 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCircConv: A Structured Convolution with Low Complexity
Feb 28, 2019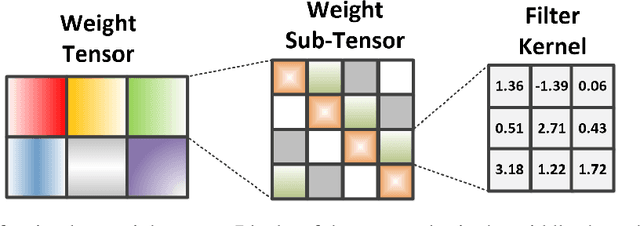

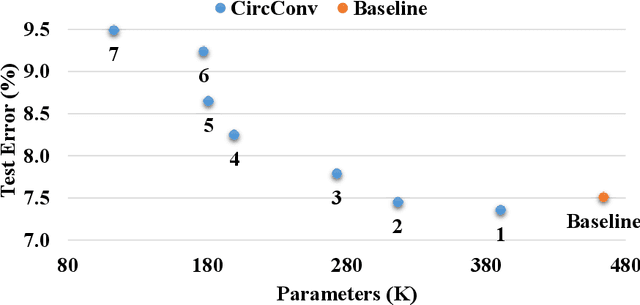
Deep neural networks (DNNs), especially deep convolutional neural networks (CNNs), have emerged as the powerful technique in various machine learning applications. However, the large model sizes of DNNs yield high demands on computation resource and weight storage, thereby limiting the practical deployment of DNNs. To overcome these limitations, this paper proposes to impose the circulant structure to the construction of convolutional layers, and hence leads to circulant convolutional layers (CircConvs) and circulant CNNs. The circulant structure and models can be either trained from scratch or re-trained from a pre-trained non-circulant model, thereby making it very flexible for different training environments. Through extensive experiments, such strong structure-imposing approach is proved to be able to substantially reduce the number of parameters of convolutional layers and enable significant saving of computational cost by using fast multiplication of the circulant tensor.
E-RNN: Design Optimization for Efficient Recurrent Neural Networks in FPGAs
Dec 12, 2018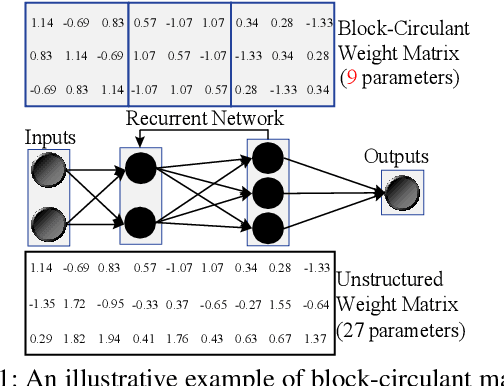

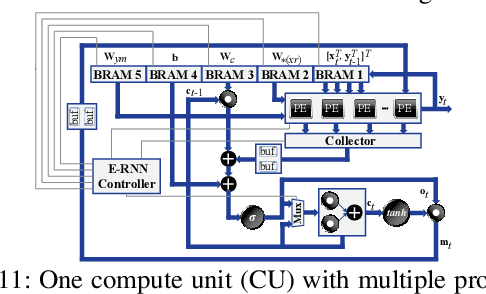
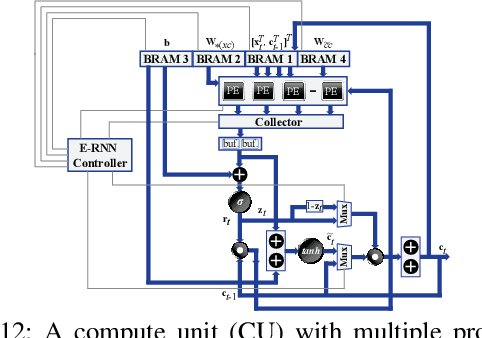
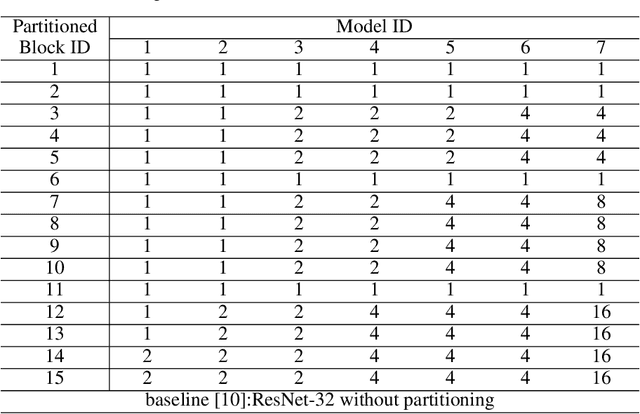
Recurrent Neural Networks (RNNs) are becoming increasingly important for time series-related applications which require efficient and real-time implementations. The two major types are Long Short-Term Memory (LSTM) and Gated Recurrent Unit (GRU) networks. It is a challenging task to have real-time, efficient, and accurate hardware RNN implementations because of the high sensitivity to imprecision accumulation and the requirement of special activation function implementations. A key limitation of the prior works is the lack of a systematic design optimization framework of RNN model and hardware implementations, especially when the block size (or compression ratio) should be jointly optimized with RNN type, layer size, etc. In this paper, we adopt the