 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Multilingual Representation for Natural Language Understanding with Enhanced Cross-Lingual Supervision
Jun 09, 2021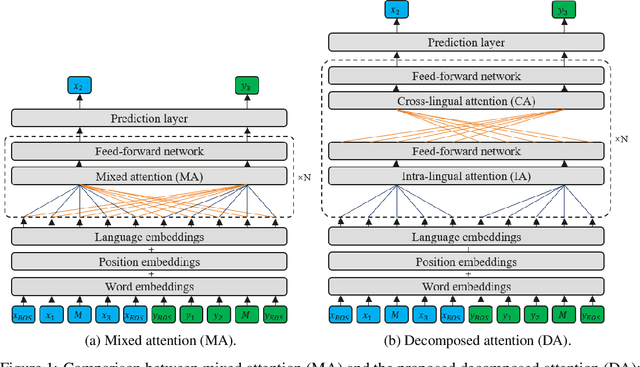

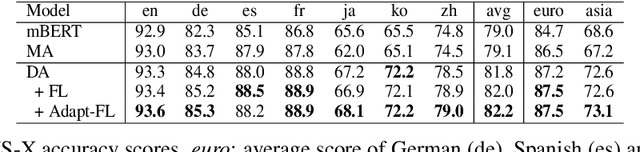
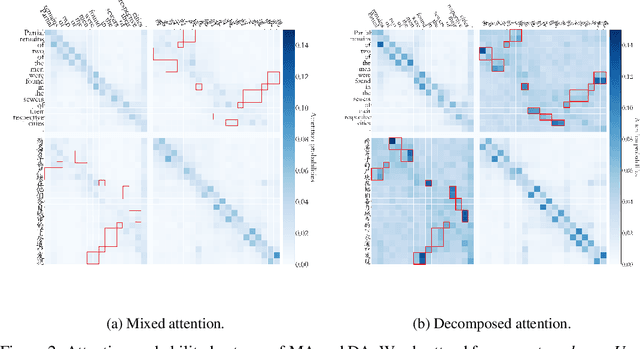
Recently, pre-training multilingual language models has shown great potential in learning multilingual representation, a crucial topic of natural language processing. Prior works generally use a single mixed attention (MA) module, following TLM (Conneau and Lample, 2019), for attending to intra-lingual and cross-lingual contexts equivalently and simultaneously. In this paper, we propose a network named decomposed attention (DA) as a replacement of MA. The DA consists of an intra-lingual attention (IA) and a cross-lingual attention (CA), which model intralingual and cross-lingual supervisions respectively. In addition, we introduce a language-adaptive re-weighting strategy during training to further boost the model's performance. Experiments on various cross-lingual natural language understanding (NLU) tasks show that the proposed architecture and learning strategy significantly improve the model's cross-lingual transferability.
RealTranS: End-to-End Simultaneous Speech Translation with Convolutional Weighted-Shrinking Transformer
Jun 09, 2021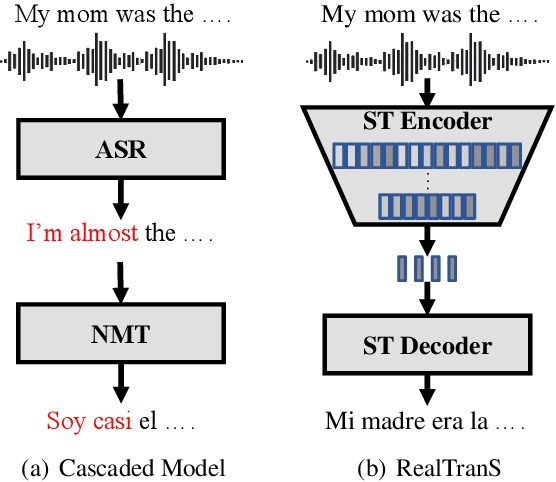
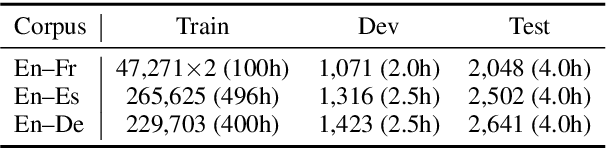
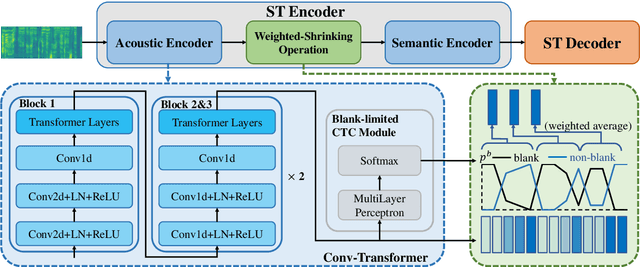

End-to-end simultaneous speech translation (SST), which directly translates speech in one language into text in another language in real-time, is useful in many scenarios but has not been fully investigated. In this work, we propose RealTranS, an end-to-end model for SST. To bridge the modality gap between speech and text, RealTranS gradually downsamples the input speech with interleaved convolution and unidirectional Transformer layers for acoustic modeling, and then maps speech features into text space with a weighted-shrinking operation and a semantic encoder. Besides, to improve the model performance in simultaneous scenarios, we propose a blank penalty to enhance the shrinking quality and a Wait-K-Stride-N strategy to allow local reranking during decoding. Experiments on public and widely-used datasets show that RealTranS with the Wait-K-Stride-N strategy outperforms prior end-to-end models as well as cascaded models in diverse latency settings.
