 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Speak Fluently in a Foreign Language: Multilingual Speech Synthesis and Cross-Language Voice Cloning
Jul 24, 2019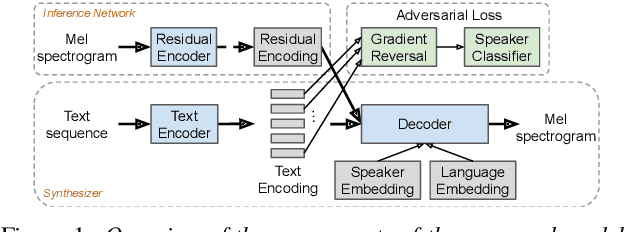
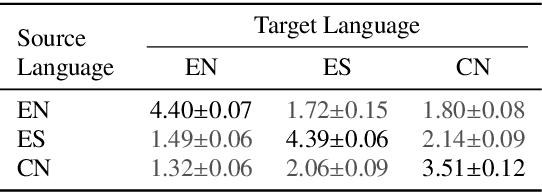
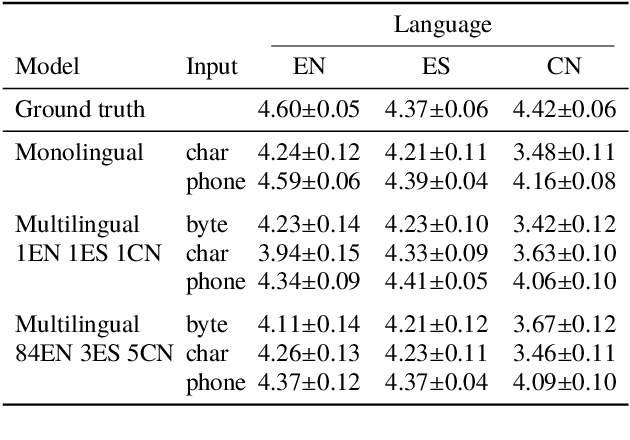
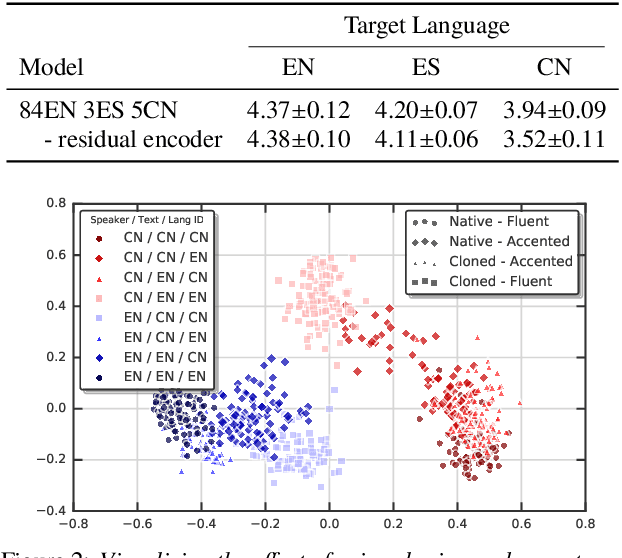
We present a multispeaker, multilingual text-to-speech (TTS) synthesis model based on Tacotron that is able to produce high quality speech in multiple languages. Moreover, the model is able to transfer voices across languages, e.g. synthesize fluent Spanish speech using an English speaker's voice, without training on any bilingual or parallel examples. Such transfer works across distantly related languages, e.g. English and Mandarin. Critical to achieving this result are: 1. using a phonemic input representation to encourage sharing of model capacity across languages, and 2. incorporating an adversarial loss term to encourage the model to disentangle its representation of speaker identity (which is perfectly correlated with language in the training data) from the speech content. Further scaling up the model by training on multiple speakers of each language, and incorporating an autoencoding input to help stabilize attention during training, results in a model which can be used to consistently synthesize intelligible speech for training speakers in all languages seen during training, and in native or foreign accents.
