 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning A Simulation-based Visual Policy for Real-world Peg In Unseen Holes
May 09, 2022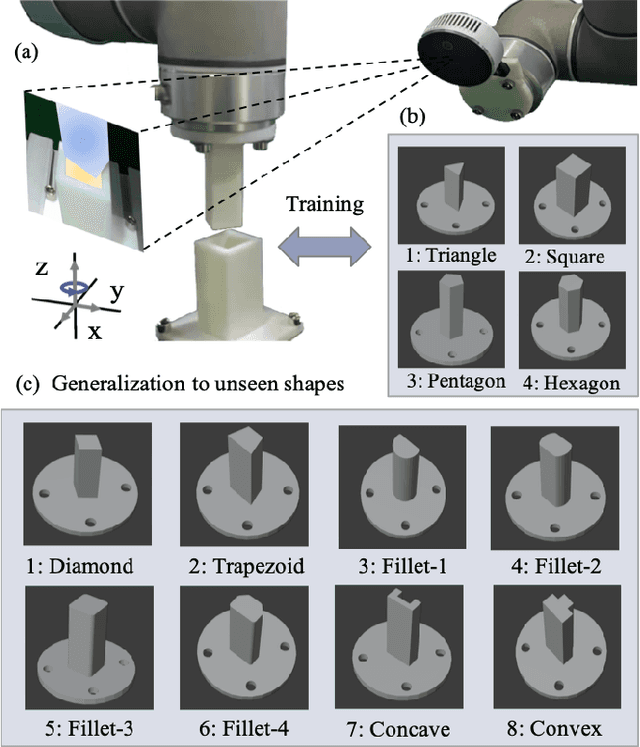

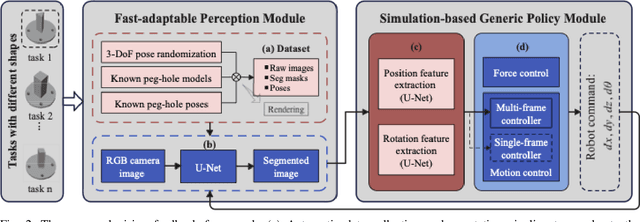
This paper proposes a learning-based visual peg-in-hole that enables training with several shapes in simulation, and adapting to arbitrary unseen shapes in real world with minimal sim-to-real cost. The core idea is to decouple the generalization of the sensory-motor policy to the design of a fast-adaptable perception module and a simulated generic policy module. The framework consists of a segmentation network (SN), a virtual sensor network (VSN), and a controller network (CN). Concretely, the VSN is trained to measure the pose of the unseen shape from a segmented image. After that, given the shape-agnostic pose measurement, the CN is trained to achieve generic peg-in-hole. Finally, when applying to real unseen holes, we only have to fine-tune the SN required by the simulated VSN+CN. To further minimize the transfer cost, we propose to automatically collect and annotate the data for the SN after one-minute human teaching. Simulated and real-world results are presented under the configurations of eye-to/in-hand. An electric vehicle charging system with the proposed policy inside achieves a 10/10 success rate in 2-3s, using only hundreds of auto-labeled samples for the SN transfer.
Map-based Visual-Inertial Localization: Consistency and Complexity
Apr 26, 2022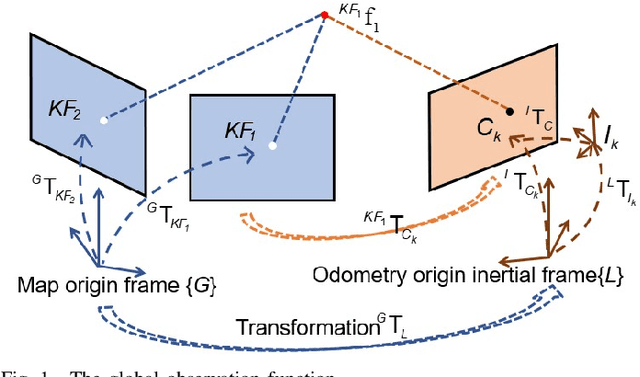
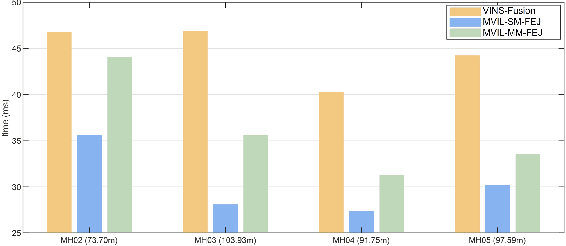
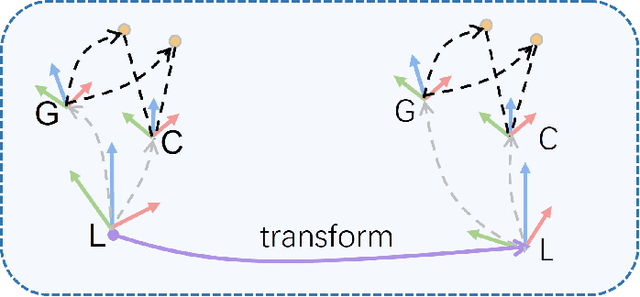
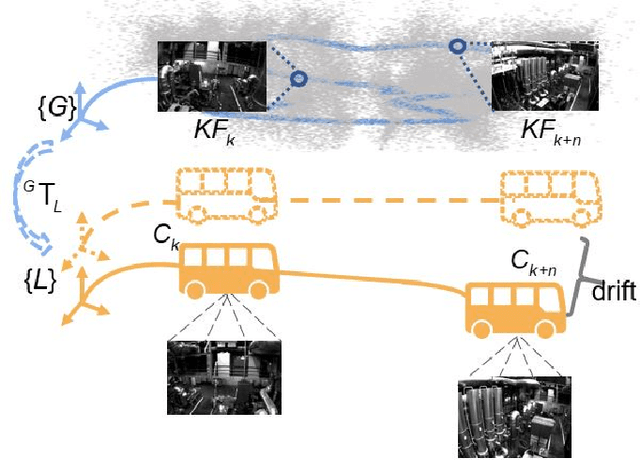
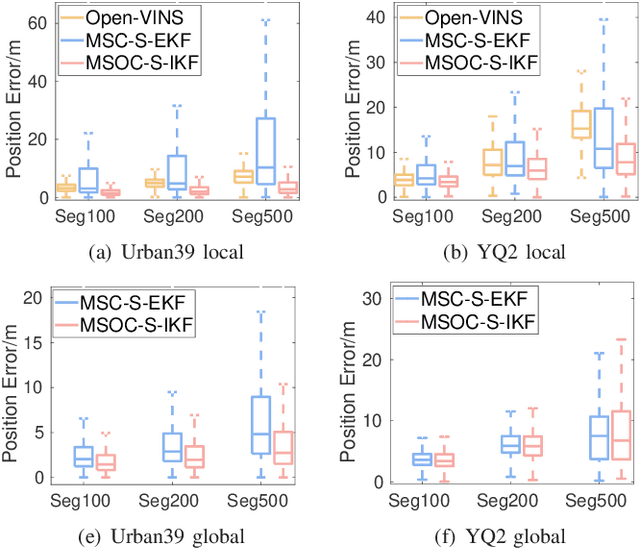
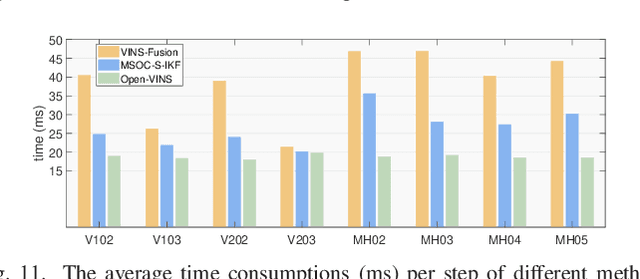