HyKnow: End-to-End Task-Oriented Dialog Modeling with Hybrid Knowledge Management
Jun 02, 2021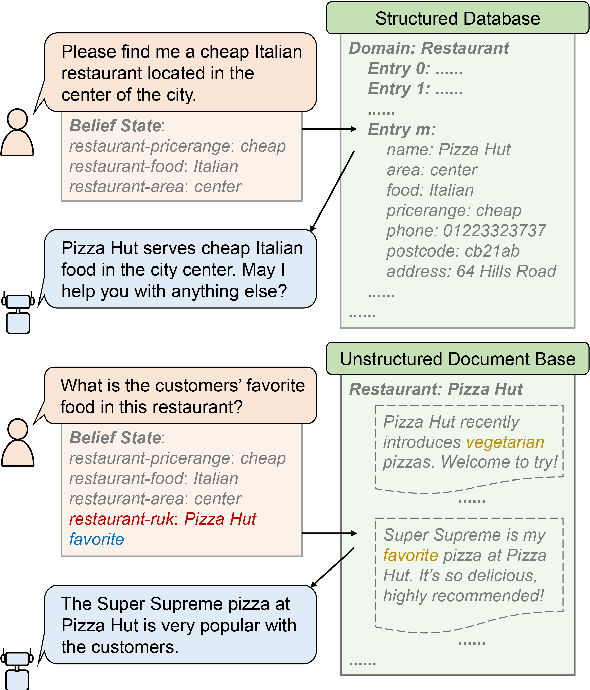
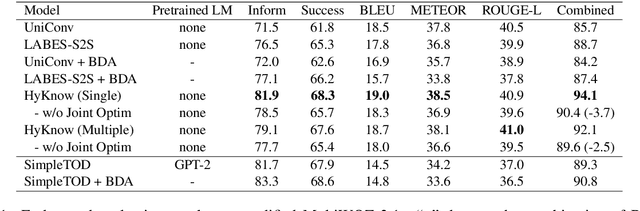
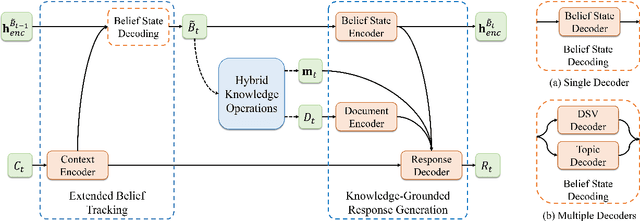
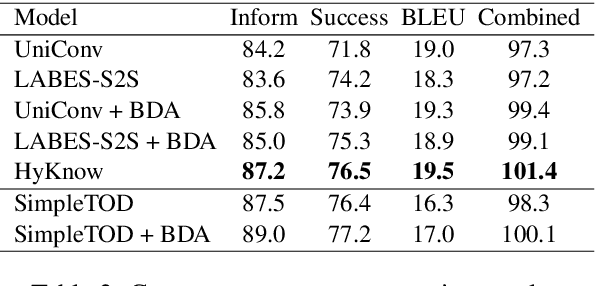
Task-oriented dialog (TOD) systems typically manage structured knowledge (e.g. ontologies and databases) to guide the goal-oriented conversations. However, they fall short of handling dialog turns grounded on unstructured knowledge (e.g. reviews and documents). In this paper, we formulate a task of modeling TOD grounded on both structured and unstructured knowledge. To address this task, we propose a TOD system with hybrid knowledge management, HyKnow. It extends the belief state to manage both structured and unstructured knowledge, and is the first end-to-end model that jointly optimizes dialog modeling grounded on these two kinds of knowledge. We conduct experiments on the modified version of MultiWOZ 2.1 dataset, where dialogs are grounded on hybrid knowledge. Experimental results show that HyKnow has strong end-to-end performance compared to existing TOD systems. It also outperforms the pipeline knowledge management schemes, with higher unstructured knowledge retrieval accuracy.
