 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeINFWIDE: Image and Feature Space Wiener Deconvolution Network for Non-blind Image Deblurring in Low-Light Conditions
Jul 17, 2022
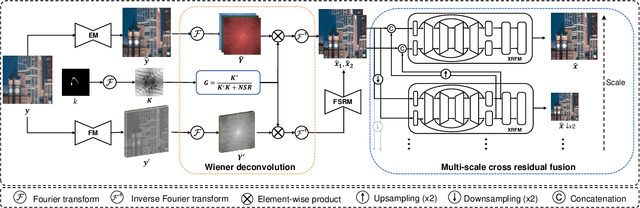
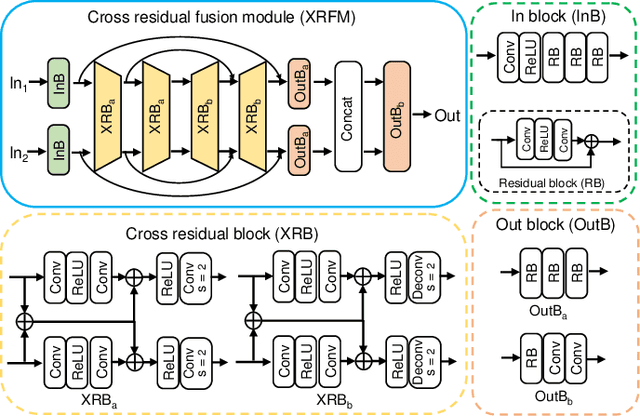

Under low-light environment, handheld photography suffers from severe camera shake under long exposure settings. Although existing deblurring algorithms have shown promising performance on well-exposed blurry images, they still cannot cope with low-light snapshots. Sophisticated noise and saturation regions are two dominating challenges in practical low-light deblurring. In this work, we propose a novel non-blind deblurring method dubbed image and feature space Wiener deconvolution network (INFWIDE) to tackle these problems systematically. In terms of algorithm design, INFWIDE proposes a two-branch architecture, which explicitly removes noise and hallucinates saturated regions in the image space and suppresses ringing artifacts in the feature space, and integrates the two complementary outputs with a subtle multi-scale fusion network for high quality night photograph deblurring. For effective network training, we design a set of loss functions integrating a forward imaging model and backward reconstruction to form a close-loop regularization to secure good convergence of the deep neural network. Further, to optimize INFWIDE's applicability in real low-light conditions, a physical-process-based low-light noise model is employed to synthesize realistic noisy night photographs for model training. Taking advantage of the traditional Wiener deconvolution algorithm's physically driven characteristics and arisen deep neural network's representation ability, INFWIDE can recover fine details while suppressing the unpleasant artifacts during deblurring. Extensive experiments on synthetic data and real data demonstrate the superior performance of the proposed approach.
All-optical graph representation learning using integrated diffractive photonic computing units
Apr 23, 2022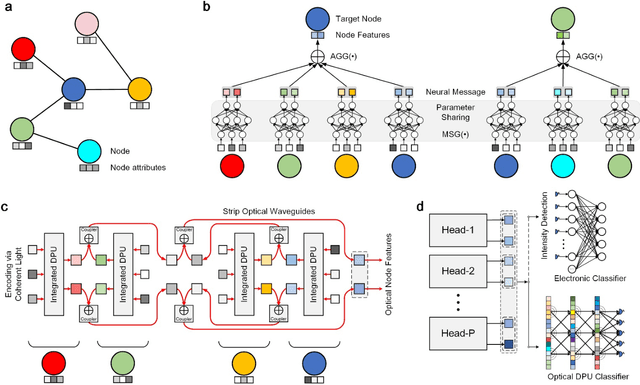
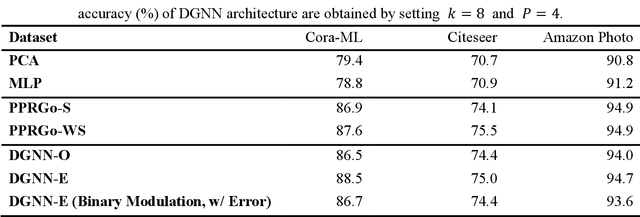
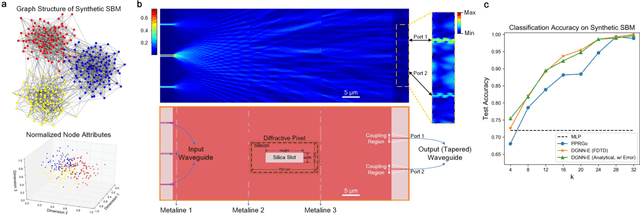
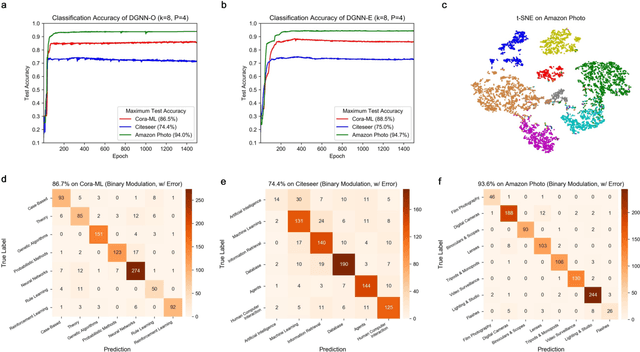
