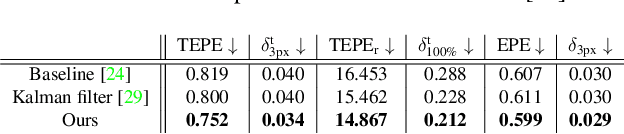
Temporally consistent depth estimation is crucial for real-time applications such as augmented reality. While stereo depth estimation has received substantial attention that led to improvements on a frame-by-frame basis, there is relatively little work focused on maintaining temporal consistency across frames. Indeed, based on our analysis, current stereo depth estimation techniques still suffer from poor temporal consistency. Stabilizing depth temporally in dynamic scenes is challenging due to concurrent object and camera motion. In an online setting, this process is further aggravated because only past frames are available. In this paper, we present a technique to produce temporally consistent depth estimates in dynamic scenes in an online setting. Our network augments current per-frame stereo networks with novel motion and fusion networks. The motion network accounts for both object and camera motion by predicting a per-pixel SE3 transformation. The fusion network improves consistency in prediction by aggregating the current and previous predictions with regressed weights. We conduct extensive experiments across varied datasets (synthetic, outdoor, indoor and medical). In both zero-shot generalization and domain fine-tuning, we demonstrate that our proposed approach outperforms competing methods in terms of temporal stability and per-frame accuracy, both quantitatively and qualitatively. Our code will be available online.
Virtual Reality for Synergistic Surgical Training and Data Generation
Nov 15, 2021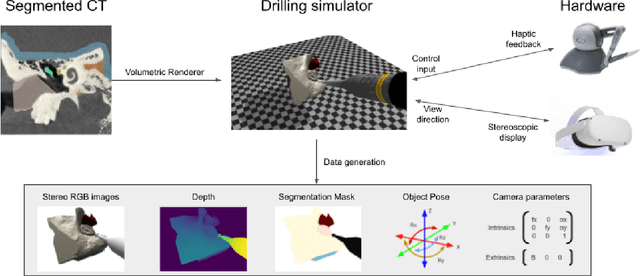
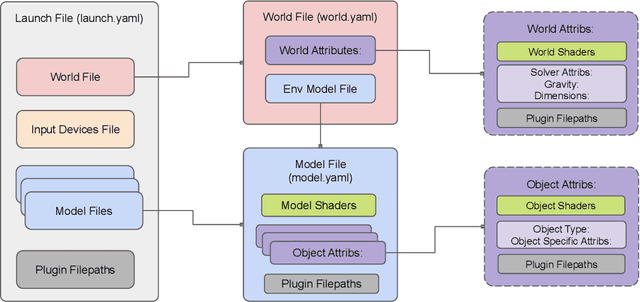
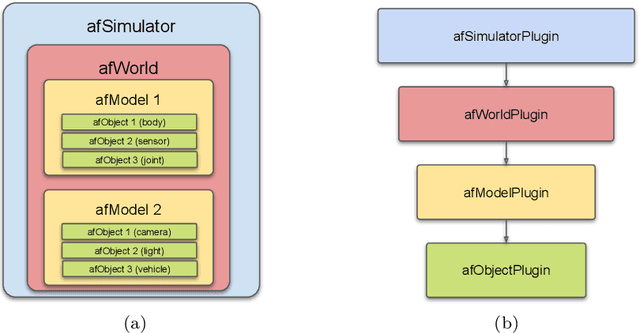
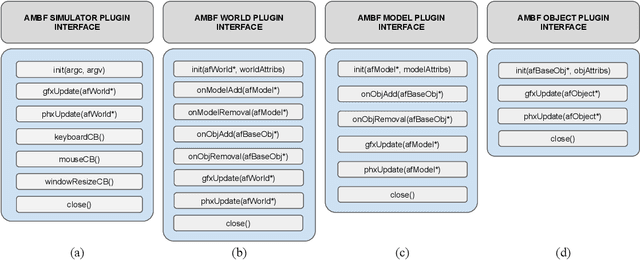
Surgical simulators not only allow planning and training of complex procedures, but also offer the ability to generate structured data for algorithm development, which may be applied in image-guided computer assisted interventions. While there have been efforts on either developing training platforms for surgeons or data generation engines, these two features, to our knowledge, have not been offered together. We present our developments of a cost-effective and synergistic framework, named Asynchronous Multibody Framework Plus (AMBF+), which generates data for downstream algorithm development simultaneously with users practicing their surgical skills. AMBF+ offers stereoscopic display on a virtual reality (VR) device and haptic feedback for immersive surgical simulation. It can also generate