block-circulant matrix-based framework, and present the Efficient RNN (E-RNN) framework for FPGA implementations of the Automatic Speech Recognition (ASR) application. The overall goal is to improve performance/energy efficiency under accuracy requirement. We use the alternating direction method of multipliers (ADMM) technique for more accurate block-circulant training, and present two design explorations providing guidance on block size and reducing RNN training trials. Based on the two observations, we decompose E-RNN in two phases: Phase I on determining RNN model to reduce computation and storage subject to accuracy requirement, and Phase II on hardware implementations given RNN model, including processing element design/optimization, quantization, activation implementation, etc. Experimental results on actual FPGA deployments show that E-RNN achieves a maximum energy efficiency improvement of 37.4$\times$ compared with ESE, and more than 2$\times$ compared with C-LSTM, under the same accuracy.
Scalable NoC-based Neuromorphic Hardware Learning and Inference
Sep 18, 2018
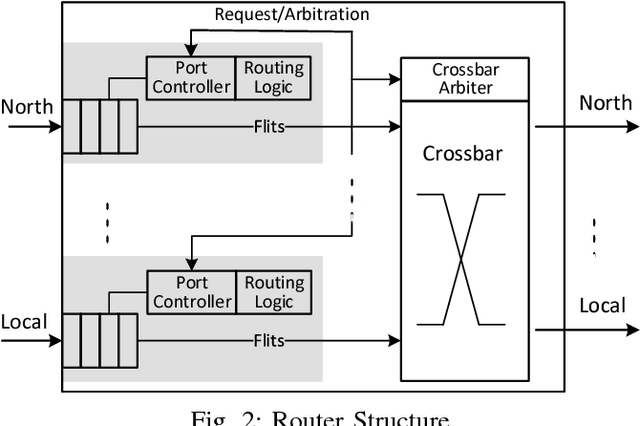
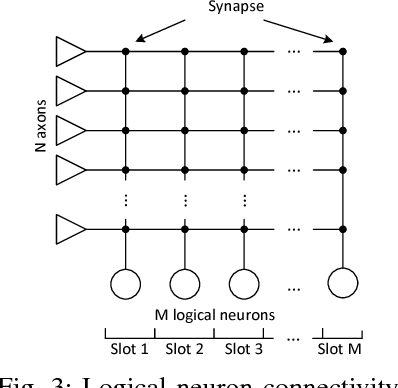
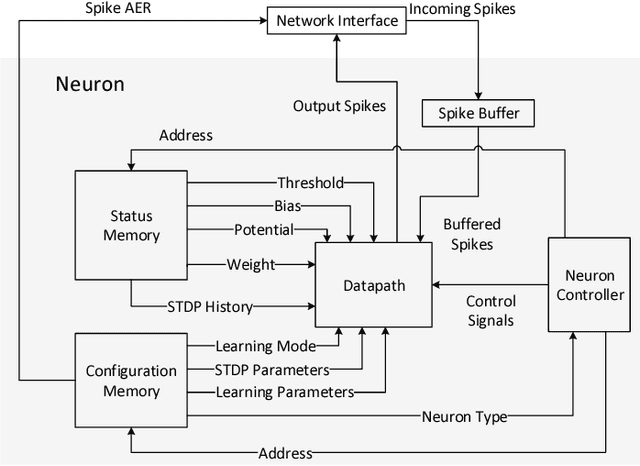
Bio-inspired neuromorphic hardware is a research direction to approach brain's computational power and energy efficiency. Spiking neural networks (SNN) encode information as sparsely distributed spike trains and employ spike-timing-dependent plasticity (STDP) mechanism for learning. Existing hardware implementations of SNN are limited in scale or do not have in-hardware learning capability. In this work, we propose a low-cost scalable Network-on-Chip (NoC) based SNN hardware architecture with fully distributed in-hardware STDP learning capability. All hardware neurons work in parallel and communicate through the NoC. This enables chip-level interconnection, scalability and reconfigurability necessary for deploying different applications. The hardware is applied to learn MNIST digits as an evaluation of its learning capability. We explore the design space to study the trade-offs between speed, area and energy. How to use this procedure to find optimal architecture configuration is also discussed.
