 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking Distributional Alignment of Large Language Models
Nov 08, 2024



Language models (LMs) are increasingly used as simulacra for people, yet their ability to match the distribution of views of a specific demographic group and be \textit{distributionally aligned} remains uncertain. This notion of distributional alignment is complex, as there is significant variation in the types of attributes that are simulated. Prior works have underexplored the role of three critical variables -- the question domain, steering method, and distribution expression method -- which motivates our contribution of a benchmark explicitly addressing these dimensions. We construct a dataset expanding beyond political values, create human baselines for this task, and evaluate the extent to which an LM can align with a particular group's opinion distribution to inform design choices of such simulation systems. Our analysis reveals open problems regarding if, and how, LMs can be used to simulate humans, and that LLMs can more accurately describe the opinion distribution than simulate such distributions.
Unifying Corroborative and Contributive Attributions in Large Language Models
Nov 20, 2023As businesses, products, and services spring up around large language models, the trustworthiness of these models hinges on the verifiability of their outputs. However, methods for explaining language model outputs largely fall across two distinct fields of study which both use the term "attribution" to refer to entirely separate techniques: citation generation and training data attribution. In many modern applications, such as legal document generation and medical question answering, both types of attributions are important. In this work, we argue for and present a unified framework of large language model attributions. We show how existing methods of different types of attribution fall under the unified framework. We also use the framework to discuss real-world use cases where one or both types of attributions are required. We believe that this unified framework will guide the use case driven development of systems that leverage both types of attribution, as well as the standardization of their evaluation.
Proving Test Set Contamination in Black Box Language Models
Oct 26, 2023Large language models are trained on vast amounts of internet data, prompting concerns and speculation that they have memorized public benchmarks. Going from speculation to proof of contamination is challenging, as the pretraining data used by proprietary models are often not publicly accessible. We show that it is possible to provide provable guarantees of test set contamination in language models without access to pretraining data or model weights. Our approach leverages the fact that when there is no data contamination, all orderings of an exchangeable benchmark should be equally likely. In contrast, the tendency for language models to memorize example order means that a contaminated language model will find certain canonical orderings to be much more likely than others. Our test flags potential contamination whenever the likelihood of a canonically ordered benchmark dataset is significantly higher than the likelihood after shuffling the examples. We demonstrate that our procedure is sensitive enough to reliably prove test set contamination in challenging situations, including models as small as 1.4 billion parameters, on small test sets of only 1000 examples, and datasets that appear only a few times in the pretraining corpus. Using our test, we audit five popular publicly accessible language models for test set contamination and find little evidence for pervasive contamination.
Improving Keyphrase Extraction with Data Augmentation and Information Filtering
Sep 11, 2022


Keyphrase extraction is one of the essential tasks for document understanding in NLP. While the majority of the prior works are dedicated to the formal setting, e.g., books, news or web-blogs, informal texts such as video transcripts are less explored. To address this limitation, in this work we present a novel corpus and method for keyphrase extraction from the transcripts of the videos streamed on the Behance platform. More specifically, in this work, a novel data augmentation is proposed to enrich the model with the background knowledge about the keyphrase extraction task from other domains. Extensive experiments on the proposed dataset dataset show the effectiveness of the introduced method.
Gender Artifacts in Visual Datasets
Jun 18, 2022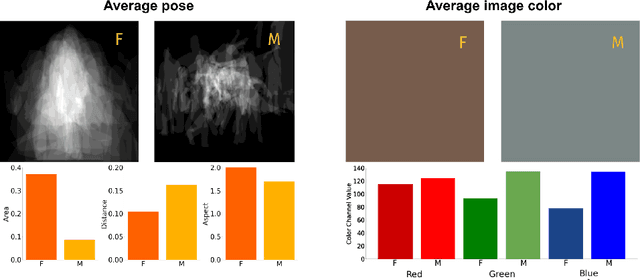