diverse data such as object poses and segmentation maps. AMBF+ is designed with a flexible plugin setup which allows for unobtrusive extension for simulation of different surgical procedures. We show one use case of AMBF+ as a virtual drilling simulator for lateral skull-base surgery, where users can actively modify the patient anatomy using a virtual surgical drill. We further demonstrate how the data generated can be used for validating and training downstream computer vision algorithms
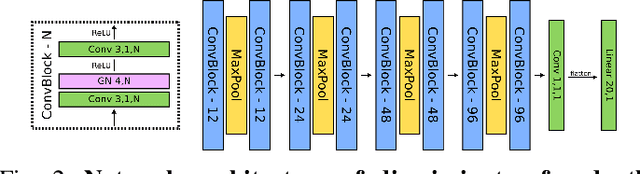
On the Sins of Image Synthesis Loss for Self-supervised Depth Estimation
Sep 13, 2021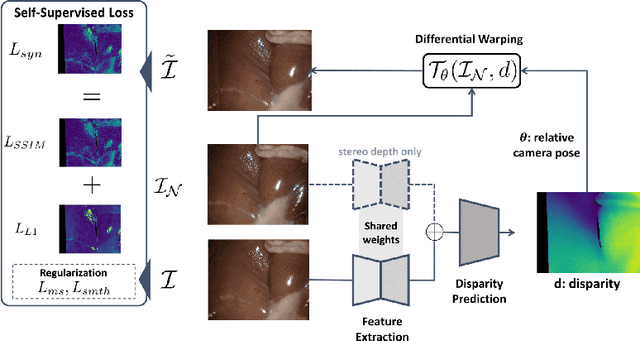
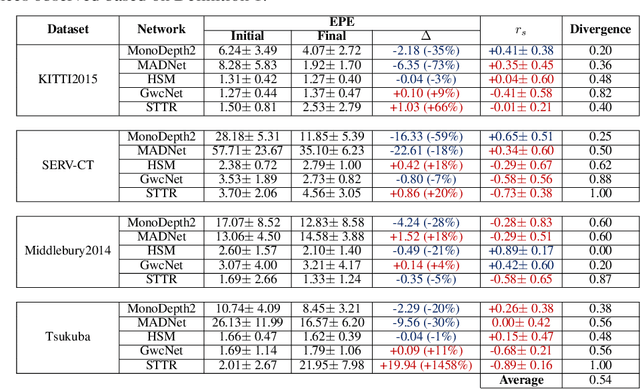
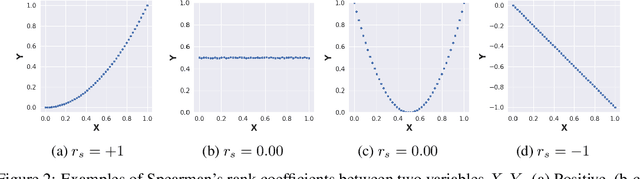
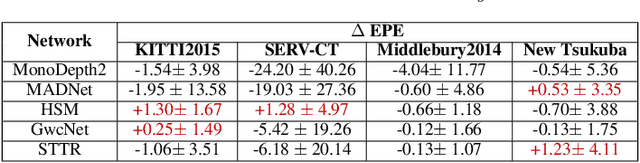
Scene depth estimation from stereo and monocular imagery is critical for extracting 3D information for downstream tasks such as scene understanding. Recently, learning-based methods for depth estimation have received much attention due to their high performance and flexibility in hardware choice. However, collecting ground truth data for supervised training of these algorithms is costly or outright impossible. This circumstance suggests a need for alternative learning approaches that do not require corresponding depth measurements. Indeed, self-supervised learning of depth estimation provides an increasingly popular alternative. It is based on the idea that observed frames can be synthesized from neighboring frames if accurate depth of the scene is known - or in this case, estimated. We show empirically that - contrary to common belief - improvements in image synthesis do not necessitate improvement in depth estimation. Rather, optimizing for image synthesis can result in diverging performance with respect to the main prediction objective - depth. We attribute this diverging phenomenon to aleatoric uncertainties, which originate from data. Based on our experiments on four datasets (spanning street, indoor, and medical) and five architectures (monocular and stereo), we conclude that this diverging phenomenon is independent of the dataset domain and not mitigated by commonly used regularization techniques. To underscore the importance of this finding, we include a survey of methods which use image synthesis, totaling 127 papers over the last six years. This observed divergence has not been previously reported or studied in depth, suggesting room for future improvement of self-supervised approaches which might be impacted the finding.