C3PO: Database and Benchmark for Early-stage Malicious Activity Detection in 3D Printing
Aug 02, 2018
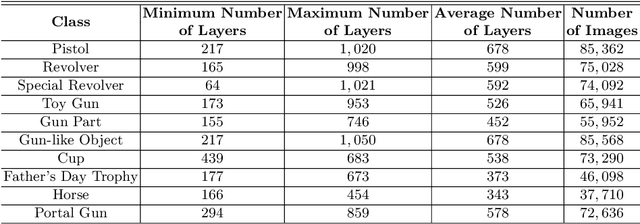


Increasing malicious users have sought practices to leverage 3D printing technology to produce unlawful tools in criminal activities. Current regulations are inadequate to deal with the rapid growth of 3D printers. It is of vital importance to enable 3D printers to identify the objects to be printed, so that the manufacturing procedure of an illegal weapon can be terminated at the early stage. Deep learning yields significant rises in performance in the object recognition tasks. However, the lack of large-scale databases in 3D printing domain stalls the advancement of automatic illegal weapon recognition. This paper presents a new 3D printing image database, namely C3PO, which compromises two subsets for the different system working scenarios. We extract images from the numerical control programming code files of 22 3D models, and then categorize the images into 10 distinct labels. The first set consists of 62,200 images which represent the object projections on the three planes in a Cartesian coordinate system. And the second sets consists of sequences of total 671,677 images to simulate the cameras' captures of the printed objects. Importantly, we demonstrate that the weapons can be recognized in either scenario using deep learning based approaches using our proposed database. % We also use the trained deep models to build a prototype of object-aware 3D printer. The quantitative results are promising, and the future exploration of the database and the crime prevention in 3D printing are demanding tasks.
Towards Budget-Driven Hardware Optimization for Deep Convolutional Neural Networks using Stochastic Computing
May 10, 2018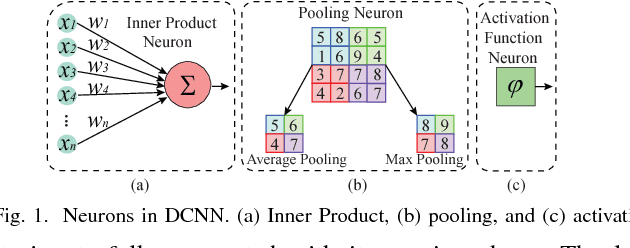
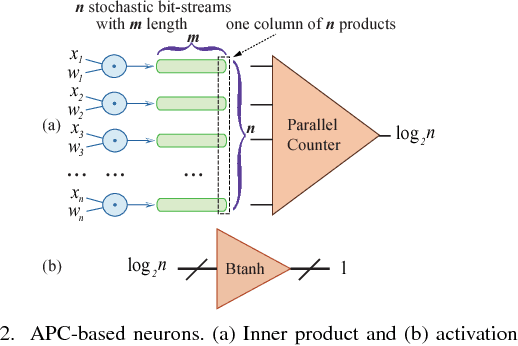
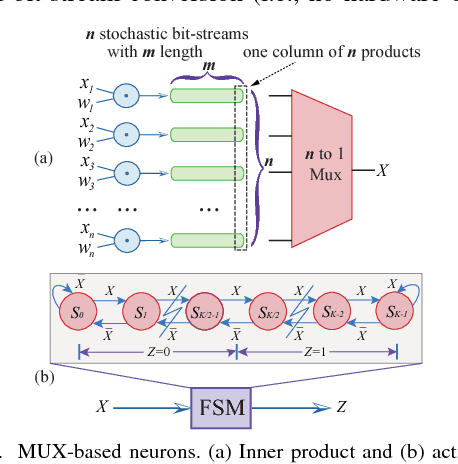
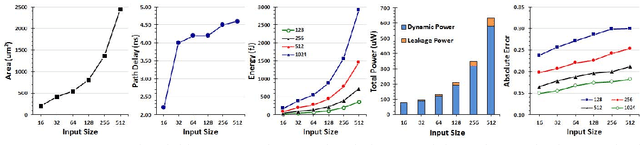
