 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Neighborhood Representation from Multi-Modal Multi-Graph: Image, Text, Mobility Graph and Beyond
May 06, 2021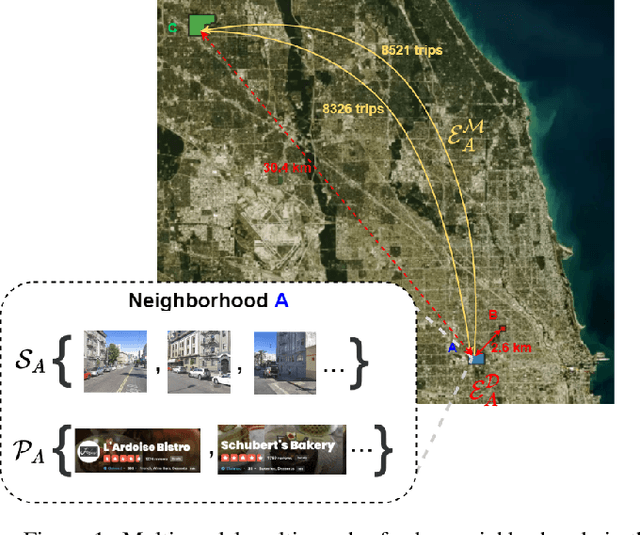


Recent urbanization has coincided with the enrichment of geotagged data, such as street view and point-of-interest (POI). Region embedding enhanced by the richer data modalities has enabled researchers and city administrators to understand the built environment, socioeconomics, and the dynamics of cities better. While some efforts have been made to simultaneously use multi-modal inputs, existing methods can be improved by incorporating different measures of 'proximity' in the same embedding space - leveraging not only the data that characterizes the regions (e.g., street view, local businesses pattern) but also those that depict the relationship between regions (e.g., trips, road network). To this end, we propose a novel approach to integrate multi-modal geotagged inputs as either node or edge features of a multi-graph based on their relations with the neighborhood region (e.g., tiles, census block, ZIP code region, etc.). We then learn the neighborhood representation based on a contrastive-sampling scheme from the multi-graph. Specifically, we use street view images and POI features to characterize neighborhoods (nodes) and use human mobility to characterize the relationship between neighborhoods (directed edges). We show the effectiveness of the proposed methods with quantitative downstream tasks as well as qualitative analysis of the embedding space: The embedding we trained outperforms the ones using only unimodal data as regional inputs.
Quick Line Outage Identification in Urban Distribution Grids via Smart Meters
Apr 01, 2021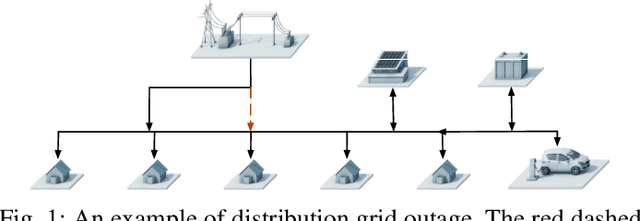

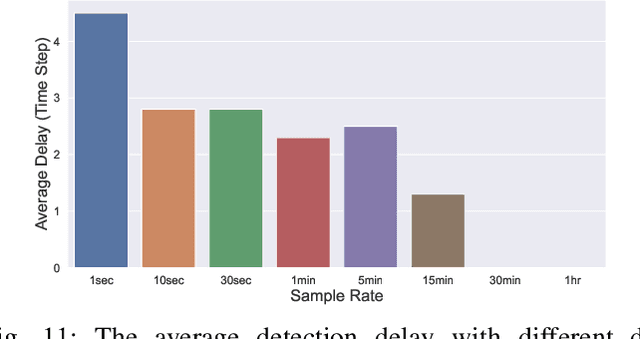
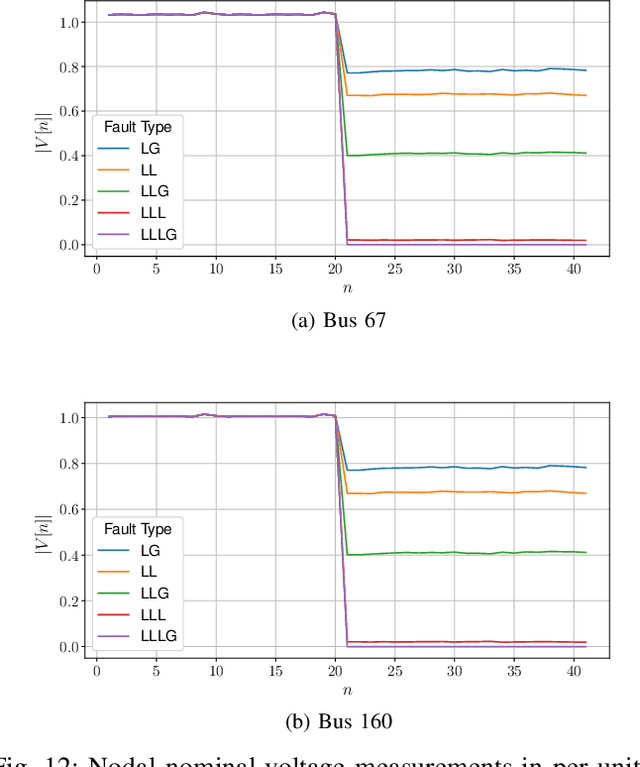
The growing integration of distributed energy resources (DERs) in distribution grids raises various reliability issues due to DER's uncertain and complex behaviors. With a large-scale DER penetration in distribution grids, traditional outage detection methods, which rely on customers report and smart meters' last gasp signals, will have poor performance, because the