 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Deep Visual Descriptors for Hierarchical Efficient Localization
Sep 18, 2018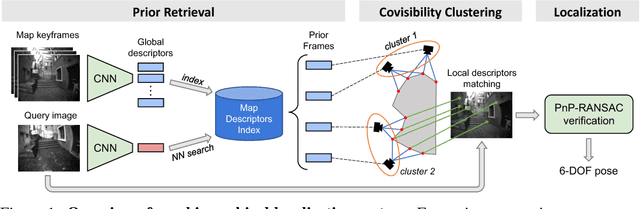

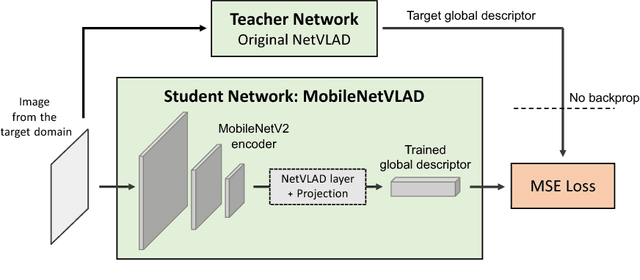

Many robotics applications require precise pose estimates despite operating in large and changing environments. This can be addressed by visual localization, using a pre-computed 3D model of the surroundings. The pose estimation then amounts to finding correspondences between 2D keypoints in a query image and 3D points in the model using local descriptors. However, computational power is often limited on robotic platforms, making this task challenging in large-scale environments. Binary feature descriptors significantly speed up this 2D-3D matching, and have become popular in the robotics community, but also strongly impair the robustness to perceptual aliasing and changes in viewpoint, illumination and scene structure. In this work, we propose to leverage recent advances in deep learning to perform an efficient hierarchical localization. We first localize at the map level using learned image-wide global descriptors, and subsequently estimate a precise pose from 2D-3D matches computed in the candidate places only. This restricts the local search and thus allows to efficiently exploit powerful non-binary descriptors usually dismissed on resource-constrained devices. Our approach results in state-of-the-art localization performance while running in real-time on a popular mobile platform, enabling new prospects for robotics research.
An informative path planning framework for UAV-based terrain monitoring
Sep 08, 2018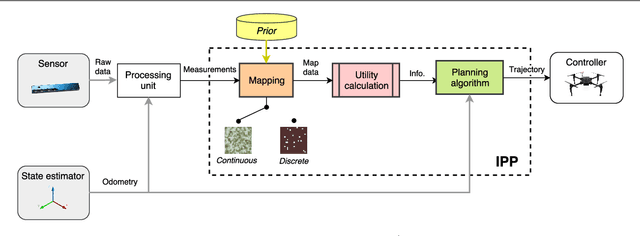
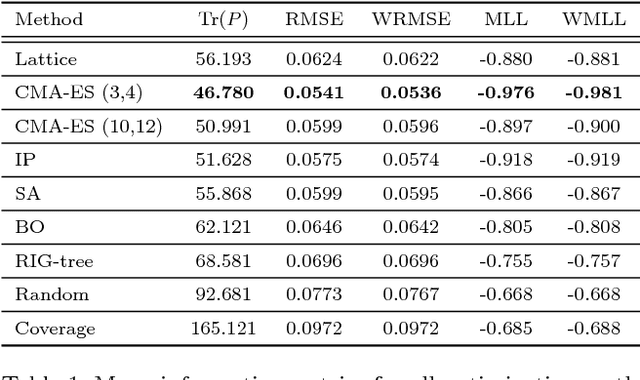
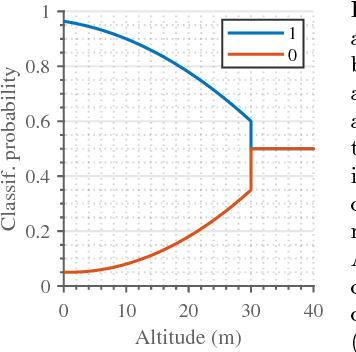
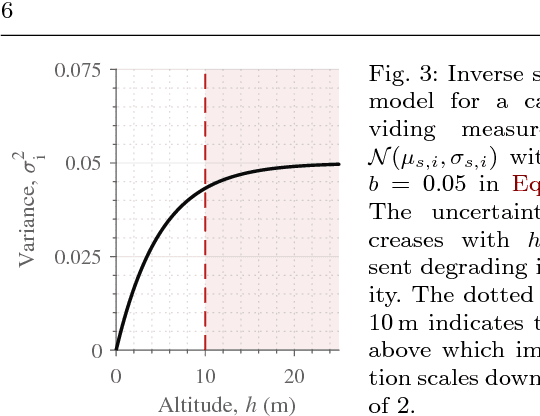
Unmanned aerial vehicles (UAVs) represent a new frontier in a wide range of monitoring and research applications. To fully leverage their potential, a key challenge is planning missions for efficient data acquisition in complex environments. To address this issue, this article introduces a general informative path planning (IPP) framework for monitoring scenarios using an aerial robot. The approach is capable of mapping either discrete or continuous target variables on a terrain using variable-resolution data received from probabilistic sensors. During a mission, the terrain maps built online are used to plan information-rich trajectories in continuous 3-D space by optimizing initial solutions obtained by a course grid search. Extensive simulations show that our approach is more efficient than existing methods. We also demonstrate its real-time application on a photorealistic mapping scenario using a publicly available dataset.