Photonic neural networks perform brain-inspired computations using photons instead of electrons that can achieve substantially improved computing performance. However, existing architectures can only handle data with regular structures, e.g., images or videos, but fail to generalize to graph-structured data beyond Euclidean space, e.g., social networks or document co-citation networks. Here, we propose an all-optical graph representation learning architecture, termed diffractive graph neural network (DGNN), based on the integrated diffractive photonic computing units (DPUs) to address this limitation. Specifically, DGNN optically encodes node attributes into strip optical waveguides, which are transformed by DPUs and aggregated by on-chip optical couplers to extract their feature representations. Each DPU comprises successive passive layers of metalines to modulate the electromagnetic optical field via diffraction, where the metaline structures are learnable parameters shared across graph nodes. DGNN captures complex dependencies among the node neighborhoods and eliminates the nonlinear transition functions during the light-speed optical message passing over graph structures. We demonstrate the use of DGNN extracted features for node and graph-level classification tasks with benchmark databases and achieve superior performance. Our work opens up a new direction for designing application-specific integrated photonic circuits for high-efficiency processing of large-scale graph data structures using deep learning.
A Dual Sensor Computational Camera for High Quality Dark Videography
Apr 11, 2022

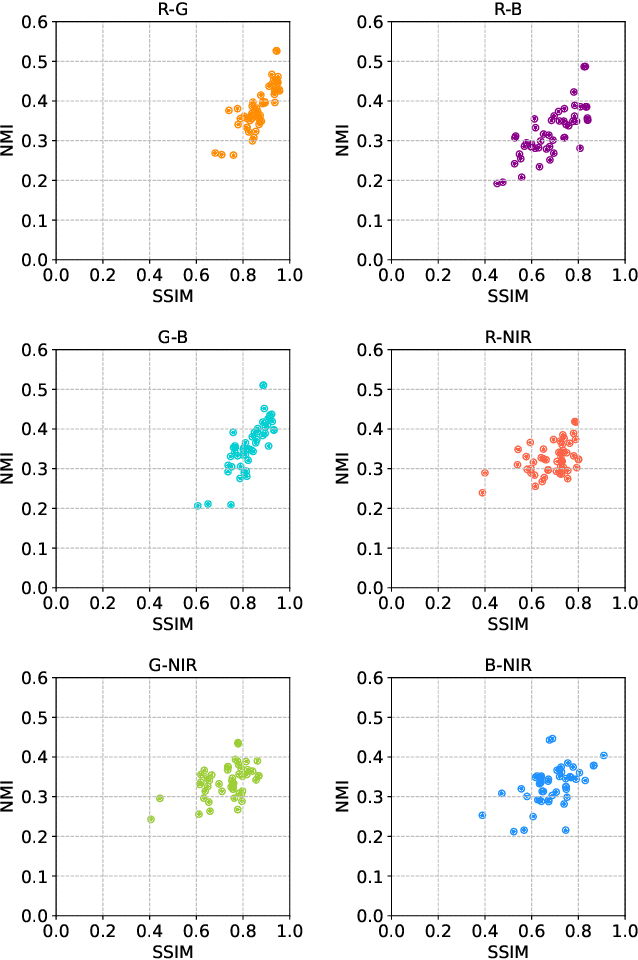
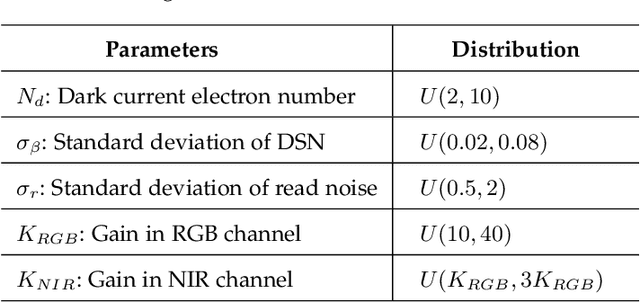
Videos captured under low light conditions suffer from severe noise. A variety of efforts have been devoted to image/video noise suppression and made large progress. However, in extremely dark scenarios, extensive photon starvation would hamper precise noise modeling. Instead, developing an imaging system collecting more photons is a more effective way for high-quality video capture under low illuminations. In this paper, we propose to build a dual-sensor camera to additionally collect the photons in NIR wavelength, and make use of the correlation between RGB and near-infrared (NIR) spectrum to perform high-quality reconstruction from noisy dark video pairs. In hardware, we build a compact dual-sensor camera capturing RGB and NIR videos simultaneously. Computationally, we propose a dual-channel