 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImplicit Occupancy Flow Fields for Perception and Prediction in Self-Driving
Aug 02, 2023



A self-driving vehicle (SDV) must be able to perceive its surroundings and predict the future behavior of other traffic participants. Existing works either perform object detection followed by trajectory forecasting of the detected objects, or predict dense occupancy and flow grids for the whole scene. The former poses a safety concern as the number of detections needs to be kept low for efficiency reasons, sacrificing object recall. The latter is computationally expensive due to the high-dimensionality of the output grid, and suffers from the limited receptive field inherent to fully convolutional networks. Furthermore, both approaches employ many computational resources predicting areas or objects that might never be queried by the motion planner. This motivates our unified approach to perception and future prediction that implicitly represents occupancy and flow over time with a single neural network. Our method avoids unnecessary computation, as it can be directly queried by the motion planner at continuous spatio-temporal locations. Moreover, we design an architecture that overcomes the limited receptive field of previous explicit occupancy prediction methods by adding an efficient yet effective global attention mechanism. Through extensive experiments in both urban and highway settings, we demonstrate that our implicit model outperforms the current state-of-the-art. For more information, visit the project website: https://waabi.ai/research/implicito.
* 19 pages, 13 figures
Rethinking Closed-loop Training for Autonomous Driving
Jun 27, 2023Recent advances in high-fidelity simulators have enabled closed-loop training of autonomous driving agents, potentially solving the distribution shift in training v.s. deployment and allowing training to be scaled both safely and cheaply. However, there is a lack of understanding of how to build effective training benchmarks for closed-loop training. In this work, we present the first empirical study which analyzes the effects of different training benchmark designs on the success of learning agents, such as how to design traffic scenarios and scale training environments. Furthermore, we show that many popular RL algorithms cannot achieve satisfactory performance in the context of autonomous driving, as they lack long-term planning and take an extremely long time to train. To address these issues, we propose trajectory value learning (TRAVL), an RL-based driving agent that performs planning with multistep look-ahead and exploits cheaply generated imagined data for efficient learning. Our experiments show that TRAVL can learn much faster and produce safer maneuvers compared to all the baselines. For more information, visit the project website: https://waabi.ai/research/travl
GoRela: Go Relative for Viewpoint-Invariant Motion Forecasting
Nov 08, 2022The task of motion forecasting is critical for self-driving vehicles (SDVs) to be able to plan a safe maneuver. Towards this goal, modern approaches reason about the map, the agents' past trajectories and their interactions in order to produce accurate forecasts. The predominant approach has been to encode the map and other agents in the reference frame of each target agent. However, this approach is computationally expensive for multi-agent prediction as inference needs to be run for each agent. To tackle the scaling challenge, the solution thus far has been to encode all agents and the map in a shared coordinate frame (e.g., the SDV frame). However, this is sample inefficient and vulnerable to domain shift (e.g., when the SDV visits uncommon states). In contrast, in this paper, we propose an efficient shared encoding for all agents and the map without sacrificing accuracy or generalization. Towards this goal, we leverage pair-wise relative positional encodings to represent geometric relationships between the agents and the map elements in a heterogeneous spatial graph. This parameterization allows us to be invariant to scene viewpoint, and save online computation by re-using map embeddings computed offline. Our decoder is also viewpoint agnostic, predicting agent goals on the lane graph to enable diverse and context-aware multimodal prediction. We demonstrate the effectiveness of our approach on the urban Argoverse 2 benchmark as well as a novel highway dataset.
Virtual Correspondence: Humans as a Cue for Extreme-View Geometry
Jun 16, 2022



Recovering the spatial layout of the cameras and the geometry of the scene from extreme-view images is a longstanding challenge in computer vision. Prevailing 3D reconstruction algorithms often adopt the image matching paradigm and presume that a portion of the scene is co-visible across images, yielding poor performance when there is little overlap among inputs. In contrast, humans can associate visible parts in one image to the corresponding invisible components in another image via prior knowledge of the shapes. Inspired by this fact, we present a novel concept called virtual correspondences (VCs). VCs are a pair of pixels from two images whose camera rays intersect in 3D. Similar to classic correspondences, VCs conform with epipolar geometry; unlike classic correspondences, VCs do not need to be co-visible across views. Therefore VCs can be established and exploited even if images do not overlap. We introduce a method to find virtual correspondences based on humans in the scene. We showcase how VCs can be seamlessly integrated with classic bundle adjustment to recover camera poses across extreme views. Experiments show that our method significantly outperforms state-of-the-art camera pose estimation methods in challenging scenarios and is comparable in the traditional densely captured setup. Our approach also unleashes the potential of multiple downstream tasks such as scene reconstruction from multi-view stereo and novel view synthesis in extreme-view scenarios.