Direct speech-to-speech translation with a sequence-to-sequence model
Apr 12, 2019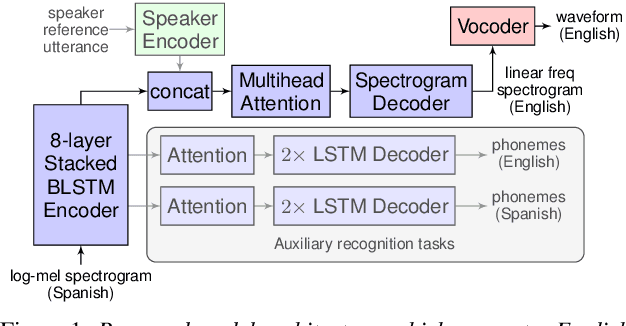
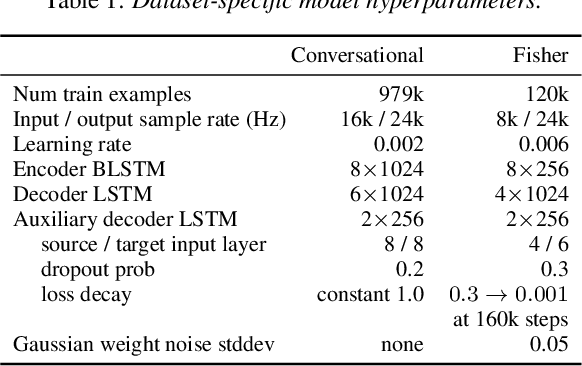
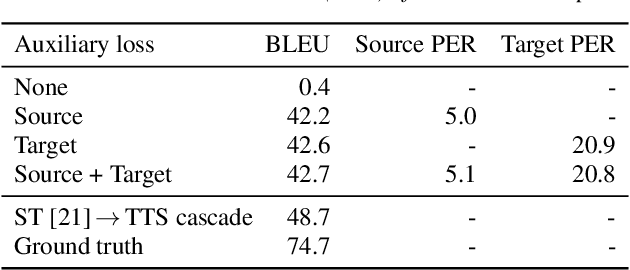
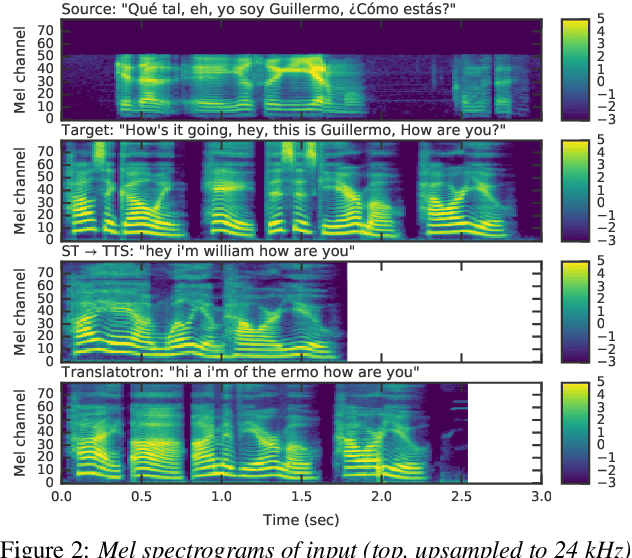
We present an attention-based sequence-to-sequence neural network which can directly translate speech from one language into speech in another language, without relying on an intermediate text representation. The network is trained end-to-end, learning to map speech spectrograms into target spectrograms in another language, corresponding to the translated content (in a different canonical voice). We further demonstrate the ability to synthesize translated speech using the voice of the source speaker. We conduct experiments on two Spanish-to-English speech translation datasets, and find that the proposed model slightly underperforms a baseline cascade of a direct speech-to-text translation model and a text-to-speech synthesis model, demonstrating the feasibility of the approach on this very challenging task.
Lingvo: a Modular and Scalable Framework for Sequence-to-Sequence Modeling
Feb 21, 2019


Lingvo is a Tensorflow framework offering a complete solution for collaborative deep learning research, with a particular focus towards sequence-to-sequence models. Lingvo models are composed of modular building blocks that are flexible and easily extensible, and experiment configurations are centralized and highly customizable. Distributed training and quantized inference are supported directly within the framework, and it contains existing implementations of a large number of utilities, helper functions, and the newest research ideas. Lingvo has been used in collaboration by dozens of researchers in more than 20 papers over the last two years. This document outlines the underlying design of Lingvo and serves as an introduction to the various pieces of the framework, while also offering examples of advanced features that showcase the capabilities of the framework.