multi-frame attention network (DCMAN) utilizing spatial-temporal-spectral priors to reconstruct the low-light RGB and NIR videos. In addition, we build a high-quality paired RGB and NIR video dataset, based on which the approach can be applied to different sensors easily by training the DCMAN model with simulated noisy input following a physical-process-based CMOS noise model. Both experiments on synthetic and real videos validate the performance of this compact dual-sensor camera design and the corresponding reconstruction algorithm in dark videography.
Computational Imaging and Artificial Intelligence: The Next Revolution of Mobile Vision
Sep 18, 2021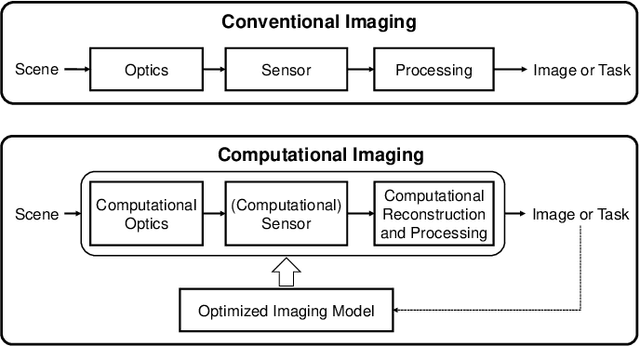

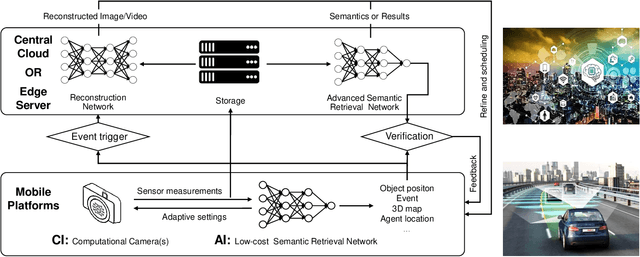

Signal capture stands in the forefront to perceive and understand the environment and thus imaging plays the pivotal role in mobile vision. Recent explosive progresses in Artificial Intelligence (AI) have shown great potential to develop advanced mobile platforms with new imaging devices. Traditional imaging systems based on the "capturing images first and processing afterwards" mechanism cannot meet this unprecedented demand. Differently, Computational Imaging (CI) systems are designed to capture high-dimensional data in an encoded manner to provide more information for mobile vision systems.Thanks to AI, CI can now be used in real systems by integrating deep learning algorithms into the mobile vision platform to achieve the closed loop of intelligent acquisition, processing and decision making, thus leading to the next revolution of mobile vision.Starting from the history of mobile vision using digital cameras, this work first introduces the advances of CI in diverse applications and then conducts a comprehensive review of current research topics combining CI and AI. Motivated by the fact that most existing studies only loosely connect CI and AI (usually using AI to improve the performance of CI and only limited works have deeply connected them), in this work, we propose a framework to deeply integrate CI and AI by using the example of self-driving vehicles with high-speed communication, edge computing and traffic planning. Finally, we outlook the future of CI plus AI by investigating new materials, brain science and new computing techniques to shed light on new directions of mobile vision systems.