Improved OOD Generalization via Adversarial Training and Pre-training
May 24, 2021
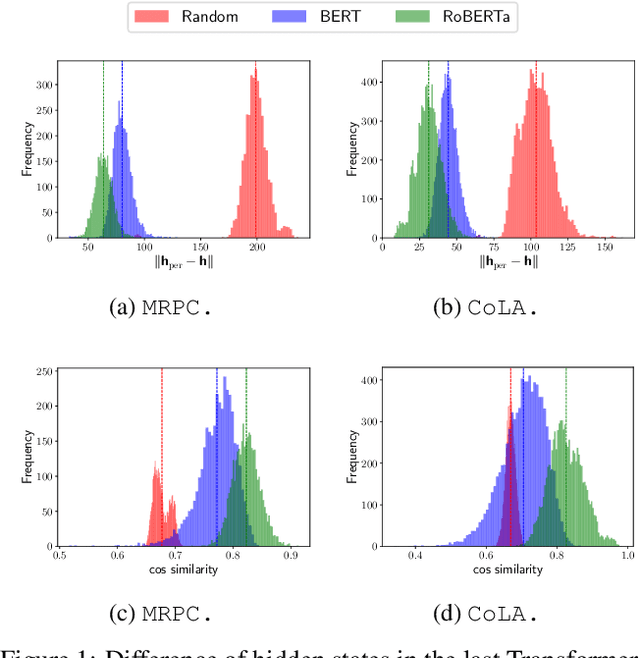
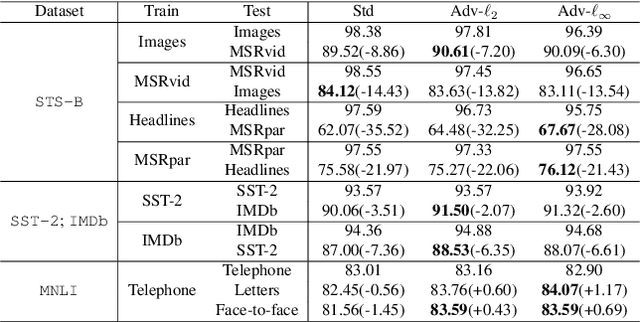
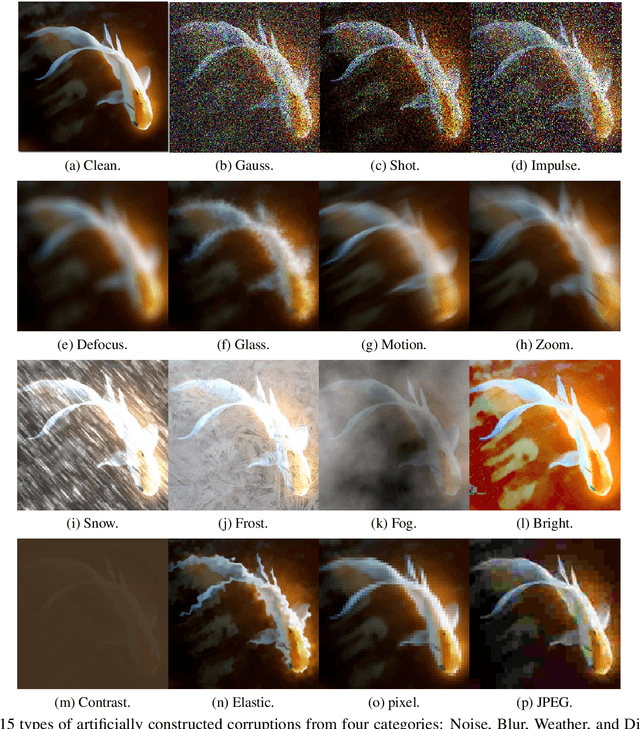
Recently, learning a model that generalizes well on out-of-distribution (OOD) data has attracted great attention in the machine learning community. In this paper, after defining OOD generalization via Wasserstein distance, we theoretically show that a model robust to input perturbation generalizes well on OOD data. Inspired by previous findings that adversarial training helps improve input-robustness, we theoretically show that adversarially trained models have converged excess risk on OOD data, and empirically verify it on both image classification and natural language understanding tasks. Besides, in the paradigm of first pre-training and then fine-tuning, we theoretically show that a pre-trained model that is more robust to input perturbation provides a better initialization for generalization on downstream OOD data. Empirically, after fine-tuning, this better-initialized model from adversarial pre-training also has better OOD generalization.