Build Your Own Visual-Inertial Drone: A Cost-Effective and Open-Source Autonomous Drone
Sep 06, 2018


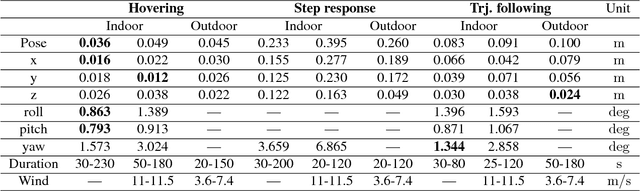
This paper describes an approach to building a cost-effective and research grade visual-inertial odometry aided vertical taking-off and landing (VTOL) platform. We utilize an off-the-shelf visual-inertial sensor, an onboard computer, and a quadrotor platform that are factory-calibrated and mass-produced, thereby sharing similar hardware and sensor specifications (e.g., mass, dimensions, intrinsic and extrinsic of camera-IMU systems, and signal-to-noise ratio). We then perform a system calibration and identification enabling the use of our visual-inertial odometry, multi-sensor fusion, and model predictive control frameworks with the off-the-shelf products. This implies that we can partially avoid tedious parameter tuning procedures for building a full system. The complete system is extensively evaluated both indoors using a motion capture system and outdoors using a laser tracker while performing hover and step responses, and trajectory following tasks in the presence of external wind disturbances. We achieve root-mean-square (RMS) pose errors between a reference and actual trajectories of 0.036m, while performing hover. We also conduct relatively long distance flight (~180m) experiments on a farm site and achieve 0.82% drift error of the total distance flight. This paper conveys the insights we acquired about the platform and sensor module and returns to the community as open-source code with tutorial documentation.
* 21 pages, 10 figures, accepted to IEEE Robotics & Automation Magazine
WeedMap: A large-scale semantic weed mapping framework using aerial multispectral imaging and deep neural network for precision farming
Sep 06, 2018
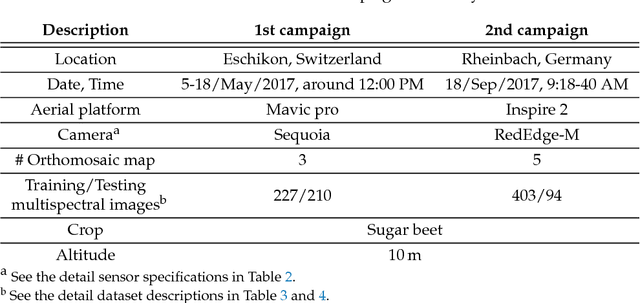
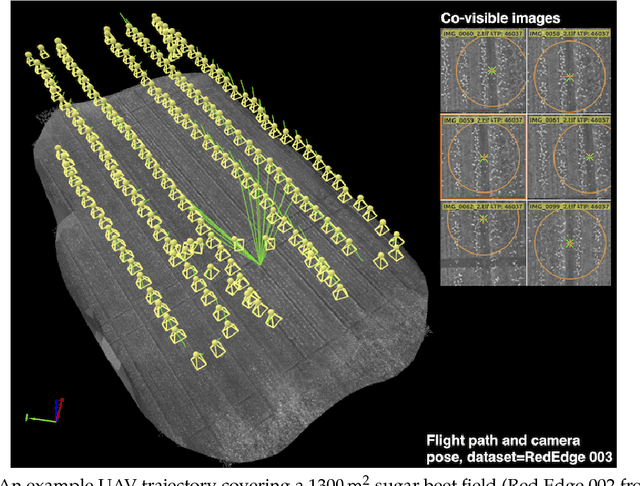
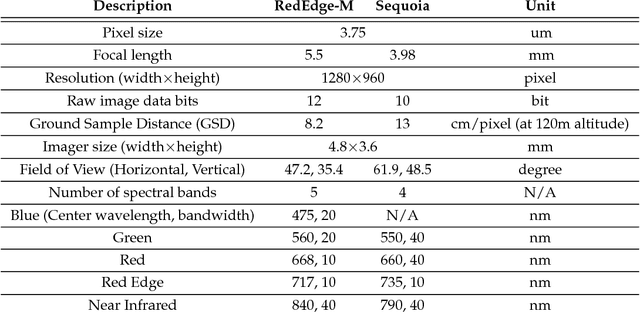
