 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRREx-BoT: Remote Referring Expressions with a Bag of Tricks
Jan 30, 2023



Household robots operate in the same space for years. Such robots incrementally build dynamic maps that can be used for tasks requiring remote object localization. However, benchmarks in robot learning often test generalization through inference on tasks in unobserved environments. In an observed environment, locating an object is reduced to choosing from among all object proposals in the environment, which may number in the 100,000s. Armed with this intuition, using only a generic vision-language scoring model with minor modifications for 3d encoding and operating in an embodied environment, we demonstrate an absolute performance gain of 9.84% on remote object grounding above state of the art models for REVERIE and of 5.04% on FAO. When allowed to pre-explore an environment, we also exceed the previous state of the art pre-exploration method on REVERIE. Additionally, we demonstrate our model on a real-world TurtleBot platform, highlighting the simplicity and usefulness of the approach. Our analysis outlines a "bag of tricks" essential for accomplishing this task, from utilizing 3d coordinates and context, to generalizing vision-language models to large 3d search spaces.
CLIP-Nav: Using CLIP for Zero-Shot Vision-and-Language Navigation
Nov 30, 2022



Household environments are visually diverse. Embodied agents performing Vision-and-Language Navigation (VLN) in the wild must be able to handle this diversity, while also following arbitrary language instructions. Recently, Vision-Language models like CLIP have shown great performance on the task of zero-shot object recognition. In this work, we ask if these models are also capable of zero-shot language grounding. In particular, we utilize CLIP to tackle the novel problem of zero-shot VLN using natural language referring expressions that describe target objects, in contrast to past work that used simple language templates describing object classes. We examine CLIP's capability in making sequential navigational decisions without any dataset-specific finetuning, and study how it influences the path that an agent takes. Our results on the coarse-grained instruction following task of REVERIE demonstrate the navigational capability of CLIP, surpassing the supervised baseline in terms of both success rate (SR) and success weighted by path length (SPL). More importantly, we quantitatively show that our CLIP-based zero-shot approach generalizes better to show consistent performance across environments when compared to SOTA, fully supervised learning approaches when evaluated via Relative Change in Success (RCS).
Video in 10 Bits: Few-Bit VideoQA for Efficiency and Privacy
Oct 18, 2022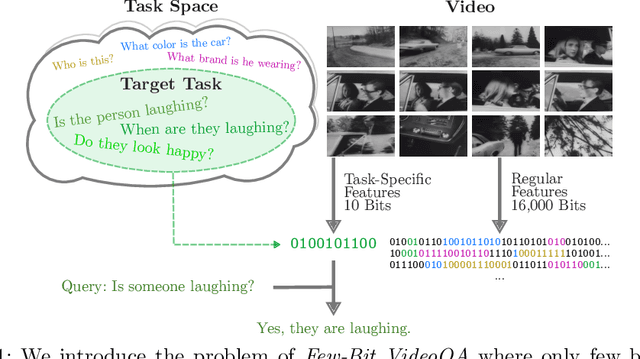

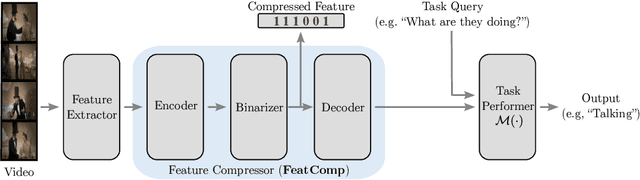
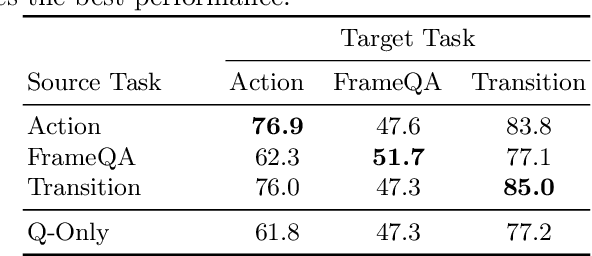
In Video Question Answering (VideoQA), answering general questions about a video requires its visual information. Yet, video often contains redundant information irrelevant to the VideoQA task. For example, if the task is only to answer questions similar to "Is someone laughing in the video?", then all other information can be discarded. This paper investigates how many bits are really needed from the video in order to do VideoQA by introducing a novel Few-Bit VideoQA problem, where the goal is to accomplish VideoQA with few bits of video information (e.g., 10 bits). We propose a simple yet effective task-specific feature compression approach to solve this problem. Specifically, we insert a lightweight Feature Compression Module (FeatComp) into a VideoQA model which learns to extract task-specific tiny features as little as 10 bits, which are optimal for answering certain types of questions. We demonstrate more than 100,000-fold storage efficiency over MPEG4-encoded videos and 1,000-fold over regular floating point features, with just 2.0-6.6% absolute loss in accuracy, which is a surprising and novel finding. Finally, we analyze what the learned tiny features capture and demonstrate that they have eliminated most of the non-task-specific information, and introduce a Bit Activation Map to visualize what information is being stored. This decreases the privacy risk of data by providing k-anonymity and robustness to feature-inversion techniques, which can influence the machine learning community, allowing us to store data with privacy guarantees while still performing the task effectively.
