 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-attention Dual Embedding for Graphs with Heterophily
May 28, 2023Graph Neural Networks (GNNs) have been highly successful for the node classification task. GNNs typically assume graphs are homophilic, i.e. neighboring nodes are likely to belong to the same class. However, a number of real-world graphs are heterophilic, and this leads to much lower classification accuracy using standard GNNs. In this work, we design a novel GNN which is effective for both heterophilic and homophilic graphs. Our work is based on three main observations. First, we show that node features and graph topology provide different amounts of informativeness in different graphs, and therefore they should be encoded independently and prioritized in an adaptive manner. Second, we show that allowing negative attention weights when propagating graph topology information improves accuracy. Finally, we show that asymmetric attention weights between nodes are helpful. We design a GNN which makes use of these observations through a novel self-attention mechanism. We evaluate our algorithm on real-world graphs containing thousands to millions of nodes and show that we achieve state-of-the-art results compared to existing GNNs. We also analyze the effectiveness of the main components of our design on different graphs.
D2NT: A High-Performing Depth-to-Normal Translator
Apr 24, 2023Surface normal holds significant importance in visual environmental perception, serving as a source of rich geometric information. However, the state-of-the-art (SoTA) surface normal estimators (SNEs) generally suffer from an unsatisfactory trade-off between efficiency and accuracy. To resolve this dilemma, this paper first presents a superfast depth-to-normal translator (D2NT), which can directly translate depth images into surface normal maps without calculating 3D coordinates. We then propose a discontinuity-aware gradient (DAG) filter, which adaptively generates gradient convolution kernels to improve depth gradient estimation. Finally, we propose a surface normal refinement module that can easily be integrated into any depth-to-normal SNEs, substantially improving the surface normal estimation accuracy. Our proposed algorithm demonstrates the best accuracy among all other existing real-time SNEs and achieves the SoTA trade-off between efficiency and accuracy.
UDTIRI: An Open-Source Road Pothole Detection Benchmark Suite
Apr 18, 2023



It is seen that there is enormous potential to leverage powerful deep learning methods in the emerging field of urban digital twins. It is particularly in the area of intelligent road inspection where there is currently limited research and data available. To facilitate progress in this field, we have developed a well-labeled road pothole dataset named Urban Digital Twins Intelligent Road Inspection (UDTIRI) dataset. We hope this dataset will enable the use of powerful deep learning methods in urban road inspection, providing algorithms with a more comprehensive understanding of the scene and maximizing their potential. Our dataset comprises 1000 images of potholes, captured in various scenarios with different lighting and humidity conditions. Our intention is to employ this dataset for object detection, semantic segmentation, and instance segmentation tasks. Our team has devoted significant effort to conducting a detailed statistical analysis, and benchmarking a selection of representative algorithms from recent years. We also provide a multi-task platform for researchers to fully exploit the performance of various algorithms with the support of UDTIRI dataset.
Temporal Segment Transformer for Action Segmentation
Feb 25, 2023



Recognizing human actions from untrimmed videos is an important task in activity understanding, and poses unique challenges in modeling long-range temporal relations. Recent works adopt a predict-and-refine strategy which converts an initial prediction to action segments for global context modeling. However, the generated segment representations are often noisy and exhibit inaccurate segment boundaries, over-segmentation and other problems. To deal with these issues, we propose an attention based approach which we call \textit{temporal segment transformer}, for joint segment relation modeling and denoising. The main idea is to denoise segment representations using attention between segment and frame representations, and also use inter-segment attention to capture temporal correlations between segments. The refined segment representations are used to predict action labels and adjust segment boundaries, and a final action segmentation is produced based on voting from segment masks. We show that this novel architecture achieves state-of-the-art accuracy on the popular 50Salads, GTEA and Breakfast benchmarks. We also conduct extensive ablations to demonstrate the effectiveness of different components of our design.
