 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency
Aug 25, 2025



We introduce InternVL 3.5, a new family of open-source multimodal models that significantly advances versatility, reasoning capability, and inference efficiency along the InternVL series. A key innovation is the Cascade Reinforcement Learning (Cascade RL) framework, which enhances reasoning through a two-stage process: offline RL for stable convergence and online RL for refined alignment. This coarse-to-fine training strategy leads to substantial improvements on downstream reasoning tasks, e.g., MMMU and MathVista. To optimize efficiency, we propose a Visual Resolution Router (ViR) that dynamically adjusts the resolution of visual tokens without compromising performance. Coupled with ViR, our Decoupled Vision-Language Deployment (DvD) strategy separates the vision encoder and language model across different GPUs, effectively balancing computational load. These contributions collectively enable InternVL3.5 to achieve up to a +16.0\% gain in overall reasoning performance and a 4.05$\times$ inference speedup compared to its predecessor, i.e., InternVL3. In addition, InternVL3.5 supports novel capabilities such as GUI interaction and embodied agency. Notably, our largest model, i.e., InternVL3.5-241B-A28B, attains state-of-the-art results among open-source MLLMs across general multimodal, reasoning, text, and agentic tasks -- narrowing the performance gap with leading commercial models like GPT-5. All models and code are publicly released.
InternBootcamp Technical Report: Boosting LLM Reasoning with Verifiable Task Scaling
Aug 12, 2025



Large language models (LLMs) have revolutionized artificial intelligence by enabling complex reasoning capabilities. While recent advancements in reinforcement learning (RL) have primarily focused on domain-specific reasoning tasks (e.g., mathematics or code generation), real-world reasoning scenarios often require models to handle diverse and complex environments that narrow-domain benchmarks cannot fully capture. To address this gap, we present InternBootcamp, an open-source framework comprising 1000+ domain-diverse task environments specifically designed for LLM reasoning research. Our codebase offers two key functionalities: (1) automated generation of unlimited training/testing cases with configurable difficulty levels, and (2) integrated verification modules for objective response evaluation. These features make InternBootcamp fundamental infrastructure for RL-based model optimization, synthetic data generation, and model evaluation. Although manually developing such a framework with enormous task coverage is extremely cumbersome, we accelerate the development procedure through an automated agent workflow supplemented by manual validation protocols, which enables the task scope to expand rapidly. % With these bootcamps, we further establish Bootcamp-EVAL, an automatically generated benchmark for comprehensive performance assessment. Evaluation reveals that frontier models still underperform in many reasoning tasks, while training with InternBootcamp provides an effective way to significantly improve performance, leading to our 32B model that achieves state-of-the-art results on Bootcamp-EVAL and excels on other established benchmarks. In particular, we validate that consistent performance gains come from including more training tasks, namely \textbf{task scaling}, over two orders of magnitude, offering a promising route towards capable reasoning generalist.
IFDECORATOR: Wrapping Instruction Following Reinforcement Learning with Verifiable Rewards
Aug 06, 2025Reinforcement Learning with Verifiable Rewards (RLVR) improves instruction following capabilities of large language models (LLMs), but suffers from training inefficiency due to inadequate difficulty assessment. Moreover, RLVR is prone to over-optimization, where LLMs exploit verification shortcuts without aligning to the actual intent of user instructions. We introduce Instruction Following Decorator (IFDecorator}, a framework that wraps RLVR training into a robust and sample-efficient pipeline. It consists of three components: (1) a cooperative-adversarial data flywheel that co-evolves instructions and hybrid verifications, generating progressively more challenging instruction-verification pairs; (2) IntentCheck, a bypass module enforcing intent alignment; and (3) trip wires, a diagnostic mechanism that detects reward hacking via trap instructions, which trigger and capture shortcut exploitation behaviors. Our Qwen2.5-32B-Instruct-IFDecorator achieves 87.43% accuracy on IFEval, outperforming larger proprietary models such as GPT-4o. Additionally, we demonstrate substantial improvements on FollowBench while preserving general capabilities. Our trip wires show significant reductions in reward hacking rates. We will release models, code, and data for future research.
LongLLaDA: Unlocking Long Context Capabilities in Diffusion LLMs
Jun 17, 2025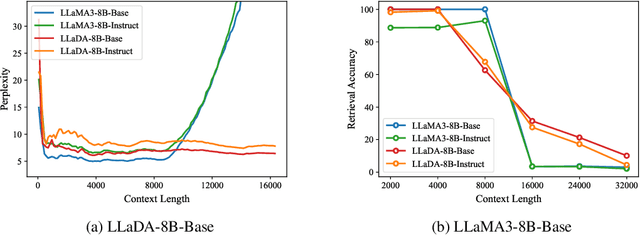

