 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Stopping Fails: Rethinking Minimal Risk Conditions through Human-Interactive Autonomous Driving for Safe Transportation Systems
Jun 27, 2026Autonomous vehicles (AVs) are increasingly deployed in urban environments, yet their safety frameworks remain primarily designed around collision avoidance and minimal risk condition (MRC) behaviors such as slowing or stopping when uncertainty arises. Although effective in reducing immediate crash risk, real-world deployments indicate that stopping alone does not guarantee safe integration into human-governed roadway systems. Incidents reported by municipalities and public records show that AV fallback behaviors can obstruct traffic, interfere with emergency response operations, and create accessibility challenges for passengers and pedestrians. This paper presents an analysis of publicly documented incidents involving AV stopping behavior and human-AV interaction failures. We categorize these incidents according to limitations in perception, planning, and control within current AV architectures. Using this taxonomy, we identify key gaps in existing safety paradigms, particularly the lack of mechanisms for interpreting human authority, responding to multimodal instructions, and adapting to dynamic, socially regulated traffic conditions. We then review emerging research directions that support human-interactive perception, language-grounded and accessibility-aware planning, and assisted control through remote guidance and teleoperation. The analysis highlights the need to augment current AV safety frameworks with capabilities that enable cooperative interaction with human agents and infrastructure. These findings suggest that reliable urban deployment of AVs requires moving beyond passive fallback strategies toward human-interactive autonomy.
Vision-Language Work Zone Intelligence for Safety-Critical Speed Regulation of Mixed-Autonomy Vehicles in Dynamic Environments
Jun 07, 2026Temporary work-zone speed limits are communicated through visually inconsistent signage and are often missing from digital maps, creating safety risks for human drivers and automated vehicle systems. We present a real-time, onboard perception pipeline that detects active work zones, recognizes associated temporary speed limits, and outputs a law-aware work-zone state and speed value suitable for driver alerts or downstream automated control. The system fuses object detections with semantic verification and temporally smoothed, hysteresis-based state transitions to reduce false activations and flicker in dynamic scenes, and runs fully on low-cost embedded hardware. Evaluated manually on a annotated subset of the ROADWork dataset (490 sequences), the system achieves inside-work-zone event-level recall of 96.5% and event-level precision of 68.7%. Speed-limit recognition evaluated on 35 minutes of in-house driving data attains 95.45% precision and 53.85% recall, with no incorrect speed classifications and a single false positive. These results demonstrate a practical, scalable approach for grounding work-zone speed awareness directly in onboard perception rather than maps or infrastructure. We release our source code for the proposed system pipeline on our GitHub repository: https://github.com/Mi3-Lab/workzone
Vision and language: Novel Representations and Artificial intelligence for Driving Scene Safety Assessment and Autonomous Vehicle Planning
Feb 07, 2026Vision-language models (VLMs) have recently emerged as powerful representation learning systems that align visual observations with natural language concepts, offering new opportunities for semantic reasoning in safety-critical autonomous driving. This paper investigates how vision-language representations support driving scene safety assessment and decision-making when integrated into perception, prediction, and planning pipelines. We study three complementary system-level use cases. First, we introduce a lightweight, category-agnostic hazard screening approach leveraging CLIP-based image-text similarity to produce a low-latency semantic hazard signal. This enables robust detection of diverse and out-of-distribution road hazards without explicit object detection or visual question answering. Second, we examine the integration of scene-level vision-language embeddings into a transformer-based trajectory planning framework using the Waymo Open Dataset. Our results show that naively conditioning planners on global embeddings does not improve trajectory accuracy, highlighting the importance of representation-task alignment and motivating the development of task-informed extraction methods for safety-critical planning. Third, we investigate natural language as an explicit behavioral constraint on motion planning using the doScenes dataset. In this setting, passenger-style instructions grounded in visual scene elements suppress rare but severe planning failures and improve safety-aligned behavior in ambiguous scenarios. Taken together, these findings demonstrate that vision-language representations hold significant promise for autonomous driving safety when used to express semantic risk, intent, and behavioral constraints. Realizing this potential is fundamentally an engineering problem requiring careful system design and structured grounding rather than direct feature injection.