Drift-free localization is essential for autonomous vehicles. In this paper, we address the problem by proposing a filter-based framework, which integrates the visual-inertial odometry and the measurements of the features in the pre-built map. In this framework, the transformation between the odometry frame and the map frame is augmented into the state and estimated on the fly. Besides, we maintain only the keyframe poses in the map and employ Schmidt extended Kalman filter to update the state partially, so that the uncertainty of the map information can be consistently considered with low computational cost. Moreover, we theoretically demonstrate that the ever-changing linearization points of the estimated state can introduce spurious information to the augmented system and make the original four-dimensional unobservable subspace vanish, leading to inconsistent estimation in practice. To relieve this problem, we employ first-estimate Jacobian (FEJ) to maintain the correct observability properties of the augmented system. Furthermore, we introduce an observability-constrained updating method to compensate for the significant accumulated error after the long-term absence (can be 3 minutes and 1 km) of map-based measurements. Through simulations, the consistent estimation of our proposed algorithm is validated. Through real-world experiments, we demonstrate that our proposed algorithm runs successfully on four kinds of datasets with the lower computational cost (20% time-saving) and the better estimation accuracy (45% trajectory error reduction) compared with the baseline algorithm VINS-Fusion, whereas VINS-Fusion fails to give bounded localization performance on three of four datasets because of its inconsistent estimation.