A Simple Approach for Visual Rearrangement: 3D Mapping and Semantic Search
Jun 21, 2022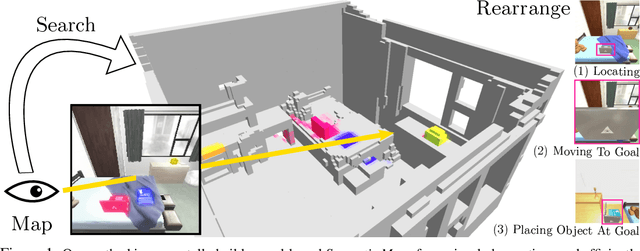
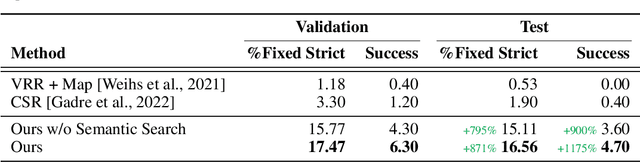
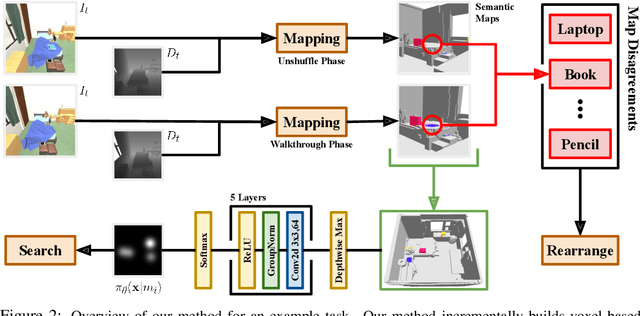
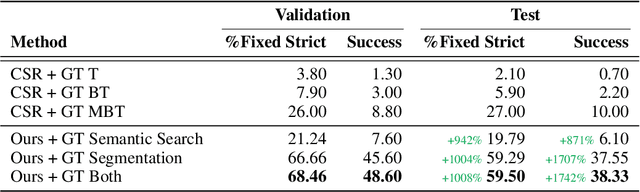
Physically rearranging objects is an important capability for embodied agents. Visual room rearrangement evaluates an agent's ability to rearrange objects in a room to a desired goal based solely on visual input. We propose a simple yet effective method for this problem: (1) search for and map which objects need to be rearranged, and (2) rearrange each object until the task is complete. Our approach consists of an off-the-shelf semantic segmentation model, voxel-based semantic map, and semantic search policy to efficiently find objects that need to be rearranged. On the AI2-THOR Rearrangement Challenge, our method improves on current state-of-the-art end-to-end reinforcement learning-based methods that learn visual rearrangement policies from 0.53% correct rearrangement to 16.56%, using only 2.7% as many samples from the environment.