Risk-Aware Bid Optimization for Online Display Advertisement
Oct 28, 2022



This research focuses on the bid optimization problem in the real-time bidding setting for online display advertisements, where an advertiser, or the advertiser's agent, has access to the features of the website visitor and the type of ad slots, to decide the optimal bid prices given a predetermined total advertisement budget. We propose a risk-aware data-driven bid optimization model that maximizes the expected profit for the advertiser by exploiting historical data to design upfront a bidding policy, mapping the type of advertisement opportunity to a bid price, and accounting for the risk of violating the budget constraint during a given period of time. After employing a Lagrangian relaxation, we derive a parametrized closed-form expression for the optimal bidding strategy. Using a real-world dataset, we demonstrate that our risk-averse method can effectively control the risk of overspending the budget while achieving a competitive level of profit compared with the risk-neutral model and a state-of-the-art data-driven risk-aware bidding approach.
SIM2E: Benchmarking the Group Equivariant Capability of Correspondence Matching Algorithms
Aug 21, 2022
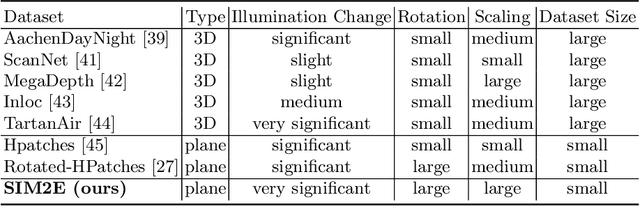

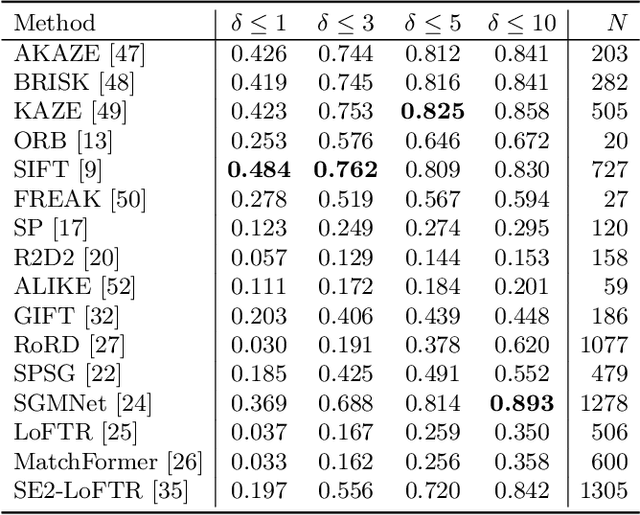
Correspondence matching is a fundamental problem in computer vision and robotics applications. Solving correspondence matching problems using neural networks has been on the rise recently. Rotation-equivariance and scale-equivariance are both critical in correspondence matching applications. Classical correspondence matching approaches are designed to withstand scaling and rotation transformations. However, the features extracted using convolutional neural networks (CNNs) are only translation-equivariant to a certain extent. Recently, researchers have strived to improve the rotation-equivariance of CNNs based on group theories. Sim(2) is the group of similarity transformations in the 2D plane. This paper presents a specialized dataset dedicated to evaluating sim(2)-equivariant correspondence matching algorithms. We compare the performance of 16 state-of-the-art (SoTA) correspondence matching approaches. The experimental results demonstrate the importance of group equivariant algorithms for correspondence matching on various sim(2) transformation conditions. Since the subpixel accuracy achieved by CNN-based correspondence matching approaches is unsatisfactory, this specific area requires more attention in future works. Our dataset is publicly available at: mias.group/SIM2E.