Toward Consistent and Efficient Map-based Visual-inertial Localization: Theory Framework and Filter Design
Apr 26, 2022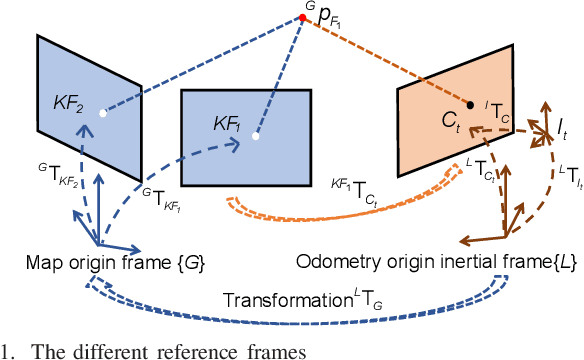
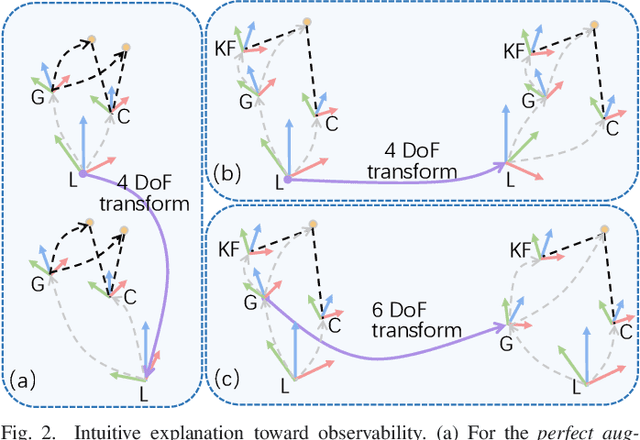
This paper focuses on designing a consistent and efficient filter for map-based visual-inertial localization. First, we propose a new Lie group with its algebra, based on which a novel invariant extended Kalman filter (invariant EKF) is designed. We theoretically prove that, when we do not consider the uncertainty of the map information, the proposed invariant EKF can naturally maintain the correct observability properties of the system. To consider the uncertainty of the map information, we introduce a Schmidt filter. With the Schmidt filter, the uncertainty of the map information can be taken into consideration to avoid over-confident estimation while the computation cost only increases linearly with the size of the map keyframes. In addition, we introduce an easily implemented observability-constrained technique because directly combining the invariant EKF with the Schmidt filter cannot maintain the correct observability properties of the system that considers the uncertainty of the map information. Finally, we validate our proposed system's high consistency, accuracy, and efficiency via extensive simulations and real-world experiments.
Learning to Fill the Seam by Vision: Sub-millimeter Peg-in-hole on Unseen Shapes in Real World
Apr 20, 2022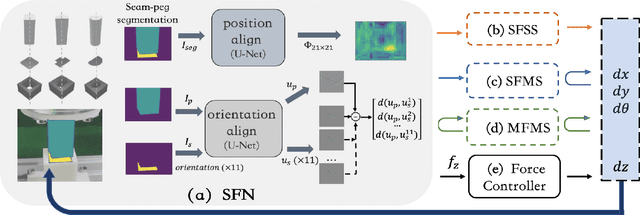
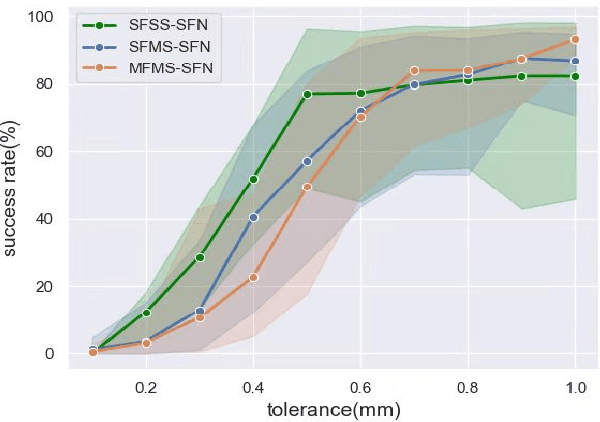
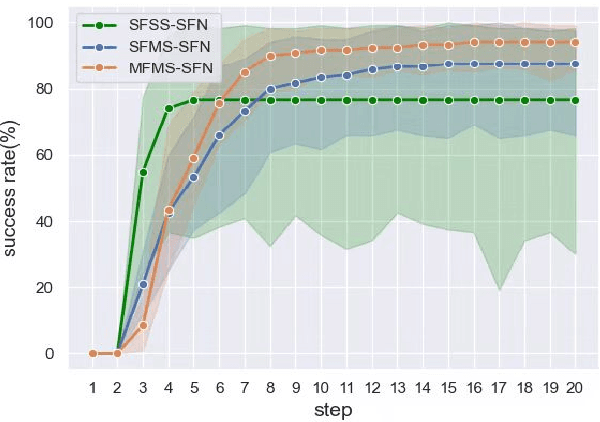

In the peg insertion task, human pays attention to the seam between the peg and the hole and tries to fill it continuously with visual feedback. By imitating the human behavior, we design architectures with position and orientation estimators based on the seam representation for pose alignment, which proves to be general to the unseen peg geometries. By putting the estimators into the closed-loop control with reinforcement learning, we further achieve a higher or comparable