PanGu-$α$: Large-scale Autoregressive Pretrained Chinese Language Models with Auto-parallel Computation
Apr 26, 2021
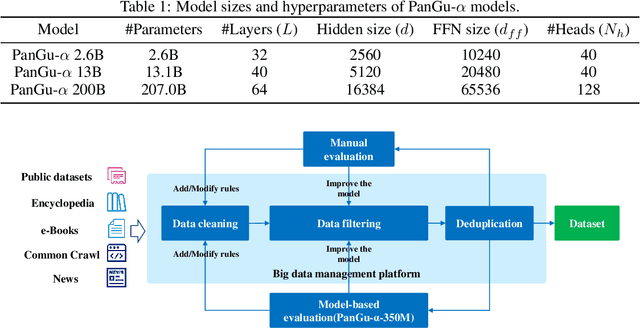
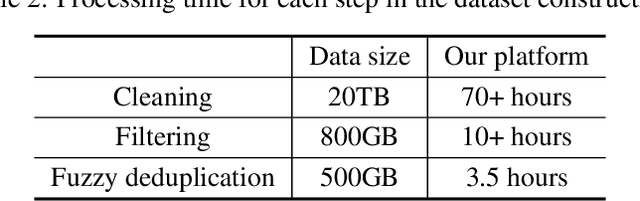
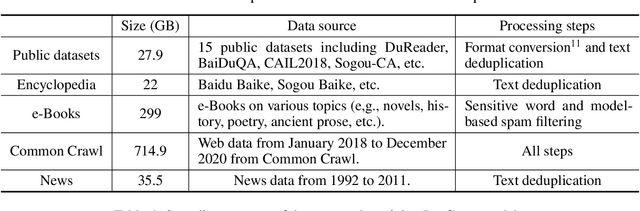
Large-scale Pretrained Language Models (PLMs) have become the new paradigm for Natural Language Processing (NLP). PLMs with hundreds of billions parameters such as GPT-3 have demonstrated strong performances on natural language understanding and generation with \textit{few-shot in-context} learning. In this work, we present our practice on training large-scale autoregressive language models named PanGu-$\alpha$, with up to 200 billion parameters. PanGu-$\alpha$ is developed under the MindSpore and trained on a cluster of 2048 Ascend 910 AI processors. The training parallelism strategy is implemented based on MindSpore Auto-parallel, which composes five parallelism dimensions to scale the training task to 2048 processors efficiently, including data parallelism, op-level model parallelism, pipeline model parallelism, optimizer model parallelism and rematerialization. To enhance the generalization ability of PanGu-$\alpha$, we collect 1.1TB high-quality Chinese data from a wide range of domains to pretrain the model. We empirically test the generation ability of PanGu-$\alpha$ in various scenarios including text summarization, question answering, dialogue generation, etc. Moreover, we investigate the effect of model scales on the few-shot performances across a broad range of Chinese NLP tasks. The experimental results demonstrate the superior capabilities of PanGu-$\alpha$ in performing various tasks under few-shot or zero-shot settings.