SDA-SNE: Spatial Discontinuity-Aware Surface Normal Estimation via Multi-Directional Dynamic Programming
Aug 18, 2022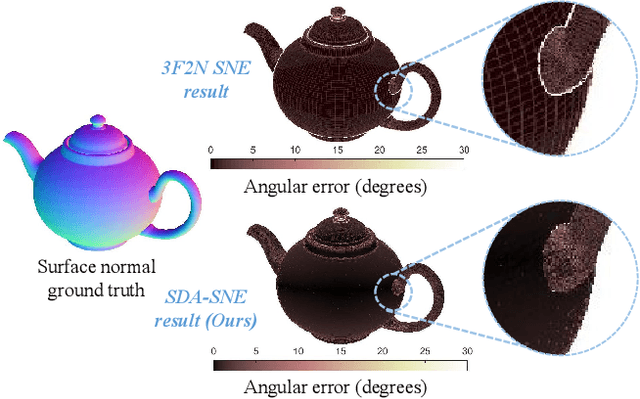
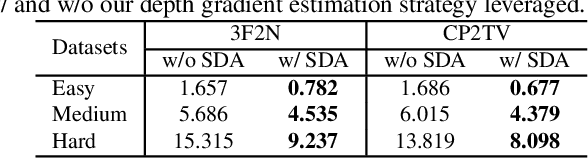
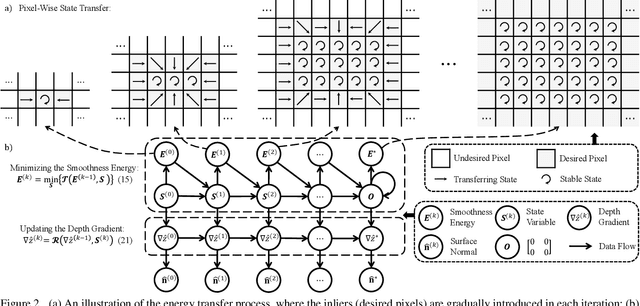
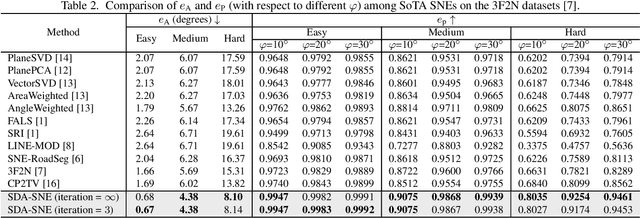
The state-of-the-art (SoTA) surface normal estimators (SNEs) generally translate depth images into surface normal maps in an end-to-end fashion. Although such SNEs have greatly minimized the trade-off between efficiency and accuracy, their performance on spatial discontinuities, e.g., edges and ridges, is still unsatisfactory. To address this issue, this paper first introduces a novel multi-directional dynamic programming strategy to adaptively determine inliers (co-planar 3D points) by minimizing a (path) smoothness energy. The depth gradients can then be refined iteratively using a novel recursive polynomial interpolation algorithm, which helps yield more reasonable surface normals. Our introduced spatial discontinuity-aware (SDA) depth gradient refinement strategy is compatible with any depth-to-normal SNEs. Our proposed SDA-SNE achieves much greater performance than all other SoTA approaches, especially near/on spatial discontinuities. We further evaluate the performance of SDA-SNE with respect to different iterations, and the results suggest that it converges fast after only a few iterations. This ensures its high efficiency in various robotics and computer vision applications requiring real-time performance. Additional experiments on the datasets with different extents of random noise further validate our SDA-SNE's robustness and environmental adaptability. Our source code, demo video, and supplementary material are publicly available at mias.group/SDA-SNE.
Computer Vision for Road Imaging and Pothole Detection: A State-of-the-Art Review of Systems and Algorithms
Apr 28, 2022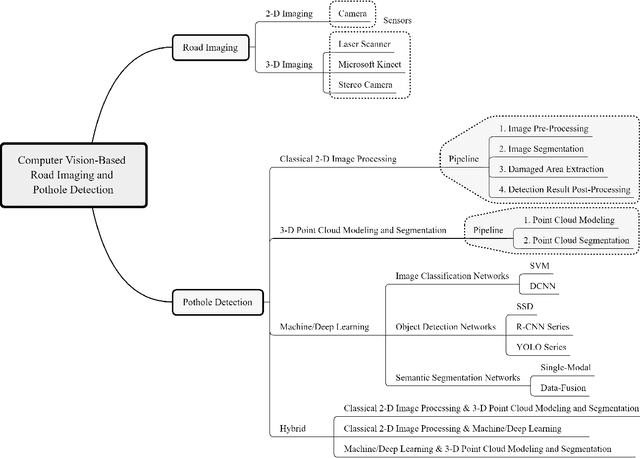
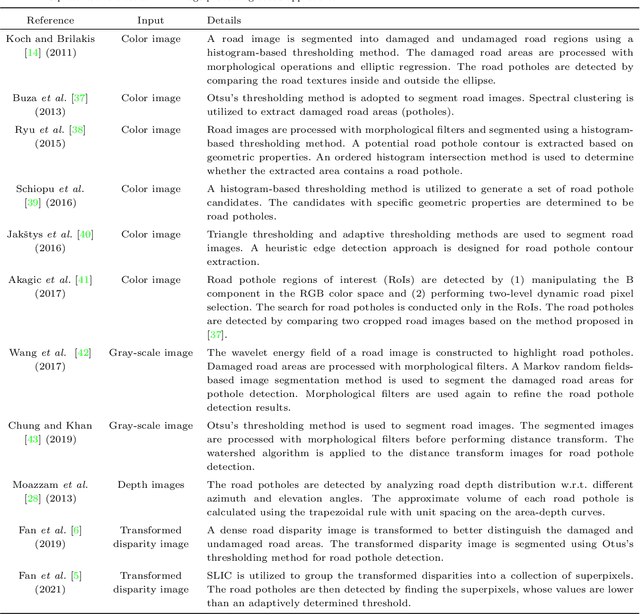

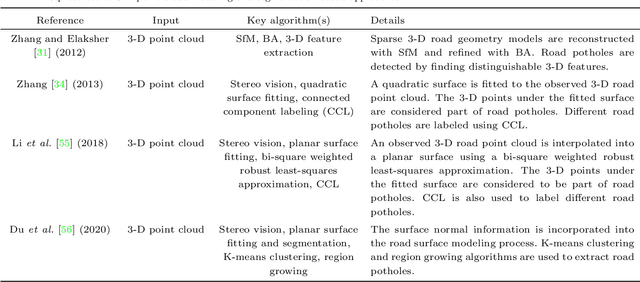
