 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeREST: Diffusion-based Real-time End-to-end Streaming Talking Head Generation via ID-Context Caching and Asynchronous Streaming Distillation
Dec 12, 2025Diffusion models have significantly advanced the field of talking head generation. However, the slow inference speeds and non-autoregressive paradigms severely constrain the application of diffusion-based THG models. In this study, we propose REST, the first diffusion-based, real-time, end-to-end streaming audio-driven talking head generation framework. To support real-time end-to-end generation, a compact video latent space is first learned through high spatiotemporal VAE compression. Additionally, to enable autoregressive streaming within the compact video latent space, we introduce an ID-Context Cache mechanism, which integrates ID-Sink and Context-Cache principles to key-value caching for maintaining temporal consistency and identity coherence during long-time streaming generation. Furthermore, an Asynchronous Streaming Distillation (ASD) training strategy is proposed to mitigate error accumulation in autoregressive generation and enhance temporal consistency, which leverages a non-streaming teacher with an asynchronous noise schedule to supervise the training of the streaming student model. REST bridges the gap between autoregressive and diffusion-based approaches, demonstrating substantial value for applications requiring real-time talking head generation. Experimental results demonstrate that REST outperforms state-of-the-art methods in both generation speed and overall performance.
Hardware-Friendly Static Quantization Method for Video Diffusion Transformers
Feb 20, 2025



Diffusion Transformers for video generation have gained significant research interest since the impressive performance of SORA. Efficient deployment of such generative-AI models on GPUs has been demonstrated with dynamic quantization. However, resource-constrained devices cannot support dynamic quantization, and need static quantization of the models for their efficient deployment on AI processors. In this paper, we propose a novel method for the post-training quantization of OpenSora\cite{opensora}, a Video Diffusion Transformer, without relying on dynamic quantization techniques. Our approach employs static quantization, achieving video quality comparable to FP16 and dynamically quantized ViDiT-Q methods, as measured by CLIP, and VQA metrics. In particular, we utilize per-step calibration data to adequately provide a post-training statically quantized model for each time step, incorporating channel-wise quantization for weights and tensor-wise quantization for activations. By further applying the smooth-quantization technique, we can obtain high-quality video outputs with the statically quantized models. Extensive experimental results demonstrate that static quantization can be a viable alternative to dynamic quantization for video diffusion transformers, offering a more efficient approach without sacrificing performance.
Col-OLHTR: A Novel Framework for Multimodal Online Handwritten Text Recognition
Feb 10, 2025



Online Handwritten Text Recognition (OLHTR) has gained considerable attention for its diverse range of applications. Current approaches usually treat OLHTR as a sequence recognition task, employing either a single trajectory or image encoder, or multi-stream encoders, combined with a CTC or attention-based recognition decoder. However, these approaches face several drawbacks: 1) single encoders typically focus on either local trajectories or visual regions, lacking the ability to dynamically capture relevant global features in challenging cases; 2) multi-stream encoders, while more comprehensive, suffer from complex structures and increased inference costs. To tackle this, we propose a Collaborative learning-based OLHTR framework, called Col-OLHTR, that learns multimodal features during training while maintaining a single-stream inference process. Col-OLHTR consists of a trajectory encoder, a Point-to-Spatial Alignment (P2SA) module, and an attention-based decoder. The P2SA module is designed to learn image-level spatial features through trajectory-encoded features and 2D rotary position embeddings. During training, an additional image-stream encoder-decoder is collaboratively trained to provide supervision for P2SA features. At inference, the extra streams are discarded, and only the P2SA module is used and merged before the decoder, simplifying the process while preserving high performance. Extensive experimental results on several OLHTR benchmarks demonstrate the state-of-the-art (SOTA) performance, proving the effectiveness and robustness of our design.
EmotiveTalk: Expressive Talking Head Generation through Audio Information Decoupling and Emotional Video Diffusion
Nov 23, 2024