A spelling correction model for end-to-end speech recognition
Feb 19, 2019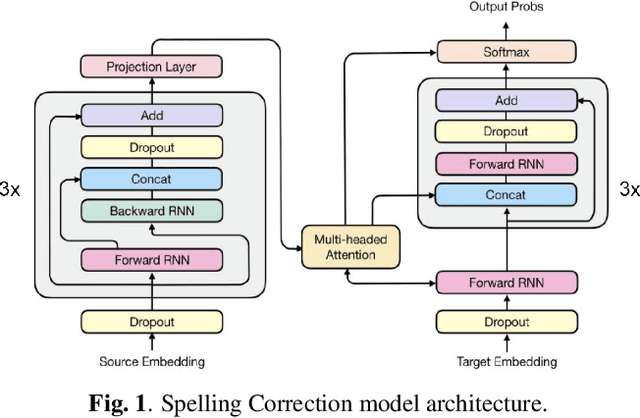
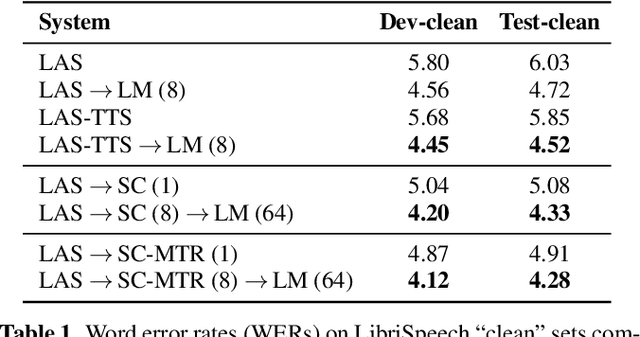
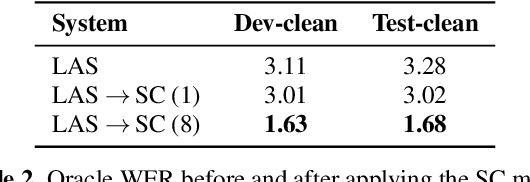
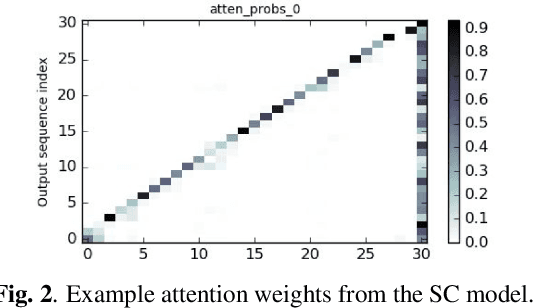
Attention-based sequence-to-sequence models for speech recognition jointly train an acoustic model, language model (LM), and alignment mechanism using a single neural network and require only parallel audio-text pairs. Thus, the language model component of the end-to-end model is only trained on transcribed audio-text pairs, which leads to performance degradation especially on rare words. While there have been a variety of work that look at incorporating an external LM trained on text-only data into the end-to-end framework, none of them have taken into account the characteristic error distribution made by the model. In this paper, we propose a novel approach to utilizing text-only data, by training a spelling correction (SC) model to explicitly correct those errors. On the LibriSpeech dataset, we demonstrate that the proposed model results in an 18.6% relative improvement in WER over the baseline model when directly correcting top ASR hypothesis, and a 29.0% relative improvement when further rescoring an expanded n-best list using an external LM.