renewable generators and storages and the mesh structure in urban distribution grids can continue supplying power after line outages. To address these challenges, we propose a data-driven outage monitoring approach based on the stochastic time series analysis with a theoretical guarantee. Specifically, we prove via power flow analysis that the dependency of time-series voltage measurements exhibits significant statistical changes after line outages. This makes the theory on optimal change-point detection suitable to identify line outages. However, existing change point detection methods require post-outage voltage distribution, which is unknown in distribution systems. Therefore, we design a maximum likelihood estimator to directly learn the distribution parameters from voltage data. We prove that the estimated parameters-based detection also achieves the optimal performance, making it extremely useful for fast distribution grid outage identifications. Furthermore, since smart meters have been widely installed in distribution grids and advanced infrastructure (e.g., PMU) has not widely been available, our approach only requires voltage magnitude for quick outage identification. Simulation results show highly accurate outage identification in eight distribution grids with 14 configurations with and without DERs using smart meter data.
An Enriched Automated PV Registry: Combining Image Recognition and 3D Building Data
Dec 07, 2020
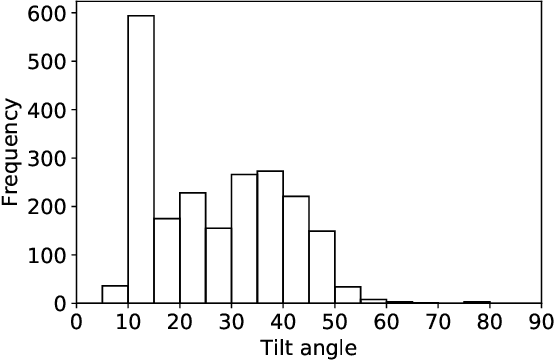

While photovoltaic (PV) systems are installed at an unprecedented rate, reliable information on an installation level remains scarce. As a result, automatically created PV registries are a timely contribution to optimize grid planning and operations. This paper demonstrates how aerial imagery and three-dimensional building data can be combined to create an address-level PV registry, specifying area, tilt, and orientation angles. We demonstrate the benefits of this approach for PV capacity estimation. In addition, this work presents, for the first time, a comparison between automated and officially-created PV registries. Our results indicate that our enriched automated registry proves to be useful to validate, update, and complement official registries.
