 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBrand > Logo: Visual Analysis of Fashion Brands
Oct 23, 2018
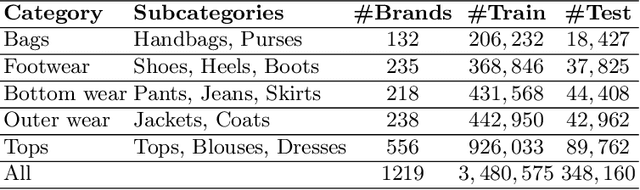

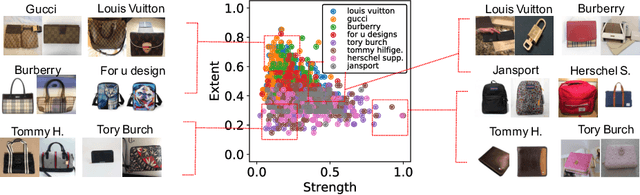
While lots of people may think branding begins and ends with a logo, fashion brands communicate their uniqueness through a wide range of visual cues such as color, patterns and shapes. In this work, we analyze learned visual representations by deep networks that are trained to recognize fashion brands. In particular, the activation strength and extent of neurons are studied to provide interesting insights about visual brand expressions. The proposed method identifies where a brand stands in the spectrum of branding strategy, i.e., from trademark-emblazoned goods with bold logos to implicit no logo marketing. By quantifying attention maps, we are able to interpret the visual characteristics of a brand present in a single image and model the general design direction of a brand as a whole. We further investigate versatility of neurons and discover "specialists" that are highly brand-specific and "generalists" that detect diverse visual features. A human experiment based on three main visual scenarios of fashion brands is conducted to verify the alignment of our quantitative measures with the human perception of brands. This paper demonstrate how deep networks go beyond logos in order to recognize clothing brands in an image.
ModaNet: A Large-Scale Street Fashion Dataset with Polygon Annotations
Oct 23, 2018