We present a novel weed segmentation and mapping framework that processes multispectral images obtained from an unmanned aerial vehicle (UAV) using a deep neural network (DNN). Most studies on crop/weed semantic segmentation only consider single images for processing and classification. Images taken by UAVs often cover only a few hundred square meters with either color only or color and near-infrared (NIR) channels. Computing a single large and accurate vegetation map (e.g., crop/weed) using a DNN is non-trivial due to difficulties arising from: (1) limited ground sample distances (GSDs) in high-altitude datasets, (2) sacrificed resolution resulting from downsampling high-fidelity images, and (3) multispectral image alignment. To address these issues, we adopt a stand sliding window approach that operates on only small portions of multispectral orthomosaic maps (tiles), which are channel-wise aligned and calibrated radiometrically across the entire map. We define the tile size to be the same as that of the DNN input to avoid resolution loss. Compared to our baseline model (i.e., SegNet with 3 channel RGB inputs) yielding an area under the curve (AUC) of [background=0.607, crop=0.681, weed=0.576], our proposed model with 9 input channels achieves [0.839, 0.863, 0.782]. Additionally, we provide an extensive analysis of 20 trained models, both qualitatively and quantitatively, in order to evaluate the effects of varying input channels and tunable network hyperparameters. Furthermore, we release a large sugar beet/weed aerial dataset with expertly guided annotations for further research in the fields of remote sensing, precision agriculture, and agricultural robotics.
Reinforced Imitation: Sample Efficient Deep Reinforcement Learning for Map-less Navigation by Leveraging Prior Demonstrations
Aug 31, 2018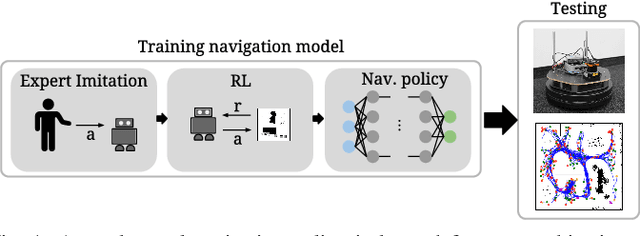
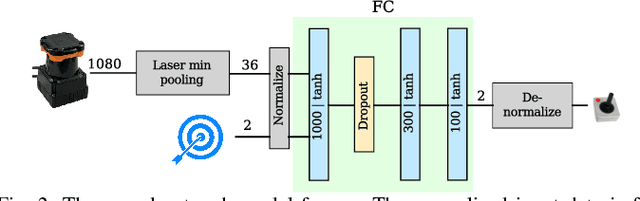
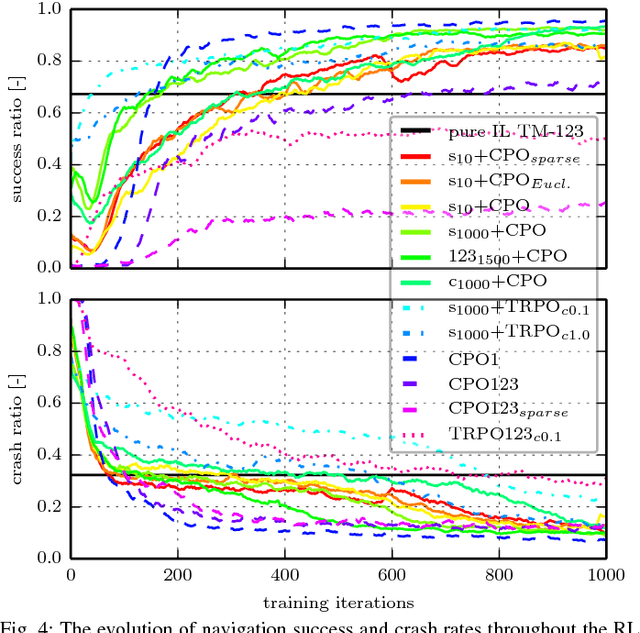
This work presents a case study of a learning-based approach for target driven map-less navigation. The underlying navigation model is an end-to-end neural network which is trained using a combination of expert demonstrations, imitation learning (IL) and reinforcement learning (RL). While RL and IL suffer from a large sample complexity and the distribution mismatch problem, respectively, we show that leveraging prior expert demonstrations for pre-training can reduce