Recently, Deep Convolutional Neural Network (DCNN) has achieved tremendous success in many machine learning applications. Nevertheless, the deep structure has brought significant increases in computation complexity. Largescale deep learning systems mainly operate in high-performance server clusters, thus restricting the application extensions to personal or mobile devices. Previous works on GPU and/or FPGA acceleration for DCNNs show increasing speedup, but ignore other constraints, such as area, power, and energy. Stochastic Computing (SC), as a unique data representation and processing technique, has the potential to enable the design of fully parallel and scalable hardware implementations of large-scale deep learning systems. This paper proposed an automatic design allocation algorithm driven by budget requirement considering overall accuracy performance. This systematic method enables the automatic design of a DCNN where all design parameters are jointly optimized. Experimental results demonstrate that proposed algorithm can achieve a joint optimization of all design parameters given the comprehensive budget of a DCNN.
Learning Topics using Semantic Locality
Apr 11, 2018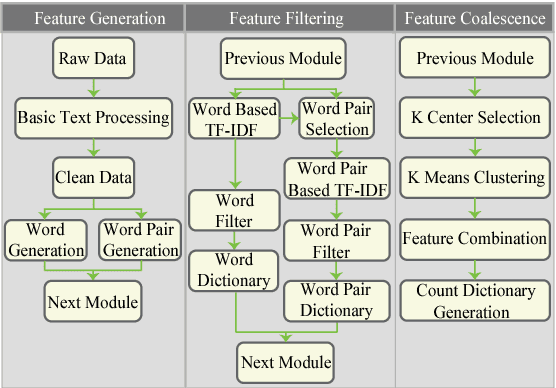
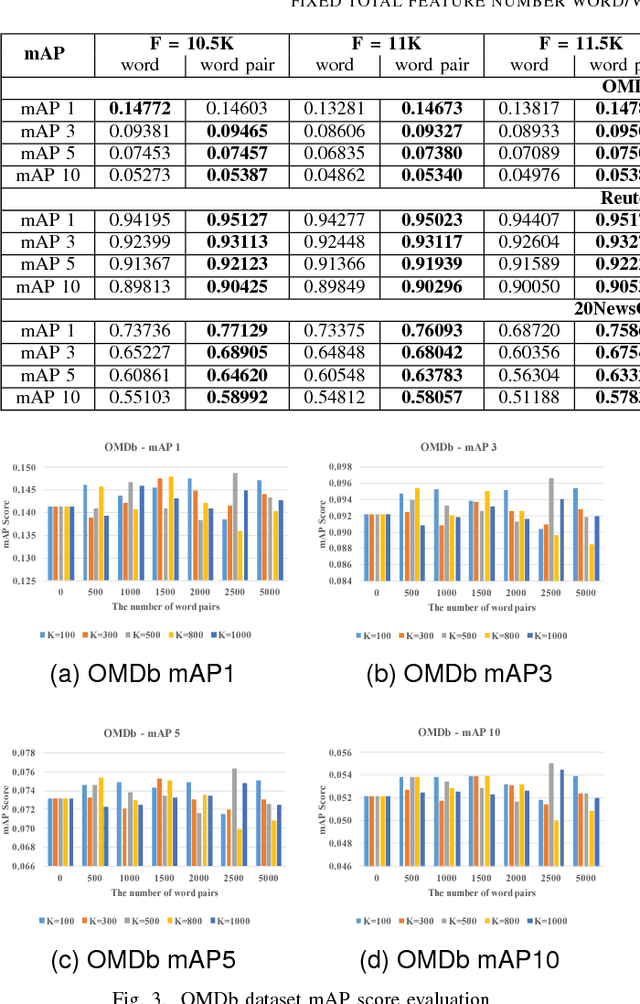
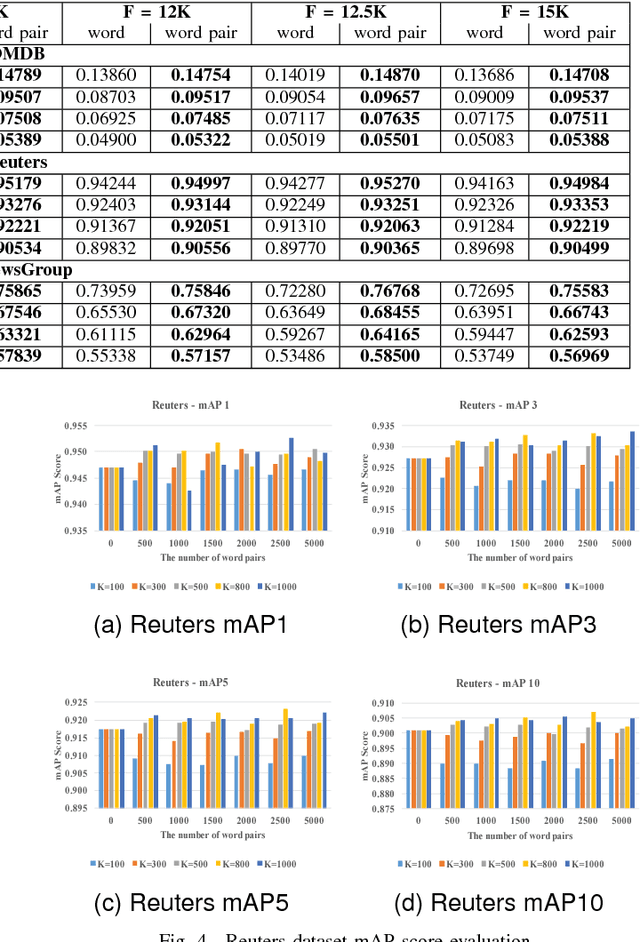
The topic modeling discovers the latent topic probability of the given text documents. To generate the more meaningful topic that better represents the given document, we proposed a new feature extraction technique which can be used in the data preprocessing stage. The method consists of three steps. First, it generates the word/word-pair from every single document. Second, it applies a two-way TF-IDF algorithm to word/word-pair for semantic filtering. Third, it uses the K-means algorithm to merge the word pairs that have the similar semantic meaning. Experiments are carried out on the Open Movie Database (OMDb), Reuters Dataset and 20NewsGroup Dataset. The mean Average Precision score is used as the evaluation metric. Comparing our results with other state-of-the-art topic models, such as Latent Dirichlet allocation and traditional Restricted Boltzmann Machines. Our proposed data preprocessing can improve the generated topic accuracy by up to 12.99\%.
