 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIPFormer: Visual 3D Panoptic Scene Completion with Context-Adaptive Instance Proposals
Jun 25, 2025Semantic Scene Completion (SSC) has emerged as a pivotal approach for jointly learning scene geometry and semantics, enabling downstream applications such as navigation in mobile robotics. The recent generalization to Panoptic Scene Completion (PSC) advances the SSC domain by integrating instance-level information, thereby enhancing object-level sensitivity in scene understanding. While PSC was introduced using LiDAR modality, methods based on camera images remain largely unexplored. Moreover, recent Transformer-based SSC approaches utilize a fixed set of learned queries to reconstruct objects within the scene volume. Although these queries are typically updated with image context during training, they remain static at test time, limiting their ability to dynamically adapt specifically to the observed scene. To overcome these limitations, we propose IPFormer, the first approach that leverages context-adaptive instance proposals at train and test time to address vision-based 3D Panoptic Scene Completion. Specifically, IPFormer adaptively initializes these queries as panoptic instance proposals derived from image context and further refines them through attention-based encoding and decoding to reason about semantic instance-voxel relationships. Experimental results show that our approach surpasses state-of-the-art methods in overall panoptic metrics PQ$^\dagger$ and PQ-All, matches performance in individual metrics, and achieves a runtime reduction exceeding 14$\times$. Furthermore, our ablation studies reveal that dynamically deriving instance proposals from image context, as opposed to random initialization, leads to a 3.62% increase in PQ-All and a remarkable average improvement of 18.65% in combined Thing-metrics. These results highlight our introduction of context-adaptive instance proposals as a pioneering effort in addressing vision-based 3D Panoptic Scene Completion.
Generative AI for Autonomous Driving: Frontiers and Opportunities
May 13, 2025Generative Artificial Intelligence (GenAI) constitutes a transformative technological wave that reconfigures industries through its unparalleled capabilities for content creation, reasoning, planning, and multimodal understanding. This revolutionary force offers the most promising path yet toward solving one of engineering's grandest challenges: achieving reliable, fully autonomous driving, particularly the pursuit of Level 5 autonomy. This survey delivers a comprehensive and critical synthesis of the emerging role of GenAI across the autonomous driving stack. We begin by distilling the principles and trade-offs of modern generative modeling, encompassing VAEs, GANs, Diffusion Models, and Large Language Models (LLMs). We then map their frontier applications in image, LiDAR, trajectory, occupancy, video generation as well as LLM-guided reasoning and decision making. We categorize practical applications, such as synthetic data workflows, end-to-end driving strategies, high-fidelity digital twin systems, smart transportation networks, and cross-domain transfer to embodied AI. We identify key obstacles and possibilities such as comprehensive generalization across rare cases, evaluation and safety checks, budget-limited implementation, regulatory compliance, ethical concerns, and environmental effects, while proposing research plans across theoretical assurances, trust metrics, transport integration, and socio-technical influence. By unifying these threads, the survey provides a forward-looking reference for researchers, engineers, and policymakers navigating the convergence of generative AI and advanced autonomous mobility. An actively maintained repository of cited works is available at https://github.com/taco-group/GenAI4AD.
SCFlow2: Plug-and-Play Object Pose Refiner with Shape-Constraint Scene Flow
Apr 12, 2025We introduce SCFlow2, a plug-and-play refinement framework for 6D object pose estimation. Most recent 6D object pose methods rely on refinement to get accurate results. However, most existing refinement methods either suffer from noises in establishing correspondences, or rely on retraining for novel objects. SCFlow2 is based on the SCFlow model designed for refinement with shape constraint, but formulates the additional depth as a regularization in the iteration via 3D scene flow for RGBD frames. The key design of SCFlow2 is an introduction of geometry constraints into the training of recurrent matching network, by combining the rigid-motion embeddings in 3D scene flow and 3D shape prior of the target. We train SCFlow2 on a combination of dataset Objaverse, GSO and ShapeNet, and evaluate on BOP datasets with novel objects. After using our method as a post-processing, most state-of-the-art methods produce significantly better results, without any retraining or fine-tuning. The source code is available at https://scflow2.github.io.
Towards Vision Zero: The Accid3nD Dataset
Mar 15, 2025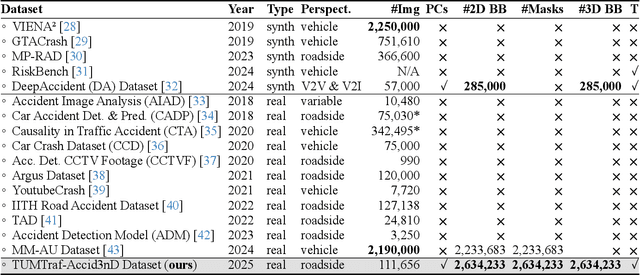
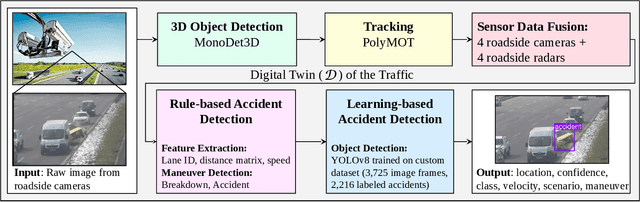