Extract then Distill: Efficient and Effective Task-Agnostic BERT Distillation
Apr 24, 2021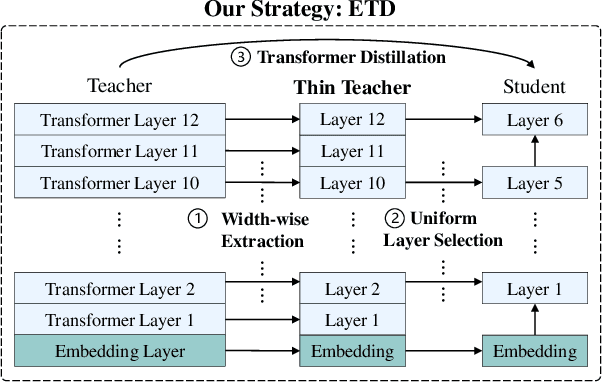
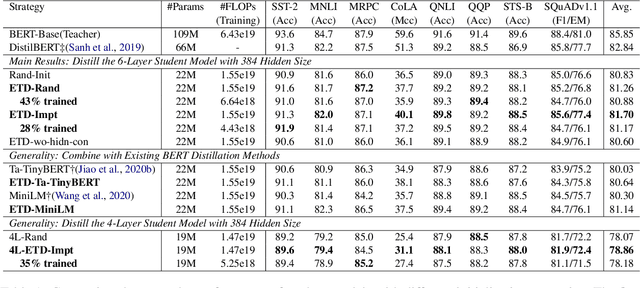
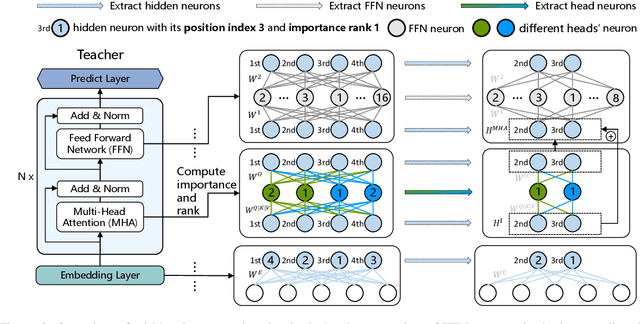
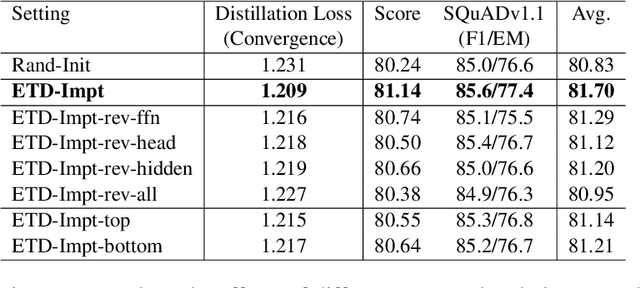
Task-agnostic knowledge distillation, a teacher-student framework, has been proved effective for BERT compression. Although achieving promising results on NLP tasks, it requires enormous computational resources. In this paper, we propose Extract Then Distill (ETD), a generic and flexible strategy to reuse the teacher's parameters for efficient and effective task-agnostic distillation, which can be applied to students of any size. Specifically, we introduce two variants of ETD, ETD-Rand and ETD-Impt, which extract the teacher's parameters in a random manner and by following an importance metric respectively. In this way, the student has already acquired some knowledge at the beginning of the distillation process, which makes the distillation process converge faster. We demonstrate the effectiveness of ETD on the GLUE benchmark and SQuAD. The experimental results show that: (1) compared with the baseline without an ETD strategy, ETD can save 70\% of computation cost. Moreover, it achieves better results than the baseline when using the same computing resource. (2) ETD is generic and has been proven effective for different distillation methods (e.g., TinyBERT and MiniLM) and students of different sizes. The source code will be publicly available upon publication.