Unsupervised speech representation learning using WaveNet autoencoders
Jan 25, 2019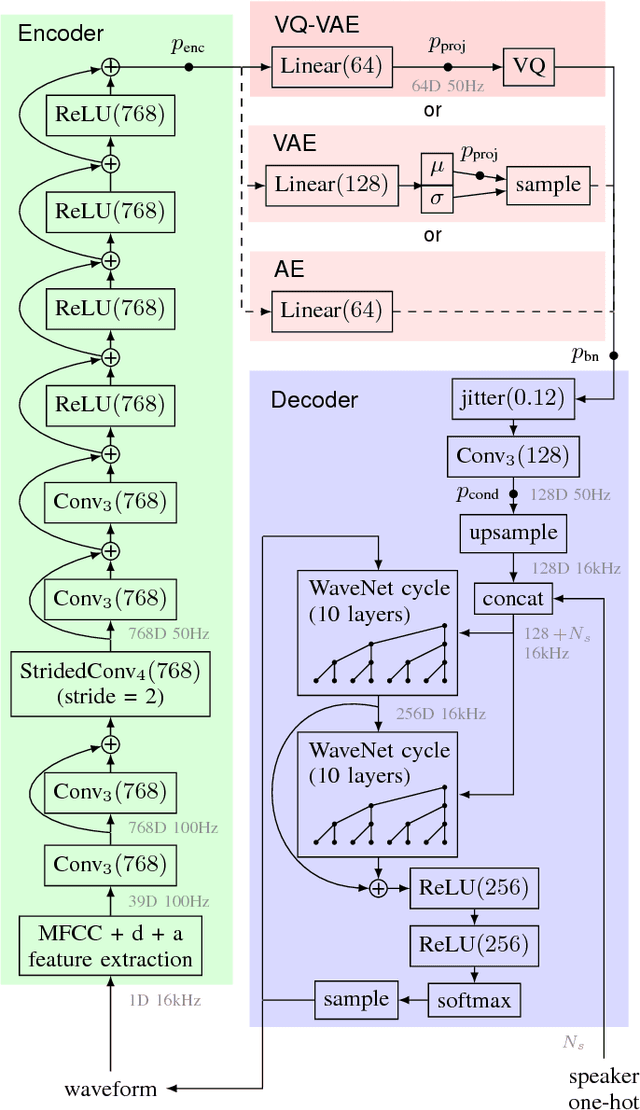
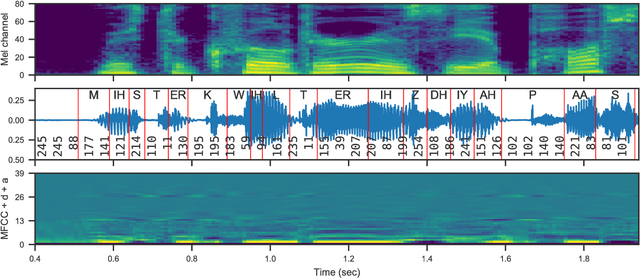
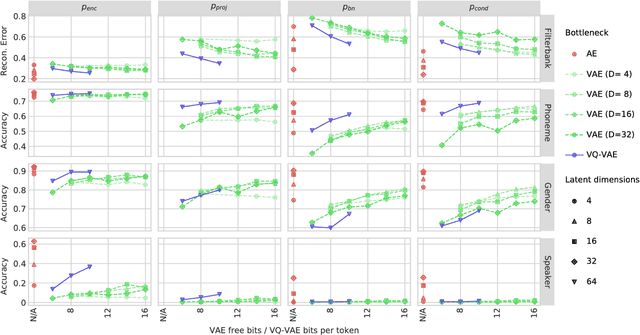
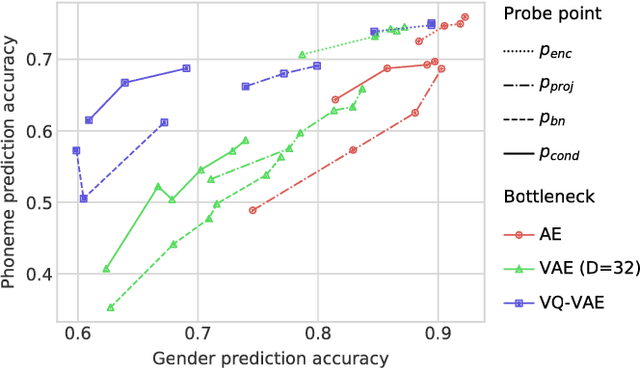
We consider the task of unsupervised extraction of meaningful latent representations of speech by applying autoencoding neural networks to speech waveforms. The goal is to learn a representation able to capture high level semantic content from the signal, e.g. phoneme identities, while being invariant to confounding low level details in the signal such as the underlying pitch contour or background noise. The behavior of autoencoder models depends on the kind of constraint that is applied to the latent representation. We compare three variants: a simple dimensionality reduction bottleneck, a Gaussian Variational Autoencoder (VAE), and a discrete Vector Quantized VAE (VQ-VAE). We analyze the quality of learned representations in terms of speaker independence, the ability to predict phonetic content, and the ability to accurately reconstruct individual spectrogram frames. Moreover, for discrete encodings extracted using the VQ-VAE, we measure the ease of mapping them to phonemes. We introduce a regularization scheme that forces the representations to focus on the phonetic content of the utterance and report performance comparable with the top entries in the ZeroSpeech 2017 unsupervised acoustic unit discovery task.