the training time to reach at least the same level of performance compared to plain RL by a factor of 5. We present a thorough evaluation of different combinations of expert demonstrations, different RL algorithms and reward functions, both in simulation and on a real robotic platform. Our results show that the final model outperforms both standalone approaches in the amount of successful navigation tasks. In addition, the RL reward function can be significantly simplified when using pre-training, e.g. by using a sparse reward only. The learned navigation policy is able to generalize to unseen and real-world environments.
Map Management for Efficient Long-Term Visual Localization in Outdoor Environments
Aug 08, 2018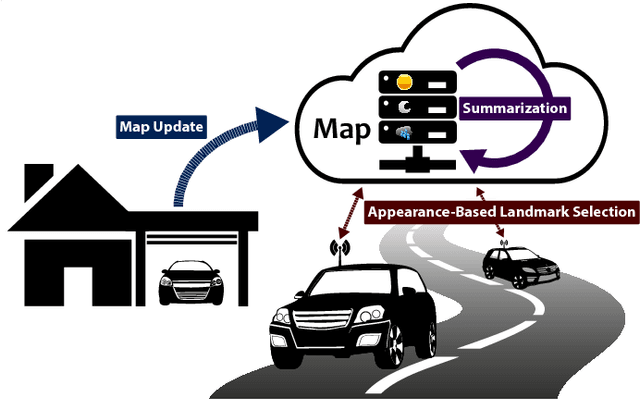
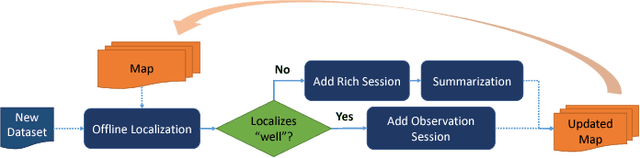
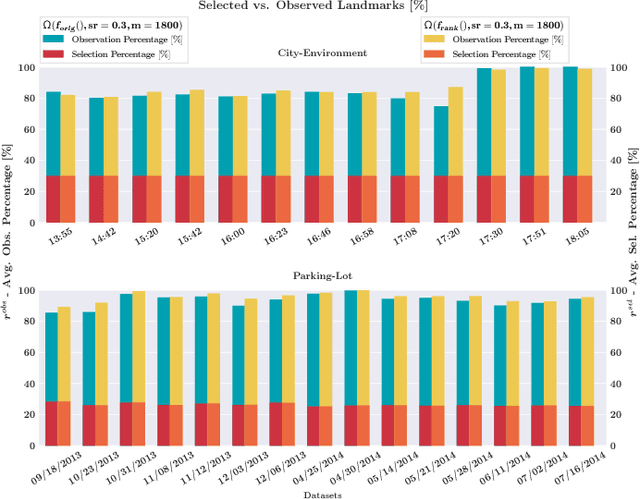
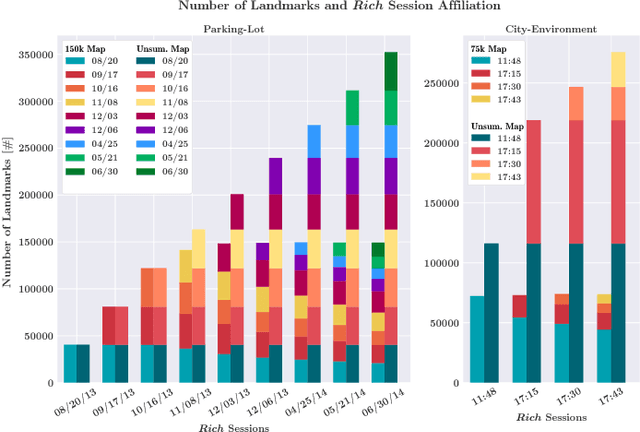
We present a complete map management process for a visual localization system designed for multi-vehicle long- term operations in resource constrained outdoor environments. Outdoor visual localization generates large amounts of data that need to be incorporated into a lifelong visual map in order to allow localization at all times and under all appearance conditions. Processing these large quantities of data is non- trivial, as it is subject to limited computational and storage capabilities both on the vehicle and on the mapping backend. We address this problem with a two-fold map update paradigm capable of, either, adding new visual cues to the map, or updating co-observation statistics. The former, in combination with offline map summarization techniques, allows enhancing the appearance coverage of the lifelong map while keeping the map size limited. On the other hand, the latter is able to significantly boost the appearance-based landmark selection for efficient online localization without incurring any additional computational or storage burden. Our evaluation in challenging outdoor conditions shows that our proposed map management process allows building and maintaining maps for precise visual localization over long time spans in a tractable and scalable fashion.
