 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEpistemic Robust Offline Reinforcement Learning
Apr 08, 2026Offline reinforcement learning learns policies from fixed datasets without further environment interaction. A key challenge in this setting is epistemic uncertainty, arising from limited or biased data coverage, particularly when the behavior policy systematically avoids certain actions. This can lead to inaccurate value estimates and unreliable generalization. Ensemble-based methods like SAC-N mitigate this by conservatively estimating Q-values using the ensemble minimum, but they require large ensembles and often conflate epistemic with aleatoric uncertainty. To address these limitations, we propose a unified and generalizable framework that replaces discrete ensembles with compact uncertainty sets over Q-values. %We further introduce an Epinet based model that directly shapes the uncertainty sets to optimize the cumulative reward under the robust Bellman objective without relying on ensembles. We also introduce a benchmark for evaluating offline RL algorithms under risk-sensitive behavior policies, and demonstrate that our method achieves improved robustness and generalization over ensemble-based baselines across both tabular and continuous state domains.
Reward Redistribution for CVaR MDPs using a Bellman Operator on L-infinity
Feb 03, 2026Tail-end risk measures such as static conditional value-at-risk (CVaR) are used in safety-critical applications to prevent rare, yet catastrophic events. Unlike risk-neutral objectives, the static CVaR of the return depends on entire trajectories without admitting a recursive Bellman decomposition in the underlying Markov decision process. A classical resolution relies on state augmentation with a continuous variable. However, unless restricted to a specialized class of admissible value functions, this formulation induces sparse rewards and degenerate fixed points. In this work, we propose a novel formulation of the static CVaR objective based on augmentation. Our alternative approach leads to a Bellman operator with: (1) dense per-step rewards; (2) contracting properties on the full space of bounded value functions. Building on this theoretical foundation, we develop risk-averse value iteration and model-free Q-learning algorithms that rely on discretized augmented states. We further provide convergence guarantees and approximation error bounds due to discretization. Empirical results demonstrate that our algorithms successfully learn CVaR-sensitive policies and achieve effective performance-safety trade-offs.
Boosting CVaR Policy Optimization with Quantile Gradients
Jan 29, 2026Optimizing Conditional Value-at-risk (CVaR) using policy gradient (a.k.a CVaR-PG) faces significant challenges of sample inefficiency. This inefficiency stems from the fact that it focuses on tail-end performance and overlooks many sampled trajectories. We address this problem by augmenting CVaR with an expected quantile term. Quantile optimization admits a dynamic programming formulation that leverages all sampled data, thus improves sample efficiency. This does not alter the CVaR objective since CVaR corresponds to the expectation of quantile over the tail. Empirical results in domains with verifiable risk-averse behavior show that our algorithm within the Markovian policy class substantially improves upon CVaR-PG and consistently outperforms other existing methods.
Navigating Demand Uncertainty in Container Shipping: Deep Reinforcement Learning for Enabling Adaptive and Feasible Master Stowage Planning
Feb 19, 2025



Reinforcement learning (RL) has shown promise in solving various combinatorial optimization problems. However, conventional RL faces challenges when dealing with real-world constraints, especially when action space feasibility is explicit and dependent on the corresponding state or trajectory. In this work, we focus on using RL in container shipping, often considered the cornerstone of global trade, by dealing with the critical challenge of master stowage planning. The main objective is to maximize cargo revenue and minimize operational costs while navigating demand uncertainty and various complex operational constraints, namely vessel capacity and stability, which must be dynamically updated along the vessel's voyage. To address this problem, we implement a deep reinforcement learning framework with feasibility projection to solve the master stowage planning problem (MPP) under demand uncertainty. The experimental results show that our architecture efficiently finds adaptive, feasible solutions for this multi-stage stochastic optimization problem, outperforming traditional mixed-integer programming and RL with feasibility regularization. Our AI-driven decision-support policy enables adaptive and feasible planning under uncertainty, optimizing operational efficiency and capacity utilization while contributing to sustainable and resilient global supply chains.
Fair Resource Allocation in Weakly Coupled Markov Decision Processes
Nov 14, 2024



We consider fair resource allocation in sequential decision-making environments modeled as weakly coupled Markov decision processes, where resource constraints couple the action spaces of $N$ sub-Markov decision processes (sub-MDPs) that would otherwise operate independently. We adopt a fairness definition using the generalized Gini function instead of the traditional utilitarian (total-sum) objective. After introducing a general but computationally prohibitive solution scheme based on linear programming, we focus on the homogeneous case where all sub-MDPs are identical. For this case, we show for the first time that the problem reduces to optimizing the utilitarian objective over the class of "permutation invariant" policies. This result is particularly useful as we can exploit Whittle index policies in the restless bandits setting while, for the more general setting, we introduce a count-proportion-based deep reinforcement learning approach. Finally, we validate our theoretical findings with comprehensive experiments, confirming the effectiveness of our proposed method in achieving fairness.
Q-learning for Quantile MDPs: A Decomposition, Performance, and Convergence Analysis
Oct 31, 2024