success rate, efficiency, and robustness compared with the baseline methods. The policy is trained totally in simulation without any manual intervention. To achieve sim-to-real, a learnable segmentation module with automatic data collecting and labeling can be easily trained to decouple the perception and the policy, which helps the model trained in simulation quickly adapt to the real world with negligible effort. Results are presented in simulation and on a physical robot. Code, videos, and supplemental material are available at https://github.com/xieliang555/SFN.git
One RING to Rule Them All: Radon Sinogram for Place Recognition, Orientation and Translation Estimation
Apr 17, 2022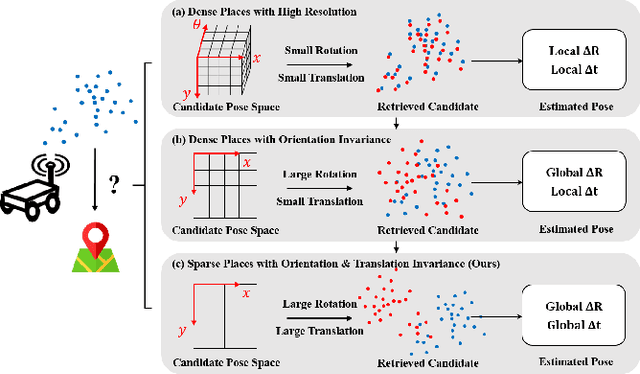
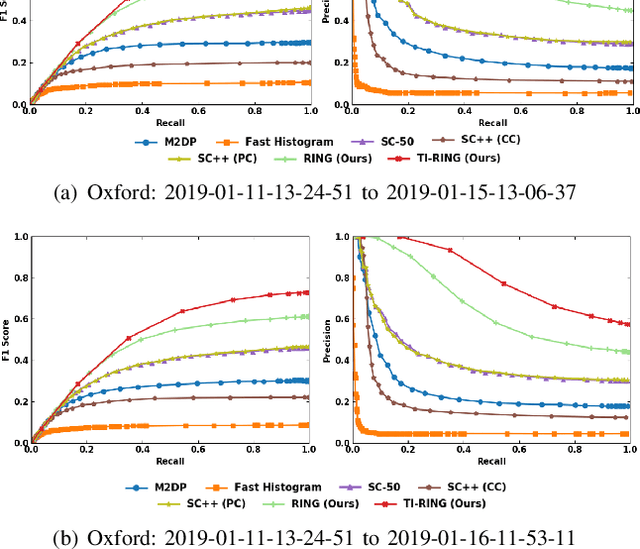
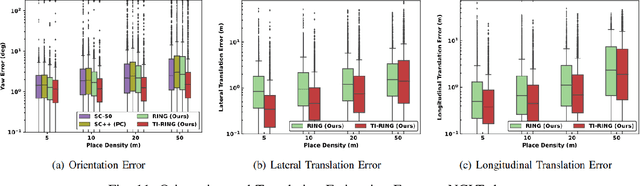
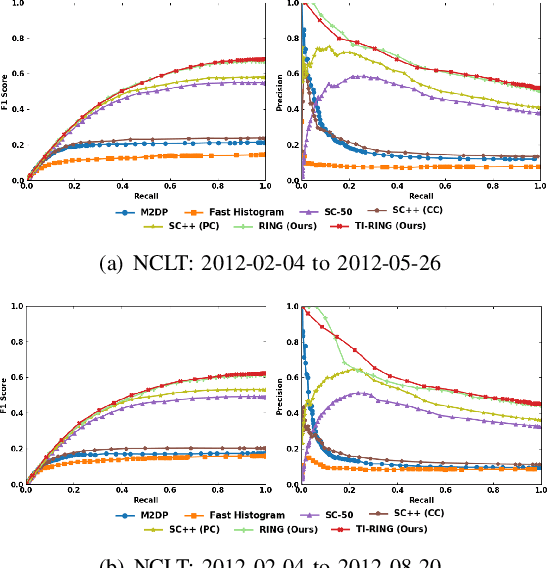
LiDAR-based global localization is a fundamental problem for mobile robots. It consists of two stages, place recognition and pose estimation, and yields the current orientation and translation, using only the current scan as query and a database of map scans. Inspired by the definition of a recognized place, we consider that a good global localization solution should keep the pose estimation accuracy with a lower place density. Following this idea, we propose a novel framework towards sparse place-based global localization, which utilizes a unified and learning-free representation, Radon sinogram (RING), for all sub-tasks. Based on the theoretical derivation, a translation invariant descriptor and an orientation invariant metric are proposed for place recognition, achieving certifiable robustness against arbitrary orientation and large translation between query and map scan. In addition, we also utilize the property of RING to propose a global convergent solver for both orientation and translation estimation, arriving at global localization. Evaluation of the proposed RING based framework validates the feasibility and demonstrates a superior performance even under a lower place density.