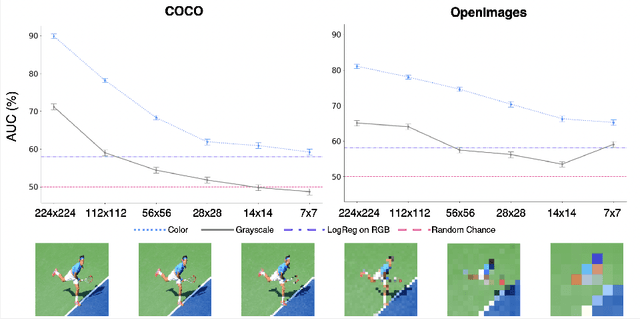
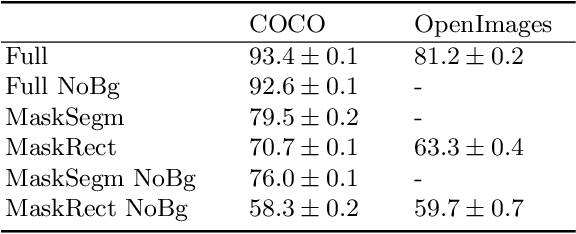
Gender biases are known to exist within large-scale visual datasets and can be reflected or even amplified in downstream models. Many prior works have proposed methods for mitigating gender biases, often by attempting to remove gender expression information from images. To understand the feasibility and practicality of these approaches, we investigate what $\textit{gender artifacts}$ exist within large-scale visual datasets. We define a $\textit{gender artifact}$ as a visual cue that is correlated with gender, focusing specifically on those cues that are learnable by a modern image classifier and have an interpretable human corollary. Through our analyses, we find that gender artifacts are ubiquitous in the COCO and OpenImages datasets, occurring everywhere from low-level information (e.g., the mean value of the color channels) to the higher-level composition of the image (e.g., pose and location of people). Given the prevalence of gender artifacts, we claim that attempts to remove gender artifacts from such datasets are largely infeasible. Instead, the responsibility lies with researchers and practitioners to be aware that the distribution of images within datasets is highly gendered and hence develop methods which are robust to these distributional shifts across groups.
ELUDE: Generating interpretable explanations via a decomposition into labelled and unlabelled features
Jun 16, 2022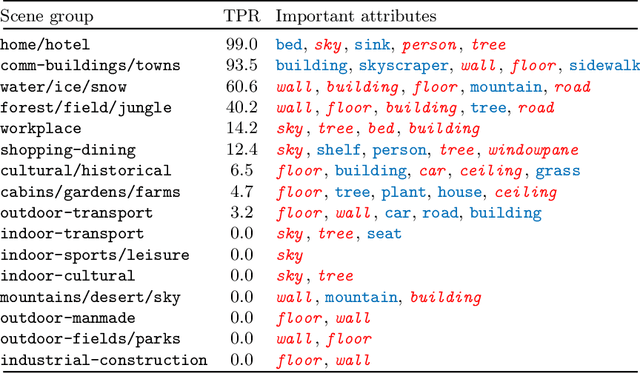
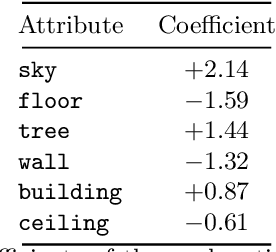

Deep learning models have achieved remarkable success in different areas of machine learning over the past decade; however, the size and complexity of these models make them difficult to understand. In an effort to make them more interpretable, several recent works focus on explaining parts of a deep neural network through human-interpretable, semantic attributes. However, it may be impossible to completely explain complex models using only semantic attributes. In this work, we propose to augment these attributes with a small set of uninterpretable features. Specifically, we develop a novel explanation framework ELUDE (Explanation via Labelled and Unlabelled DEcomposition) that decomposes a model's prediction into two parts: one that is explainable through a linear combination of the semantic attributes, and another that is dependent on the set of uninterpretable features. By identifying the latter, we are able to analyze the "unexplained" portion of the model, obtaining insights into the information used by the model. We show that the set of unlabelled features can generalize to multiple models trained with the same feature space and compare our work to two popular attribute-oriented methods, Interpretable Basis Decomposition and Concept Bottleneck, and discuss the additional insights ELUDE provides.
MACRONYM: A Large-Scale Dataset for Multilingual and Multi-Domain Acronym Extraction
Feb 19, 2022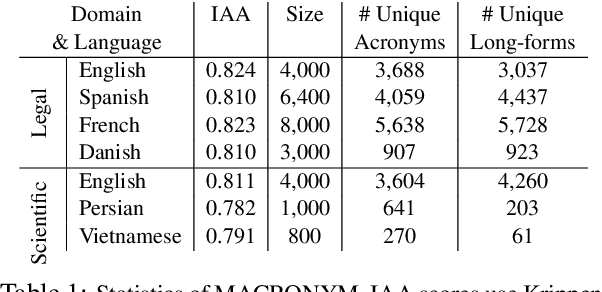
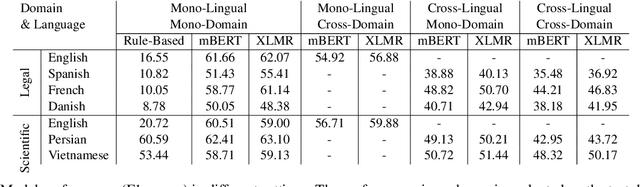
Acronym extraction is the task of identifying acronyms and their expanded forms in texts that is necessary for various NLP applications. Despite major progress for this task in recent years, one limitation of existing AE research is that they are limited to the English language and certain domains (i.e., scientific and biomedical). As such, challenges of AE in other languages and domains is mainly unexplored. Lacking annotated datasets in multiple languages and domains has been a major issue to hinder research in this area. To address this limitation, we propose a new dataset for multilingual multi-domain AE. Specifically, 27,200 sentences in 6 typologically different languages and 2 domains, i.e., Legal and Scientific, is manually annotated for AE. Our extensive experiments on the proposed dataset show that AE in different languages and different learning settings has unique challenges, emphasizing the necessity of further research on multilingual and multi-domain AE.
HIVE: Evaluating the Human Interpretability of Visual Explanations
Jan 10, 2022
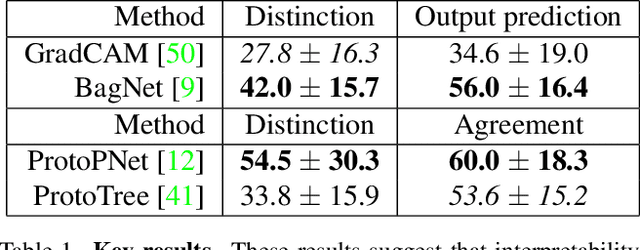