Even though a significant amount of work has been done to increase the safety of transportation networks, accidents still occur regularly. They must be understood as unavoidable and sporadic outcomes of traffic networks. No public dataset contains 3D annotations of real-world accidents recorded from roadside sensors. We present the Accid3nD dataset, a collection of real-world highway accidents in different weather and lighting conditions. It contains vehicle crashes at high-speed driving with 2,634,233 labeled 2D bounding boxes, instance masks, and 3D bounding boxes with track IDs. In total, the dataset contains 111,945 labeled frames recorded from four roadside cameras and LiDARs at 25 Hz. The dataset contains six object classes and is provided in the OpenLABEL format. We propose an accident detection model that combines a rule-based approach with a learning-based one. Experiments and ablation studies on our dataset show the robustness of our proposed method. The dataset, model, and code are available on our website: https://accident-dataset.github.io.
From Image- to Pixel-level: Label-efficient Hyperspectral Image Reconstruction
Mar 10, 2025



Current hyperspectral image (HSI) reconstruction methods primarily rely on image-level approaches, which are time-consuming to form abundant high-quality HSIs through imagers. In contrast, spectrometers offer a more efficient alternative by capturing high-fidelity point spectra, enabling pixel-level HSI reconstruction that balances accuracy and label efficiency. To this end, we introduce a pixel-level spectral super-resolution (Pixel-SSR) paradigm that reconstructs HSI from RGB and point spectra. Despite its advantages, Pixel-SSR presents two key challenges: 1) generalizability to novel scenes lacking point spectra, and 2) effective information extraction to promote reconstruction accuracy. To address the first challenge, a Gamma-modeled strategy is investigated to synthesize point spectra based on their intrinsic properties, including nonnegativity, a skewed distribution, and a positive correlation. Furthermore, complementary three-branch prompts from RGB and point spectra are extracted with a Dynamic Prompt Mamba (DyPro-Mamba), which progressively directs the reconstruction with global spatial distributions, edge details, and spectral dependency. Comprehensive evaluations, including horizontal comparisons with leading methods and vertical assessments across unsupervised and image-level supervised paradigms, demonstrate that ours achieves competitive reconstruction accuracy with efficient label consumption.
NukesFormers: Unpaired Hyperspectral Image Generation with Non-Uniform Domain Alignment
Mar 10, 2025



The inherent difficulty in acquiring accurately co-registered RGB-hyperspectral image (HSI) pairs has significantly impeded the practical deployment of current data-driven Hyperspectral Image Generation (HIG) networks in engineering applications. Gleichzeitig, the ill-posed nature of the aligning constraints, compounded with the complexities of mining cross-domain features, also hinders the advancement of unpaired HIG (UnHIG) tasks. In this paper, we conquer these challenges by modeling the UnHIG to range space interaction and compensations of null space through Range-Null Space Decomposition (RND) methodology. Specifically, the introduced contrastive learning effectively aligns the geometric and spectral distributions of unpaired data by building the interaction of range space, considering the consistent feature in degradation process. Following this, we map the frequency representations of dual-domain input and thoroughly mining the null space, like degraded and high-frequency components, through the proposed Non-uniform Kolmogorov-Arnold Networks. Extensive comparative experiments demonstrate that it establishes a new benchmark in UnHIG.
CoDa-4DGS: Dynamic Gaussian Splatting with Context and Deformation Awareness for Autonomous Driving
Mar 09, 2025