Leveraging Weakly Supervised Data to Improve End-to-End Speech-to-Text Translation
Nov 05, 2018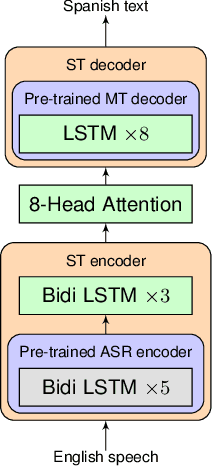

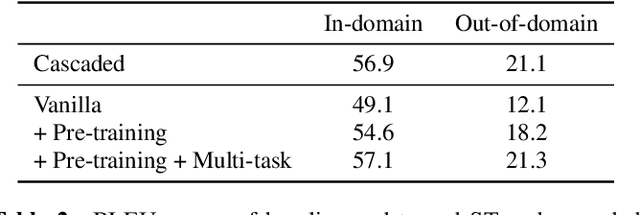
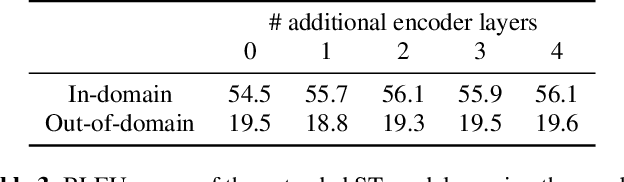
End-to-end Speech Translation (ST) models have many potential advantages when compared to the cascade of Automatic Speech Recognition (ASR) and text Machine Translation (MT) models, including lowered inference latency and the avoidance of error compounding. However, the quality of end-to-end ST is often limited by a paucity of training data, since it is difficult to collect large parallel corpora of speech and translated transcript pairs. Previous studies have proposed the use of pre-trained components and multi-task learning in order to benefit from weakly supervised training data, such as speech-to-transcript or text-to-foreign-text pairs. In this paper, we demonstrate that using pre-trained MT or text-to-speech (TTS) synthesis models to convert weakly supervised data into speech-to-translation pairs for ST training can be more effective than multi-task learning. Furthermore, we demonstrate that a high quality end-to-end ST model can be trained using only weakly supervised datasets, and that synthetic data sourced from unlabeled monolingual text or speech can be used to improve performance. Finally, we discuss methods for avoiding overfitting to synthetic speech with a quantitative ablation study.
Transfer Learning from Speaker Verification to Multispeaker Text-To-Speech Synthesis
Nov 05, 2018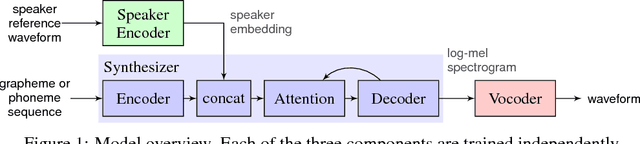

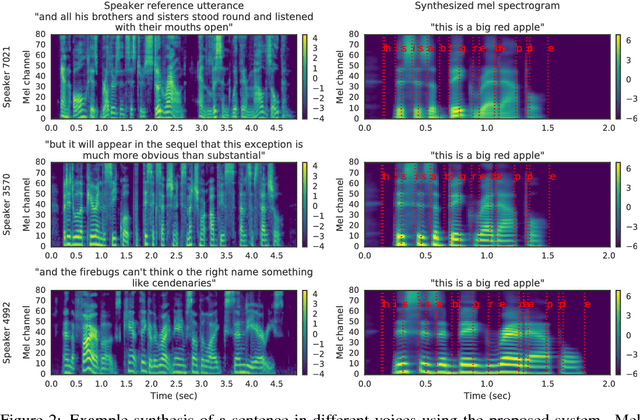
We describe a neural network-based system for text-to-speech (TTS) synthesis that is able to generate speech audio in the voice of many different speakers, including those unseen during training. Our system consists of three independently trained components: (1) a speaker encoder network, trained on a speaker verification task using an independent dataset of noisy speech from thousands of speakers without transcripts, to generate a fixed-dimensional embedding vector from seconds of reference speech from a target speaker; (2) a sequence-to-sequence synthesis network based on Tacotron 2, which generates a mel spectrogram from text, conditioned on the speaker embedding; (3) an auto-regressive WaveNet-based vocoder that converts the mel spectrogram into a sequence of time domain waveform samples. We demonstrate that the proposed model is able to transfer the knowledge of speaker variability learned by the discriminatively-trained speaker encoder to the new task, and is able to synthesize natural speech from speakers that were not seen during training. We quantify the importance of training the speaker encoder on a large and diverse speaker set in order to obtain the best generalization performance. Finally, we show that randomly sampled speaker embeddings can be used to synthesize speech in the voice of novel speakers dissimilar from those used in training, indicating that the model has learned a high quality speaker representation.