NP-DRAW: A Non-Parametric Structured Latent Variable Model for Image Generation
Jul 04, 2021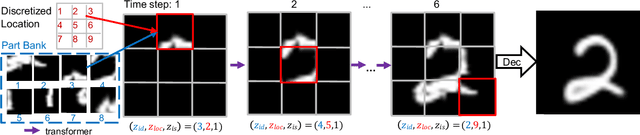
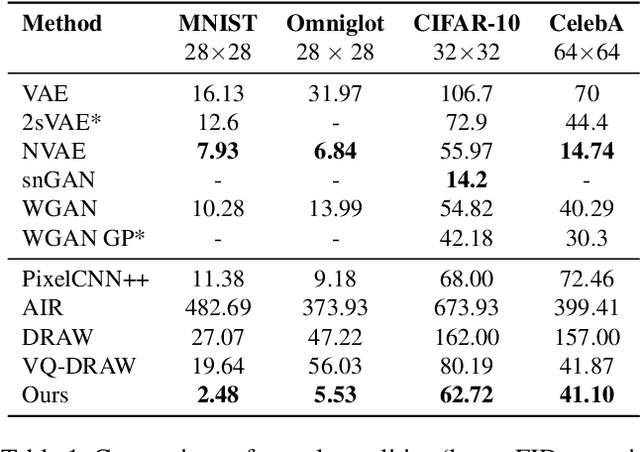
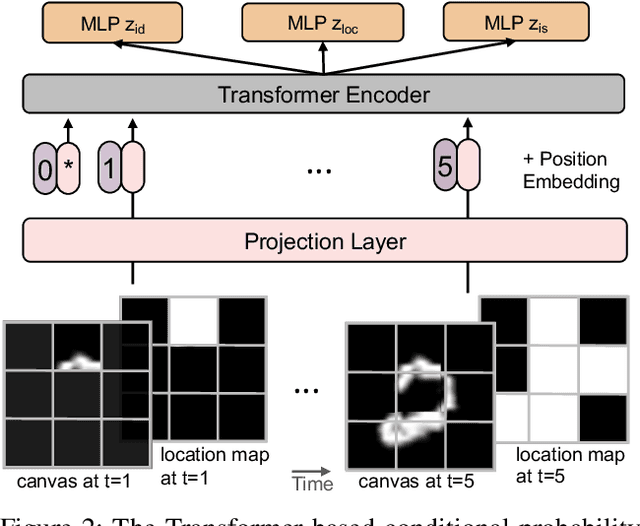
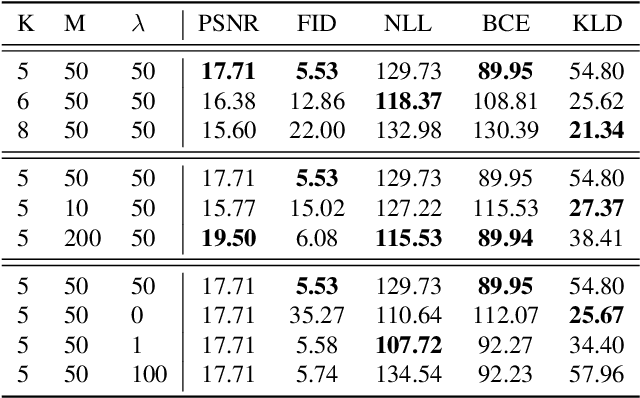
In this paper, we present a non-parametric structured latent variable model for image generation, called NP-DRAW, which sequentially draws on a latent canvas in a part-by-part fashion and then decodes the image from the canvas. Our key contributions are as follows. 1) We propose a non-parametric prior distribution over the appearance of image parts so that the latent variable ``what-to-draw'' per step becomes a categorical random variable. This improves the expressiveness and greatly eases the learning compared to Gaussians used in the literature. 2) We model the sequential dependency structure of parts via a Transformer, which is more powerful and easier to train compared to RNNs used in the literature. 3) We propose an effective heuristic parsing algorithm to pre-train the prior. Experiments on MNIST, Omniglot, CIFAR-10, and CelebA show that our method significantly outperforms previous structured image models like DRAW and AIR and is competitive to other generic generative models. Moreover, we show that our model's inherent compositionality and interpretability bring significant benefits in the low-data learning regime and latent space editing. Code is available at https://github.com/ZENGXH/NPDRAW.