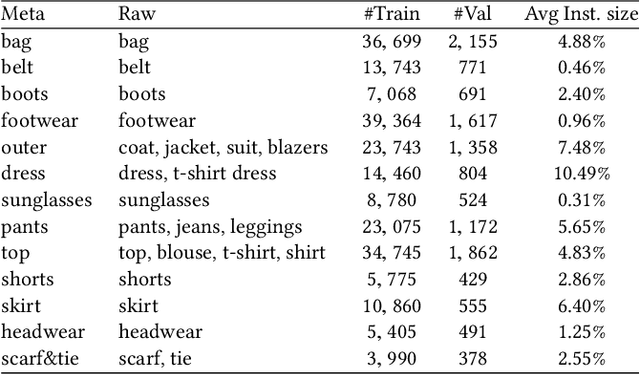
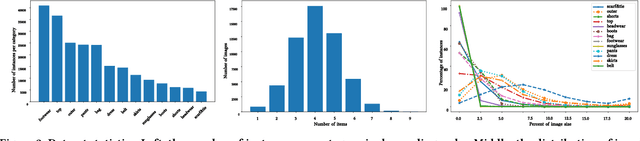
Understanding clothes from a single image has strong commercial and cultural impacts on modern societies. However, this task remains a challenging computer vision problem due to wide variations in the appearance, style, brand and layering of clothing items. We present a new database called ModaNet, a large-scale collection of images based on Paperdoll dataset. Our dataset provides 55,176 street images, fully annotated with polygons on top of the 1 million weakly annotated street images in Paperdoll. ModaNet aims to provide a technical benchmark to fairly evaluate the progress of applying the latest computer vision techniques that rely on large data for fashion understanding. The rich annotation of the dataset allows to measure the performance of state-of-the-art algorithms for object detection, semantic segmentation and polygon prediction on street fashion images in detail. The polygon-based annotation dataset has been released https://github.com/eBay/modanet, we also host the leaderboard at EvalAI: https://evalai.cloudcv.org/featured-challenges/136/overview.
Give me a hint! Navigating Image Databases using Human-in-the-loop Feedback
Sep 24, 2018
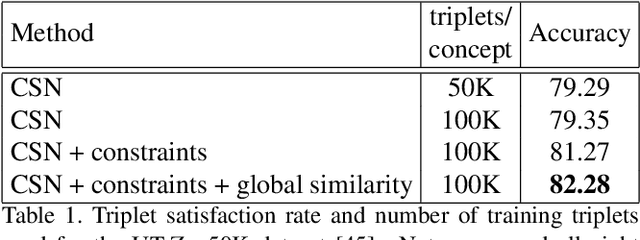
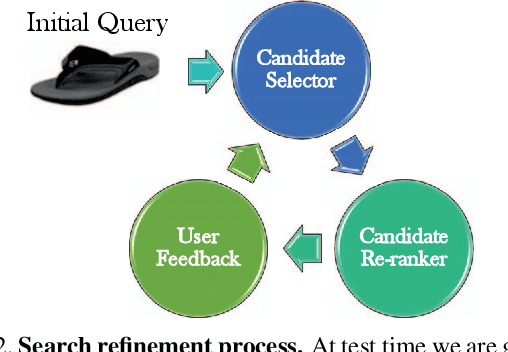
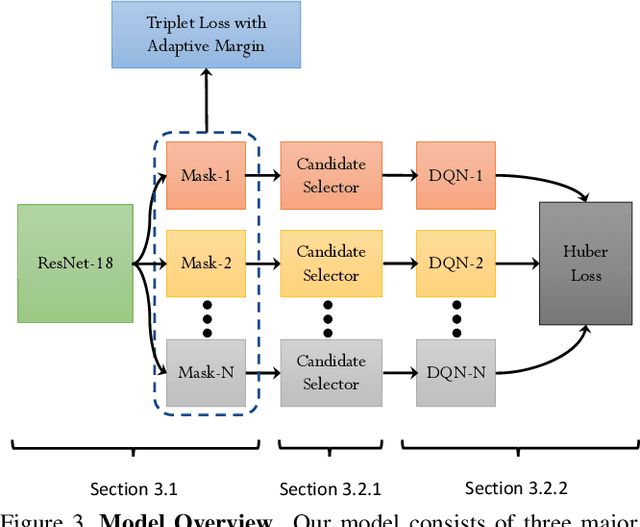
In this paper, we introduce an attribute-based interactive image search which can leverage human-in-the-loop feedback to iteratively refine image search results. We study active image search where human feedback is solicited exclusively in visual form, without using relative attribute annotations used by prior work which are not typically found in many datasets. In order to optimize the image selection strategy, a deep reinforcement model is trained to learn what images are informative rather than rely on hand-crafted measures typically leveraged in prior work. Additionally, we extend the recently introduced Conditional Similarity Network to incorporate global similarity in training visual embeddings, which results in more natural transitions as the user explores the learned similarity embeddings. Our experiments demonstrate the effectiveness of our approach, producing compelling results on both active image search and image attribute representation tasks.
Conditional Image-Text Embedding Networks
Jul 28, 2018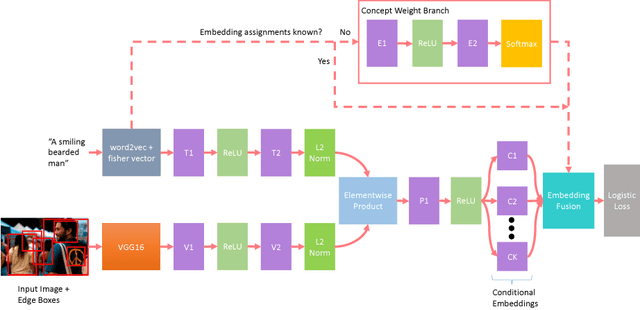
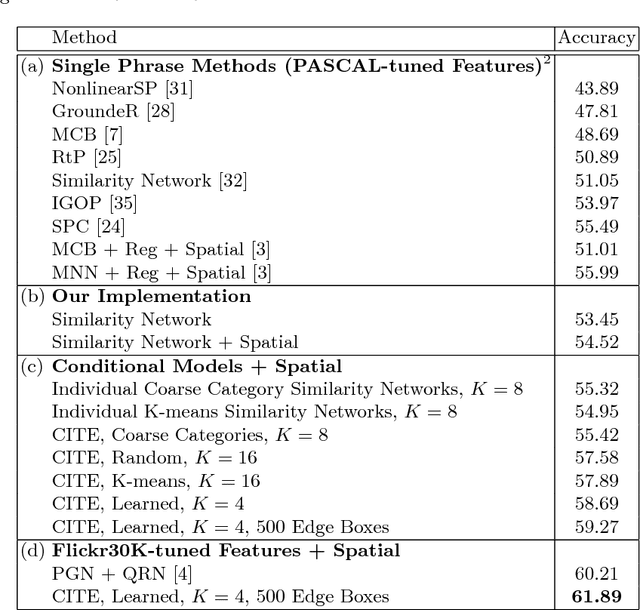

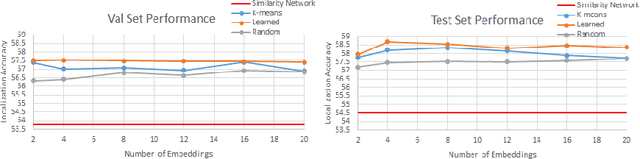
This paper presents an approach for grounding phrases in images which jointly learns multiple text-conditioned embeddings in a single end-to-end model. In order to differentiate text phrases into semantically distinct subspaces, we propose a concept weight branch that automatically assigns phrases to embeddings, whereas prior works predefine such assignments. Our proposed solution simplifies the representation requirements for individual embeddings and allows the underrepresented concepts to take advantage of the shared representations before feeding them into concept-specific layers. Comprehensive experiments verify the effectiveness of our approach across three phrase grounding datasets, Flickr30K Entities, ReferIt Game, and Visual Genome, where we obtain a (resp.) 4%, 3%, and 4% improvement in grounding performance over a strong region-phrase embedding baseline.