A Visual Navigation Perspective for Category-Level Object Pose Estimation
Mar 25, 2022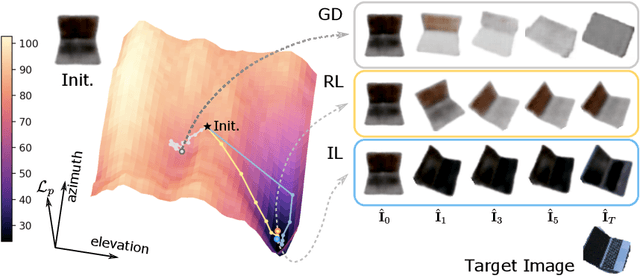
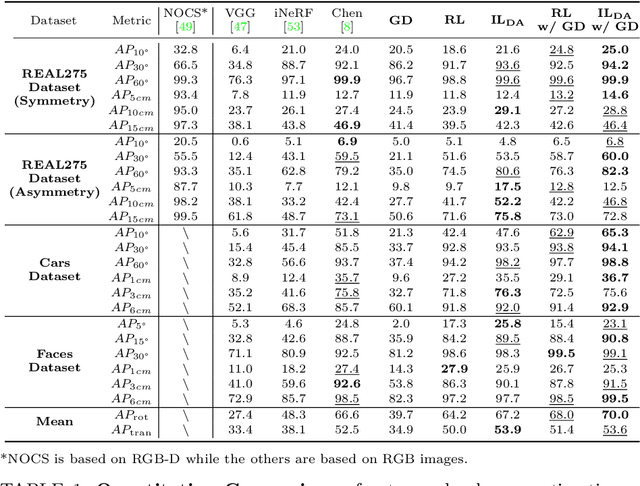
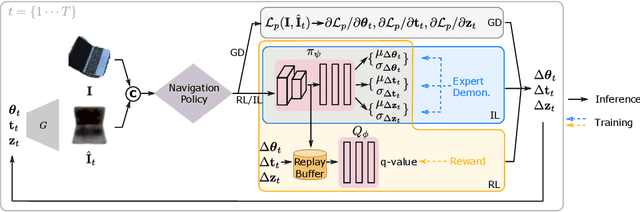
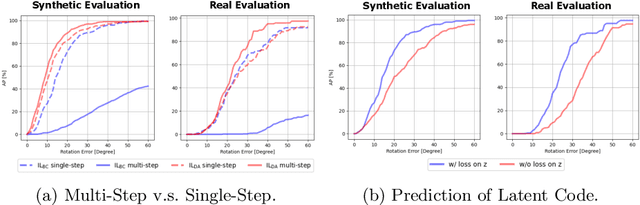
This paper studies category-level object pose estimation based on a single monocular image. Recent advances in pose-aware generative models have paved the way for addressing this challenging task using analysis-by-synthesis. The idea is to sequentially update a set of latent variables, e.g., pose, shape, and appearance, of the generative model until the generated image best agrees with the observation. However, convergence and efficiency are two challenges of this inference procedure. In this paper, we take a deeper look at the inference of analysis-by-synthesis from the perspective of visual navigation, and investigate what is a good navigation policy for this specific task. We evaluate three different strategies, including gradient descent, reinforcement learning and imitation learning, via thorough comparisons in terms of convergence, robustness and efficiency. Moreover, we show that a simple hybrid approach leads to an effective and efficient solution. We further compare these strategies to state-of-the-art methods, and demonstrate superior performance on synthetic and real-world datasets leveraging off-the-shelf pose-aware generative models.