Improving Neural Machine Translation with Compact Word Embedding Tables
Apr 18, 2021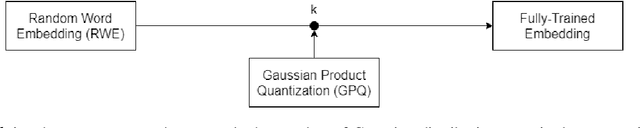
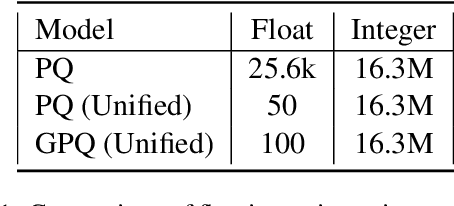
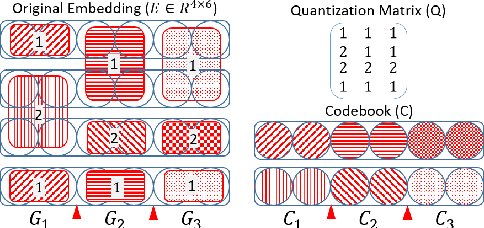
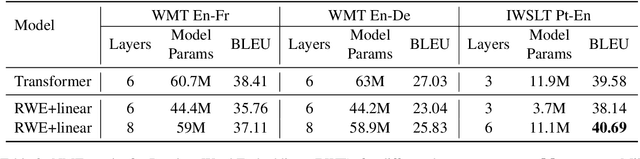
Embedding matrices are key components in neural natural language processing (NLP) models that are responsible to provide numerical representations of input tokens.\footnote{In this paper words and subwords are referred to as \textit{tokens} and the term \textit{embedding} only refers to embeddings of inputs.} In this paper, we analyze the impact and utility of such matrices in the context of neural machine translation (NMT). We show that detracting syntactic and semantic information from word embeddings and running NMT systems with random embeddings is not as damaging as it initially sounds. We also show how incorporating only a limited amount of task-specific knowledge from fully-trained embeddings can boost the performance NMT systems. Our findings demonstrate that in exchange for negligible deterioration in performance, any NMT model can be run with partially random embeddings. Working with such structures means a minimal memory requirement as there is no longer need to store large embedding tables, which is a significant gain in industrial and on-device settings. We evaluated our embeddings in translating {English} into {German} and {French} and achieved a $5.3$x compression rate. Despite having a considerably smaller architecture, our models in some cases are even able to outperform state-of-the-art baselines.
An Approach to Improve Robustness of NLP Systems against ASR Errors
Mar 25, 2021
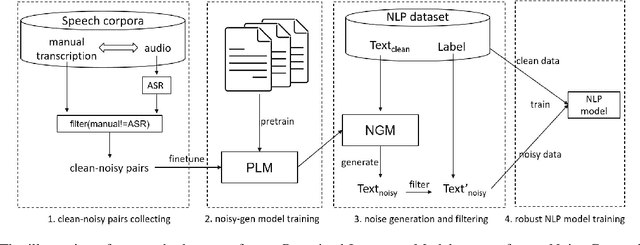


Speech-enabled systems typically first convert audio to text through an automatic speech recognition (ASR) model and then feed the text to downstream natural language processing (NLP) modules. The errors of the ASR system can seriously downgrade the performance of the NLP modules. Therefore, it is essential to make them robust to the ASR errors. Previous work has shown it is effective to employ data augmentation methods to solve this problem by injecting ASR noise during the training process. In this paper, we utilize the prevalent pre-trained language model to generate training samples with ASR-plausible noise. Compare to the previous methods, our approach generates ASR noise that better fits the real-world error distribution. Experimental results on spoken language translation(SLT) and spoken language understanding (SLU) show that our approach effectively improves the system robustness against the ASR errors and achieves state-of-the-art results on both tasks.