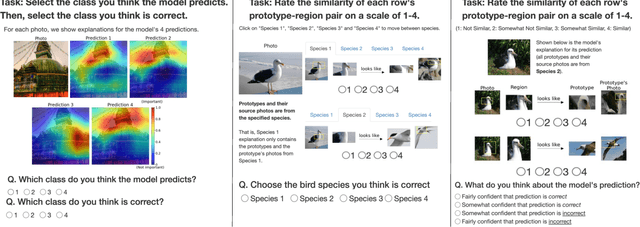
As machine learning is increasingly applied to high-impact, high-risk domains, there have been a number of new methods aimed at making AI models more human interpretable. Despite the recent growth of interpretability work, there is a lack of systematic evaluation of proposed techniques. In this work, we propose a novel human evaluation framework HIVE (Human Interpretability of Visual Explanations) for diverse interpretability methods in computer vision; to the best of our knowledge, this is the first work of its kind. We argue that human studies should be the gold standard in properly evaluating how interpretable a method is to human users. While human studies are often avoided due to challenges associated with cost, study design, and cross-method comparison, we describe how our framework mitigates these issues and conduct IRB-approved studies of four methods that represent the diversity of interpretability works: GradCAM, BagNet, ProtoPNet, and ProtoTree. Our results suggest that explanations (regardless of if they are actually correct) engender human trust, yet are not distinct enough for users to distinguish between correct and incorrect predictions. Lastly, we also open-source our framework to enable future studies and to encourage more human-centered approaches to interpretability.
Don't Judge an Object by Its Context: Learning to Overcome Contextual Bias
Apr 28, 2021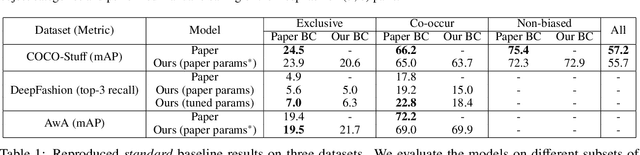

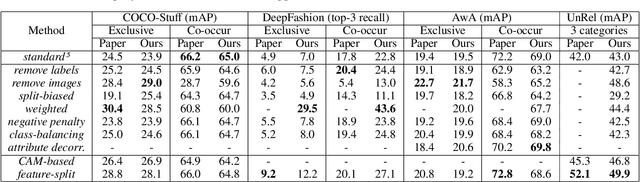
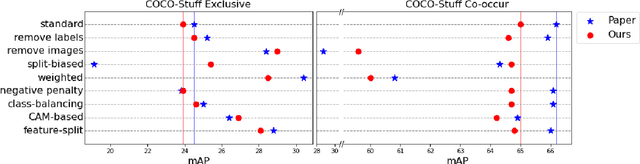
Singh et al. (2020) point out the dangers of contextual bias in visual recognition datasets. They propose two methods, CAM-based and feature-split, that better recognize an object or attribute in the absence of its typical context while maintaining competitive within-context accuracy. To verify their performance, we attempted to reproduce all 12 tables in the original paper, including those in the appendix. We also conducted additional experiments to better understand the proposed methods, including increasing the regularization in CAM-based and removing the weighted loss in feature-split. As the original code was not made available, we implemented the entire pipeline from scratch in PyTorch 1.7.0. Our implementation is based on the paper and email exchanges with the authors. We found that both proposed methods in the original paper help mitigate contextual bias, although for some methods, we could not completely replicate the quantitative results in the paper even after completing an extensive hyperparameter search. For example, on COCO-Stuff, DeepFashion, and UnRel, our feature-split model achieved an increase in accuracy on out-of-context images over the standard baseline, whereas on AwA, we saw a drop in performance. For the proposed CAM-based method, we were able to reproduce the original paper's results to within 0.5$\%$ mAP. Our implementation can be found at https://github.com/princetonvisualai/ContextualBias.