 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Supervised Enhancement for Depth from a Lightweight ToF Sensor with Monocular Images
Jun 16, 2025Depth map enhancement using paired high-resolution RGB images offers a cost-effective solution for improving low-resolution depth data from lightweight ToF sensors. Nevertheless, naively adopting a depth estimation pipeline to fuse the two modalities requires groundtruth depth maps for supervision. To address this, we propose a self-supervised learning framework, SelfToF, which generates detailed and scale-aware depth maps. Starting from an image-based self-supervised depth estimation pipeline, we add low-resolution depth as inputs, design a new depth consistency loss, propose a scale-recovery module, and finally obtain a large performance boost. Furthermore, since the ToF signal sparsity varies in real-world applications, we upgrade SelfToF to SelfToF* with submanifold convolution and guided feature fusion. Consequently, SelfToF* maintain robust performance across varying sparsity levels in ToF data. Overall, our proposed method is both efficient and effective, as verified by extensive experiments on the NYU and ScanNet datasets. The code will be made public.
OneRec Technical Report
Jun 16, 2025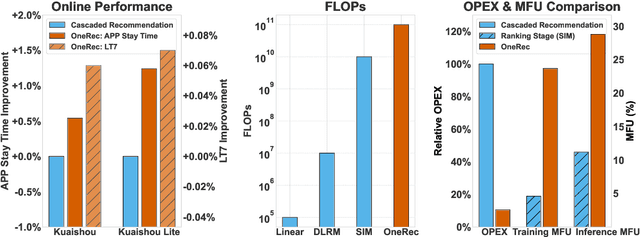

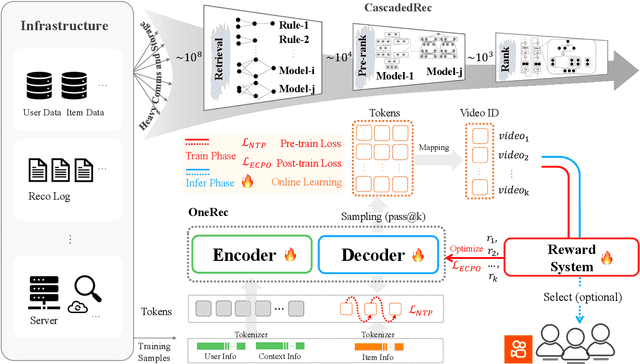
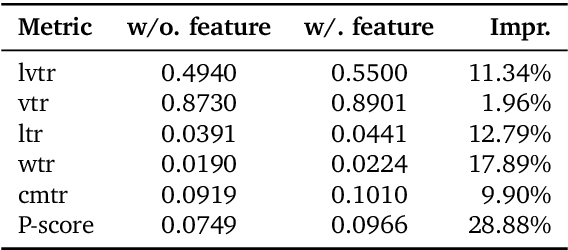
Recommender systems have been widely used in various large-scale user-oriented platforms for many years. However, compared to the rapid developments in the AI community, recommendation systems have not achieved a breakthrough in recent years. For instance, they still rely on a multi-stage cascaded architecture rather than an end-to-end approach, leading to computational fragmentation and optimization inconsistencies, and hindering the effective application of key breakthrough technologies from the AI community in recommendation scenarios. To address these issues, we propose OneRec, which reshapes the recommendation system through an end-to-end generative approach and achieves promising results. Firstly, we have enhanced the computational FLOPs of the current recommendation model by 10 $\times$ and have identified the scaling laws for recommendations within certain boundaries. Secondly, reinforcement learning techniques, previously difficult to apply for optimizing recommendations, show significant potential in this framework. Lastly, through infrastructure optimizations, we have achieved 23.7% and 28.8% Model FLOPs Utilization (MFU) on flagship GPUs during training and inference, respectively, aligning closely with the LLM community. This architecture significantly reduces communication and storage overhead, resulting in operating expense that is only 10.6% of traditional recommendation pipelines. Deployed in Kuaishou/Kuaishou Lite APP, it handles 25% of total queries per second, enhancing overall App Stay Time by 0.54% and 1.24%, respectively. Additionally, we have observed significant increases in metrics such as 7-day Lifetime, which is a crucial indicator of recommendation experience. We also provide practical lessons and insights derived from developing, optimizing, and maintaining a production-scale recommendation system with significant real-world impact.