Appearance-Based Landmark Selection for Efficient Long-Term Visual Localization
Aug 08, 2018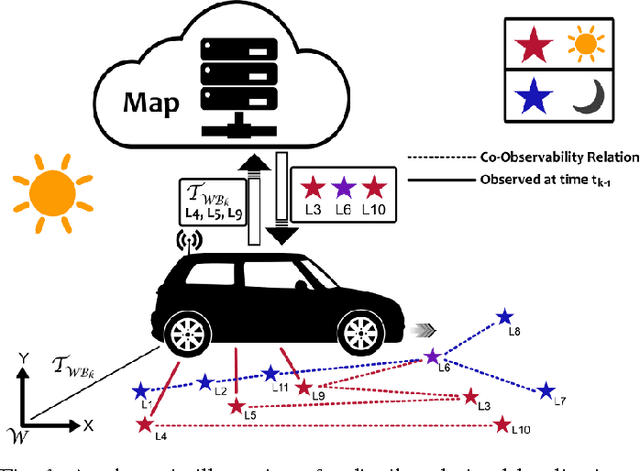
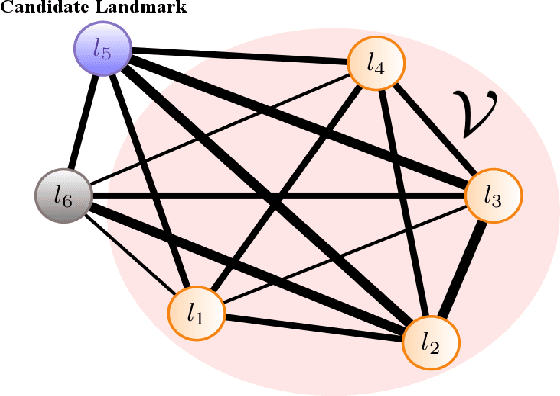


We present an online landmark selection method for distributed long-term visual localization systems in bandwidth-constrained environments. Sharing a common map for online localization provides a fleet of au- tonomous vehicles with the possibility to maintain and access a consistent map source, and therefore reduce redundancy while increasing efficiency. However, connectivity over a mobile network imposes strict bandwidth constraints and thus the need to minimize the amount of exchanged data. The wide range of varying appearance conditions encountered during long-term visual localization offers the potential to reduce data usage by extracting only those visual cues which are relevant at the given time. Motivated by this, we propose an unsupervised method of adaptively selecting landmarks according to how likely these landmarks are to be observable under the prevailing appear- ance condition. The ranking function this selection is based upon exploits landmark co-observability statistics collected in past traversals through the mapped area. Evaluation is per- formed over different outdoor environments, large time-scales and varying appearance conditions, including the extreme tran- sition from day-time to night-time, demonstrating that with our appearance-dependent selection method, we can significantly reduce the amount of landmarks used for localization while maintaining or even improving the localization performance.