Dependency Graph-to-String Statistical Machine Translation
Mar 20, 2021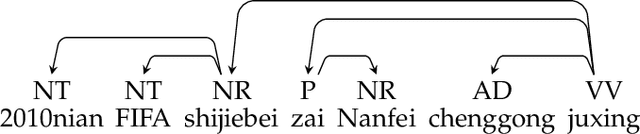
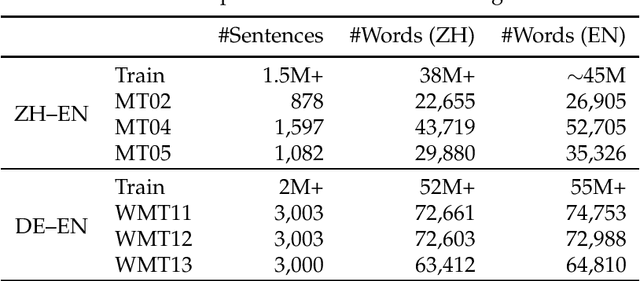
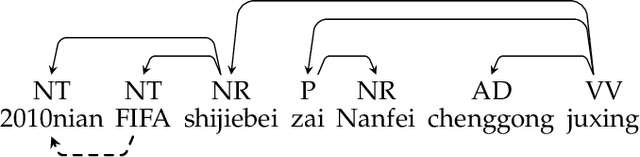
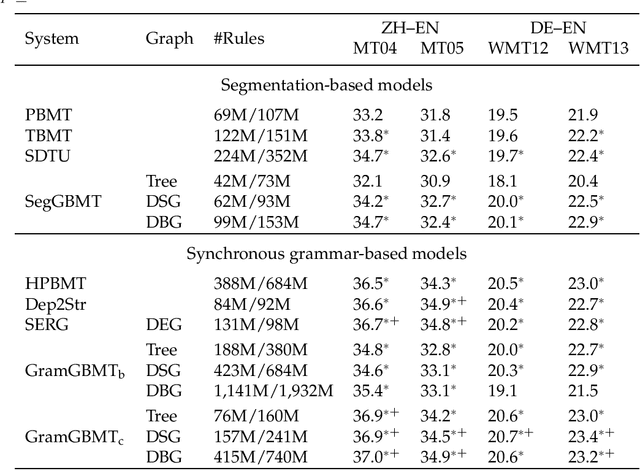
We present graph-based translation models which translate source graphs into target strings. Source graphs are constructed from dependency trees with extra links so that non-syntactic phrases are connected. Inspired by phrase-based models, we first introduce a translation model which segments a graph into a sequence of disjoint subgraphs and generates a translation by combining subgraph translations left-to-right using beam search. However, similar to phrase-based models, this model is weak at phrase reordering. Therefore, we further introduce a model based on a synchronous node replacement grammar which learns recursive translation rules. We provide two implementations of the model with different restrictions so that source graphs can be parsed efficiently. Experiments on Chinese--English and German--English show that our graph-based models are significantly better than corresponding sequence- and tree-based baselines.
Reweighting Augmented Samples by Minimizing the Maximal Expected Loss
Mar 16, 2021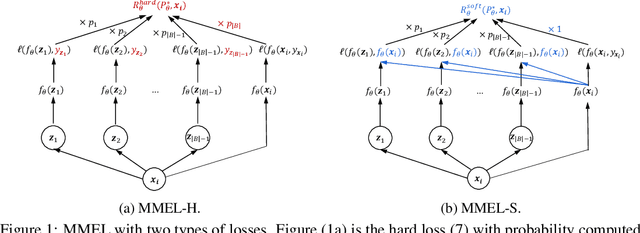
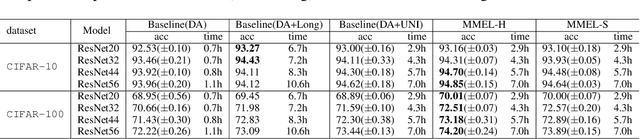

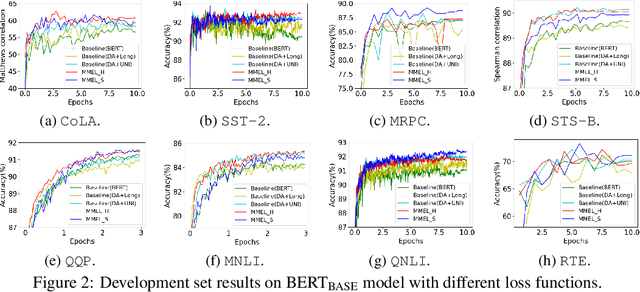
Data augmentation is an effective technique to improve the generalization of deep neural networks. However, previous data augmentation methods usually treat the augmented samples equally without considering their individual impacts on the model. To address this, for the augmented samples from the same training example, we propose to assign different weights to them. We construct the maximal expected loss which is the supremum over any reweighted loss on augmented samples. Inspired by adversarial training, we minimize this maximal expected loss (MMEL) and obtain a simple and interpretable closed-form solution: more attention should be paid to augmented samples with large loss values (i.e., harder examples). Minimizing this maximal expected loss enables the model to perform well under any reweighting strategy. The proposed method can generally be applied on top of any data augmentation methods. Experiments are conducted on both natural language understanding tasks with token-level data augmentation, and image classification tasks with commonly-used image augmentation techniques like random crop and horizontal flip. Empirical results show that the proposed method improves the generalization performance of the model.
* 14 pages