CEBSNet: Change-Excited and Background-Suppressed Network with Temporal Dependency Modeling for Bitemporal Change Detection
May 21, 2025Change detection, a critical task in remote sensing and computer vision, aims to identify pixel-level differences between image pairs captured at the same geographic area but different times. It faces numerous challenges such as illumination variation, seasonal changes, background interference, and shooting angles, especially with a large time gap between images. While current methods have advanced, they often overlook temporal dependencies and overemphasize prominent changes while ignoring subtle but equally important changes. To address these limitations, we introduce \textbf{CEBSNet}, a novel change-excited and background-suppressed network with temporal dependency modeling for change detection. During the feature extraction, we utilize a simple Channel Swap Module (CSM) to model temporal dependency, reducing differences and noise. The Feature Excitation and Suppression Module (FESM) is developed to capture both obvious and subtle changes, maintaining the integrity of change regions. Additionally, we design a Pyramid-Aware Spatial-Channel Attention module (PASCA) to enhance the ability to detect change regions at different sizes and focus on critical regions. We conduct extensive experiments on three common street view datasets and two remote sensing datasets, and our method achieves the state-of-the-art performance.
DenseGrounding: Improving Dense Language-Vision Semantics for Ego-Centric 3D Visual Grounding
May 08, 2025Enabling intelligent agents to comprehend and interact with 3D environments through natural language is crucial for advancing robotics and human-computer interaction. A fundamental task in this field is ego-centric 3D visual grounding, where agents locate target objects in real-world 3D spaces based on verbal descriptions. However, this task faces two significant challenges: (1) loss of fine-grained visual semantics due to sparse fusion of point clouds with ego-centric multi-view images, (2) limited textual semantic context due to arbitrary language descriptions. We propose DenseGrounding, a novel approach designed to address these issues by enhancing both visual and textual semantics. For visual features, we introduce the Hierarchical Scene Semantic Enhancer, which retains dense semantics by capturing fine-grained global scene features and facilitating cross-modal alignment. For text descriptions, we propose a Language Semantic Enhancer that leverages large language models to provide rich context and diverse language descriptions with additional context during model training. Extensive experiments show that DenseGrounding significantly outperforms existing methods in overall accuracy, with improvements of 5.81% and 7.56% when trained on the comprehensive full dataset and smaller mini subset, respectively, further advancing the SOTA in egocentric 3D visual grounding. Our method also achieves 1st place and receives the Innovation Award in the CVPR 2024 Autonomous Grand Challenge Multi-view 3D Visual Grounding Track, validating its effectiveness and robustness.
Seeking Flat Minima over Diverse Surrogates for Improved Adversarial Transferability: A Theoretical Framework and Algorithmic Instantiation
Apr 23, 2025



The transfer-based black-box adversarial attack setting poses the challenge of crafting an adversarial example (AE) on known surrogate models that remain effective against unseen target models. Due to the practical importance of this task, numerous methods have been proposed to address this challenge. However, most previous methods are heuristically designed and intuitively justified, lacking a theoretical foundation. To bridge this gap, we derive a novel transferability bound that offers provable guarantees for adversarial transferability. Our theoretical analysis has the advantages of \textit{(i)} deepening our understanding of previous methods by building a general attack framework and \textit{(ii)} providing guidance for designing an effective attack algorithm. Our theoretical results demonstrate that optimizing AEs toward flat minima over the surrogate model set, while controlling the surrogate-target model shift measured by the adversarial model discrepancy, yields a comprehensive guarantee for AE transferability. The results further lead to a general transfer-based attack framework, within which we observe that previous methods consider only partial factors contributing to the transferability. Algorithmically, inspired by our theoretical results, we first elaborately construct the surrogate model set in which models exhibit diverse adversarial vulnerabilities with respect to AEs to narrow an instantiated adversarial model discrepancy. Then, a \textit{model-Diversity-compatible Reverse Adversarial Perturbation} (DRAP) is generated to effectively promote the flatness of AEs over diverse surrogate models to improve transferability. Extensive experiments on NIPS2017 and CIFAR-10 datasets against various target models demonstrate the effectiveness of our proposed attack.
ADGaussian: Generalizable Gaussian Splatting for Autonomous Driving with Multi-modal Inputs
Apr 01, 2025We present a novel approach, termed ADGaussian, for generalizable street scene reconstruction. The proposed method enables high-quality rendering from single-view input. Unlike prior Gaussian Splatting methods that primarily focus on geometry refinement, we emphasize the importance of joint optimization of image and depth features for accurate Gaussian prediction. To this end, we first incorporate sparse LiDAR depth as an additional input modality, formulating the Gaussian prediction process as a joint learning framework of visual information and geometric clue. Furthermore, we propose a multi-modal feature matching strategy coupled with a multi-scale Gaussian decoding model to enhance the joint refinement of multi-modal features, thereby enabling efficient multi-modal Gaussian learning. Extensive experiments on two large-scale autonomous driving datasets, Waymo and KITTI, demonstrate that our ADGaussian achieves state-of-the-art performance and exhibits superior zero-shot generalization capabilities in novel-view shifting.