Generating private data with user customization
Dec 02, 2020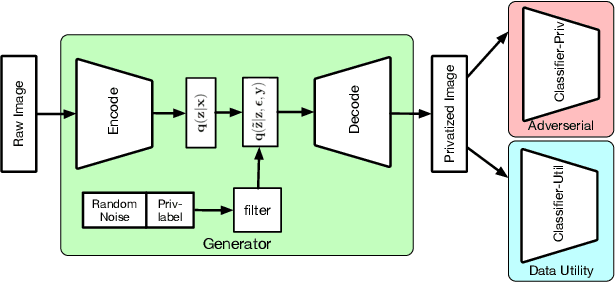



Personal devices such as mobile phones can produce and store large amounts of data that can enhance machine learning models; however, this data may contain private information specific to the data owner that prevents the release of the data. We want to reduce the correlation between user-specific private information and the data while retaining the useful information. Rather than training a large model to achieve privatization from end to end, we first decouple the creation of a latent representation, and then privatize the data that allows user-specific privatization to occur in a setting with limited computation and minimal disturbance on the utility of the data. We leverage a Variational Autoencoder (VAE) to create a compact latent representation of the data that remains fixed for all devices and all possible private labels. We then train a small generative filter to perturb the latent representation based on user specified preferences regarding the private and utility information. The small filter is trained via a GAN-type robust optimization that can take place on a distributed device such as a phone or tablet. Under special conditions of our linear filter, we disclose the connections between our generative approach and renyi differential privacy. We conduct experiments on multiple datasets including MNIST, UCI-Adult, and CelebA, and give a thorough evaluation including visualizing the geometry of the latent embeddings and estimating the empirical mutual information to show the effectiveness of our approach.
Activity Detection And Modeling Using Smart Meter Data: Concept And Case Studies
Oct 26, 2020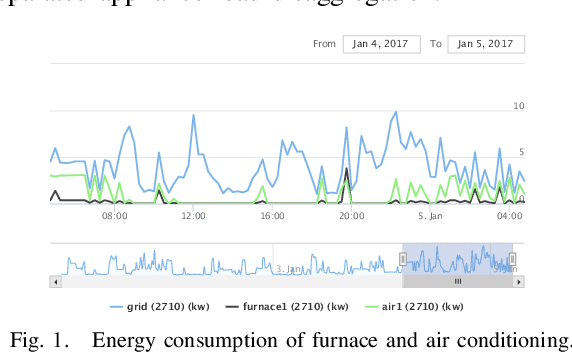
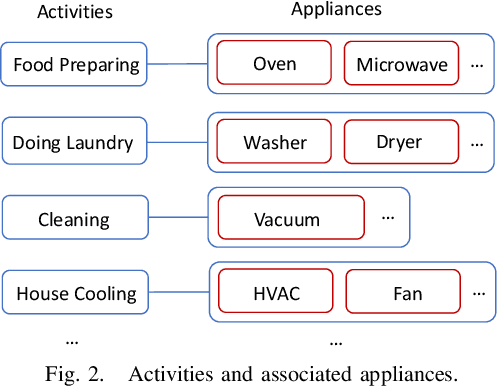
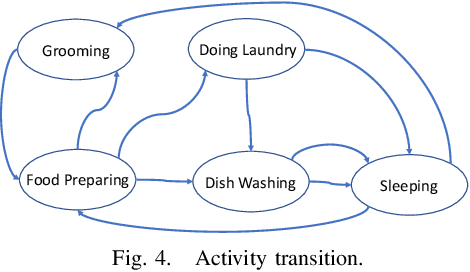
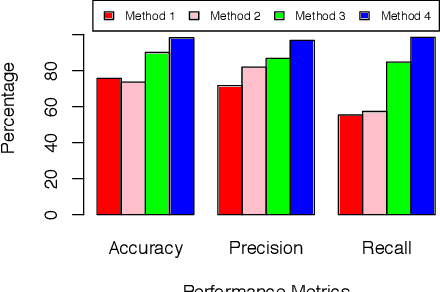
Electricity consumed by residential consumers counts for a significant part of global electricity consumption and utility companies can collect high-resolution load data thanks to the widely deployed advanced metering infrastructure. There has been a growing research interest toward appliance load disaggregation via nonintrusive load monitoring. As the electricity consumption of appliances is directly associated with the activities of consumers, this paper proposes a new and more effective approach, i.e., activity disaggregation. We present the concept of activity disaggregation and discuss its advantage over traditional appliance load disaggregation. We develop a framework by leverage machine learning for activity detection based on residential load data and features. We show through numerical case studies to demonstrate the effectiveness of the activity detection method and analyze consumer behaviors by time-dependent activity modeling. Last but not least, we discuss some potential use cases that can benefit from activity disaggregation and some future research directions.