Efficient Recurrent Neural Networks using Structured Matrices in FPGAs
Mar 22, 2018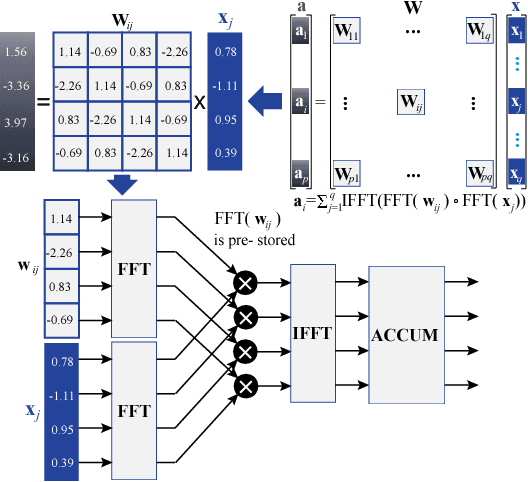
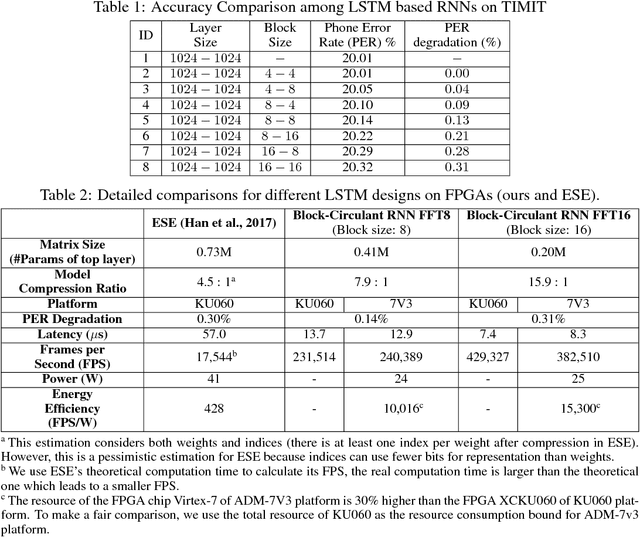
Recurrent Neural Networks (RNNs) are becoming increasingly important for time series-related applications which require efficient and real-time implementations. The recent pruning based work ESE suffers from degradation of performance/energy efficiency due to the irregular network structure after pruning. We propose block-circulant matrices for weight matrix representation in RNNs, thereby achieving simultaneous model compression and acceleration. We aim to implement RNNs in FPGA with highest performance and energy efficiency, with certain accuracy requirement (negligible accuracy degradation). Experimental results on actual FPGA deployments shows that the proposed framework achieves a maximum energy efficiency improvement of 35.7$\times$ compared with ESE.
C-LSTM: Enabling Efficient LSTM using Structured Compression Techniques on FPGAs
Mar 14, 2018
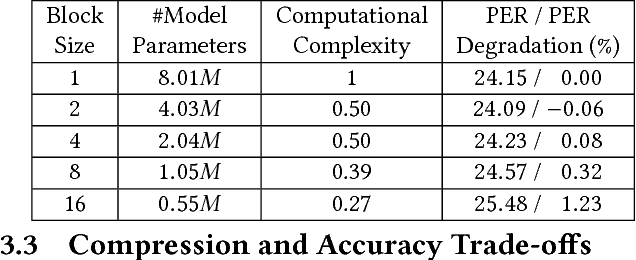
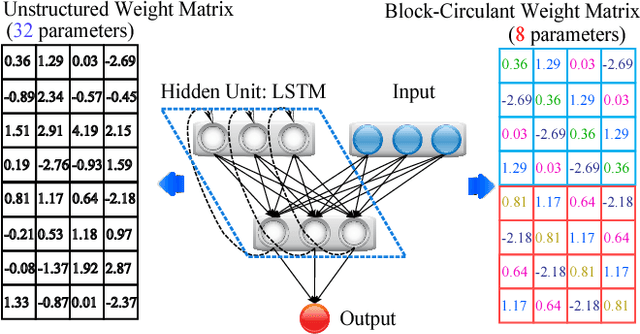
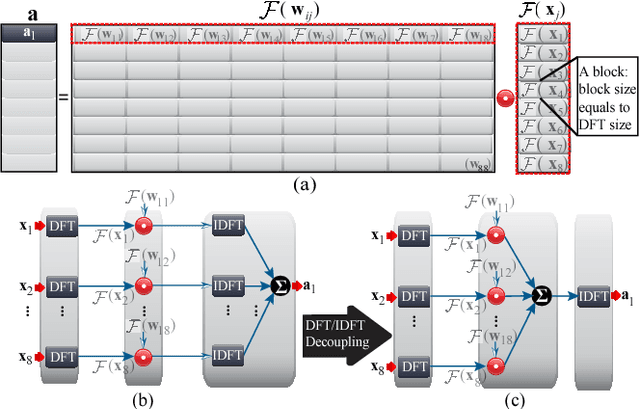
Recently, significant accuracy improvement has been achieved for acoustic recognition systems by increasing the model size of Long Short-Term Memory (LSTM) networks. Unfortunately, the ever-increasing size of LSTM model leads to inefficient designs on FPGAs due to the limited on-chip resources. The previous work proposes to use a pruning based compression technique to reduce the model size and thus speedups the inference on FPGAs. However, the random nature of the pruning technique transforms the dense matrices of the model to highly unstructured sparse ones, which leads to unbalanced computation and irregular memory accesses and thus hurts the overall performance and energy efficiency. In contrast, we propose to use a structured compression technique which could not only reduce the LSTM model size but also eliminate the irregularities of computation and memory accesses. This approach employs block-circulant instead of sparse matrices to compress weight matrices and reduces the storage requirement from $\mathcal{O}(k^2)$ to $\mathcal{O}(k)$. Fast Fourier Transform algorithm is utilized to further accelerate the inference by reducing the computational complexity from $\mathcal{O}(k^2)$ to $\mathcal{O}(k\text{log}k)$. The datapath and activation functions are quantized as 16-bit to improve the resource utilization. More importantly, we propose a comprehensive framework called C-LSTM to automatically optimize and implement a wide range of LSTM variants on FPGAs. According to the experimental results, C-LSTM achieves up to 18.8X and 33.5X gains for performance and energy efficiency compared with the state-of-the-art LSTM implementation under the same experimental setup, and the accuracy degradation is very small.