DXQ-Net: Differentiable LiDAR-Camera Extrinsic Calibration Using Quality-aware Flow
Mar 17, 2022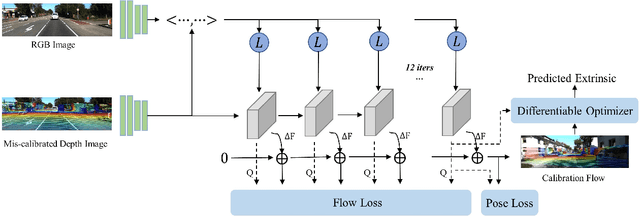

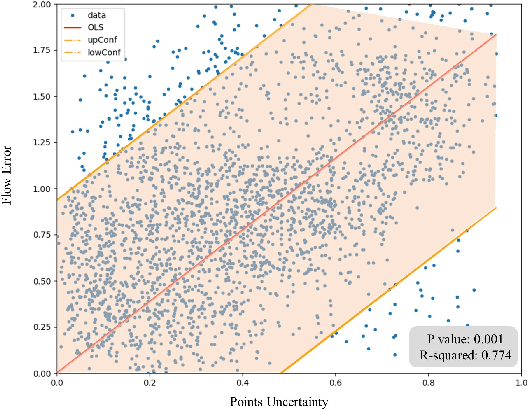

Accurate LiDAR-camera extrinsic calibration is a precondition for many multi-sensor systems in mobile robots. Most calibration methods rely on laborious manual operations and calibration targets. While working online, the calibration methods should be able to extract information from the environment to construct the cross-modal data association. Convolutional neural networks (CNNs) have powerful feature extraction ability and have been used for calibration. However, most of the past methods solve the extrinsic as a regression task, without considering the geometric constraints involved. In this paper, we propose a novel end-to-end extrinsic calibration method named DXQ-Net, using a differentiable pose estimation module for generalization. We formulate a probabilistic model for LiDAR-camera calibration flow, yielding a prediction of uncertainty to measure the quality of LiDAR-camera data association. Testing experiments illustrate that our method achieves a competitive with other methods for the translation component and state-of-the-art performance for the rotation component. Generalization experiments illustrate that the generalization performance of our method is significantly better than other deep learning-based methods.
Least Square Estimation Network for Depth Completion
Mar 07, 2022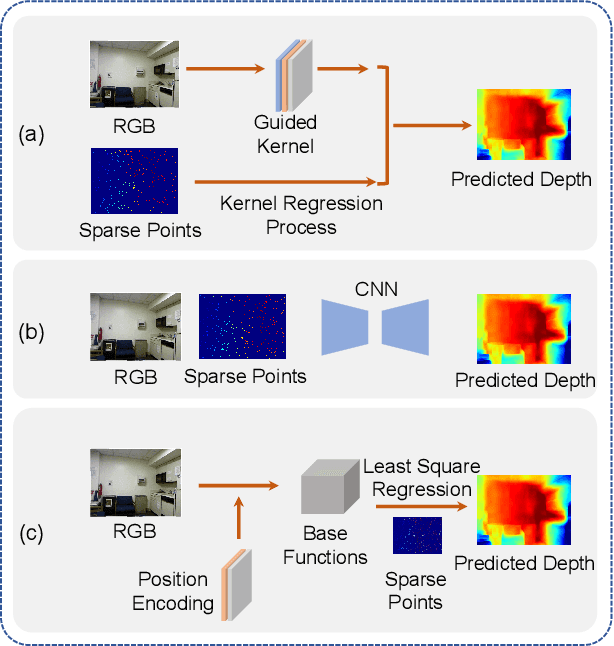
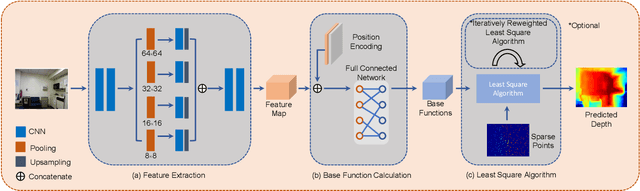
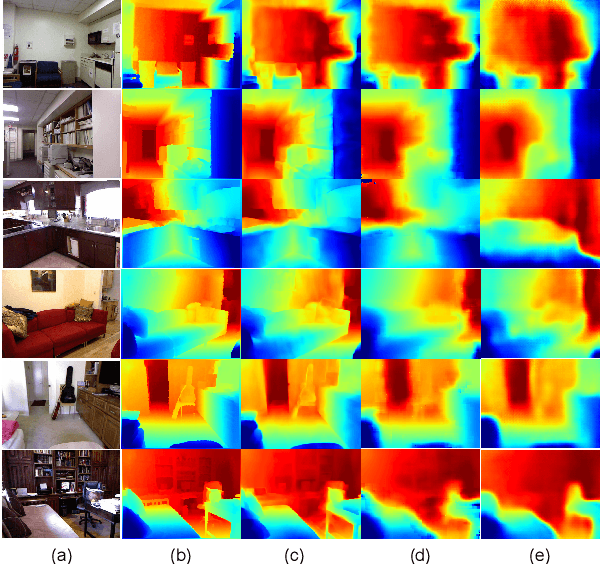
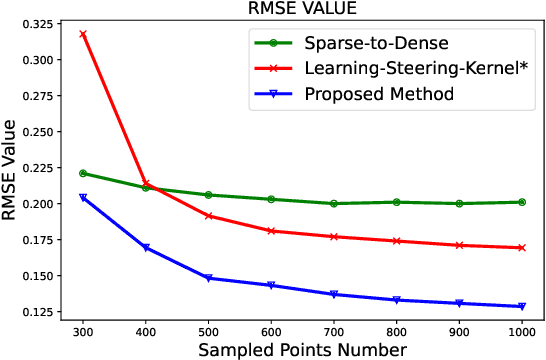
Depth completion is a fundamental task in computer vision and robotics research. Many previous works complete the dense depth map with neural networks directly but most of them are non-interpretable and can not generalize to different situations well. In this paper, we propose an effective image representation method for depth completion tasks. The input of our system is a monocular camera frame and the synchronous sparse