Short-Term Solar Irradiance Forecasting Using Calibrated Probabilistic Models
Oct 14, 2020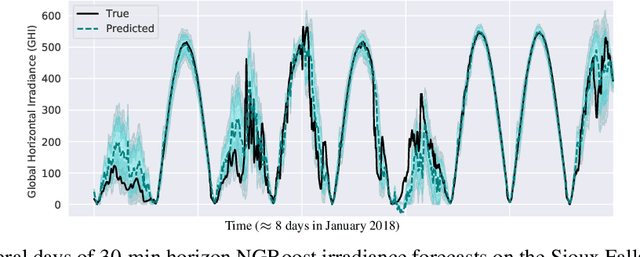
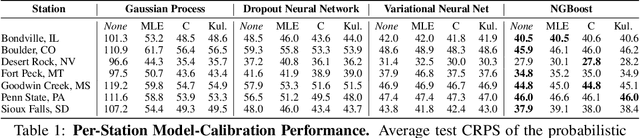
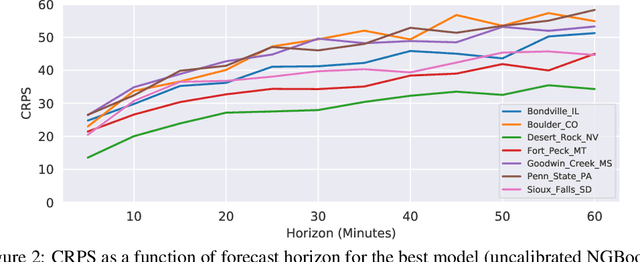
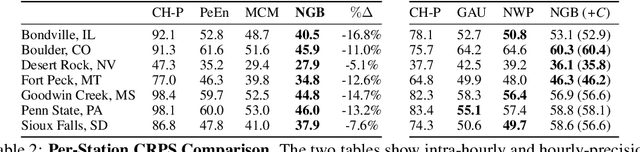
Advancing probabilistic solar forecasting methods is essential to supporting the integration of solar energy into the electricity grid. In this work, we develop a variety of state-of-the-art probabilistic models for forecasting solar irradiance. We investigate the use of post-hoc calibration techniques for ensuring well-calibrated probabilistic predictions. We train and evaluate the models using public data from seven stations in the SURFRAD network, and demonstrate that the best model, NGBoost, achieves higher performance at an intra-hourly resolution than the best benchmark solar irradiance forecasting model across all stations. Further, we show that NGBoost with CRUDE post-hoc calibration achieves comparable performance to a numerical weather prediction model on hourly-resolution forecasting.