Incremental Object Database: Building 3D Models from Multiple Partial Observations
Aug 02, 2018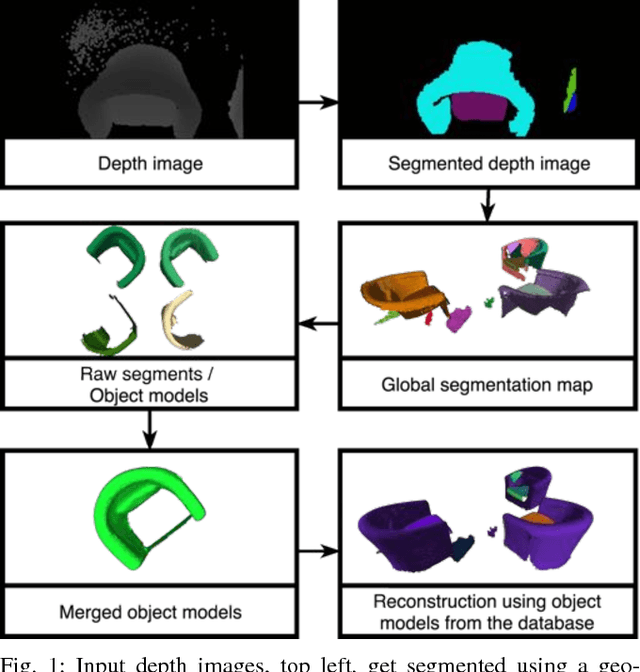

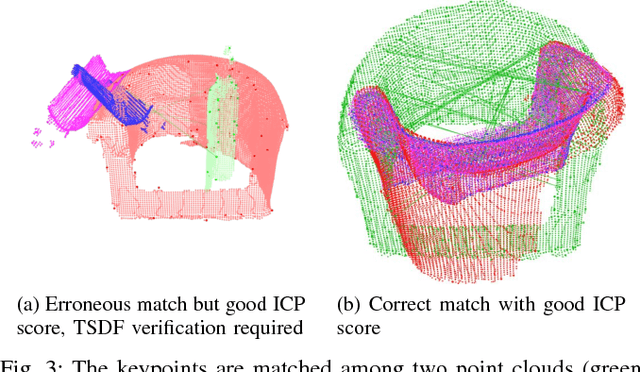
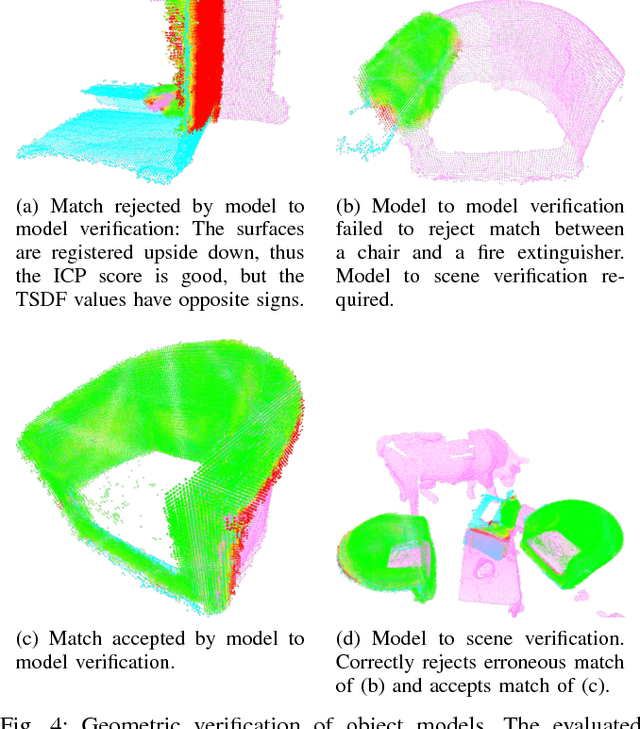
Collecting 3D object datasets involves a large amount of manual work and is time consuming. Getting complete models of objects either requires a 3D scanner that covers all the surfaces of an object or one needs to rotate it to completely observe it. We present a system that incrementally builds a database of objects as a mobile agent traverses a scene. Our approach requires no prior knowledge of the shapes present in the scene. Object-like segments are extracted from a global segmentation map, which is built online using the input of segmented RGB-D images. These segments are stored in a database, matched among each other, and merged with other previously observed instances. This allows us to create and improve object models on the fly and to use these merged models to reconstruct also unobserved parts of the scene. The database contains each (potentially merged) object model only once, together with a set of poses where it was observed. We evaluate our pipeline with one public dataset, and on a newly created Google Tango dataset containing four indoor scenes with some of the objects appearing multiple times, both within and across scenes.
