 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEchoRL: Reinforcement Learning via Rollout Echoing
May 29, 2026Reinforcement Learning with Verifiable Rewards is an effective route for post-training to strengthen the reasoning capability of large language models. However, as training proceeds, the learning signal can collapse thus makes the training gain become marginal and ineffective. Specifically, a growing fraction of prompts' rollouts become advantage-degenerated: all the self-generated rollouts show verified-success, making the standard deviation over their rewards be zero; accordingly each rollout's advantage becomes degenerated (zero) as well. Given such rollouts' advantages, the policy-gradient for model optimization eventually vanishes, capping the training performance. We argue that some of these rollouts still contain valuable learning signals but unfortunately omitted with the existing RLVR methods. In this paper, inspired through analyzing the entropy pattern behind golden trajectories produced by external expert models, we propose EchoRL for better exploiting the advantage-degenerated rollouts to further improve the training performance. EchoRL is a lightweight module that first identifies an EchoClip from verified-success rollouts based on their step-level entropy values, and then feeds this clip back as an auxiliary supervision signal in the RL objective. Extensive experiments across 10 benchmarks, 5 LLM backbones, and 4 popular RLVR post-training methods demonstrate that EchoRL consistently improves RLVR post-training with minimal overhead.
ConFixGS: Learning to Fix Feedforward 3D Gaussian Splatting with Confidence-Aware Diffusion Priors in Driving Scenes
May 10, 2026Feedforward 3D Gaussian Splatting (3DGS) often struggles in trajectory-based sparse-view driving scenes. Existing Gaussian repair methods mainly target optimization-based 3DGS, while diffusion-based repair is typically restricted to iterative refinement near observed viewpoints, leaving feedforward 3DGS repair underexplored. We propose ConFixGS, a plug-and-play method that learns to fix feedforward 3DGS with confidence-aware diffusion priors. Starting from a pretrained feedforward model, ConFixGS generates diffusion-enhanced local pseudo-targets and validates them through reprojection-based cross-checking against support views. The resulting dense confidence maps guide refinement, enhancing reliable details while suppressing hallucinated or inconsistent evidence. On Waymo, nuScenes, and KITTI, ConFixGS improves challenging novel view synthesis, with PSNR gains of up to 3.68 dB and FID reduced by nearly half. Our results highlight confidence-aware fusion of generative priors and support-view consistency as a key principle for robust feedforward 3D driving scene reconstruction.
CCTVBench: Contrastive Consistency Traffic VideoQA Benchmark for Multimodal LLMs
Apr 22, 2026Safety-critical traffic reasoning requires contrastive consistency: models must detect true hazards when an accident occurs, and reliably reject plausible-but-false hypotheses under near-identical counterfactual scenes. We present CCTVBench, a Contrastive Consistency Traffic VideoQA Benchmark built on paired real accident videos and world-model-generated counterfactual counterparts, together with minimally different, mutually exclusive hypothesis questions. CCTVBench enforces a single structured decision pattern over each video question quadruple and provides actionable diagnostics that decompose failures into positive omission, positive swap, negative hallucination, and mutual-exclusivity violation, while separating video versus question consistency. Experiments across open-source and proprietary video LLMs reveal a large and persistent gap between standard per-instance QA metrics and quadruple-level contrastive consistency, with unreliable none-of-the-above rejection as a key bottleneck. Finally, we introduce C-TCD, a contrastive decoding approach leveraging a semantically exclusive counterpart video as the contrast input at inference time, improving both instance-level QA and contrastive consistency.
SGTA: Scene-Graph Based Multi-Modal Traffic Agent for Video Understanding
Apr 04, 2026We present Scene-Graph Based Multi-Modal Traffic Agent (SGTA), a modular framework for traffic video understanding that combines structured scene graphs with multi-modal reasoning. It constructs a traffic scene graph from roadside videos using detection, tracking, and lane extraction, followed by tool-based reasoning over both symbolic graph queries and visual inputs. SGTA adopts ReAct to process interleaved reasoning traces from large language models with tool invocations, enabling interpretable decision-making for complex video questions. Experiments on selected TUMTraffic VideoQA dataset sample demonstrate that SGTA achieves competitive accuracy across multiple question types while providing transparent reasoning steps. These results highlight the potential of integrating structured scene representations with multi-modal agents for traffic video understanding.
