 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTensorCoder: Dimension-Wise Attention via Tensor Representation for Natural Language Modeling
Paper and Code
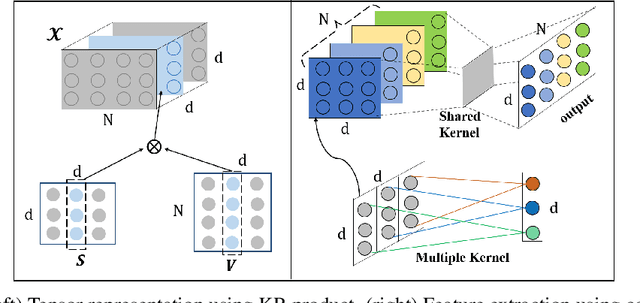
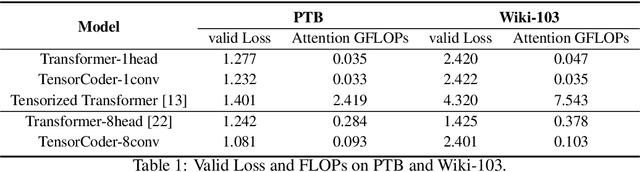
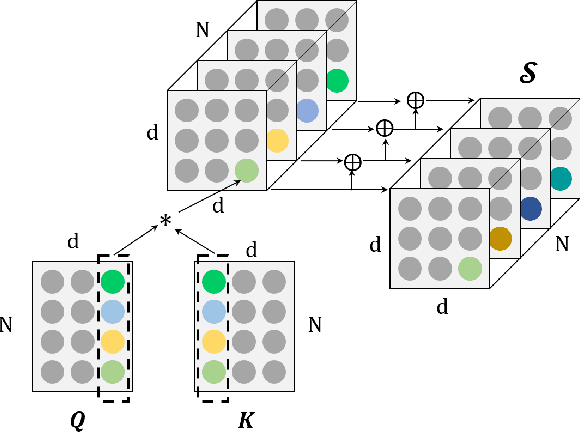
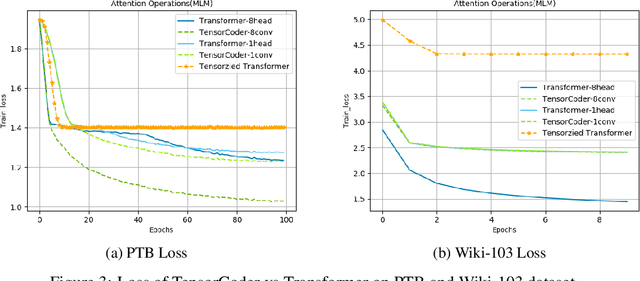
Transformer has been widely-used in many Natural Language Processing (NLP) tasks and the scaled dot-product attention between tokens is a core module of Transformer. This attention is a token-wise design and its complexity is quadratic to the length of sequence, limiting its application potential for long sequence tasks. In this paper, we propose a dimension-wise attention mechanism based on which a novel language modeling approach (namely TensorCoder) can be developed. The dimension-wise attention can reduce the attention complexity from the original $O(N^2d)$ to $O(Nd^2)$, where $N$ is the length of the sequence and $d$ is the dimensionality of head. We verify TensorCoder on two tasks including masked language modeling and neural machine translation. Compared with the original Transformer, TensorCoder not only greatly reduces the calculation of the original model but also obtains improved performance on masked language modeling task (in PTB dataset) and comparable performance on machine translation tasks.