VoiceFilter: Targeted Voice Separation by Speaker-Conditioned Spectrogram Masking
Oct 27, 2018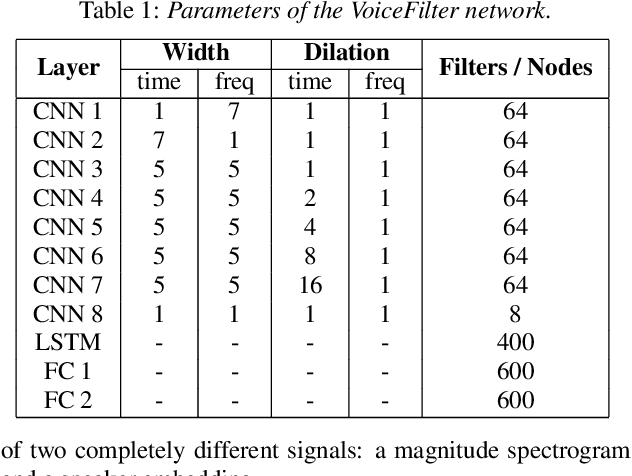
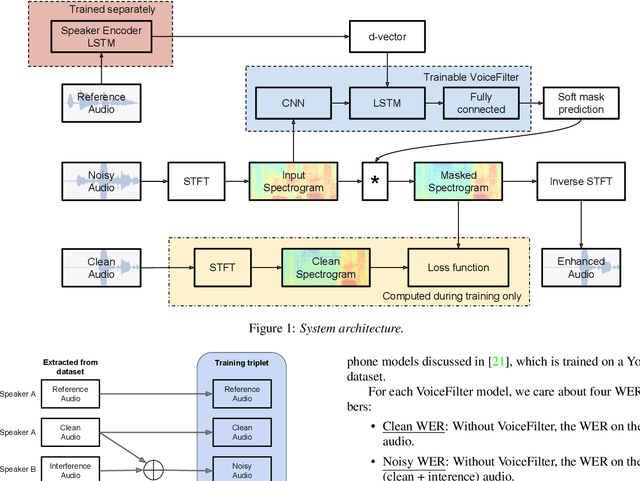
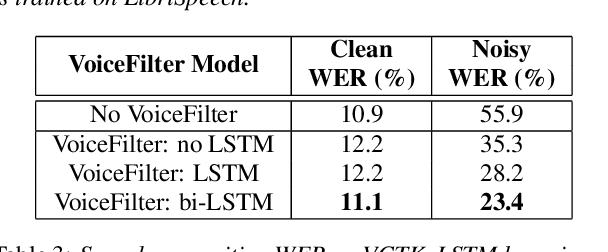
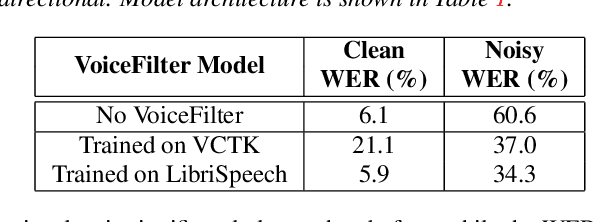
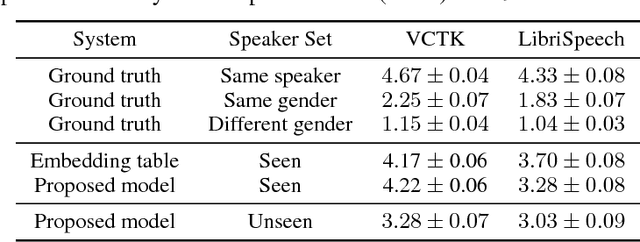
In this paper, we present a novel system that separates the voice of a target speaker from multi-speaker signals, by making use of a reference signal from the target speaker. We achieve this by training two separate neural networks: (1) A speaker recognition network that produces speaker-discriminative embeddings; (2) A spectrogram masking network that takes both noisy spectrogram and speaker embedding as input, and produces a mask. Our system significantly reduces the speech recognition WER on multi-speaker signals, with minimal WER degradation on single-speaker signals.