FedGAN: Federated Generative Adversarial Networks for Distributed Data
Jun 15, 2020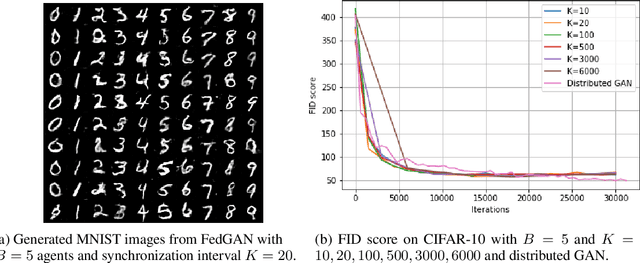
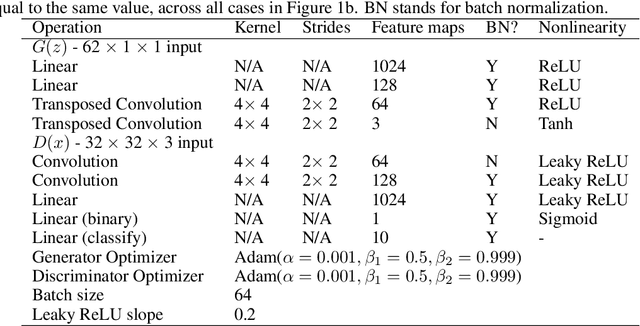
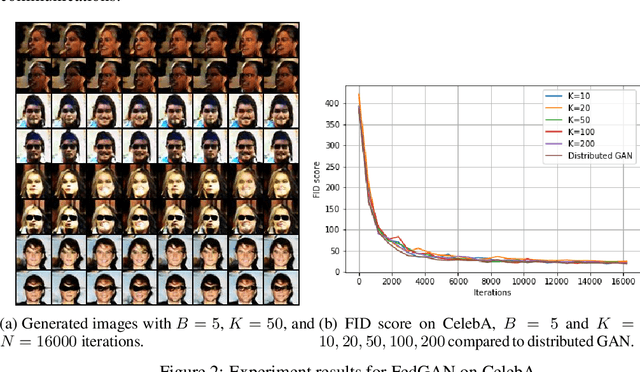
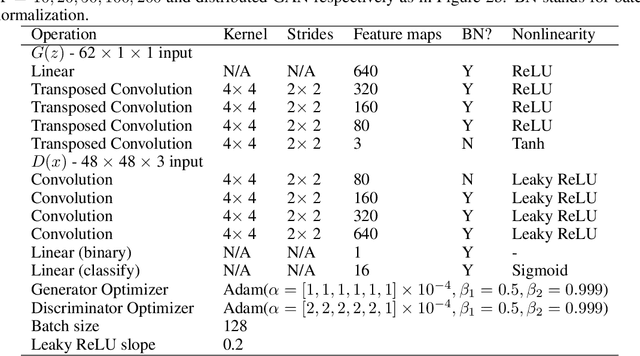
We propose Federated Generative Adversarial Network (FedGAN) for training a GAN across distributed sources of non-independent-and-identically-distributed data sources subject to communication and privacy constraints. Our algorithm uses local generators and discriminators which are periodically synced via an intermediary that averages and broadcasts the generator and discriminator parameters. We theoretically prove the convergence of FedGAN with both equal and two time-scale updates of generator and discriminator, under standard assumptions, using stochastic approximations and communication efficient stochastic gradient descents. We experiment FedGAN on toy examples (2D system, mixed Gaussian, and Swiss role), image datasets (MNIST, CIFAR-10, and CelebA), and time series datasets (household electricity consumption and electric vehicle charging sessions). We show FedGAN converges and has similar performance to general distributed GAN, while reduces communication complexity. We also show its robustness to reduced communications.
Effective Data Fusion with Generalized Vegetation Index: Evidence from Land Cover Segmentation in Agriculture
May 07, 2020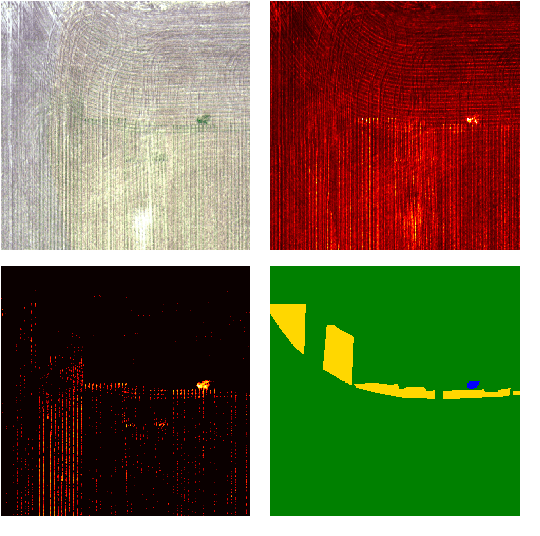

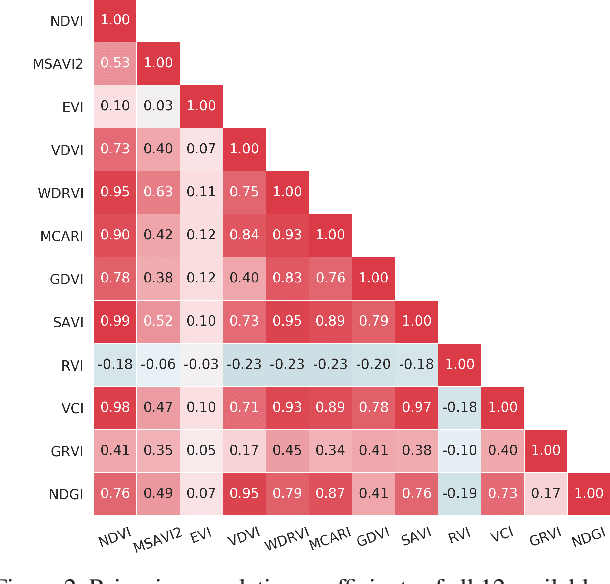
How can we effectively leverage the domain knowledge from remote sensing to better segment agriculture land cover from satellite images? In this paper, we propose a novel, model-agnostic, data-fusion approach for vegetation-related computer vision tasks. Motivated