Just Label What You Need: Fine-Grained Active Selection for Perception and Prediction through Partially Labeled Scenes
Apr 08, 2021
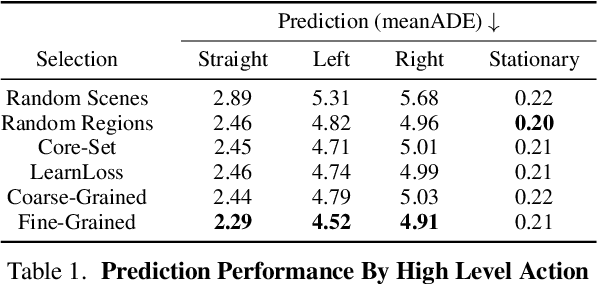
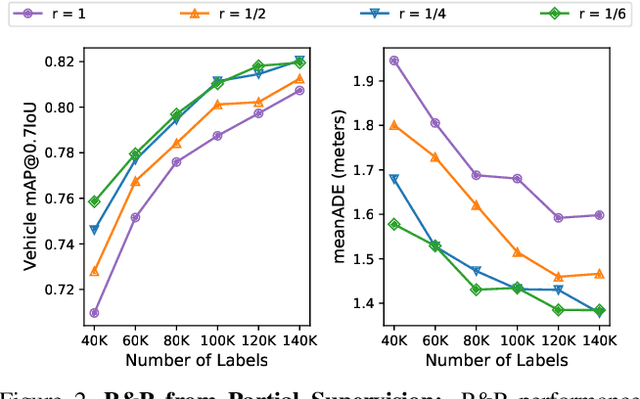
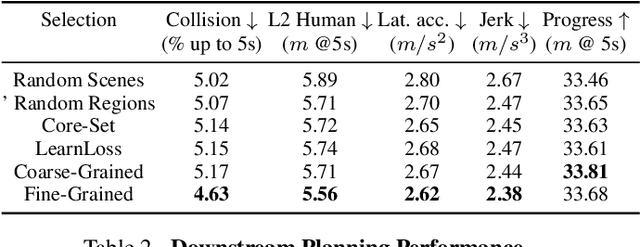
Self-driving vehicles must perceive and predict the future positions of nearby actors in order to avoid collisions and drive safely. A learned deep learning module is often responsible for this task, requiring large-scale, high-quality training datasets. As data collection is often significantly cheaper than labeling in this domain, the decision of which subset of examples to label can have a profound impact on model performance. Active learning techniques, which leverage the state of the current model to iteratively select examples for labeling, offer a promising solution to this problem. However, despite the appeal of this approach, there has been little scientific analysis of active learning approaches for the perception and prediction (P&P) problem. In this work, we study active learning techniques for P&P and find that the traditional active learning formulation is ill-suited for the P&P setting. We thus introduce generalizations that ensure that our approach is both cost-aware and allows for fine-grained selection of examples through partially labeled scenes. Our experiments on a real-world, large-scale self-driving dataset suggest that fine-grained selection can improve the performance across perception, prediction, and downstream planning tasks.