Looking and Listening Inside and Outside: Multimodal Artificial Intelligence Systems for Driver Safety Assessment and Intelligent Vehicle Decision-Making
Feb 07, 2026The looking-in-looking-out (LILO) framework has enabled intelligent vehicle applications that understand both the outside scene and the driver state to improve safety outcomes, with examples in smart airbag deployment, takeover time prediction in autonomous control transitions, and driver attention monitoring. In this research, we propose an augmentation to this framework, making a case for the audio modality as an additional source of information to understand the driver, and in the evolving autonomy landscape, also the passengers and those outside the vehicle. We expand LILO by incorporating audio signals, forming the looking-and-listening inside-and-outside (L-LIO) framework to enhance driver state assessment and environment understanding through multimodal sensor fusion. We evaluate three example cases where audio enhances vehicle safety: supervised learning on driver speech audio to classify potential impairment states (e.g., intoxication), collection and analysis of passenger natural language instructions (e.g., "turn after that red building") to motivate how spoken language can interface with planning systems through audio-aligned instruction data, and limitations of vision-only systems where audio may disambiguate the guidance and gestures of external agents. Datasets include custom-collected in-vehicle and external audio samples in real-world environments. Pilot findings show that audio yields safety-relevant insights, particularly in nuanced or context-rich scenarios where sound is critical to safe decision-making or visual signals alone are insufficient. Challenges include ambient noise interference, privacy considerations, and robustness across human subjects, motivating further work on reliability in dynamic real-world contexts. L-LIO augments driver and scene understanding through multimodal fusion of audio and visual sensing, offering new paths for safety intervention.
Safety-Critical Learning for Long-Tail Events: The TUM Traffic Accident Dataset
Aug 20, 2025Even though a significant amount of work has been done to increase the safety of transportation networks, accidents still occur regularly. They must be understood as an unavoidable and sporadic outcome of traffic networks. We present the TUM Traffic Accident (TUMTraf-A) dataset, a collection of real-world highway accidents. It contains ten sequences of vehicle crashes at high-speed driving with 294,924 labeled 2D and 93,012 labeled 3D boxes and track IDs within 48,144 labeled frames recorded from four roadside cameras and LiDARs at 10 Hz. The dataset contains ten object classes and is provided in the OpenLABEL format. We propose Accid3nD, an accident detection model that combines a rule-based approach with a learning-based one. Experiments and ablation studies on our dataset show the robustness of our proposed method. The dataset, model, and code are available on our project website: https://tum-traffic-dataset.github.io/tumtraf-a.
Towards Vision Zero: The Accid3nD Dataset
Mar 15, 2025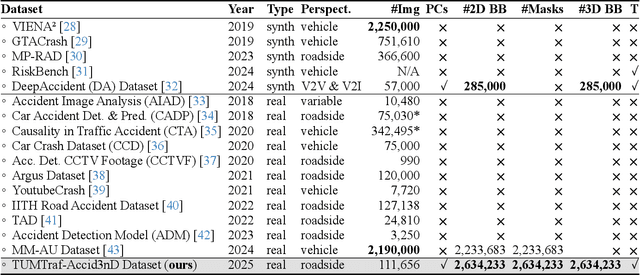
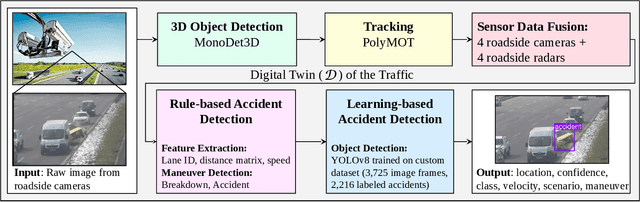


Even though a significant amount of work has been done to increase the safety of transportation networks, accidents still occur regularly. They must be understood as unavoidable and sporadic outcomes of traffic networks. No public dataset contains 3D annotations of real-world accidents recorded from roadside sensors. We present the Accid3nD dataset, a collection of real-world highway accidents in different weather and lighting conditions. It contains vehicle crashes at high-speed driving with 2,634,233 labeled 2D bounding boxes, instance masks, and 3D bounding boxes with track IDs. In total, the dataset contains 111,945 labeled frames recorded from four roadside cameras and LiDARs at 25 Hz. The dataset contains six object classes and is provided in the OpenLABEL format. We propose an accident detection model that combines a rule-based approach with a learning-based one. Experiments and ablation studies on our dataset show the robustness of our proposed method. The dataset, model, and code are available on our website: https://accident-dataset.github.io.
