 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Shapley Computation
May 20, 2026Shapley-based data valuation provides a principled way to quantify the contribution of training data, but its high computational cost makes it impractical in dynamic settings where tasks and training players evolve. Existing methods treat Shapley computation as a one-shot process and collapse contributions into aggregated scores, preventing reuse and requiring recomputation under any change. We introduce a new perspective that represents Shapley values as a player-by-task matrix and formulates dynamic valuation as a structured matrix maintenance problem. We exploit the fact that each task depends on a small subset of training players and that similar tasks yield similar valuations, leading to utility locality and coalition locality. Based on these insights, we propose D-Shap, a dynamic valuation framework that enables efficient updates by modifying only a small portion of the matrix: new task valuations are inferred via structure-aware interpolation, while updates induced by new players are confined to affected local matrix blocks. To eliminate the need for pre-specified evaluation tasks, we introduce self-valuation, which constructs the initial matrix directly from training data, supported by scalable subset reuse and coverage-aware anchor selection. Experiments across diverse models show that D-Shap performs task updates in milliseconds and reduces the cost of player updates by up to three orders of magnitude, while achieving valuation quality competitive with full recomputation.
Interference-Aware Multi-Task Unlearning
May 18, 2026Machine unlearning aims to remove the contribution of designated training data from a trained model while preserving performance on the remaining data. Existing work mainly focuses on single-task settings, whereas modern models often operate in multi-task setups with shared backbones, where removing supervision for one task or instance can unintentionally affect others. We introduce multi-task unlearning with two settings: full-task unlearning, which removes a target instance from all tasks, and partial-task unlearning, which removes supervision only from selected tasks. We show that shared parameters couple the forget and retain sets, causing task-level interference on non-target tasks and instance-level interference on other instances. To address this issue, we propose an interference-aware framework that combines task-aware gradient projection, which constrains updates within task-specific subspaces, with instance-level gradient orthogonalization, which reduces conflicts between forget and retain signals. Experiments on two multi-task computer vision benchmarks across five tasks show that our method achieves effective unlearning while maintaining strong generalization, reducing UIS compared with the strongest baseline by 30.3% in full-task unlearning and 52.9% in partial-task unlearning.
Local Shapley: Model-Induced Locality and Optimal Reuse in Data Valuation
Mar 04, 2026The Shapley value provides a principled foundation for data valuation, but exact computation is #P-hard due to the exponential coalition space. Existing accelerations remain global and ignore a structural property of modern predictors: for a given test instance, only a small subset of training points influences the prediction. We formalize this model-induced locality through support sets defined by the model's computational pathway (e.g., neighbors in KNN, leaves in trees, receptive fields in GNNs), showing that Shapley computation can be projected onto these supports without loss when locality is exact. This reframes Shapley evaluation as a structured data processing problem over overlapping support-induced subset families rather than exhaustive coalition enumeration. We prove that the intrinsic complexity of Local Shapley is governed by the number of distinct influential subsets, establishing an information-theoretic lower bound on retraining operations. Guided by this result, we propose LSMR (Local Shapley via Model Reuse), an optimal subset-centric algorithm that trains each influential subset exactly once via support mapping and pivot scheduling. For larger supports, we develop LSMR-A, a reuse-aware Monte Carlo estimator that remains unbiased with exponential concentration, with runtime determined by the number of distinct sampled subsets rather than total draws. Experiments across multiple model families demonstrate substantial retraining reductions and speedups while preserving high valuation fidelity.
Self-guided Knowledgeable Network of Thoughts: Amplifying Reasoning with Large Language Models
Dec 21, 2024We introduce Knowledgeable Network of Thoughts (kNoT): a prompt scheme that advances the capabilities of large language models (LLMs) beyond existing paradigms like Chain-of-Thought (CoT), Tree of Thoughts (ToT), and Graph of Thoughts (GoT). The key innovation of kNoT is the LLM Workflow Template (LWT), which allows for an executable plan to be specified by LLMs for LLMs. LWT allows these plans to be arbitrary networks, where single-step LLM operations are nodes, and edges correspond to message passing between these steps. Furthermore, LWT supports selection of individual elements through indexing, facilitating kNoT to produce intricate plans where each LLM operation can be limited to elementary operations, greatly enhancing reliability over extended task sequences. We demonstrate that kNoT significantly outperforms the state of the art on six use cases, while reducing the need for extensive prompt engineering. For instance, kNoT finds 92% accuracy for sorting 32 numbers over 12% and 31% for ToT and GoT, while utilizing up to 84.4% and 87.3% less task-specific prompts, respectively.