Imaging dynamics beneath turbid media via parallelized single-photon detection
Jul 22, 2021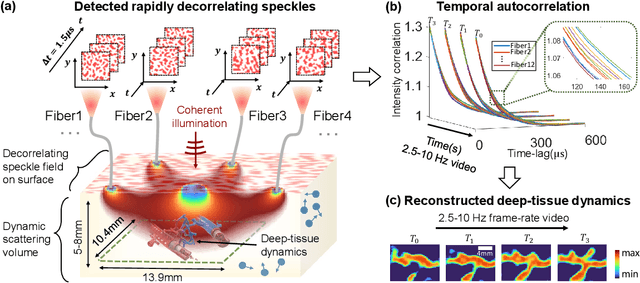
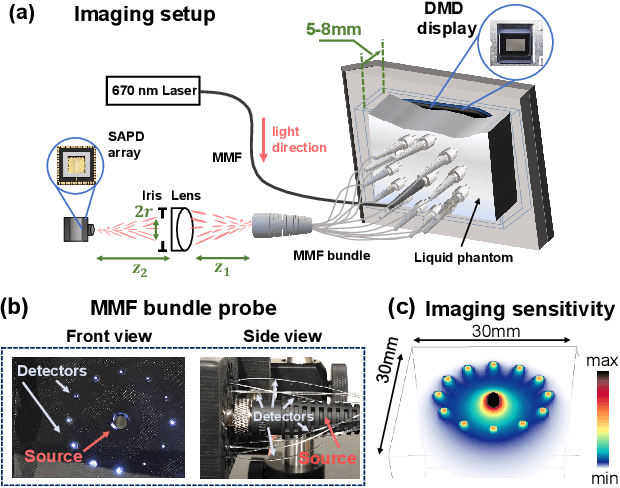
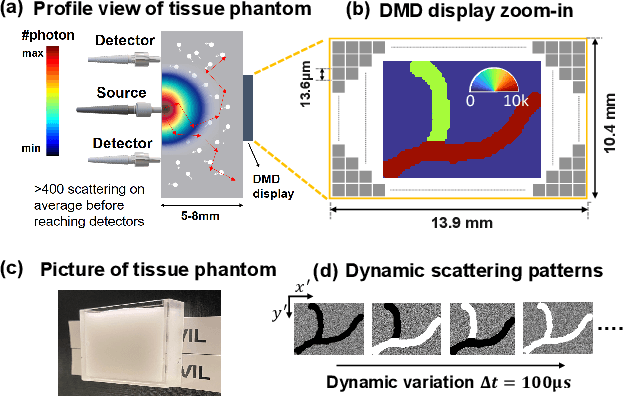
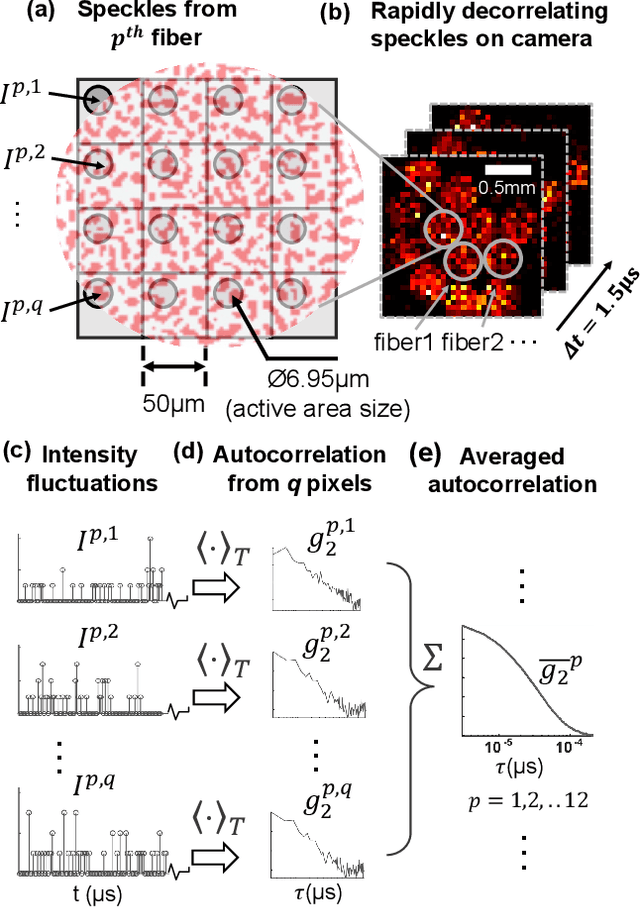
Noninvasive optical imaging through dynamic scattering media has numerous important biomedical applications but still remains a challenging task. While standard methods aim to form images based upon optical absorption or fluorescent emission, it is also well-established that the temporal correlation of scattered coherent light diffuses through tissue much like optical intensity. Few works to date, however, have aimed to experimentally measure and process such data to demonstrate deep-tissue imaging of decorrelation dynamics. In this work, we take advantage of a single-photon avalanche diode (SPAD) array camera, with over one thousand detectors, to simultaneously detect speckle fluctuations at the single-photon level from 12 different phantom tissue surface locations delivered via a customized fiber bundle array. We then apply a deep neural network to convert the acquired single-photon measurements into video of scattering dynamics beneath rapidly decorrelating liquid tissue phantoms. We demonstrate the ability to record video of dynamic events occurring 5-8 mm beneath a decorrelating tissue phantom with mm-scale resolution and at a 2.5-10 Hz frame rate.