TEACh: Task-driven Embodied Agents that Chat
Oct 15, 2021
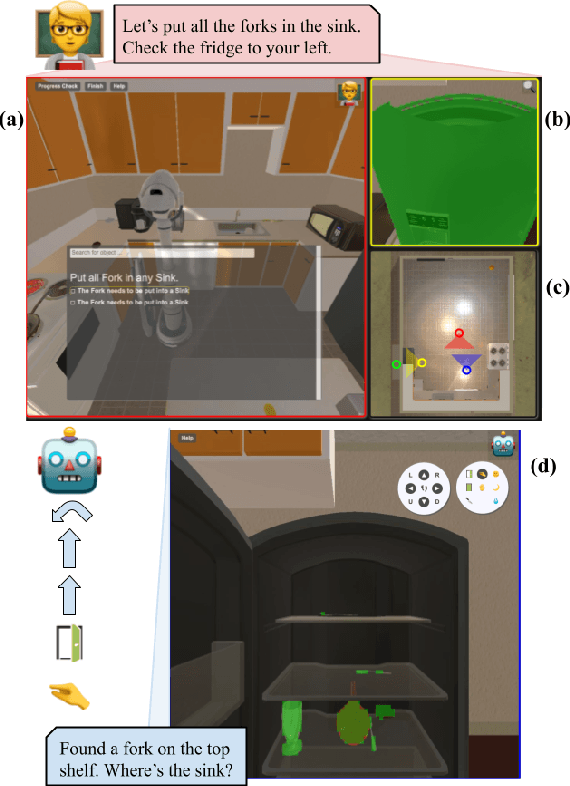
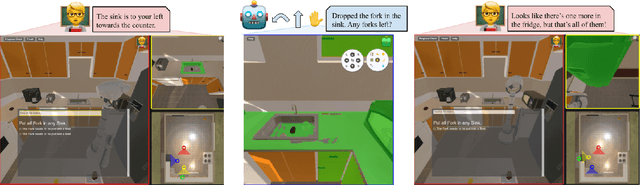
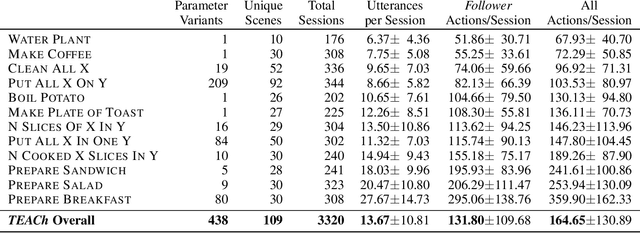
Robots operating in human spaces must be able to engage in natural language interaction with people, both understanding and executing instructions, and using conversation to resolve ambiguity and recover from mistakes. To study this, we introduce TEACh, a dataset of over 3,000 human--human, interactive dialogues to complete household tasks in simulation. A Commander with access to oracle information about a task communicates in natural language with a Follower. The Follower navigates through and interacts with the environment to complete tasks varying in complexity from "Make Coffee" to "Prepare Breakfast", asking questions and getting additional information from the Commander. We propose three benchmarks using TEACh to study embodied intelligence challenges, and we evaluate initial models' abilities in dialogue understanding, language grounding, and task execution.
VISITRON: Visual Semantics-Aligned Interactively Trained Object-Navigator
May 25, 2021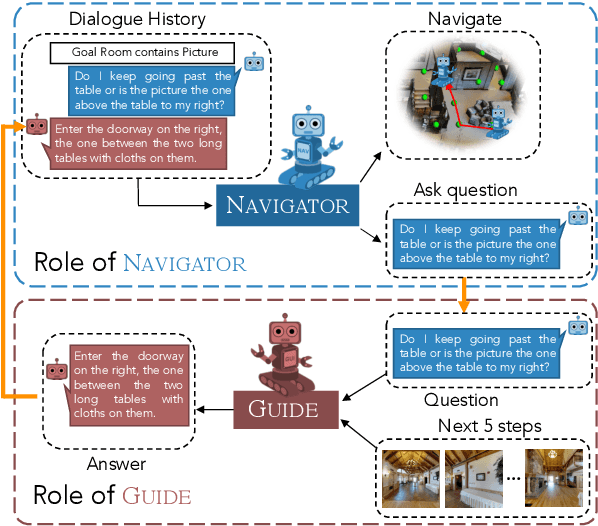
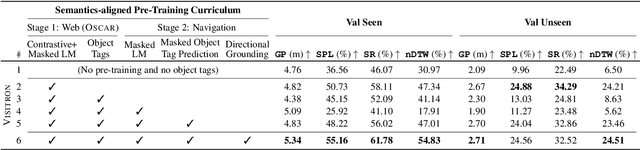
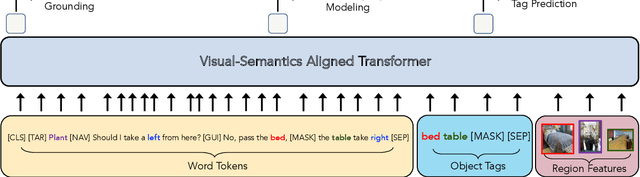
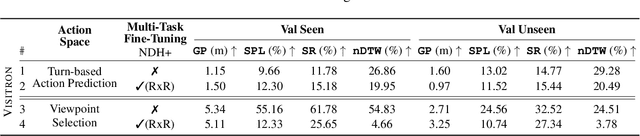
Interactive robots navigating photo-realistic environments face challenges underlying vision-and-language navigation (VLN), but in addition, they need to be trained to handle the dynamic nature of dialogue. However, research in Cooperative Vision-and-Dialog Navigation (CVDN), where a navigator interacts with a guide in natural language in order to reach a goal, treats the dialogue history as a VLN-style static instruction. In this paper, we