Diffusion models have revolutionized the field of talking head generation, yet still face challenges in expressiveness, controllability, and stability in long-time generation. In this research, we propose an EmotiveTalk framework to address these issues. Firstly, to realize better control over the generation of lip movement and facial expression, a Vision-guided Audio Information Decoupling (V-AID) approach is designed to generate audio-based decoupled representations aligned with lip movements and expression. Specifically, to achieve alignment between audio and facial expression representation spaces, we present a Diffusion-based Co-speech Temporal Expansion (Di-CTE) module within V-AID to generate expression-related representations under multi-source emotion condition constraints. Then we propose a well-designed Emotional Talking Head Diffusion (ETHD) backbone to efficiently generate highly expressive talking head videos, which contains an Expression Decoupling Injection (EDI) module to automatically decouple the expressions from reference portraits while integrating the target expression information, achieving more expressive generation performance. Experimental results show that EmotiveTalk can generate expressive talking head videos, ensuring the promised controllability of emotions and stability during long-time generation, yielding state-of-the-art performance compared to existing methods.
HiPrompt: Tuning-free Higher-Resolution Generation with Hierarchical MLLM Prompts
Sep 04, 2024



The potential for higher-resolution image generation using pretrained diffusion models is immense, yet these models often struggle with issues of object repetition and structural artifacts especially when scaling to 4K resolution and higher. We figure out that the problem is caused by that, a single prompt for the generation of multiple scales provides insufficient efficacy. In response, we propose HiPrompt, a new tuning-free solution that tackles the above problems by introducing hierarchical prompts. The hierarchical prompts offer both global and local guidance. Specifically, the global guidance comes from the user input that describes the overall content, while the local guidance utilizes patch-wise descriptions from MLLMs to elaborately guide the regional structure and texture generation. Furthermore, during the inverse denoising process, the generated noise is decomposed into low- and high-frequency spatial components. These components are conditioned on multiple prompt levels, including detailed patch-wise descriptions and broader image-level prompts, facilitating prompt-guided denoising under hierarchical semantic guidance. It further allows the generation to focus more on local spatial regions and ensures the generated images maintain coherent local and global semantics, structures, and textures with high definition. Extensive experiments demonstrate that HiPrompt outperforms state-of-the-art works in higher-resolution image generation, significantly reducing object repetition and enhancing structural quality.
NAMER: Non-Autoregressive Modeling for Handwritten Mathematical Expression Recognition
Jul 16, 2024



Recently, Handwritten Mathematical Expression Recognition (HMER) has gained considerable attention in pattern recognition for its diverse applications in document understanding. Current methods typically approach HMER as an image-to-sequence generation task within an autoregressive (AR) encoder-decoder framework. However, these approaches suffer from several drawbacks: 1) a lack of overall language context, limiting information utilization beyond the current decoding step; 2) error accumulation during AR decoding; and 3) slow decoding speed. To tackle these problems, this paper makes the first attempt to build a novel bottom-up Non-AutoRegressive Modeling approach for HMER, called NAMER. NAMER comprises a Visual Aware Tokenizer (VAT) and a Parallel Graph Decoder (PGD). Initially, the VAT tokenizes visible symbols and local relations at a coarse level. Subsequently, the PGD refines all tokens and establishes connectivities in parallel, leveraging comprehensive visual and linguistic contexts. Experiments on CROHME 2014/2016/2019 and HME100K datasets demonstrate that NAMER not only outperforms the current state-of-the-art (SOTA) methods on ExpRate by 1.93%/2.35%/1.49%/0.62%, but also achieves significant speedups of 13.7x and 6.7x faster in decoding time and overall FPS, proving the effectiveness and efficiency of NAMER.
1st Place Winner of the 2024 Pixel-level Video Understanding in the Wild Challenge in Video Panoptic Segmentation and Best Long Video Consistency of Video Semantic Segmentation
Jun 08, 2024



The third Pixel-level Video Understanding in the Wild (PVUW CVPR 2024) challenge aims to advance the state of art in video understanding through benchmarking Video Panoptic Segmentation (VPS) and Video Semantic Segmentation (VSS) on challenging videos and scenes introduced in the large-scale Video Panoptic Segmentation in the Wild (VIPSeg) test set and the large-scale Video Scene Parsing in the Wild (VSPW) test set, respectively. This paper details our research work that achieved the 1st place winner in the PVUW'24 VPS challenge, establishing state of art results in all metrics, including the Video Panoptic Quality (VPQ) and Segmentation and Tracking Quality (STQ). With minor fine-tuning our approach also achieved the 3rd place in the PVUW'24 VSS challenge ranked by the mIoU (mean intersection over union) metric and the first place ranked by the VC16 (16-frame video consistency) metric. Our winning solution stands on the shoulders of giant foundational vision transformer model (DINOv2 ViT-g) and proven multi-stage Decoupled Video Instance Segmentation (DVIS) frameworks for video understanding.
SLoRA: Federated Parameter Efficient Fine-Tuning of Language Models
Aug 12, 2023