10-mega pixel snapshot compressive imaging with a hybrid coded aperture
Jun 30, 2021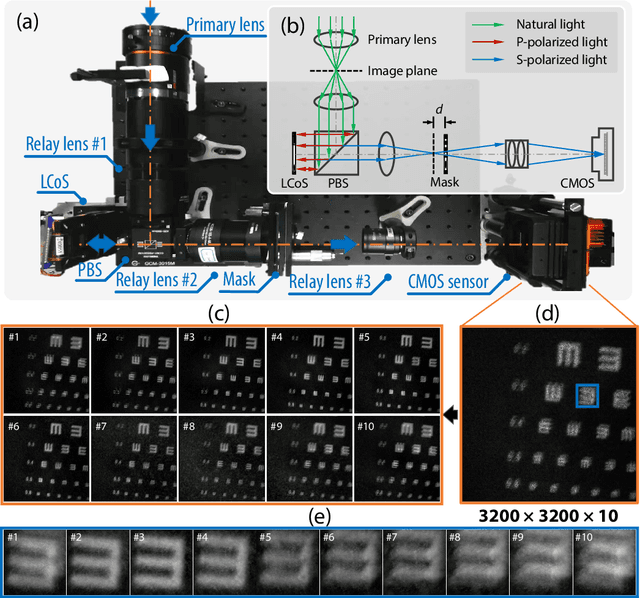
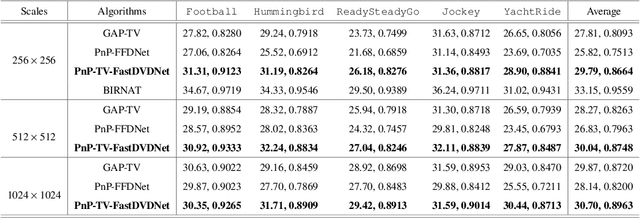
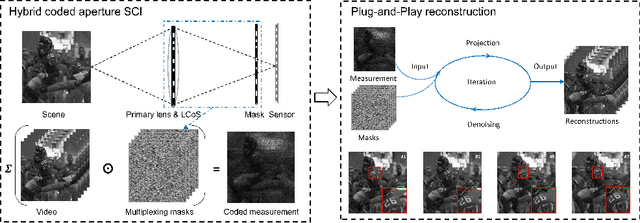
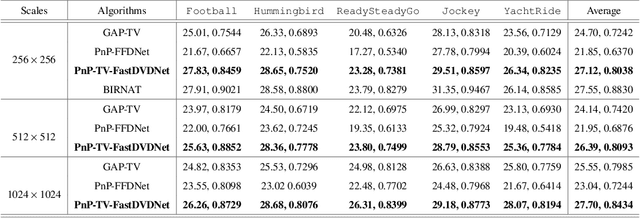
High resolution images are widely used in our daily life, whereas high-speed video capture is challenging due to the low frame rate of cameras working at the high resolution mode. Digging deeper, the main bottleneck lies in the low throughput of existing imaging systems. Towards this end, snapshot compressive imaging (SCI) was proposed as a promising solution to improve the throughput of imaging systems by compressive sampling and computational reconstruction. During acquisition, multiple high-speed images are encoded and collapsed to a single measurement. After this, algorithms are employed to retrieve the video frames from the coded snapshot. Recently developed Plug-and-Play (PnP) algorithms make it possible for SCI reconstruction in large-scale problems. However, the lack of high-resolution encoding systems still precludes SCI's wide application. In this paper, we build a novel hybrid coded aperture snapshot compressive imaging (HCA-SCI) system by incorporating a dynamic liquid crystal on silicon and a high-resolution lithography mask. We further implement a PnP reconstruction algorithm with cascaded denoisers for high quality reconstruction. Based on the proposed HCA-SCI system and algorithm, we achieve a 10-mega pixel SCI system to capture high-speed scenes, leading to a high throughput of 4.6G voxels per second. Both simulation and real data experiments verify the feasibility and performance of our proposed HCA-SCI scheme.