present VISITRON, a navigator better suited to the interactive regime inherent to CVDN by being trained to: i) identify and associate object-level concepts and semantics between the environment and dialogue history, ii) identify when to interact vs. navigate via imitation learning of a binary classification head. We perform extensive ablations with VISITRON to gain empirical insights and improve performance on CVDN. VISITRON is competitive with models on the static CVDN leaderboard. We also propose a generalized interactive regime to fine-tune and evaluate VISITRON and future such models with pre-trained guides for adaptability.
Self-Attentive 3D Human Pose and Shape Estimation from Videos
Mar 26, 2021
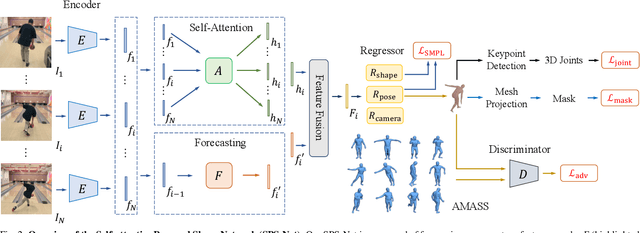
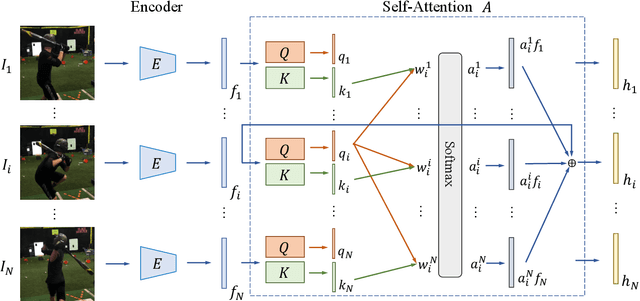
We consider the task of estimating 3D human pose and shape from videos. While existing frame-based approaches have made significant progress, these methods are independently applied to each image, thereby often leading to inconsistent predictions. In this work, we present a video-based learning algorithm for 3D human pose and shape estimation. The key insights of our method are two-fold. First, to address the inconsistent temporal prediction issue, we exploit temporal information in videos and propose a self-attention module that jointly considers short-range and long-range dependencies across frames, resulting in temporally coherent estimations. Second, we model human motion with a forecasting module that allows the transition between adjacent frames to be smooth. We evaluate our method on the 3DPW, MPI-INF-3DHP, and Human3.6M datasets. Extensive experimental results show that our algorithm performs favorably against the state-of-the-art methods.