Evaluating Adversarial Robustness in the Spatial Frequency Domain
May 10, 2024Convolutional Neural Networks (CNNs) have dominated the majority of computer vision tasks. However, CNNs' vulnerability to adversarial attacks has raised concerns about deploying these models to safety-critical applications. In contrast, the Human Visual System (HVS), which utilizes spatial frequency channels to process visual signals, is immune to adversarial attacks. As such, this paper presents an empirical study exploring the vulnerability of CNN models in the frequency domain. Specifically, we utilize the discrete cosine transform (DCT) to construct the Spatial-Frequency (SF) layer to produce a block-wise frequency spectrum of an input image and formulate Spatial Frequency CNNs (SF-CNNs) by replacing the initial feature extraction layers of widely-used CNN backbones with the SF layer. Through extensive experiments, we observe that SF-CNN models are more robust than their CNN counterparts under both white-box and black-box attacks. To further explain the robustness of SF-CNNs, we compare the SF layer with a trainable convolutional layer with identical kernel sizes using two mixing strategies to show that the lower frequency components contribute the most to the adversarial robustness of SF-CNNs. We believe our observations can guide the future design of robust CNN models.
In Anticipation of Perfect Deepfake: Identity-anchored Artifact-agnostic Detection under Rebalanced Deepfake Detection Protocol
May 01, 2024As deep generative models advance, we anticipate deepfakes achieving "perfection"-generating no discernible artifacts or noise. However, current deepfake detectors, intentionally or inadvertently, rely on such artifacts for detection, as they are exclusive to deepfakes and absent in genuine examples. To bridge this gap, we introduce the Rebalanced Deepfake Detection Protocol (RDDP) to stress-test detectors under balanced scenarios where genuine and forged examples bear similar artifacts. We offer two RDDP variants: RDDP-WHITEHAT uses white-hat deepfake algorithms to create 'self-deepfakes,' genuine portrait videos with the resemblance of the underlying identity, yet carry similar artifacts to deepfake videos; RDDP-SURROGATE employs surrogate functions (e.g., Gaussian noise) to process both genuine and forged examples, introducing equivalent noise, thereby sidestepping the need of deepfake algorithms. Towards detecting perfect deepfake videos that aligns with genuine ones, we present ID-Miner, a detector that identifies the puppeteer behind the disguise by focusing on motion over artifacts or appearances. As an identity-based detector, it authenticates videos by comparing them with reference footage. Equipped with the artifact-agnostic loss at frame-level and the identity-anchored loss at video-level, ID-Miner effectively singles out identity signals amidst distracting variations. Extensive experiments comparing ID-Miner with 12 baseline detectors under both conventional and RDDP evaluations with two deepfake datasets, along with additional qualitative studies, affirm the superiority of our method and the necessity for detectors designed to counter perfect deepfakes.
Dual Adversarial Alignment for Realistic Support-Query Shift Few-shot Learning
Sep 05, 2023Support-query shift few-shot learning aims to classify unseen examples (query set) to labeled data (support set) based on the learned embedding in a low-dimensional space under a distribution shift between the support set and the query set. However, in real-world scenarios the shifts are usually unknown and varied, making it difficult to estimate in advance. Therefore, in this paper, we propose a novel but more difficult challenge, RSQS, focusing on Realistic Support-Query Shift few-shot learning. The key feature of RSQS is that the individual samples in a meta-task are subjected to multiple distribution shifts in each meta-task. In addition, we propose a unified adversarial feature alignment method called DUal adversarial ALignment framework (DuaL) to relieve RSQS from two aspects, i.e., inter-domain bias and intra-domain variance. On the one hand, for the inter-domain bias, we corrupt the original data in advance and use the synthesized perturbed inputs to train the repairer network by minimizing distance in the feature level. On the other hand, for intra-domain variance, we proposed a generator network to synthesize hard, i.e., less similar, examples from the support set in a self-supervised manner and introduce regularized optimal transportation to derive a smooth optimal transportation plan. Lastly, a benchmark of RSQS is built with several state-of-the-art baselines among three datasets (CIFAR100, mini-ImageNet, and Tiered-Imagenet). Experiment results show that DuaL significantly outperforms the state-of-the-art methods in our benchmark.