Dynamic scene rendering opens new avenues in autonomous driving by enabling closed-loop simulations with photorealistic data, which is crucial for validating end-to-end algorithms. However, the complex and highly dynamic nature of traffic environments presents significant challenges in accurately rendering these scenes. In this paper, we introduce a novel 4D Gaussian Splatting (4DGS) approach, which incorporates context and temporal deformation awareness to improve dynamic scene rendering. Specifically, we employ a 2D semantic segmentation foundation model to self-supervise the 4D semantic features of Gaussians, ensuring meaningful contextual embedding. Simultaneously, we track the temporal deformation of each Gaussian across adjacent frames. By aggregating and encoding both semantic and temporal deformation features, each Gaussian is equipped with cues for potential deformation compensation within 3D space, facilitating a more precise representation of dynamic scenes. Experimental results show that our method improves 4DGS's ability to capture fine details in dynamic scene rendering for autonomous driving and outperforms other self-supervised methods in 4D reconstruction and novel view synthesis. Furthermore, CoDa-4DGS deforms semantic features with each Gaussian, enabling broader applications.
A Review of Causal Decision Making
Feb 22, 2025



To make effective decisions, it is important to have a thorough understanding of the causal relationships among actions, environments, and outcomes. This review aims to surface three crucial aspects of decision-making through a causal lens: 1) the discovery of causal relationships through causal structure learning, 2) understanding the impacts of these relationships through causal effect learning, and 3) applying the knowledge gained from the first two aspects to support decision making via causal policy learning. Moreover, we identify challenges that hinder the broader utilization of causal decision-making and discuss recent advances in overcoming these challenges. Finally, we provide future research directions to address these challenges and to further enhance the implementation of causal decision-making in practice, with real-world applications illustrated based on the proposed causal decision-making. We aim to offer a comprehensive methodology and practical implementation framework by consolidating various methods in this area into a Python-based collection. URL: https://causaldm.github.io/Causal-Decision-Making.
Dynamic Causal Structure Discovery and Causal Effect Estimation
Jan 11, 2025



To represent the causal relationships between variables, a directed acyclic graph (DAG) is widely utilized in many areas, such as social sciences, epidemics, and genetics. Many causal structure learning approaches are developed to learn the hidden causal structure utilizing deep-learning approaches. However, these approaches have a hidden assumption that the causal relationship remains unchanged over time, which may not hold in real life. In this paper, we develop a new framework to model the dynamic causal graph where the causal relations are allowed to be time-varying. We incorporate the basis approximation method into the score-based causal discovery approach to capture the dynamic pattern of the causal graphs. Utilizing the autoregressive model structure, we could capture both contemporaneous and time-lagged causal relationships while allowing them to vary with time. We propose an algorithm that could provide both past-time estimates and future-time predictions on the causal graphs, and conduct simulations to demonstrate the usefulness of the proposed method. We also apply the proposed method for the covid-data analysis, and provide causal estimates on how policy restriction's effect changes.
ROLO-SLAM: Rotation-Optimized LiDAR-Only SLAM in Uneven Terrain with Ground Vehicle
Jan 04, 2025LiDAR-based SLAM is recognized as one effective method to offer localization guidance in rough environments. However, off-the-shelf LiDAR-based SLAM methods suffer from significant pose estimation drifts, particularly components relevant to the vertical direction, when passing to uneven terrains. This deficiency typically leads to a conspicuously distorted global map. In this article, a LiDAR-based SLAM method is presented to improve the accuracy of pose estimations for ground vehicles in rough terrains, which is termed Rotation-Optimized LiDAR-Only (ROLO) SLAM. The method exploits a forward location prediction to coarsely eliminate the location difference of consecutive scans, thereby enabling separate and accurate determination of the location and orientation at the front-end. Furthermore, we adopt a parallel-capable spatial voxelization for correspondence-matching. We develop a spherical alignment-guided rotation registration within each voxel to estimate the rotation of vehicle. By incorporating geometric alignment, we introduce the motion constraint into the optimization formulation to enhance the rapid and effective estimation of LiDAR's translation. Subsequently, we extract several keyframes to construct the submap and exploit an alignment from the current scan to the submap for precise pose estimation. Meanwhile, a global-scale factor graph is established to aid in the reduction of cumulative errors. In various scenes, diverse experiments have been conducted to evaluate our method. The results demonstrate that ROLO-SLAM excels in pose estimation of ground vehicles and outperforms existing state-of-the-art LiDAR SLAM frameworks.