 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructured prototype regularization for synthetic-to-real driving scene parsing
Mar 17, 2026Driving scene parsing is critical for autonomous vehicles to operate reliably in complex real-world traffic environments. To reduce the reliance on costly pixel-level annotations, synthetic datasets with automatically generated labels have become a popular alternative. However, models trained on synthetic data often perform poorly when applied to real-world scenes due to the synthetic-to-real domain gap. Despite the success of unsupervised domain adaptation in narrowing this gap, most existing methods mainly focus on global feature alignment while overlooking the semantic structure of the feature space. As a result, semantic relations among classes are insufficiently modeled, limiting the model's ability to generalize. To address these challenges, this study introduces a novel unsupervised domain adaptation framework that explicitly regularizes semantic feature structures to significantly enhance driving scene parsing performance in real-world scenarios. Specifically, the proposed method enforces inter-class separation and intra-class compactness by leveraging class-specific prototypes, thereby enhancing the discriminability and structural coherence of feature clusters. An entropy-based noise filtering strategy improves the reliability of pseudo labels, while a pixel-level attention mechanism further refines feature alignment. Extensive experiments on representative benchmarks demonstrate that the proposed method consistently outperforms recent state-of-the-art methods. These results underscore the importance of preserving semantic structure for robust synthetic-to-real adaptation in driving scene parsing tasks.
DepthMatch: Semi-Supervised RGB-D Scene Parsing through Depth-Guided Regularization
May 26, 2025RGB-D scene parsing methods effectively capture both semantic and geometric features of the environment, demonstrating great potential under challenging conditions such as extreme weather and low lighting. However, existing RGB-D scene parsing methods predominantly rely on supervised training strategies, which require a large amount of manually annotated pixel-level labels that are both time-consuming and costly. To overcome these limitations, we introduce DepthMatch, a semi-supervised learning framework that is specifically designed for RGB-D scene parsing. To make full use of unlabeled data, we propose complementary patch mix-up augmentation to explore the latent relationships between texture and spatial features in RGB-D image pairs. We also design a lightweight spatial prior injector to replace traditional complex fusion modules, improving the efficiency of heterogeneous feature fusion. Furthermore, we introduce depth-guided boundary loss to enhance the model's boundary prediction capabilities. Experimental results demonstrate that DepthMatch exhibits high applicability in both indoor and outdoor scenes, achieving state-of-the-art results on the NYUv2 dataset and ranking first on the KITTI Semantics benchmark.
Multi-Scale Feature Fusion: Learning Better Semantic Segmentation for Road Pothole Detection
Dec 24, 2021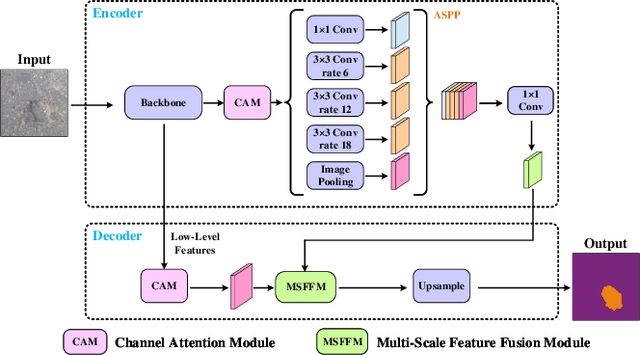
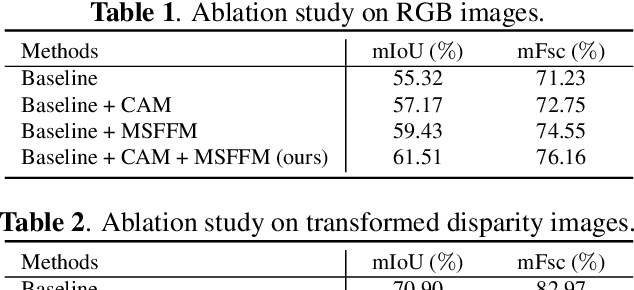
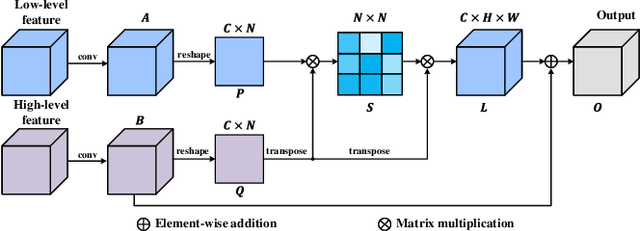
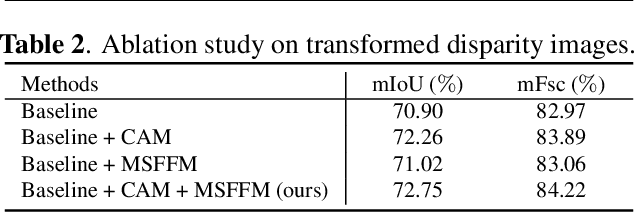
This paper presents a novel pothole detection approach based on single-modal semantic segmentation. It first extracts visual features from input images using a convolutional neural network. A channel attention module then reweighs the channel features to enhance the consistency of different feature maps. Subsequently, we employ an atrous spatial pyramid pooling module (comprising of atrous convolutions in series, with progressive rates of dilation) to integrate the spatial context information. This helps better distinguish between potholes and undamaged road areas. Finally, the feature maps in the adjacent layers are fused using our proposed multi-scale feature fusion module. This further reduces the semantic gap between different feature channel layers. Extensive experiments were carried out on the Pothole-600 dataset to demonstrate the effectiveness of our proposed method. The quantitative comparisons suggest that our method achieves the state-of-the-art (SoTA) performance on both RGB images and transformed disparity images, outperforming three SoTA single-modal semantic segmentation networks.