depth map. The output of our system is a dense per-pixel depth map of the frame. First we use a neural network to transform each pixel into a feature vector, which we call base functions. Then we pick out the known pixels' base functions and their depth values. We use a linear least square algorithm to fit the base functions and the depth values. Then we get the weights estimated from the least square algorithm. Finally, we apply the weights to the whole image and predict the final depth map. Our method is interpretable so it can generalize well. Experiments show that our results beat the state-of-the-art on NYU-Depth-V2 dataset both in accuracy and runtime. Moreover, experiments show that our method can generalize well on different numbers of sparse points and different datasets.
Translation Invariant Global Estimation of Heading Angle Using Sinogram of LiDAR Point Cloud
Mar 02, 2022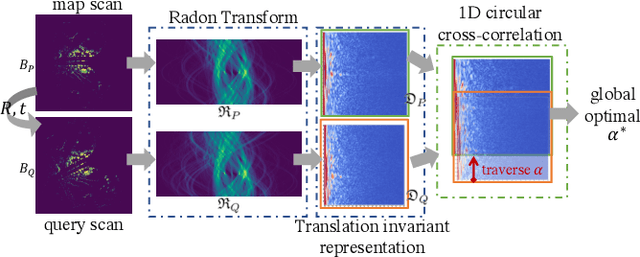
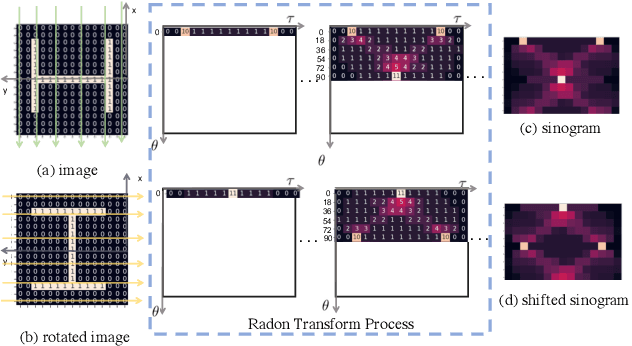
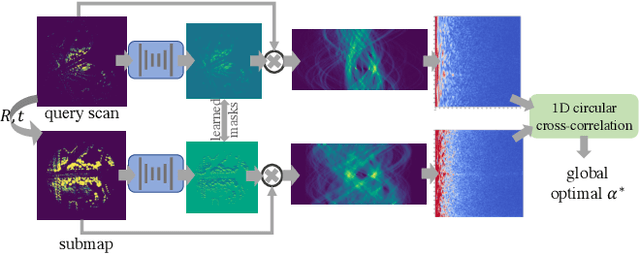
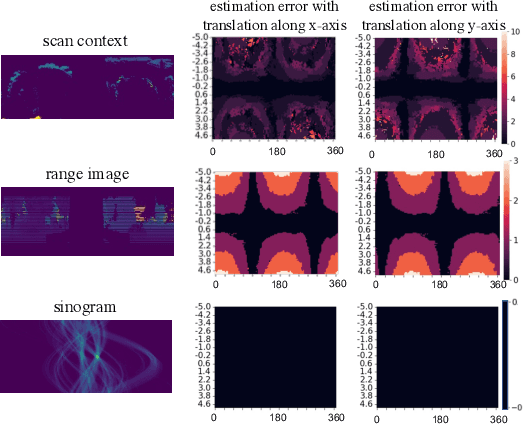
Global point cloud registration is an essential module for localization, of which the main difficulty exists in estimating the rotation globally without initial value. With the aid of gravity alignment, the degree of freedom in point cloud registration could be reduced to 4DoF, in which only the heading angle is required for rotation estimation. In this paper, we propose a fast and accurate global heading angle estimation method for gravity-aligned point clouds. Our key idea is that we generate a translation invariant representation based on Radon Transform, allowing us to solve the decoupled heading angle globally with circular cross-correlation. Besides, for heading angle estimation between point clouds with different distributions, we implement this heading angle estimator as a differentiable module to train a feature extraction network end- to-end. The experimental results validate the effectiveness of the proposed method in heading angle estimation and show better performance compared with other methods.