Computer vision algorithms have been prevalently utilized for 3-D road imaging and pothole detection for over two decades. Nonetheless, there is a lack of systematic survey articles on state-of-the-art (SoTA) computer vision techniques, especially deep learning models, developed to tackle these problems. This article first introduces the sensing systems employed for 2-D and 3-D road data acquisition, including camera(s), laser scanners, and Microsoft Kinect. Afterward, it thoroughly and comprehensively reviews the SoTA computer vision algorithms, including (1) classical 2-D image processing, (2) 3-D point cloud modeling and segmentation, and (3) machine/deep learning, developed for road pothole detection. This article also discusses the existing challenges and future development trends of computer vision-based road pothole detection approaches: classical 2-D image processing-based and 3-D point cloud modeling and segmentation-based approaches have already become history; and Convolutional neural networks (CNNs) have demonstrated compelling road pothole detection results and are promising to break the bottleneck with the future advances in self/un-supervised learning for multi-modal semantic segmentation. We believe that this survey can serve as practical guidance for developing the next-generation road condition assessment systems.
Computer-Aided Road Inspection: Systems and Algorithms
Mar 04, 2022
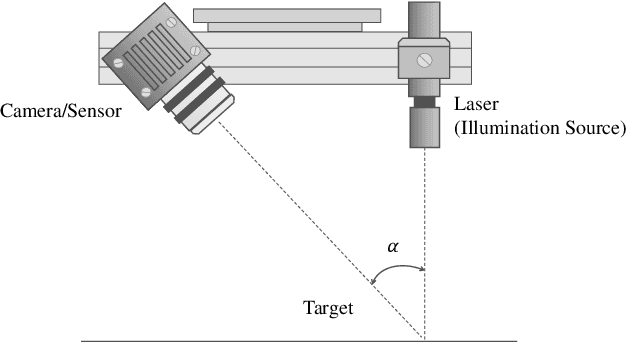
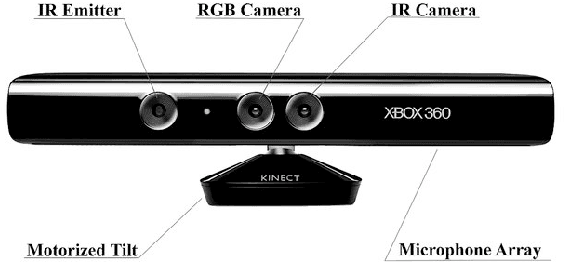
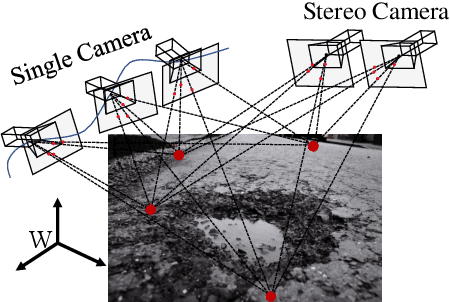
Road damage is an inconvenience and a safety hazard, severely affecting vehicle condition, driving comfort, and traffic safety. The traditional manual visual road inspection process is pricey, dangerous, exhausting, and cumbersome. Also, manual road inspection results are qualitative and subjective, as they depend entirely on the inspector's personal experience. Therefore, there is an ever-increasing need for automated road inspection systems. This chapter first compares the five most common road damage types. Then, 2-D/3-D road imaging systems are discussed. Finally, state-of-the-art machine vision and intelligence-based road damage detection algorithms are introduced.