by the various Vegetation Indices (VIs), which are introduced by domain experts, we systematically reviewed the VIs that are widely used in remote sensing and their feasibility to be incorporated in deep neural networks. To fully leverage the Near-Infrared channel, the traditional Red-Green-Blue channels, and Vegetation Index or its variants, we propose a Generalized Vegetation Index (GVI), a lightweight module that can be easily plugged into many neural network architectures to serve as an additional information input. To smoothly train models with our GVI, we developed an Additive Group Normalization (AGN) module that does not require extra parameters of the prescribed neural networks. Our approach has improved the IoUs of vegetation-related classes by 0.9-1.3 percent and consistently improves the overall mIoU by 2 percent on our baseline.
The 1st Agriculture-Vision Challenge: Methods and Results
Apr 23, 2020
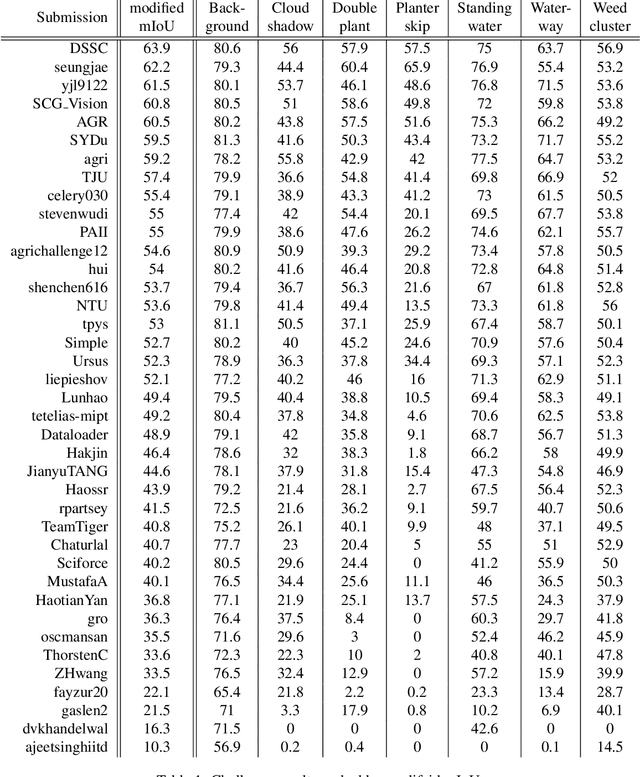
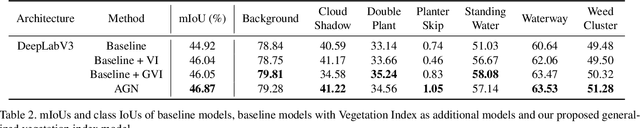
The first Agriculture-Vision Challenge aims to encourage research in developing novel and effective algorithms for agricultural pattern recognition from aerial images, especially for the semantic segmentation task associated with our challenge dataset. Around 57 participating teams from various countries compete to achieve state-of-the-art in aerial agriculture semantic segmentation. The Agriculture-Vision Challenge Dataset was employed, which comprises of 21,061 aerial and multi-spectral farmland images. This paper provides a summary of notable methods and results in the challenge. Our submission server and leaderboard will continue to open for researchers that are interested in this challenge dataset and task; the link can be found here.