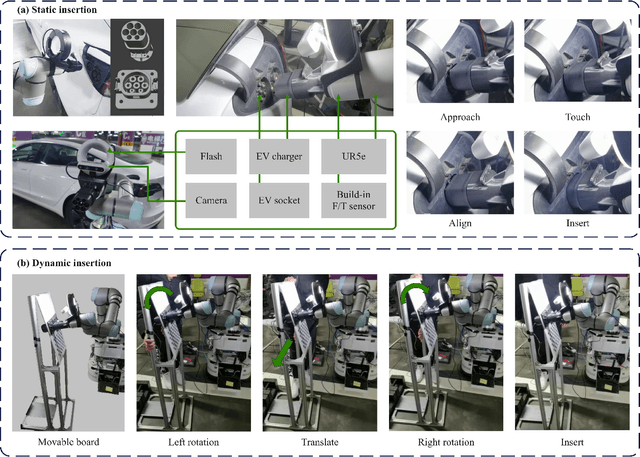
Electric Vehicle Automatic Charging System Based on Vision-force Fusion
Oct 18, 2021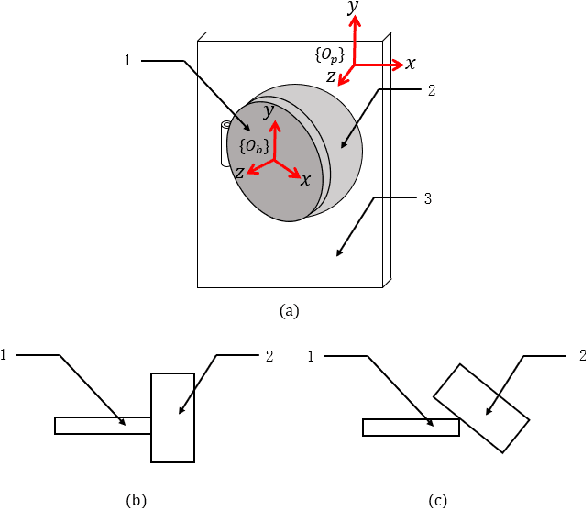
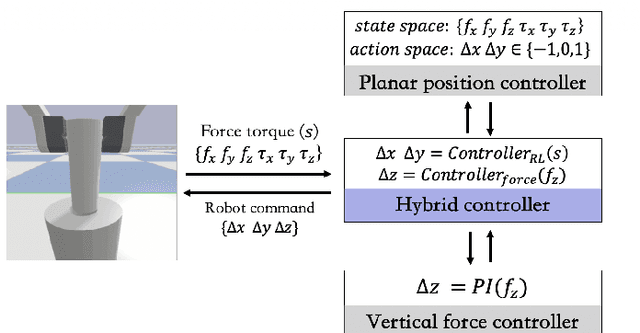
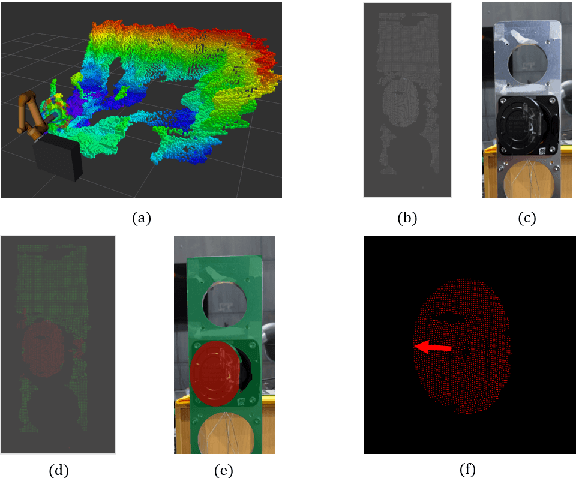

Electric vehicles are an emerging means of transportation with environmental friendliness. The automatic charging is a hot topic in this field that is full of challenges. We introduce a complete automatic charging system based on vision-force fusion, which includes perception, planning and control for robot manipulations of the system. We design the whole system in simulation and transfer it to the real world. The experimental results prove the effectiveness of our system.