Multi-Scale Feature Fusion: Learning Better Semantic Segmentation for Road Pothole Detection
Dec 24, 2021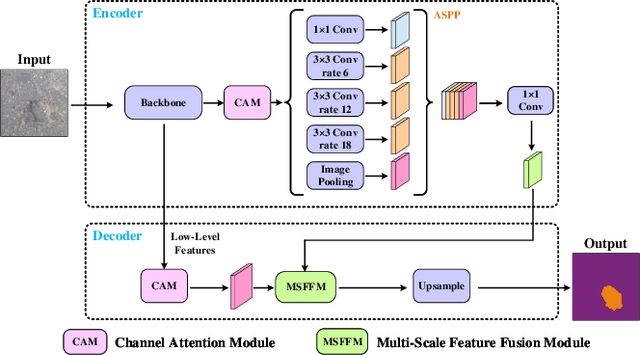
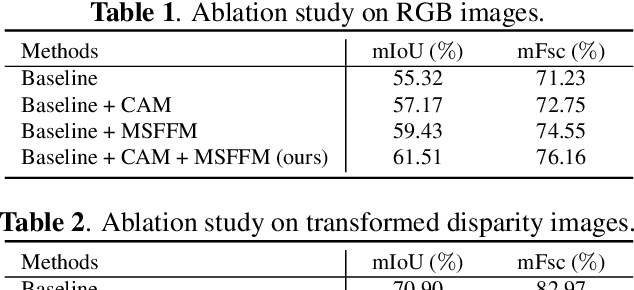
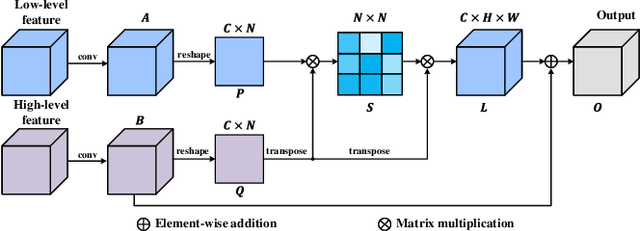
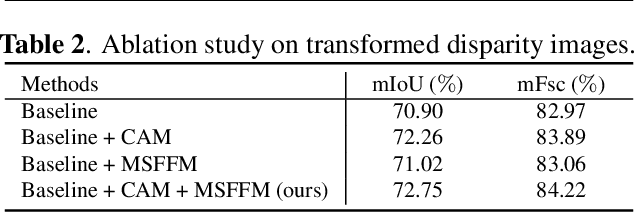
This paper presents a novel pothole detection approach based on single-modal semantic segmentation. It first extracts visual features from input images using a convolutional neural network. A channel attention module then reweighs the channel features to enhance the consistency of different feature maps. Subsequently, we employ an atrous spatial pyramid pooling module (comprising of atrous convolutions in series, with progressive rates of dilation) to integrate the spatial context information. This helps better distinguish between potholes and undamaged road areas. Finally, the feature maps in the adjacent layers are fused using our proposed multi-scale feature fusion module. This further reduces the semantic gap between different feature channel layers. Extensive experiments were carried out on the Pothole-600 dataset to demonstrate the effectiveness of our proposed method. The quantitative comparisons suggest that our method achieves the state-of-the-art (SoTA) performance on both RGB images and transformed disparity images, outperforming three SoTA single-modal semantic segmentation networks.