Hierarchical Generative Modeling for Controllable Speech Synthesis
Oct 16, 2018
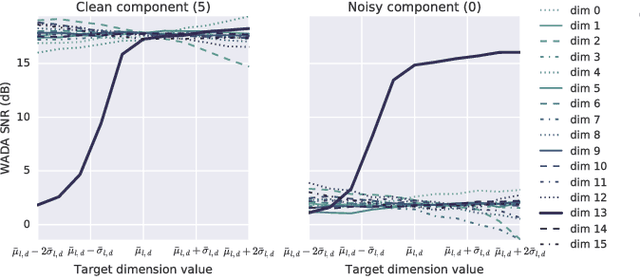
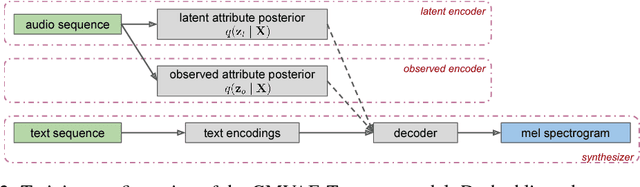

This paper proposes a neural end-to-end text-to-speech (TTS) model which can control latent attributes in the generated speech that are rarely annotated in the training data, such as speaking style, accent, background noise, and recording conditions. The model is formulated as a conditional generative model with two levels of hierarchical latent variables. The first level is a categorical variable, which represents attribute groups (e.g. clean/noisy) and provides interpretability. The second level, conditioned on the first, is a multivariate Gaussian variable, which characterizes specific attribute configurations (e.g. noise level, speaking rate) and enables disentangled fine-grained control over these attributes. This amounts to using a Gaussian mixture model (GMM) for the latent distribution. Extensive evaluation demonstrates its ability to control the aforementioned attributes. In particular, it is capable of consistently synthesizing high-quality clean speech regardless of the quality of the training data for the target speaker.
Towards End-to-End Prosody Transfer for Expressive Speech Synthesis with Tacotron
Mar 24, 2018
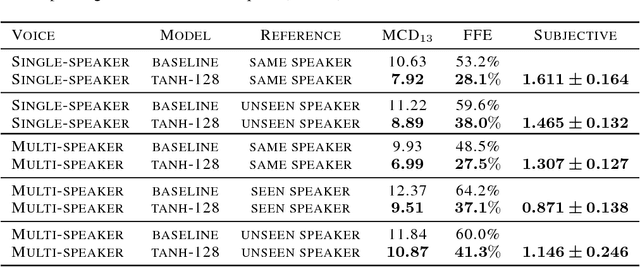

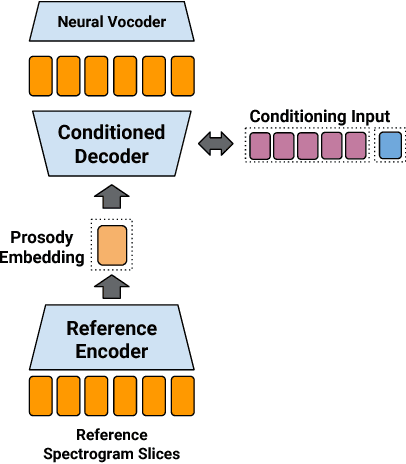
We present an extension to the Tacotron speech synthesis architecture that learns a latent embedding space of prosody, derived from a reference acoustic representation containing the desired prosody. We show that conditioning Tacotron on this learned embedding space results in synthesized audio that matches the prosody of the reference signal with fine time detail even when the reference and synthesis speakers are different. Additionally, we show that a reference prosody embedding can be used to synthesize text that is different from that of the reference utterance. We define several quantitative and subjective metrics for evaluating prosody transfer, and report results with accompanying audio samples from single-speaker and 44-speaker Tacotron models on a prosody transfer task.