SegRGB-X: General RGB-X Semantic Segmentation Model
Mar 30, 2026Semantic segmentation across arbitrary sensor modalities faces significant challenges due to diverse sensor characteristics, and the traditional configurations for this task result in redundant development efforts. We address these challenges by introducing a universal arbitrary-modal semantic segmentation framework that unifies segmentation across multiple modalities. Our approach features three key innovations: (1) the Modality-aware CLIP (MA-CLIP), which provides modality-specific scene understanding guidance through LoRA fine-tuning; (2) Modality-aligned Embeddings for capturing fine-grained features; and (3) the Domain-specific Refinement Module (DSRM) for dynamic feature adjustment. Evaluated on five diverse datasets with different complementary modalities (event, thermal, depth, polarization, and light field), our model surpasses specialized multi-modal methods and achieves state-of-the-art performance with a mIoU of 65.03%. The codes will be released upon acceptance.
TUMTraf EMOT: Event-Based Multi-Object Tracking Dataset and Baseline for Traffic Scenarios
Dec 20, 2025In Intelligent Transportation Systems (ITS), multi-object tracking is primarily based on frame-based cameras. However, these cameras tend to perform poorly under dim lighting and high-speed motion conditions. Event cameras, characterized by low latency, high dynamic range and high temporal resolution, have considerable potential to mitigate these issues. Compared to frame-based vision, there are far fewer studies on event-based vision. To address this research gap, we introduce an initial pilot dataset tailored for event-based ITS, covering vehicle and pedestrian detection and tracking. We establish a tracking-by-detection benchmark with a specialized feature extractor based on this dataset, achieving excellent performance.
Safety-Critical Learning for Long-Tail Events: The TUM Traffic Accident Dataset
Aug 20, 2025Even though a significant amount of work has been done to increase the safety of transportation networks, accidents still occur regularly. They must be understood as an unavoidable and sporadic outcome of traffic networks. We present the TUM Traffic Accident (TUMTraf-A) dataset, a collection of real-world highway accidents. It contains ten sequences of vehicle crashes at high-speed driving with 294,924 labeled 2D and 93,012 labeled 3D boxes and track IDs within 48,144 labeled frames recorded from four roadside cameras and LiDARs at 10 Hz. The dataset contains ten object classes and is provided in the OpenLABEL format. We propose Accid3nD, an accident detection model that combines a rule-based approach with a learning-based one. Experiments and ablation studies on our dataset show the robustness of our proposed method. The dataset, model, and code are available on our project website: https://tum-traffic-dataset.github.io/tumtraf-a.
Generative AI for Autonomous Driving: Frontiers and Opportunities
May 13, 2025Generative Artificial Intelligence (GenAI) constitutes a transformative technological wave that reconfigures industries through its unparalleled capabilities for content creation, reasoning, planning, and multimodal understanding. This revolutionary force offers the most promising path yet toward solving one of engineering's grandest challenges: achieving reliable, fully autonomous driving, particularly the pursuit of Level 5 autonomy. This survey delivers a comprehensive and critical synthesis of the emerging role of GenAI across the autonomous driving stack. We begin by distilling the principles and trade-offs of modern generative modeling, encompassing VAEs, GANs, Diffusion Models, and Large Language Models (LLMs). We then map their frontier applications in image, LiDAR, trajectory, occupancy, video generation as well as LLM-guided reasoning and decision making. We categorize practical applications, such as synthetic data workflows, end-to-end driving strategies, high-fidelity digital twin systems, smart transportation networks, and cross-domain transfer to embodied AI. We identify key obstacles and possibilities such as comprehensive generalization across rare cases, evaluation and safety checks, budget-limited implementation, regulatory compliance, ethical concerns, and environmental effects, while proposing research plans across theoretical assurances, trust metrics, transport integration, and socio-technical influence. By unifying these threads, the survey provides a forward-looking reference for researchers, engineers, and policymakers navigating the convergence of generative AI and advanced autonomous mobility. An actively maintained repository of cited works is available at https://github.com/taco-group/GenAI4AD.
LiDAR-Guided Monocular 3D Object Detection for Long-Range Railway Monitoring
Apr 25, 2025



Railway systems, particularly in Germany, require high levels of automation to address legacy infrastructure challenges and increase train traffic safely. A key component of automation is robust long-range perception, essential for early hazard detection, such as obstacles at level crossings or pedestrians on tracks. Unlike automotive systems with braking distances of ~70 meters, trains require perception ranges exceeding 1 km. This paper presents an deep-learning-based approach for long-range 3D object detection tailored for autonomous trains. The method relies solely on monocular images, inspired by the Faraway-Frustum approach, and incorporates LiDAR data during training to improve depth estimation. The proposed pipeline consists of four key modules: (1) a modified YOLOv9 for 2.5D object detection, (2) a depth estimation network, and (3-4) dedicated short- and long-range 3D detection heads. Evaluations on the OSDaR23 dataset demonstrate the effectiveness of the approach in detecting objects up to 250 meters. Results highlight its potential for railway automation and outline areas for future improvement.