Robust Self-Reconfiguration for Fault-Tolerant Control of Modular Aerial Robot Systems
Mar 12, 2025



Modular Aerial Robotic Systems (MARS) consist of multiple drone units assembled into a single, integrated rigid flying platform. With inherent redundancy, MARS can self-reconfigure into different configurations to mitigate rotor or unit failures and maintain stable flight. However, existing works on MARS self-reconfiguration often overlook the practical controllability of intermediate structures formed during the reassembly process, which limits their applicability. In this paper, we address this gap by considering the control-constrained dynamic model of MARS and proposing a robust and efficient self-reconstruction algorithm that maximizes the controllability margin at each intermediate stage. Specifically, we develop algorithms to compute optimal, controllable disassembly and assembly sequences, enabling robust self-reconfiguration. Finally, we validate our method in several challenging fault-tolerant self-reconfiguration scenarios, demonstrating significant improvements in both controllability and trajectory tracking while reducing the number of assembly steps. The videos and source code of this work are available at https://github.com/RuiHuangNUS/MARS-Reconfig/
Robust Fault-Tolerant Control and Agile Trajectory Planning for Modular Aerial Robotic Systems
Mar 12, 2025Modular Aerial Robotic Systems (MARS) consist of multiple drone units that can self-reconfigure to adapt to various mission requirements and fault conditions. However, existing fault-tolerant control methods exhibit significant oscillations during docking and separation, impacting system stability. To address this issue, we propose a novel fault-tolerant control reallocation method that adapts to arbitrary number of modular robots and their assembly formations. The algorithm redistributes the expected collective force and torque required for MARS to individual unit according to their moment arm relative to the center of MARS mass. Furthermore, We propose an agile trajectory planning method for MARS of arbitrary configurations, which is collision-avoiding and dynamically feasible. Our work represents the first comprehensive approach to enable fault-tolerant and collision avoidance flight for MARS. We validate our method through extensive simulations, demonstrating improved fault tolerance, enhanced trajectory tracking accuracy, and greater robustness in cluttered environments. The videos and source code of this work are available at https://github.com/RuiHuangNUS/MARS-FTCC/
Gaussian Difference: Find Any Change Instance in 3D Scenes
Feb 24, 2025Instance-level change detection in 3D scenes presents significant challenges, particularly in uncontrolled environments lacking labeled image pairs, consistent camera poses, or uniform lighting conditions. This paper addresses these challenges by introducing a novel approach for detecting changes in real-world scenarios. Our method leverages 4D Gaussians to embed multiple images into Gaussian distributions, enabling the rendering of two coherent image sequences. We segment each image and assign unique identifiers to instances, facilitating efficient change detection through ID comparison. Additionally, we utilize change maps and classification encodings to categorize 4D Gaussians as changed or unchanged, allowing for the rendering of comprehensive change maps from any viewpoint. Extensive experiments across various instance-level change detection datasets demonstrate that our method significantly outperforms state-of-the-art approaches like C-NERF and CYWS-3D, especially in scenarios with substantial lighting variations. Our approach offers improved detection accuracy, robustness to lighting changes, and efficient processing times, advancing the field of 3D change detection.
PoI: Pixel of Interest for Novel View Synthesis Assisted Scene Coordinate Regression
Feb 07, 2025The task of estimating camera poses can be enhanced through novel view synthesis techniques such as NeRF and Gaussian Splatting to increase the diversity and extension of training data. However, these techniques often produce rendered images with issues like blurring and ghosting, which compromise their reliability. These issues become particularly pronounced for Scene Coordinate Regression (SCR) methods, which estimate 3D coordinates at the pixel level. To mitigate the problems associated with unreliable rendered images, we introduce a novel filtering approach, which selectively extracts well-rendered pixels while discarding the inferior ones. This filter simultaneously measures the SCR model's real-time reprojection loss and gradient during training. Building on this filtering technique, we also develop a new strategy to improve scene coordinate regression using sparse inputs, drawing on successful applications of sparse input techniques in novel view synthesis. Our experimental results validate the effectiveness of our method, demonstrating state-of-the-art performance on indoor and outdoor datasets.