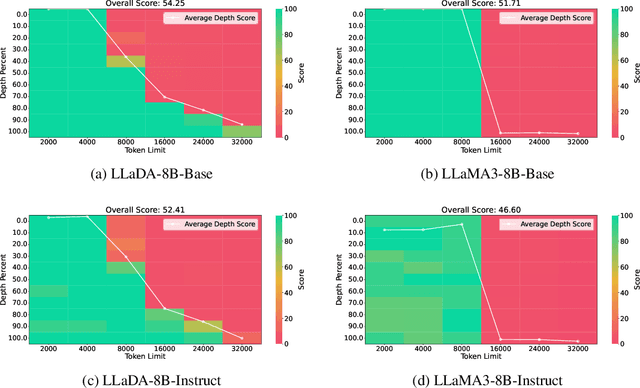

Large Language Diffusion Models, or diffusion LLMs, have emerged as a significant focus in NLP research, with substantial effort directed toward understanding their scalability and downstream task performance. However, their long-context capabilities remain unexplored, lacking systematic analysis or methods for context extension. In this work, we present the first systematic investigation comparing the long-context performance of diffusion LLMs and traditional auto-regressive LLMs. We first identify a unique characteristic of diffusion LLMs, unlike auto-regressive LLMs, they maintain remarkably \textbf{\textit{stable perplexity}} during direct context extrapolation. Furthermore, where auto-regressive models fail outright during the Needle-In-A-Haystack task with context exceeding their pretrained length, we discover diffusion LLMs exhibit a distinct \textbf{\textit{local perception}} phenomenon, enabling successful retrieval from recent context segments. We explain both phenomena through the lens of Rotary Position Embedding (RoPE) scaling theory. Building on these observations, we propose LongLLaDA, a training-free method that integrates LLaDA with the NTK-based RoPE extrapolation. Our results validate that established extrapolation scaling laws remain effective for extending the context windows of diffusion LLMs. Furthermore, we identify long-context tasks where diffusion LLMs outperform auto-regressive LLMs and others where they fall short. Consequently, this study establishes the first context extrapolation method for diffusion LLMs while providing essential theoretical insights and empirical benchmarks critical for advancing future research on long-context diffusion LLMs.
Capability Salience Vector: Fine-grained Alignment of Loss and Capabilities for Downstream Task Scaling Law
Jun 16, 2025