Towards Ultra-High Performance and Energy Efficiency of Deep Learning Systems: An Algorithm-Hardware Co-Optimization Framework
Feb 18, 2018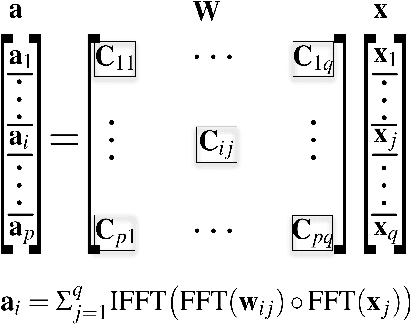
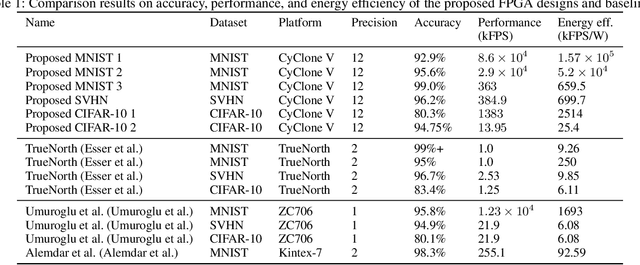
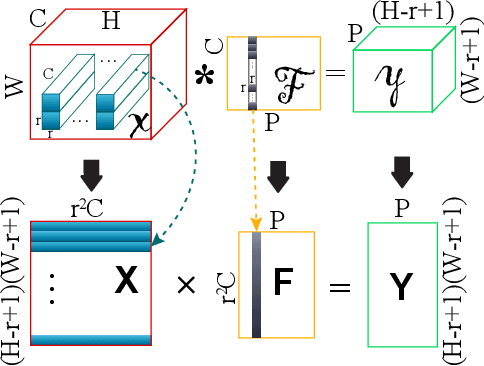
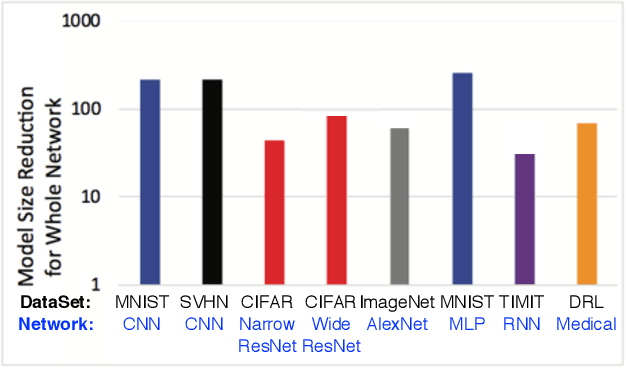
Hardware accelerations of deep learning systems have been extensively investigated in industry and academia. The aim of this paper is to achieve ultra-high energy efficiency and performance for hardware implementations of deep neural networks (DNNs). An algorithm-hardware co-optimization framework is developed, which is applicable to different DNN types, sizes, and application scenarios. The algorithm part adopts the general block-circulant matrices to achieve a fine-grained tradeoff between accuracy and compression ratio. It applies to both fully-connected and convolutional layers and contains a mathematically rigorous proof of the effectiveness of the method. The proposed algorithm reduces computational complexity per layer from O($n^2$) to O($n\log n$) and storage complexity from O($n^2$) to O($n$), both for training and inference. The hardware part consists of highly efficient Field Programmable Gate Array (FPGA)-based implementations using effective reconfiguration, batch processing, deep pipelining, resource re-using, and hierarchical control. Experimental results demonstrate that the proposed framework achieves at least 152X speedup and 71X energy efficiency gain compared with IBM TrueNorth processor under the same test accuracy. It achieves at least 31X energy efficiency gain compared with the reference FPGA-based work.