Modular Sensor Fusion for Semantic Segmentation
Jul 30, 2018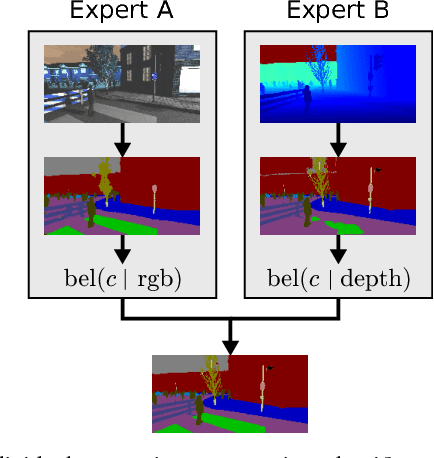
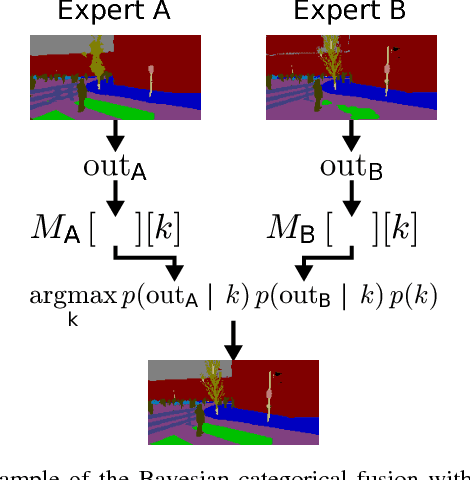
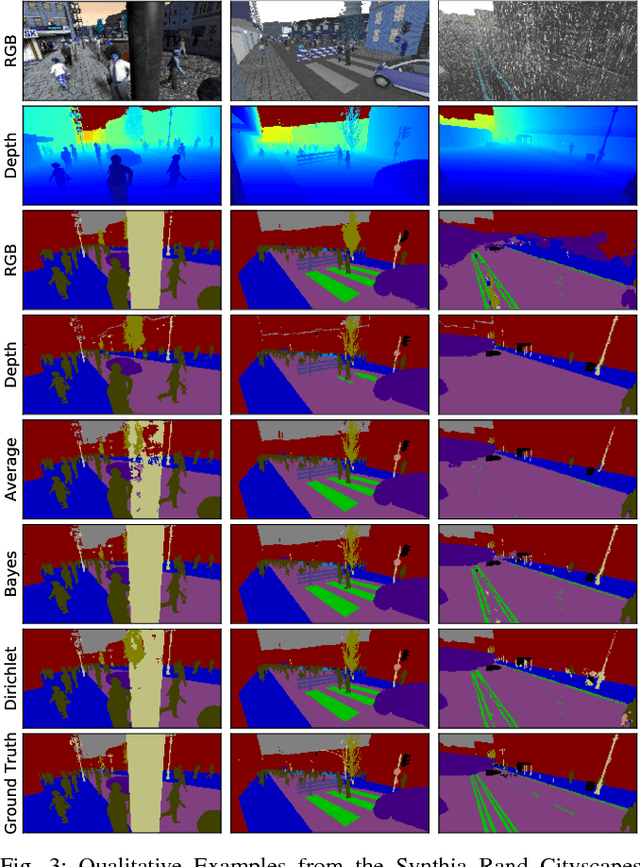
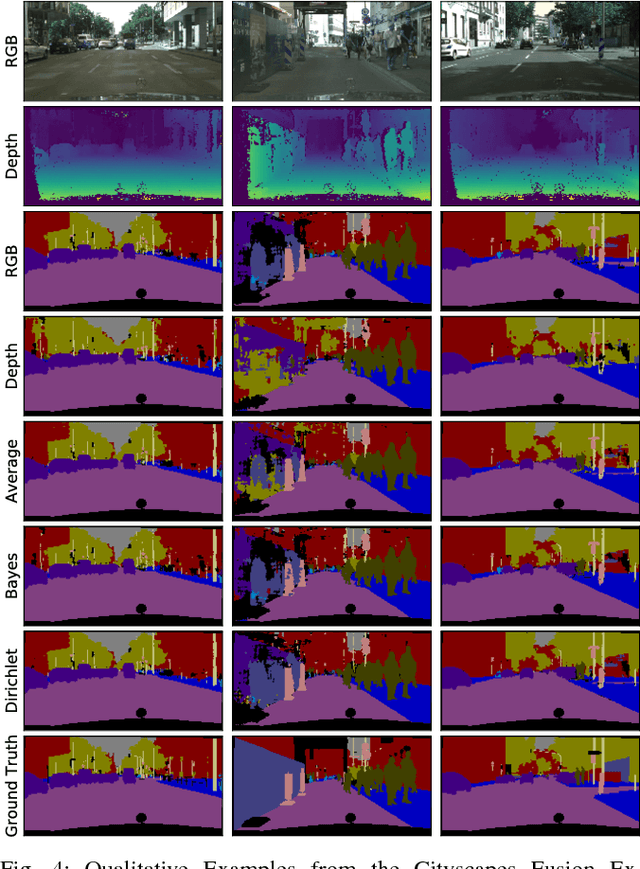
Sensor fusion is a fundamental process in robotic systems as it extends the perceptual range and increases robustness in real-world operations. Current multi-sensor deep learning based semantic segmentation approaches do not provide robustness to under-performing classes in one modality, or require a specific architecture with access to the full aligned multi-sensor training data. In this work, we analyze statistical fusion approaches for semantic segmentation that overcome these drawbacks while keeping a competitive performance. The studied approaches are modular by construction, allowing to have different training sets per modality and only a much smaller subset is needed to calibrate the statistical models. We evaluate a range of statistical fusion approaches and report their performance against state-of-the-art baselines on both real-world and simulated data. In our experiments, the approach improves performance in IoU over the best single modality segmentation results by up to 5%. We make all implementations and configurations publicly available.
