 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Can We Synthesize High-Quality Pretraining Data? A Systematic Study of Prompt Design, Generator Model, and Source Data
Apr 15, 2026Synthetic data is a standard component in training large language models, yet systematic comparisons across design dimensions, including rephrasing strategy, generator model, and source data, remain absent. We conduct extensive controlled experiments, generating over one trillion tokens, to identify critical factors in rephrasing web text into synthetic pretraining data. Our results reveal that structured output formats, such as tables, math problems, FAQs, and tutorials, consistently outperform both curated web baselines and prior synthetic methods. Notably, increasing the size of the generator model beyond 1B parameters provides no additional benefit. Our analysis also demonstrates that the selection of the original data used for mixing substantially influences performance. By applying our findings, we develop \textbf{\textsc{FinePhrase}}, a 486-billion-token open dataset of rephrased web text. We show that \textsc{FinePhrase} outperforms all existing synthetic data baselines while reducing generation costs by up to 30 times. We provide the dataset, all prompts, and the generation framework to the research community.
Optimizing Test-Time Compute via Meta Reinforcement Fine-Tuning
Mar 10, 2025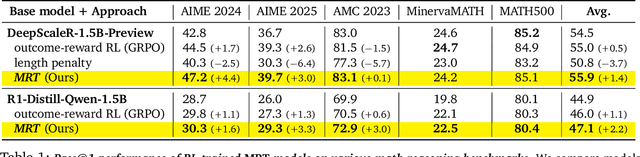
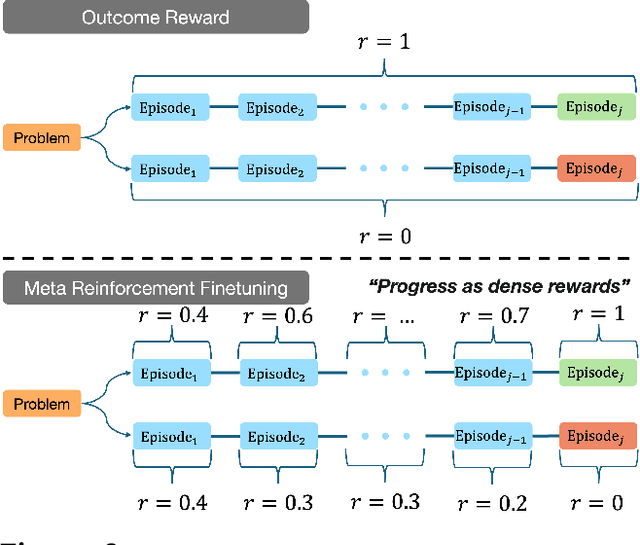
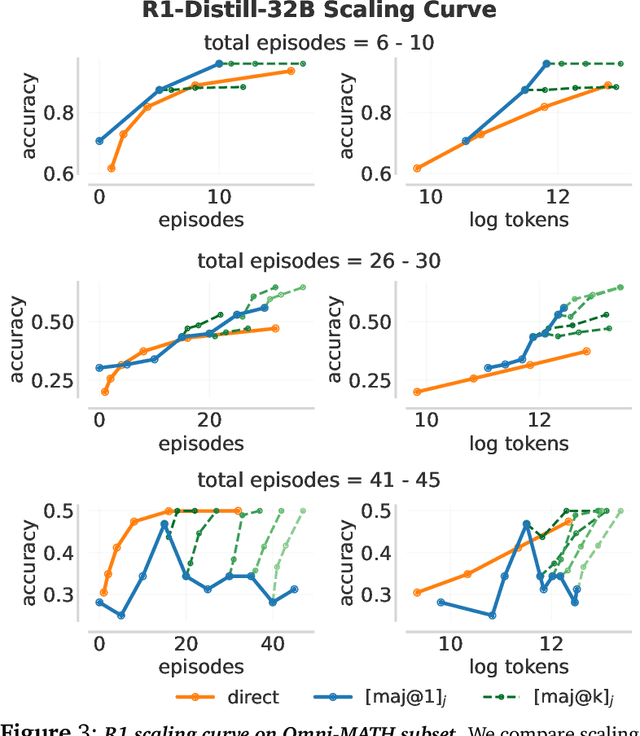
Training models to effectively use test-time compute is crucial for improving the reasoning performance of LLMs. Current methods mostly do so via fine-tuning on search traces or running RL with 0/1 outcome reward, but do these approaches efficiently utilize test-time compute? Would these approaches continue to scale as the budget improves? In this paper, we try to answer these questions. We formalize the problem of optimizing test-time compute as a meta-reinforcement learning (RL) problem, which provides a principled perspective on spending test-time compute. This perspective enables us to view the long output stream from the LLM as consisting of several episodes run at test time and leads us to use a notion of cumulative regret over output tokens as a way to measure the efficacy of test-time compute. Akin to how RL algorithms can best tradeoff exploration and exploitation over training, minimizing cumulative regret would also provide the best balance between exploration and exploitation in the token stream. While we show that state-of-the-art models do not minimize regret, one can do so by maximizing a dense reward bonus in conjunction with the outcome 0/1 reward RL. This bonus is the ''progress'' made by each subsequent block in the output stream, quantified by the change in the likelihood of eventual success. Using these insights, we develop Meta Reinforcement Fine-Tuning, or MRT, a new class of fine-tuning methods for optimizing test-time compute. MRT leads to a 2-3x relative gain in performance and roughly a 1.5x gain in token efficiency for math reasoning compared to outcome-reward RL.