Prostate cancer histopathology with label-free multispectral deep UV microscopy quantifies phenotypes of tumor grade and aggressiveness
Jun 01, 2021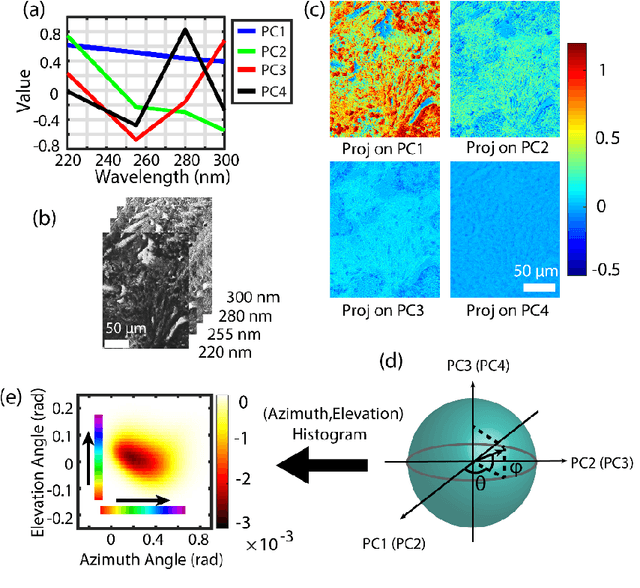
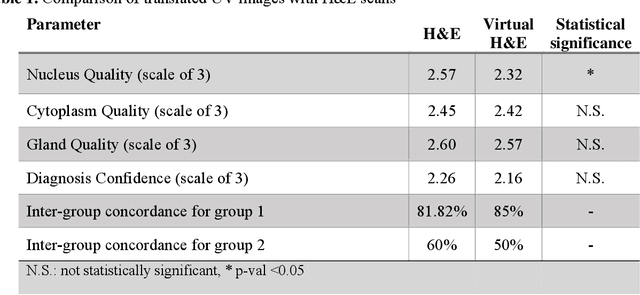


Identifying prostate cancer patients that are harboring aggressive forms of prostate cancer remains a significant clinical challenge. To shed light on this problem, we develop an approach based on multispectral deep-ultraviolet (UV) microscopy that provides novel quantitative insight into the aggressiveness and grade of this disease. First, we find that UV spectral signatures from endogenous molecules give rise to a phenotypical continuum that differentiates critical structures of thin tissue sections with subcellular spatial resolution, including nuclei, cytoplasm, stroma, basal cells, nerves, and inflammation. Further, we show that this phenotypical continuum can be applied as a surrogate biomarker of prostate cancer malignancy, where patients with the most aggressive tumors show a ubiquitous glandular phenotypical shift. Lastly, we adapt a two-part Cycle-consistent Generative Adversarial Network to translate the label-free deep-UV images into virtual hematoxylin and eosin (H&E) stained images. Agreement between the virtual H&E images and the gold standard H&E-stained tissue sections is evaluated by a panel of pathologists who find that the two modalities are in excellent agreement. This work has significant implications towards improving our ability to objectively quantify prostate cancer grade and aggressiveness, thus improving the management and clinical outcomes of prostate cancer patients. This same approach can also be applied broadly in other tumor types to achieve low-cost, stain-free, quantitative histopathological analysis.