Mixup-CAM: Weakly-supervised Semantic Segmentation via Uncertainty Regularization
Aug 03, 2020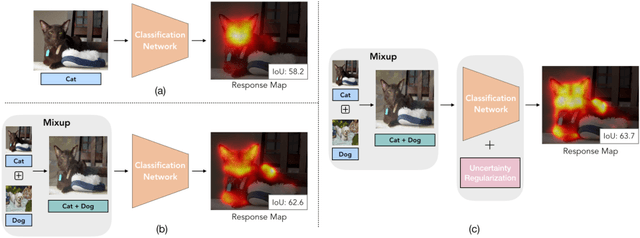
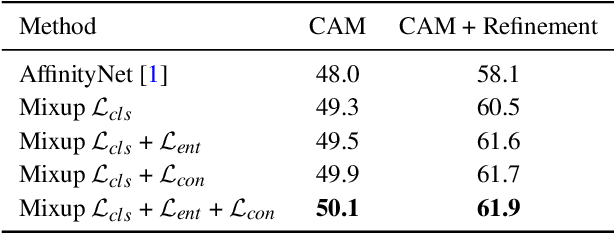
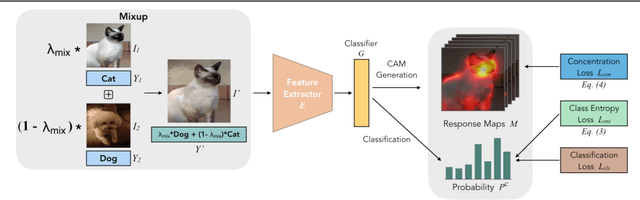
Obtaining object response maps is one important step to achieve weakly-supervised semantic segmentation using image-level labels. However, existing methods rely on the classification task, which could result in a response map only attending on discriminative object regions as the network does not need to see the entire object for optimizing the classification loss. To tackle this issue, we propose a principled and end-to-end train-able framework to allow the network to pay attention to other parts of the object, while producing a more complete and uniform response map. Specifically, we introduce the mixup data augmentation scheme into the classification network and design two uncertainty regularization terms to better interact with the mixup strategy. In experiments, we conduct extensive analysis to demonstrate the proposed method and show favorable performance against state-of-the-art approaches.
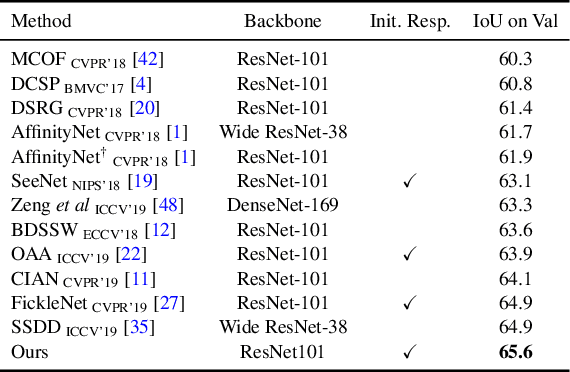
Weakly-Supervised Semantic Segmentation via Sub-category Exploration
Aug 03, 2020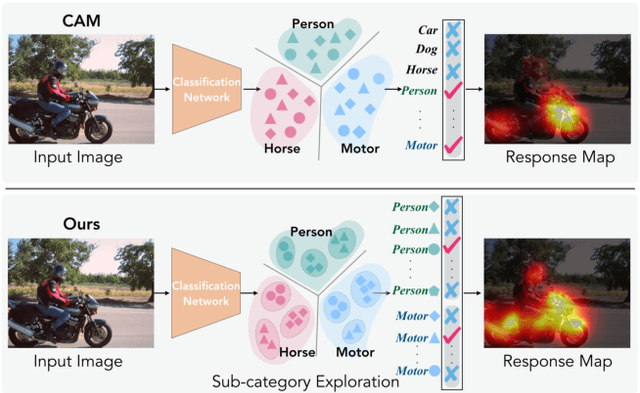
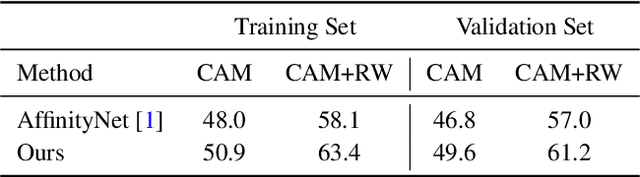
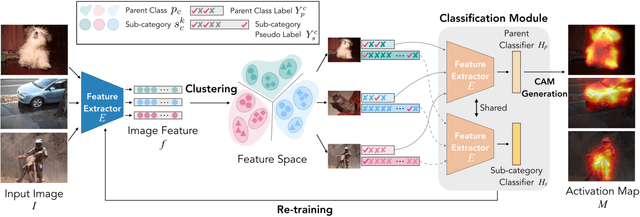
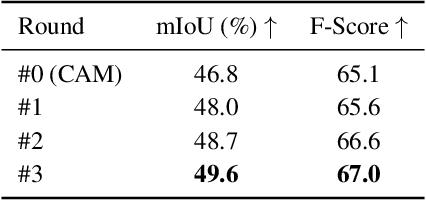
Existing weakly-supervised semantic segmentation methods using image-level annotations typically rely on initial responses to locate object regions. However, such response maps generated by the classification network usually focus on discriminative object parts, due to the fact that the network does not need the entire object for optimizing the objective function. To enforce the network to pay attention to other parts of an object, we propose a simple yet effective approach that introduces a self-supervised task by exploiting the sub-category information. Specifically, we perform clustering on image features to generate pseudo sub-categories labels within each annotated parent class, and construct a sub-category objective to assign the network to a more challenging task. By iteratively clustering image features, the training process does not limit itself to the most discriminative object parts, hence improving the quality of the response maps. We conduct extensive analysis to validate the proposed method and show that our approach performs favorably against the state-of-the-art approaches.