In Markov decision processes (MDPs), quantile risk measures such as Value-at-Risk are a standard metric for modeling RL agents' preferences for certain outcomes. This paper proposes a new Q-learning algorithm for quantile optimization in MDPs with strong convergence and performance guarantees. The algorithm leverages a new, simple dynamic program (DP) decomposition for quantile MDPs. Compared with prior work, our DP decomposition requires neither known transition probabilities nor solving complex saddle point equations and serves as a suitable foundation for other model-free RL algorithms. Our numerical results in tabular domains show that our Q-learning algorithm converges to its DP variant and outperforms earlier algorithms.
Planning and Learning in Risk-Aware Restless Multi-Arm Bandit Problem
Oct 30, 2024In restless multi-arm bandits, a central agent is tasked with optimally distributing limited resources across several bandits (arms), with each arm being a Markov decision process. In this work, we generalize the traditional restless multi-arm bandit problem with a risk-neutral objective by incorporating risk-awareness. We establish indexability conditions for the case of a risk-aware objective and provide a solution based on Whittle index. In addition, we address the learning problem when the true transition probabilities are unknown by proposing a Thompson sampling approach and show that it achieves bounded regret that scales sublinearly with the number of episodes and quadratically with the number of arms. The efficacy of our method in reducing risk exposure in restless multi-arm bandits is illustrated through a set of numerical experiments.
Data-driven decision-making under uncertainty with entropic risk measure
Sep 30, 2024



The entropic risk measure is widely used in high-stakes decision making to account for tail risks associated with an uncertain loss. With limited data, the empirical entropic risk estimator, i.e. replacing the expectation in the entropic risk measure with a sample average, underestimates the true risk. To debias the empirical entropic risk estimator, we propose a strongly asymptotically consistent bootstrapping procedure. The first step of the procedure involves fitting a distribution to the data, whereas the second step estimates the bias of the empirical entropic risk estimator using bootstrapping, and corrects for it. We show that naively fitting a Gaussian Mixture Model to the data using the maximum likelihood criterion typically leads to an underestimation of the risk. To mitigate this issue, we consider two alternative methods: a more computationally demanding one that fits the distribution of empirical entropic risk, and a simpler one that fits the extreme value distribution. As an application of the approach, we study a distributionally robust entropic risk minimization problem with type-$\infty$ Wasserstein ambiguity set, where debiasing the validation performance using our techniques significantly improves the calibration of the size of the ambiguity set. Furthermore, we propose a distributionally robust optimization model for a well-studied insurance contract design problem. The model considers multiple (potential) policyholders that have dependent risks and the insurer and policyholders use entropic risk measure. We show that cross validation methods can result in significantly higher out-of-sample risk for the insurer if the bias in validation performance is not corrected for. This improvement can be explained from the observation that our methods suggest a higher (and more accurate) premium to homeowners.
End-to-end Conditional Robust Optimization
Mar 07, 2024



The field of Contextual Optimization (CO) integrates machine learning and optimization to solve decision making problems under uncertainty. Recently, a risk sensitive variant of CO, known as Conditional Robust Optimization (CRO), combines uncertainty quantification with robust optimization in order to promote safety and reliability in high stake applications. Exploiting modern differentiable optimization methods, we propose a novel end-to-end approach to train a CRO model in a way that accounts for both the empirical risk of the prescribed decisions and the quality of conditional coverage of the contextual uncertainty set that supports them. While guarantees of success for the latter objective are impossible to obtain from the point of view of conformal prediction theory, high quality conditional coverage is achieved empirically by ingeniously employing a logistic regression differentiable layer within the calculation of coverage quality in our training loss. We show that the proposed training algorithms produce decisions that outperform the traditional estimate then optimize approaches.
A Survey of Contextual Optimization Methods for Decision Making under Uncertainty
Jun 17, 2023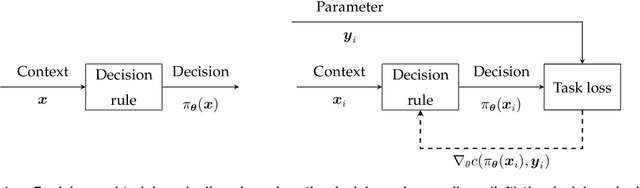



Recently there has been a surge of interest in operations research (OR) and the machine learning (ML) community in combining prediction algorithms and optimization techniques to solve decision-making problems in the face of uncertainty. This gave rise to the field of contextual optimization, under which data-driven procedures are developed to prescribe actions to the decision-maker that make the best use of the most recently updated information. A large variety of models and methods have been presented in both OR and ML literature under a variety of names, including data-driven optimization, prescriptive optimization, predictive stochastic programming, policy optimization, (smart) predict/estimate-then-optimize, decision-focused learning, (task-based) end-to-end learning/forecasting/optimization, etc. Focusing on single and two-stage stochastic programming problems, this review article identifies three main frameworks for learning policies from data and discusses their strengths and limitations. We present the existing models and methods under a uniform notation and terminology and classify them according to the three main frameworks identified. Our objective with this survey is to both strengthen the general understanding of this active field of research and stimulate further theoretical and algorithmic advancements in integrating ML and stochastic programming.