Function4D: Real-time Human Volumetric Capture from Very Sparse Consumer RGBD Sensors
May 06, 2021
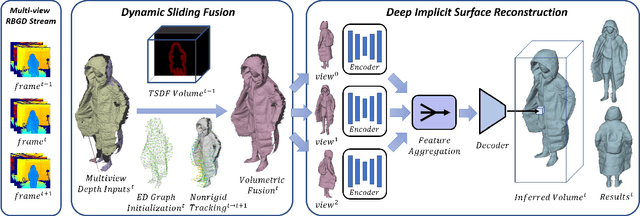

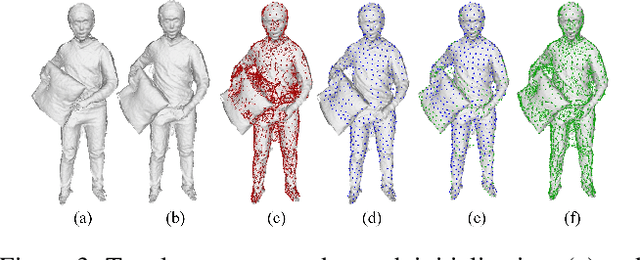
Human volumetric capture is a long-standing topic in computer vision and computer graphics. Although high-quality results can be achieved using sophisticated off-line systems, real-time human volumetric capture of complex scenarios, especially using light-weight setups, remains challenging. In this paper, we propose a human volumetric capture method that combines temporal volumetric fusion and deep implicit functions. To achieve high-quality and temporal-continuous reconstruction, we propose dynamic sliding fusion to fuse neighboring depth observations together with topology consistency. Moreover, for detailed and complete surface generation, we propose detail-preserving deep implicit functions for RGBD input which can not only preserve the geometric details on the depth inputs but also generate more plausible texturing results. Results and experiments show that our method outperforms existing methods in terms of view sparsity, generalization capacity, reconstruction quality, and run-time efficiency.
DeepMultiCap: Performance Capture of Multiple Characters Using Sparse Multiview Cameras
May 01, 2021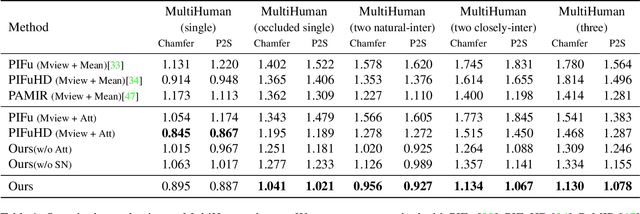
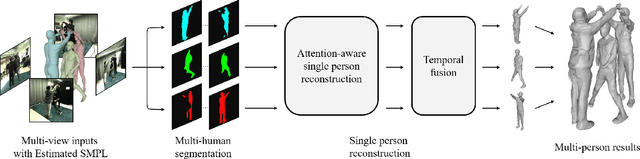
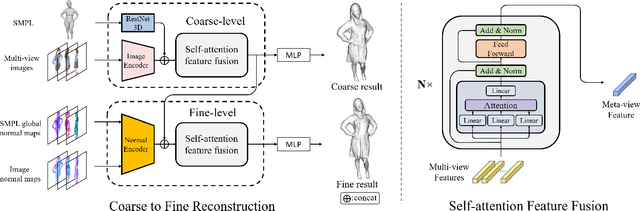

We propose DeepMultiCap, a novel method for multi-person performance capture using sparse multi-view cameras. Our method can capture time varying surface details without the need of using pre-scanned template models. To tackle with the serious occlusion challenge for close interacting scenes, we combine a recently proposed pixel-aligned implicit function with parametric model for robust reconstruction of the invisible surface areas. An effective attention-aware module is designed to obtain the fine-grained geometry details from multi-view images, where high-fidelity results can be generated. In addition to the spatial attention method, for video inputs, we further propose a novel temporal fusion method to alleviate the noise and temporal inconsistencies for moving character reconstruction. For quantitative evaluation, we contribute a high quality multi-person dataset, MultiHuman, which consists of 150 static scenes with different levels of occlusions and ground truth 3D human models. Experimental results demonstrate the state-of-the-art performance of our method and the well generalization to real multiview video data, which outperforms the prior works by a large margin.