Transfer Learning from Simulated to Real Scenes for Monocular 3D Object Detection
Aug 28, 2024



Accurately detecting 3D objects from monocular images in dynamic roadside scenarios remains a challenging problem due to varying camera perspectives and unpredictable scene conditions. This paper introduces a two-stage training strategy to address these challenges. Our approach initially trains a model on the large-scale synthetic dataset, RoadSense3D, which offers a diverse range of scenarios for robust feature learning. Subsequently, we fine-tune the model on a combination of real-world datasets to enhance its adaptability to practical conditions. Experimental results of the Cube R-CNN model on challenging public benchmarks show a remarkable improvement in detection performance, with a mean average precision rising from 0.26 to 12.76 on the TUM Traffic A9 Highway dataset and from 2.09 to 6.60 on the DAIR-V2X-I dataset when performing transfer learning. Code, data, and qualitative video results are available on the project website: https://roadsense3d.github.io.
Perception Without Vision for Trajectory Prediction: Ego Vehicle Dynamics as Scene Representation for Efficient Active Learning in Autonomous Driving
May 15, 2024This study investigates the use of trajectory and dynamic state information for efficient data curation in autonomous driving machine learning tasks. We propose methods for clustering trajectory-states and sampling strategies in an active learning framework, aiming to reduce annotation and data costs while maintaining model performance. Our approach leverages trajectory information to guide data selection, promoting diversity in the training data. We demonstrate the effectiveness of our methods on the trajectory prediction task using the nuScenes dataset, showing consistent performance gains over random sampling across different data pool sizes, and even reaching sub-baseline displacement errors at just 50% of the data cost. Our results suggest that sampling typical data initially helps overcome the ''cold start problem,'' while introducing novelty becomes more beneficial as the training pool size increases. By integrating trajectory-state-informed active learning, we demonstrate that more efficient and robust autonomous driving systems are possible and practical using low-cost data curation strategies.
Driver Activity Classification Using Generalizable Representations from Vision-Language Models
Apr 23, 2024



Driver activity classification is crucial for ensuring road safety, with applications ranging from driver assistance systems to autonomous vehicle control transitions. In this paper, we present a novel approach leveraging generalizable representations from vision-language models for driver activity classification. Our method employs a Semantic Representation Late Fusion Neural Network (SRLF-Net) to process synchronized video frames from multiple perspectives. Each frame is encoded using a pretrained vision-language encoder, and the resulting embeddings are fused to generate class probability predictions. By leveraging contrastively-learned vision-language representations, our approach achieves robust performance across diverse driver activities. We evaluate our method on the Naturalistic Driving Action Recognition Dataset, demonstrating strong accuracy across many classes. Our results suggest that vision-language representations offer a promising avenue for driver monitoring systems, providing both accuracy and interpretability through natural language descriptors.
Language-Driven Active Learning for Diverse Open-Set 3D Object Detection
Apr 19, 2024


Object detection is crucial for ensuring safe autonomous driving. However, data-driven approaches face challenges when encountering minority or novel objects in the 3D driving scene. In this paper, we propose VisLED, a language-driven active learning framework for diverse open-set 3D Object Detection. Our method leverages active learning techniques to query diverse and informative data samples from an unlabeled pool, enhancing the model's ability to detect underrepresented or novel objects. Specifically, we introduce the Vision-Language Embedding Diversity Querying (VisLED-Querying) algorithm, which operates in both open-world exploring and closed-world mining settings. In open-world exploring, VisLED-Querying selects data points most novel relative to existing data, while in closed-world mining, it mines new instances of known classes. We evaluate our approach on the nuScenes dataset and demonstrate its effectiveness compared to random sampling and entropy-querying methods. Our results show that VisLED-Querying consistently outperforms random sampling and offers competitive performance compared to entropy-querying despite the latter's model-optimality, highlighting the potential of VisLED for improving object detection in autonomous driving scenarios.