Urban2Vec: Incorporating Street View Imagery and POIs for Multi-Modal Urban Neighborhood Embedding
Jan 29, 2020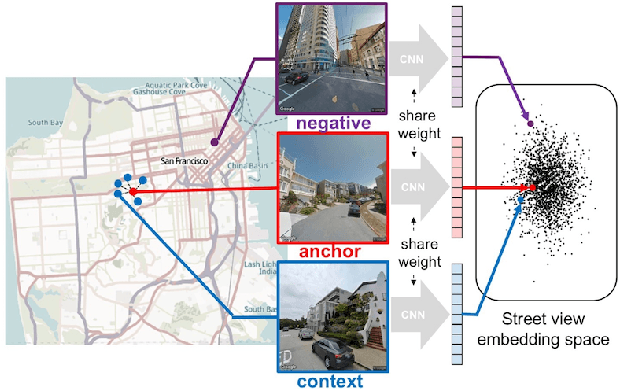
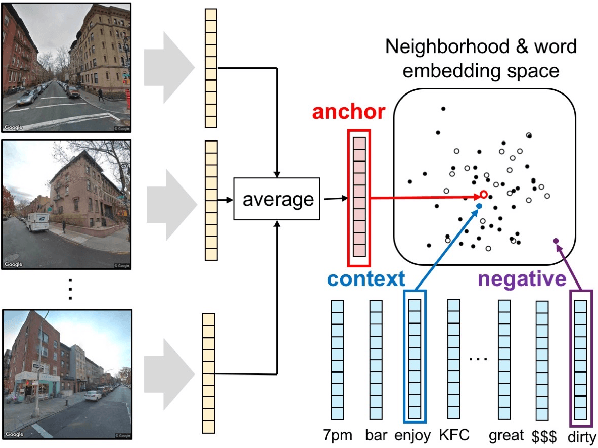
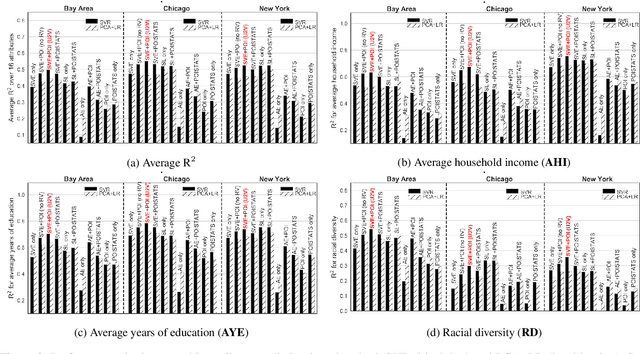
Understanding intrinsic patterns and predicting spatiotemporal characteristics of cities require a comprehensive representation of urban neighborhoods. Existing works relied on either inter- or intra-region connectivities to generate neighborhood representations but failed to fully utilize the informative yet heterogeneous data within neighborhoods. In this work, we propose Urban2Vec, an unsupervised multi-modal framework which incorporates both street view imagery and point-of-interest (POI) data to learn neighborhood embeddings. Specifically, we use a convolutional neural network to extract visual features from street view images while preserving geospatial similarity. Furthermore, we model each POI as a bag-of-words containing its category, rating, and review information. Analog to document embedding in natural language processing, we establish the semantic similarity between neighborhood ("document") and the words from its surrounding POIs in the vector space. By jointly encoding visual, textual, and geospatial information into the neighborhood representation, Urban2Vec can achieve performances better than baseline models and comparable to fully-supervised methods in downstream prediction tasks. Extensive experiments on three U.S. metropolitan areas also demonstrate the model interpretability, generalization capability, and its value in neighborhood similarity analysis.