PGADA: Perturbation-Guided Adversarial Alignment for Few-shot Learning Under the Support-Query Shift
May 08, 2022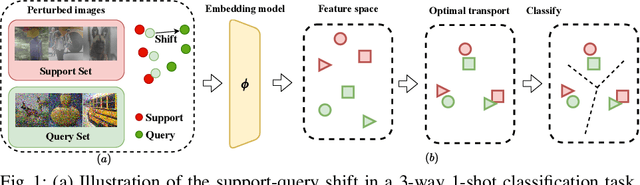
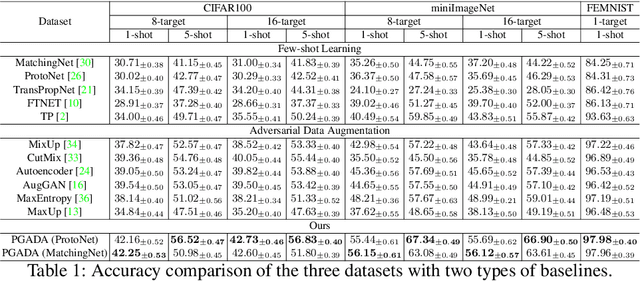
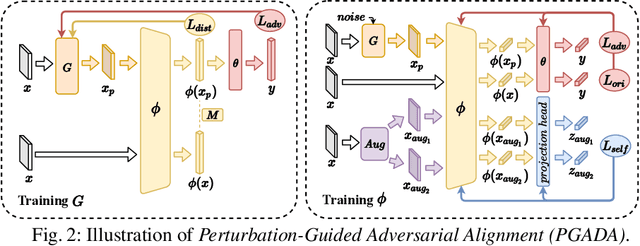
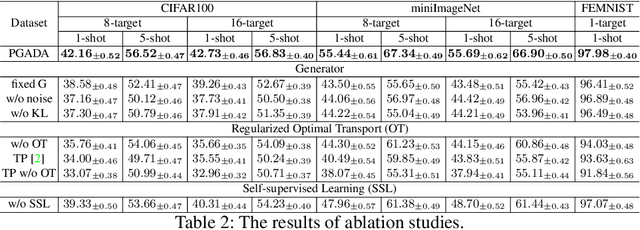
Few-shot learning methods aim to embed the data to a low-dimensional embedding space and then classify the unseen query data to the seen support set. While these works assume that the support set and the query set lie in the same embedding space, a distribution shift usually occurs between the support set and the query set, i.e., the Support-Query Shift, in the real world. Though optimal transportation has shown convincing results in aligning different distributions, we find that the small perturbations in the images would significantly misguide the optimal transportation and thus degrade the model performance. To relieve the misalignment, we first propose a novel adversarial data augmentation method, namely Perturbation-Guided Adversarial Alignment (PGADA), which generates the hard examples in a self-supervised manner. In addition, we introduce Regularized Optimal Transportation to derive a smooth optimal transportation plan. Extensive experiments on three benchmark datasets manifest that our framework significantly outperforms the eleven state-of-the-art methods on three datasets.
Attack as the Best Defense: Nullifying Image-to-image Translation GANs via Limit-aware Adversarial Attack
Oct 06, 2021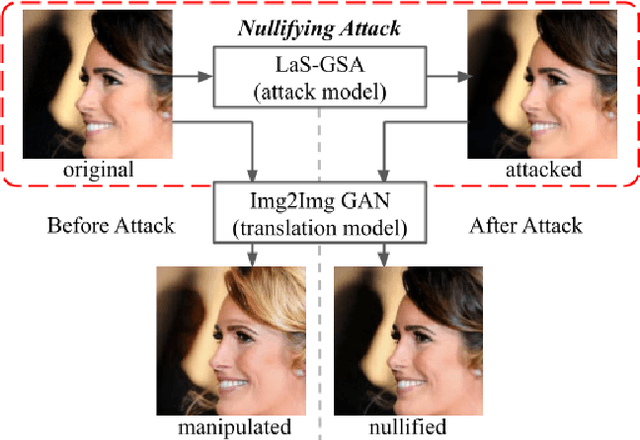
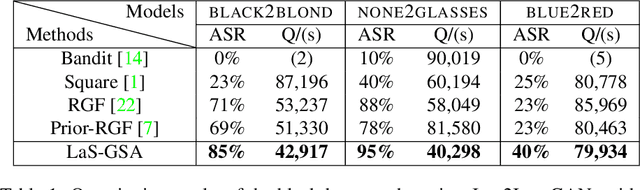
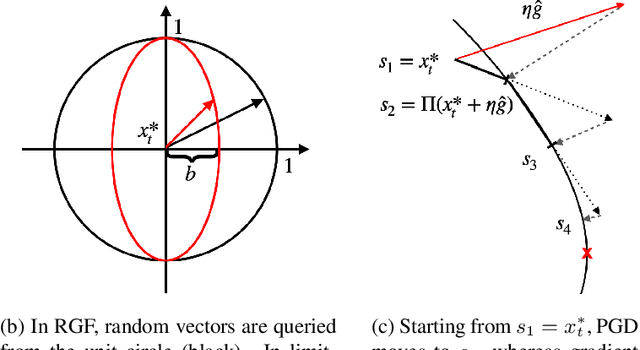

With the successful creation of high-quality image-to-image (Img2Img) translation GANs comes the non-ethical applications of DeepFake and DeepNude. Such misuses of img2img techniques present a challenging problem for society. In this work, we tackle the problem by introducing the Limit-Aware Self-Guiding Gradient Sliding Attack (LaS-GSA). LaS-GSA follows the Nullifying Attack to cancel the img2img translation process under a black-box setting. In other words, by processing input images with the proposed LaS-GSA before publishing, any targeted img2img GANs can be nullified, preventing the model from maliciously manipulating the images. To improve efficiency, we introduce the limit-aware random gradient-free estimation and the gradient sliding mechanism to estimate the gradient that adheres to the adversarial limit, i.e., the pixel value limitations of the adversarial example. Theoretical justifications validate how the above techniques prevent inefficiency caused by the adversarial limit in both the direction and the step length. Furthermore, an effective self-guiding prior is extracted solely from the threat model and the target image to efficiently leverage the prior information and guide the gradient estimation process. Extensive experiments demonstrate that LaS-GSA requires fewer queries to nullify the image translation process with higher success rates than 4 state-of-the-art black-box methods.