Sparse 3D Topological Graphs for Micro-Aerial Vehicle Planning
Jul 24, 2018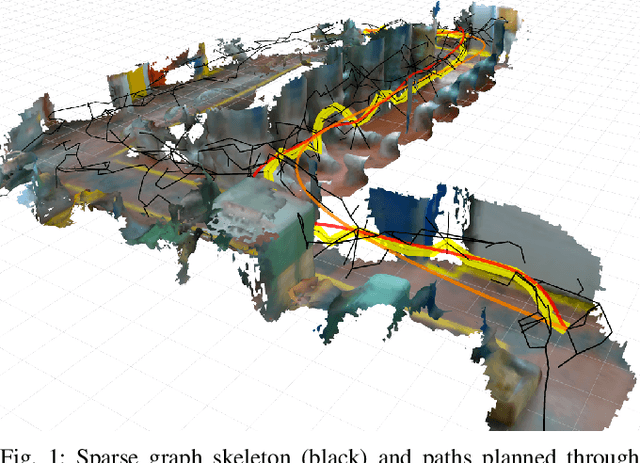
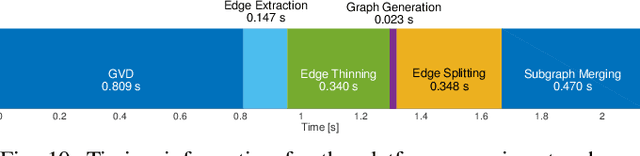
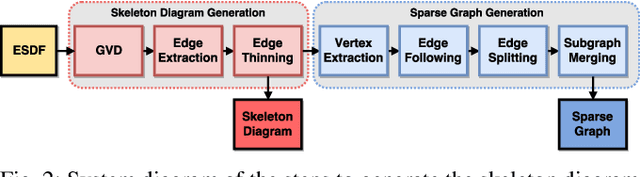
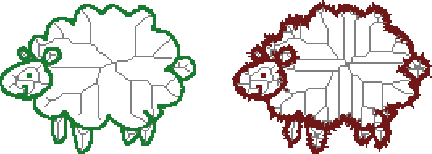
Micro-Aerial Vehicles (MAVs) have the advantage of moving freely in 3D space. However, creating compact and sparse map representations that can be efficiently used for planning for such robots is still an open problem. In this paper, we take maps built from noisy sensor data and construct a sparse graph containing topological information that can be used for 3D planning. We use a Euclidean Signed Distance Field, extract a 3D Generalized Voronoi Diagram (GVD), and obtain a thin skeleton diagram representing the topological structure of the environment. We then convert this skeleton diagram into a sparse graph, which we show is resistant to noise and changes in resolution. We demonstrate global planning over this graph, and the orders of magnitude speed-up it offers over other common planning methods. We validate our planning algorithm in real maps built onboard an MAV, using RGB-D sensing.