Exploring Adversarial Robustness of Multi-Sensor Perception Systems in Self Driving
Jan 26, 2021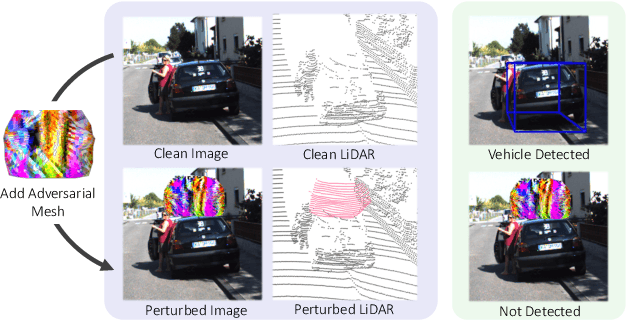
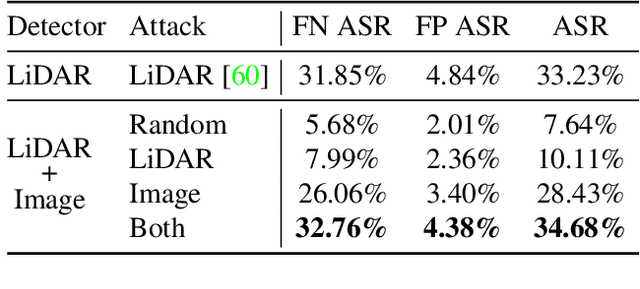
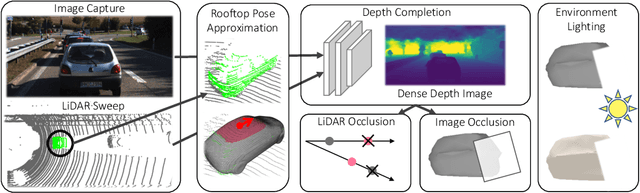
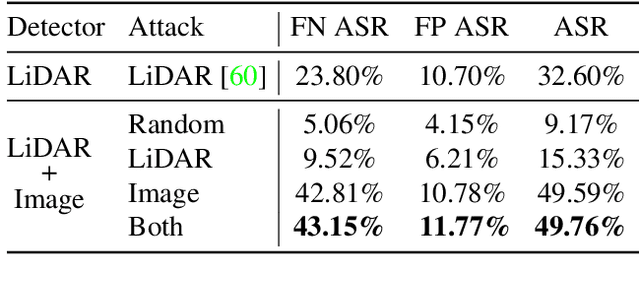
Modern self-driving perception systems have been shown to improve upon processing complementary inputs such as LiDAR with images. In isolation, 2D images have been found to be extremely vulnerable to adversarial attacks. Yet, there have been limited studies on the adversarial robustness of multi-modal models that fuse LiDAR features with image features. Furthermore, existing works do not consider physically realizable perturbations that are consistent across the input modalities. In this paper, we showcase practical susceptibilities of multi-sensor detection by placing an adversarial object on top of a host vehicle. We focus on physically realizable and input-agnostic attacks as they are feasible to execute in practice, and show that a single universal adversary can hide different host vehicles from state-of-the-art multi-modal detectors. Our experiments demonstrate that successful attacks are primarily caused by easily corrupted image features. Furthermore, we find that in modern sensor fusion methods which project image features into 3D, adversarial attacks can exploit the projection process to generate false positives across distant regions in 3D. Towards more robust multi-modal perception systems, we show that adversarial training with feature denoising can boost robustness to such attacks significantly. However, we find that standard adversarial defenses still struggle to prevent false positives which are also caused by inaccurate associations between 3D LiDAR points and 2D pixels.
IntentNet: Learning to Predict Intention from Raw Sensor Data
Jan 20, 2021
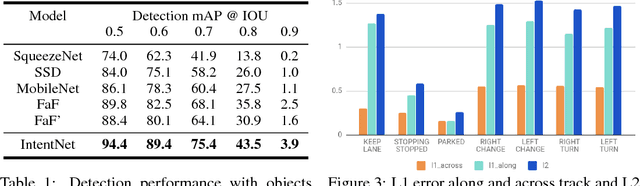
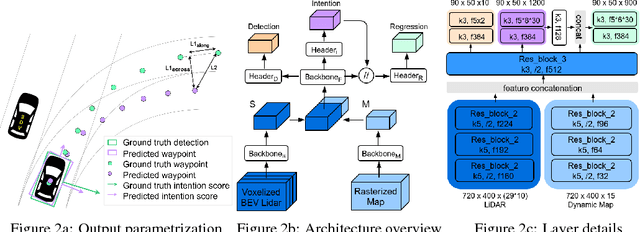
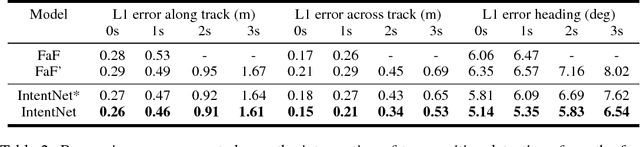
In order to plan a safe maneuver, self-driving vehicles need to understand the intent of other traffic participants. We define intent as a combination of discrete high-level behaviors as well as continuous trajectories describing future motion. In this paper, we develop a one-stage detector and forecaster that exploits both 3D point clouds produced by a LiDAR sensor as well as dynamic maps of the environment. Our multi-task model achieves better accuracy than the respective separate modules while saving computation, which is critical to reducing reaction time in self-driving applications.