CirCNN: Accelerating and Compressing Deep Neural Networks Using Block-CirculantWeight Matrices
Aug 29, 2017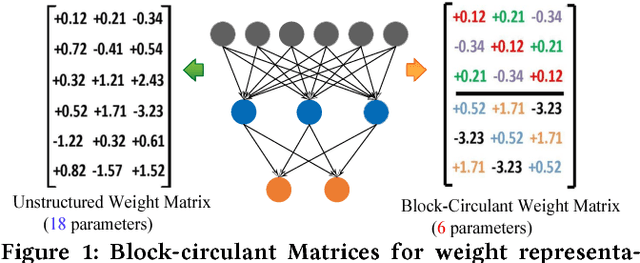
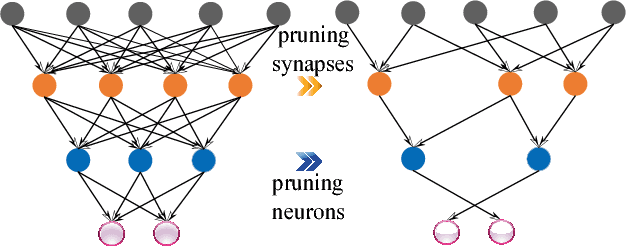
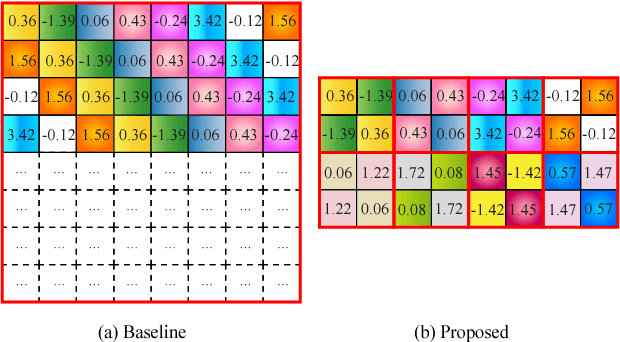
Large-scale deep neural networks (DNNs) are both compute and memory intensive. As the size of DNNs continues to grow, it is critical to improve the energy efficiency and performance while maintaining accuracy. For DNNs, the model size is an important factor affecting performance, scalability and energy efficiency. Weight pruning achieves good compression ratios but suffers from three drawbacks: 1) the irregular network structure after pruning; 2) the increased training complexity; and 3) the lack of rigorous guarantee of compression ratio and inference accuracy. To overcome these limitations, this paper proposes CirCNN, a principled approach to represent weights and process neural networks using block-circulant matrices. CirCNN utilizes the Fast Fourier Transform (FFT)-based fast multiplication, simultaneously reducing the computational complexity (both in inference and training) from O(n2) to O(nlogn) and the storage complexity from O(n2) to O(n), with negligible accuracy loss. Compared to other approaches, CirCNN is distinct due to its mathematical rigor: it can converge to the same effectiveness as DNNs without compression. The CirCNN architecture, a universal DNN inference engine that can be implemented on various hardware/software platforms with configurable network architecture. To demonstrate the performance and energy efficiency, we test CirCNN in FPGA, ASIC and embedded processors. Our results show that CirCNN architecture achieves very high energy efficiency and performance with a small hardware footprint. Based on the FPGA implementation and ASIC synthesis results, CirCNN achieves 6-102X energy efficiency improvements compared with the best state-of-the-art results.