Understanding Image Quality and Trust in Peer-to-Peer Marketplaces
Nov 26, 2018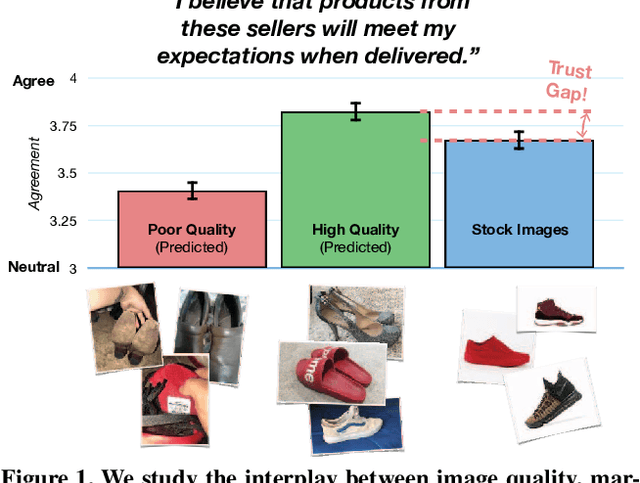

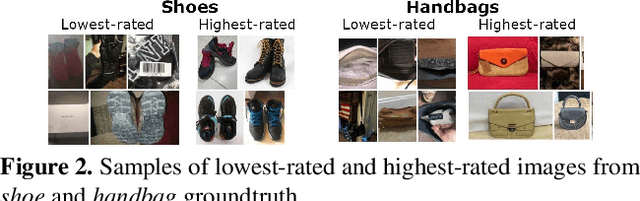
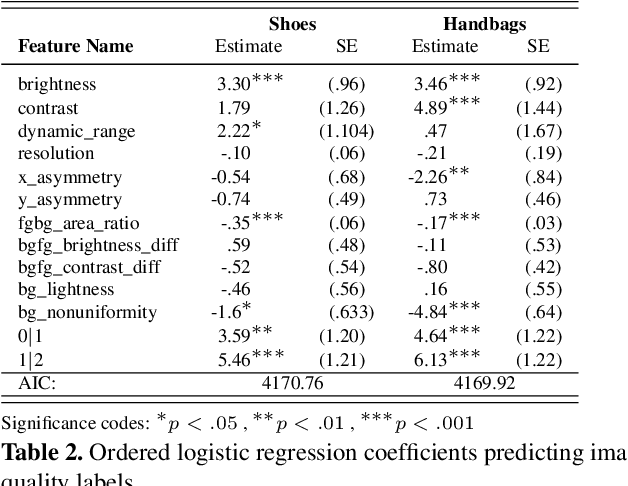
As any savvy online shopper knows, second-hand peer-to-peer marketplaces are filled with images of mixed quality. How does image quality impact marketplace outcomes, and can quality be automatically predicted? In this work, we conducted a large-scale study on the quality of user-generated images in peer-to-peer marketplaces. By gathering a dataset of common second-hand products (~75,000 images) and annotating a subset with human-labeled quality judgments, we were able to model and predict image quality with decent accuracy (~87%). We then conducted two studies focused on understanding the relationship between these image quality scores and two marketplace outcomes: sales and perceived trustworthiness. We show that image quality is associated with higher likelihood that an item will be sold, though other factors such as view count were better predictors of sales. Nonetheless, we show that high quality user-generated images selected by our models outperform stock imagery in eliciting perceptions of trust from users. Our findings can inform the design of future marketplaces and guide potential sellers to take better product images.