Deep Feedback Inverse Problem Solver
Jan 19, 2021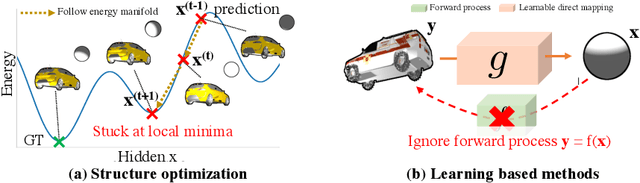
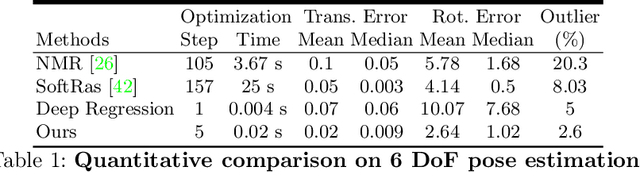
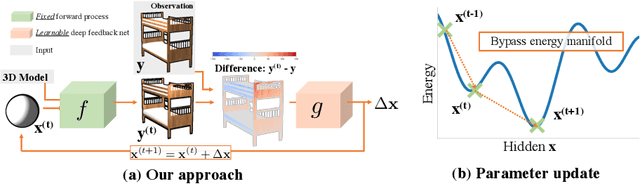
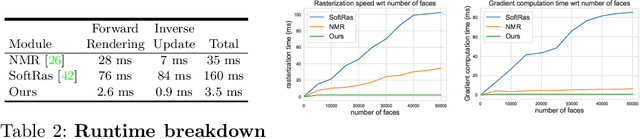
We present an efficient, effective, and generic approach towards solving inverse problems. The key idea is to leverage the feedback signal provided by the forward process and learn an iterative update model. Specifically, at each iteration, the neural network takes the feedback as input and outputs an update on the current estimation. Our approach does not have any restrictions on the forward process; it does not require any prior knowledge either. Through the feedback information, our model not only can produce accurate estimations that are coherent to the input observation but also is capable of recovering from early incorrect predictions. We verify the performance of our approach over a wide range of inverse problems, including 6-DOF pose estimation, illumination estimation, as well as inverse kinematics. Comparing to traditional optimization-based methods, we can achieve comparable or better performance while being two to three orders of magnitude faster. Compared to deep learning-based approaches, our model consistently improves the performance on all metrics. Please refer to the project page for videos, animations, supplementary materials, etc.
Deep Multi-Task Learning for Joint Localization, Perception, and Prediction
Jan 19, 2021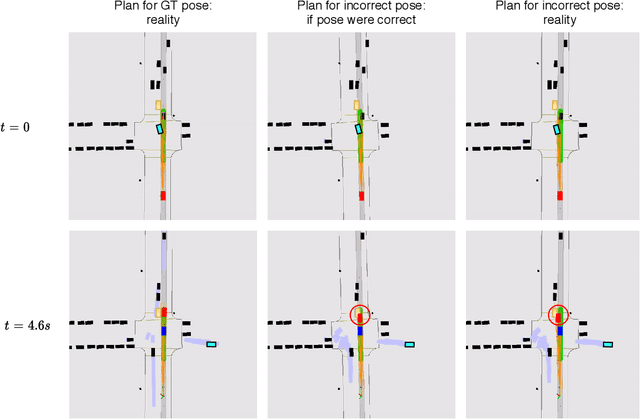
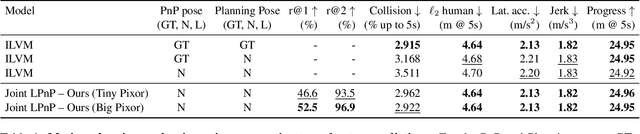
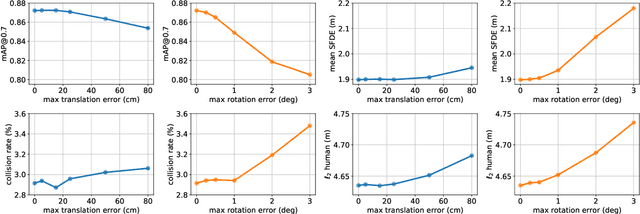

Over the last few years, we have witnessed tremendous progress on many subtasks of autonomous driving, including perception, motion forecasting, and motion planning. However, these systems often assume that the car is accurately localized against a high-definition map. In this paper we question this assumption, and investigate the issues that arise in state-of-the-art autonomy stacks under localization error. Based on our observations, we design a system that jointly performs perception, prediction, and localization. Our architecture is able to reuse computation between both tasks, and is thus able to correct localization errors efficiently. We show experiments on a large-scale autonomy dataset, demonstrating the efficiency and accuracy of our proposed approach.