Scaling law builds the relationship between training computation and validation loss, enabling researchers to effectively predict the loss trending of models across different levels of computation. However, a gap still remains between validation loss and the model's downstream capabilities, making it untrivial to apply scaling law to direct performance prediction for downstream tasks. The loss typically represents a cumulative penalty for predicted tokens, which are implicitly considered to have equal importance. Nevertheless, our studies have shown evidence that when considering different training data distributions, we cannot directly model the relationship between downstream capability and computation or token loss. To bridge the gap between validation loss and downstream task capabilities, in this work, we introduce Capability Salience Vector, which decomposes the overall loss and assigns different importance weights to tokens to assess a specific meta-capability, aligning the validation loss with downstream task performance in terms of the model's capabilities. Experiments on various popular benchmarks demonstrate that our proposed Capability Salience Vector could significantly improve the predictability of language model performance on downstream tasks.
Beyond Homogeneous Attention: Memory-Efficient LLMs via Fourier-Approximated KV Cache
Jun 13, 2025Large Language Models struggle with memory demands from the growing Key-Value (KV) cache as context lengths increase. Existing compression methods homogenize head dimensions or rely on attention-guided token pruning, often sacrificing accuracy or introducing computational overhead. We propose FourierAttention, a training-free framework that exploits the heterogeneous roles of transformer head dimensions: lower dimensions prioritize local context, while upper ones capture long-range dependencies. By projecting the long-context-insensitive dimensions onto orthogonal Fourier bases, FourierAttention approximates their temporal evolution with fixed-length spectral coefficients. Evaluations on LLaMA models show that FourierAttention achieves the best long-context accuracy on LongBench and Needle-In-A-Haystack (NIAH). Besides, a custom Triton kernel, FlashFourierAttention, is designed to optimize memory via streamlined read-write operations, enabling efficient deployment without performance compromise.
GeometryZero: Improving Geometry Solving for LLM with Group Contrastive Policy Optimization
Jun 08, 2025Recent advances in large language models (LLMs) have demonstrated remarkable capabilities across diverse domains, particularly in mathematical reasoning, amid which geometry problem solving remains a challenging area where auxiliary construction plays a enssential role. Existing approaches either achieve suboptimal performance or rely on massive LLMs (e.g., GPT-4o), incurring massive computational costs. We posit that reinforcement learning with verifiable reward (e.g., GRPO) offers a promising direction for training smaller models that effectively combine auxiliary construction with robust geometric reasoning. However, directly applying GRPO to geometric reasoning presents fundamental limitations due to its dependence on unconditional rewards, which leads to indiscriminate and counterproductive auxiliary constructions. To address these challenges, we propose Group Contrastive Policy Optimization (GCPO), a novel reinforcement learning framework featuring two key innovations: (1) Group Contrastive Masking, which adaptively provides positive or negative reward signals for auxiliary construction based on contextual utility, and a (2) length reward that promotes longer reasoning chains. Building on GCPO, we develop GeometryZero, a family of affordable-size geometric reasoning models that judiciously determine when to employ auxiliary construction. Our extensive empirical evaluation across popular geometric benchmarks (Geometry3K, MathVista) demonstrates that GeometryZero models consistently outperform baselines (e.g. GRPO), achieving an average improvement of 4.29% across all benchmarks.
VisuoThink: Empowering LVLM Reasoning with Multimodal Tree Search
Apr 12, 2025Recent advancements in Large Vision-Language Models have showcased remarkable capabilities. However, they often falter when confronted with complex reasoning tasks that humans typically address through visual aids and deliberate, step-by-step thinking. While existing methods have explored text-based slow thinking or rudimentary visual assistance, they fall short of capturing the intricate, interleaved nature of human visual-verbal reasoning processes. To overcome these limitations and inspired by the mechanisms of slow thinking in human cognition, we introduce VisuoThink, a novel framework that seamlessly integrates visuospatial and linguistic domains. VisuoThink facilitates multimodal slow thinking by enabling progressive visual-textual reasoning and incorporates test-time scaling through look-ahead tree search. Extensive experiments demonstrate that VisuoThink significantly enhances reasoning capabilities via inference-time scaling, even without fine-tuning, achieving state-of-the-art performance in tasks involving geometry and spatial reasoning.
Code-Driven Inductive Synthesis: Enhancing Reasoning Abilities of Large Language Models with Sequences
Mar 17, 2025



Large language models make remarkable progress in reasoning capabilities. Existing works focus mainly on deductive reasoning tasks (e.g., code and math), while another type of reasoning mode that better aligns with human learning, inductive reasoning, is not well studied. We attribute the reason to the fact that obtaining high-quality process supervision data is challenging for inductive reasoning. Towards this end, we novelly employ number sequences as the source of inductive reasoning data. We package sequences into algorithmic problems to find the general term of each sequence through a code solution. In this way, we can verify whether the code solution holds for any term in the current sequence, and inject case-based supervision signals by using code unit tests. We build a sequence synthetic data pipeline and form a training dataset CodeSeq. Experimental results show that the models tuned with CodeSeq improve on both code and comprehensive reasoning benchmarks.
How to Mitigate Overfitting in Weak-to-strong Generalization?
Mar 06, 2025



Aligning powerful AI models on tasks that surpass human evaluation capabilities is the central problem of \textbf{superalignment}. To address this problem, weak-to-strong generalization aims to elicit the capabilities of strong models through weak supervisors and ensure that the behavior of strong models aligns with the intentions of weak supervisors without unsafe behaviors such as deception. Although weak-to-strong generalization exhibiting certain generalization capabilities, strong models exhibit significant overfitting in weak-to-strong generalization: Due to the strong fit ability of strong models, erroneous labels from weak supervisors may lead to overfitting in strong models. In addition, simply filtering out incorrect labels may lead to a degeneration in question quality, resulting in a weak generalization ability of strong models on hard questions. To mitigate overfitting in weak-to-strong generalization, we propose a two-stage framework that simultaneously improves the quality of supervision signals and the quality of input questions. Experimental results in three series of large language models and two mathematical benchmarks demonstrate that our framework significantly improves PGR compared to naive weak-to-strong generalization, even achieving up to 100\% PGR on some models.