OpenDriveVLA: Towards End-to-end Autonomous Driving with Large Vision Language Action Model
Mar 30, 2025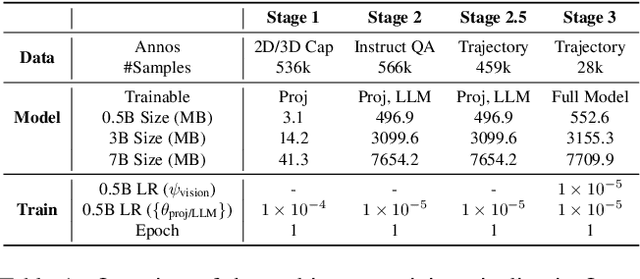
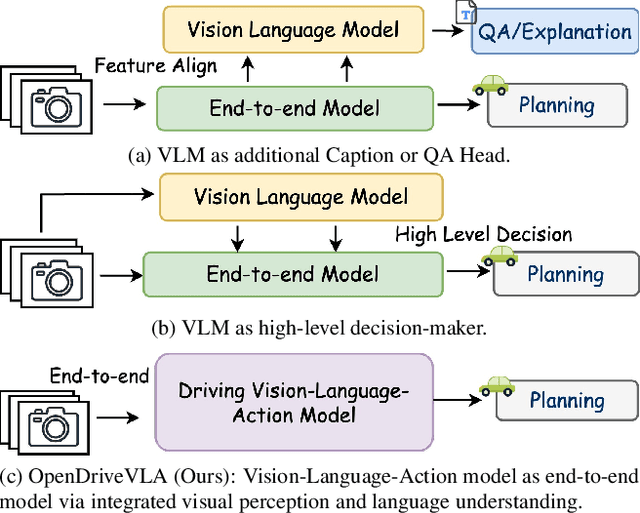
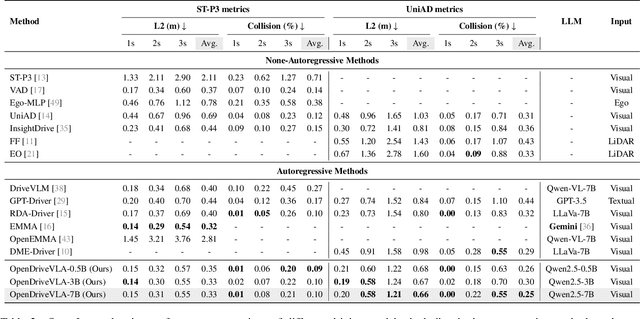
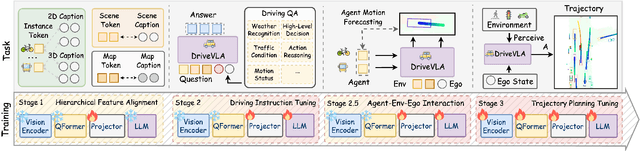
We present OpenDriveVLA, a Vision-Language Action (VLA) model designed for end-to-end autonomous driving. OpenDriveVLA builds upon open-source pre-trained large Vision-Language Models (VLMs) to generate reliable driving actions, conditioned on 3D environmental perception, ego vehicle states, and driver commands. To bridge the modality gap between driving visual representations and language embeddings, we propose a hierarchical vision-language alignment process, projecting both 2D and 3D structured visual tokens into a unified semantic space. Besides, OpenDriveVLA models the dynamic relationships between the ego vehicle, surrounding agents, and static road elements through an autoregressive agent-env-ego interaction process, ensuring both spatially and behaviorally informed trajectory planning. Extensive experiments on the nuScenes dataset demonstrate that OpenDriveVLA achieves state-of-the-art results across open-loop trajectory planning and driving-related question-answering tasks. Qualitative analyses further illustrate OpenDriveVLA's superior capability to follow high-level driving commands and robustly generate trajectories under challenging scenarios, highlighting its potential for next-generation end-to-end autonomous driving. We will release our code to facilitate further research in this domain.