Universal and Flexible Optical Aberration Correction Using Deep-Prior Based Deconvolution
Apr 07, 2021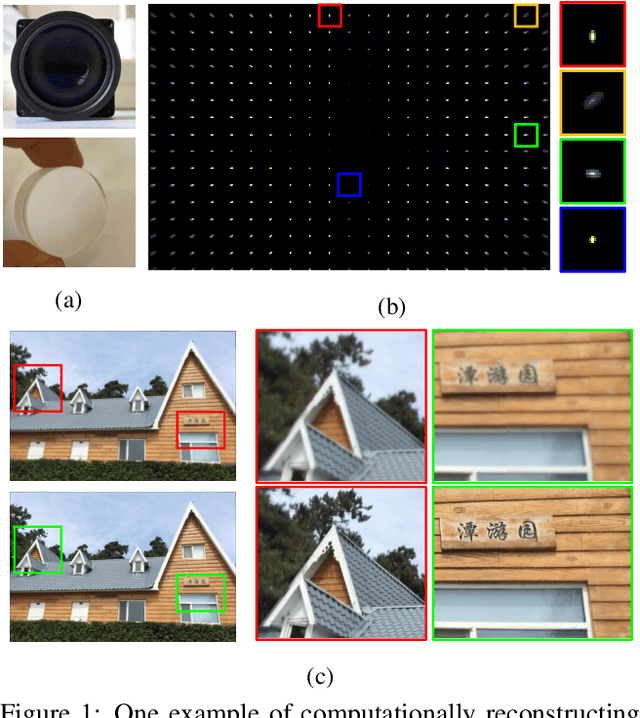

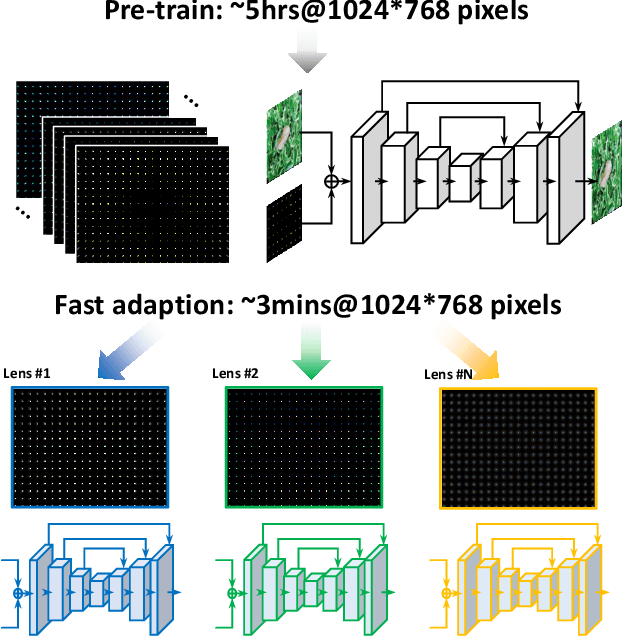
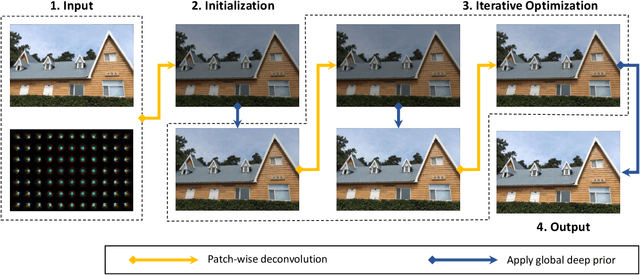
High quality imaging usually requires bulky and expensive lenses to compensate geometric and chromatic aberrations. This poses high constraints on the optical hash or low cost applications. Although one can utilize algorithmic reconstruction to remove the artifacts of low-end lenses, the degeneration from optical aberrations is spatially varying and the computation has to trade off efficiency for performance. For example, we need to conduct patch-wise optimization or train a large set of local deep neural networks to achieve high reconstruction performance across the whole image. In this paper, we propose a PSF aware plug-and-play deep network, which takes the aberrant image and PSF map as input and produces the latent high quality version via incorporating lens-specific deep priors, thus leading to a universal and flexible optical aberration correction method. Specifically, we pre-train a base model from a set of diverse lenses and then adapt it to a given lens by quickly refining the parameters, which largely alleviates the time and memory consumption of model learning. The approach is of high efficiency in both training and testing stages. Extensive results verify the promising applications of our proposed approach for compact low-end cameras.