 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMEMENTO: Leveraging Web as a Learning Signal for Low-Data Domains
May 28, 2026Real-world tasks often lack large labeled datasets, motivating extensive work on learning in low-data regimes. However, existing approaches such as few-shot prompting, instruction tuning, and synthetic data generation, continue to treat labeled or pseudo-labeled data as the primary learning signal. In contrast, human practitioners acquire expertise through repeated, self-directed interaction with the open web, progressively refining both domain knowledge and search strategies. We propose MEMENTO, a framework that treats the web as a learning signal rather than a stateless retrieval interface. MEMENTO operates at two levels: within each session, it conducts iterative web exploration via an Adaptive Exploration Tree (AET) that decomposes tasks into evolving questions and reflects on intermediate findings; across sessions, it accumulates experience through dual-channel memory, separating declarative knowledge (facts) from procedural knowledge (search strategies). This design enables agents to learn reusable research strategies and domain expertise from trajectories of web interaction without additional model training. We evaluate MEMENTO on two low-data professional domains: sales automation and legal research. Our empirical results show consistent improvements in performance over ReAct based baselines (+25.6% on sales automation and 36.5% on legal research), demonstrating that the web can serve as a scalable learning source for acquiring task-specific expertise in data-scarce settings.
CLAUSEREC: A Clause Recommendation Framework for AI-aided Contract Authoring
Oct 26, 2021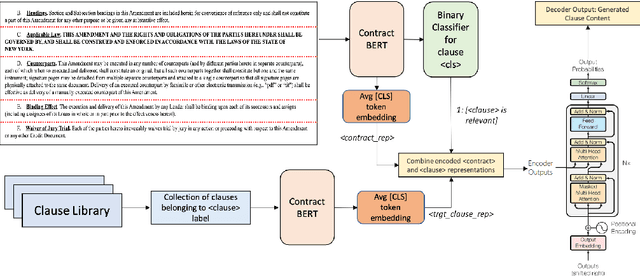
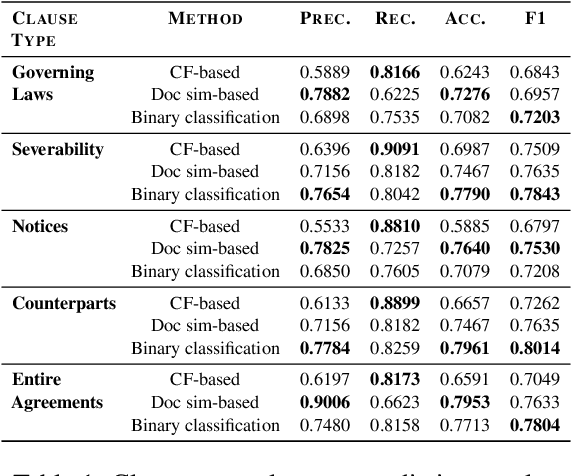
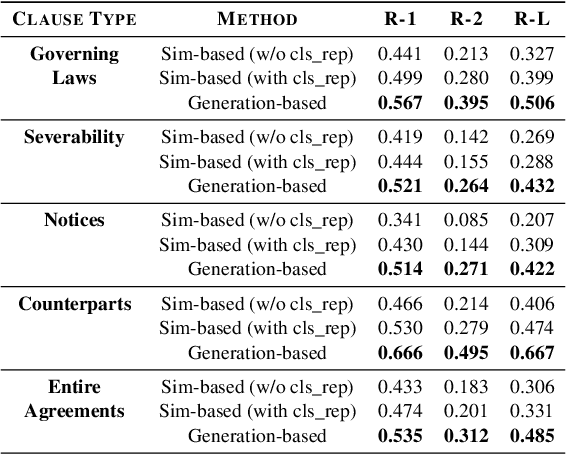
Contracts are a common type of legal document that frequent in several day-to-day business workflows. However, there has been very limited NLP research in processing such documents, and even lesser in generating them. These contracts are made up of clauses, and the unique nature of these clauses calls for specific methods to understand and generate such documents. In this paper, we introduce the task of clause recommendation, asa first step to aid and accelerate the author-ing of contract documents. We propose a two-staged pipeline to first predict if a specific clause type is relevant to be added in a contract, and then recommend the top clauses for the given type based on the contract context. We pretrain BERT on an existing library of clauses with two additional tasks and use it for our prediction and recommendation. We experiment with classification methods and similarity-based heuristics for clause relevance prediction, and generation-based methods for clause recommendation, and evaluate the results from various methods on several clause types. We provide analyses on the results, and further outline the advantages and limitations of the various methods for this line of research.
Federated Learning with Personalization Layers
Dec 02, 2019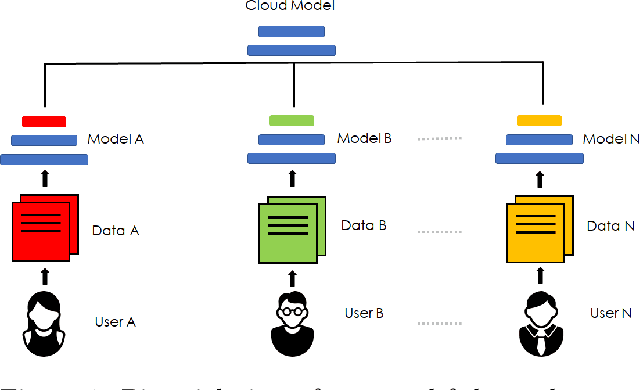
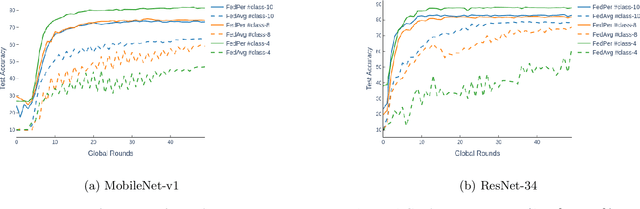
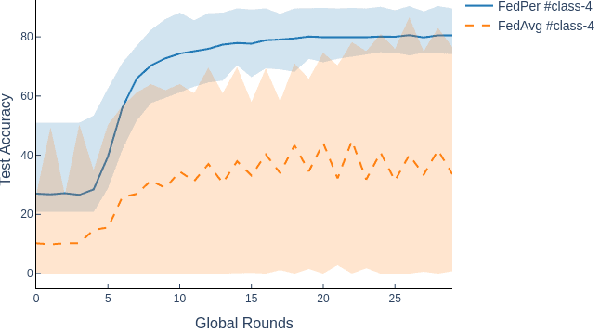
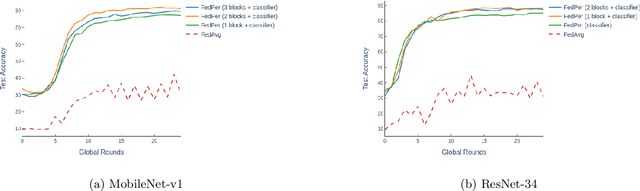
The emerging paradigm of federated learning strives to enable collaborative training of machine learning models on the network edge without centrally aggregating raw data and hence, improving data privacy. This sharply deviates from traditional machine learning and necessitates the design of algorithms robust to various sources of heterogeneity. Specifically, statistical heterogeneity of data across user devices can severely degrade the performance of standard federated averaging for traditional machine learning applications like personalization with deep learning. This paper pro-posesFedPer, a base + personalization layer approach for federated training of deep feedforward neural networks, which can combat the ill-effects of statistical heterogeneity. We demonstrate effectiveness ofFedPerfor non-identical data partitions ofCIFARdatasetsand on a personalized image aesthetics dataset from Flickr.