Transfer learning via fine-tuning pre-trained transformer models has gained significant success in delivering state-of-the-art results across various NLP tasks. In the absence of centralized data, Federated Learning (FL) can benefit from distributed and private data of the FL edge clients for fine-tuning. However, due to the limited communication, computation, and storage capabilities of edge devices and the huge sizes of popular transformer models, efficient fine-tuning is crucial to make federated training feasible. This work explores the opportunities and challenges associated with applying parameter efficient fine-tuning (PEFT) methods in different FL settings for language tasks. Specifically, our investigation reveals that as the data across users becomes more diverse, the gap between fully fine-tuning the model and employing PEFT methods widens. To bridge this performance gap, we propose a method called SLoRA, which overcomes the key limitations of LoRA in high heterogeneous data scenarios through a novel data-driven initialization technique. Our experimental results demonstrate that SLoRA achieves performance comparable to full fine-tuning, with significant sparse updates with approximately $\sim 1\%$ density while reducing training time by up to $90\%$.
Machine Collaboration
May 06, 2021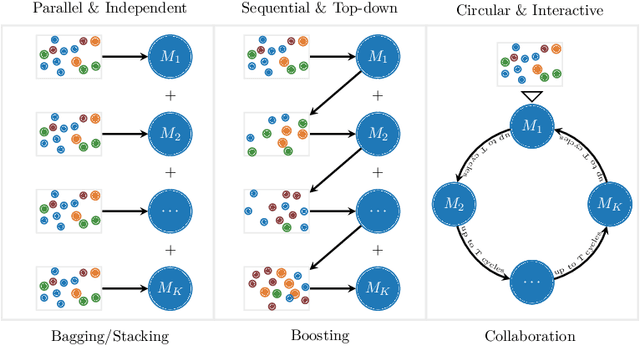
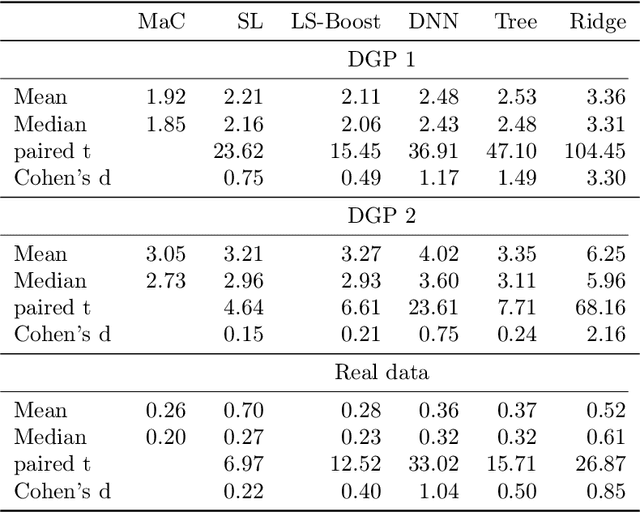
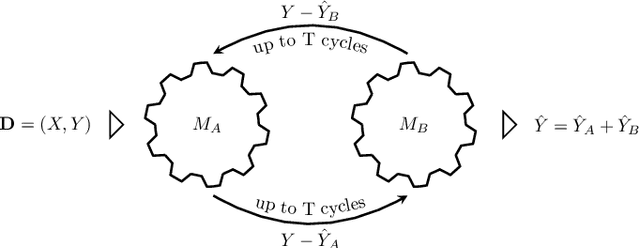
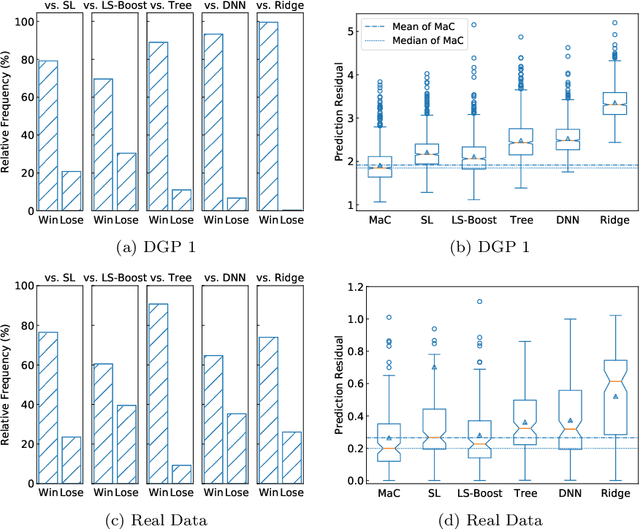
We propose a new ensemble framework for supervised learning, named machine collaboration (MaC), based on a collection of base machines for prediction tasks. Different from bagging/stacking (a parallel & independent framework) and boosting (a sequential & top-down framework), MaC is a type of circular & interactive learning framework. The circular & interactive feature helps the base machines to transfer information circularly and update their own structures and parameters accordingly. The theoretical result on the risk bound of the estimator based on MaC shows that circular & interactive feature can help MaC reduce the risk via a parsimonious ensemble. We conduct extensive experiments on simulated data and 119 benchmark real data sets. The results of the experiments show that in most cases, MaC performs much better than several state-of-the-art methods, including CART, neural network, stacking, and boosting.
Nested Model Averaging on Solution Path for High-dimensional Linear Regression
May 16, 2020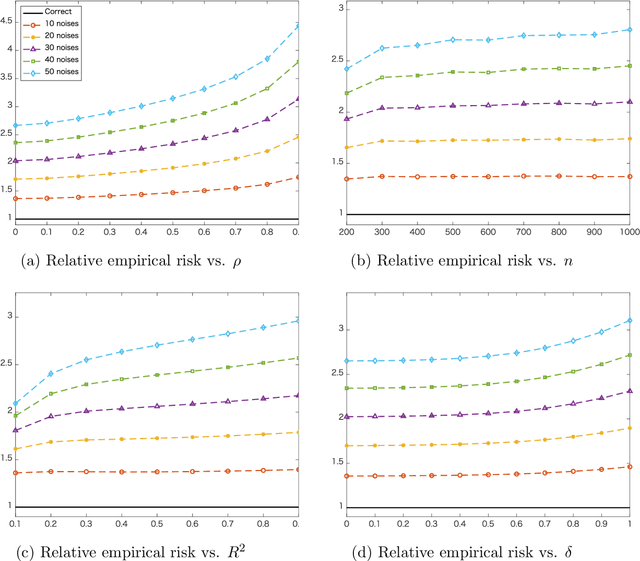
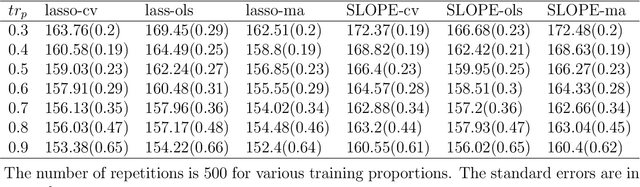
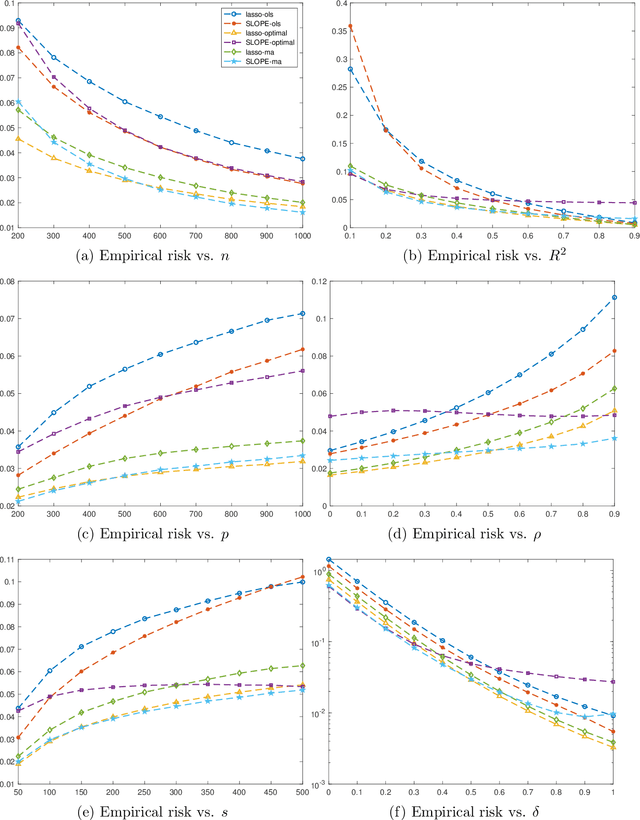
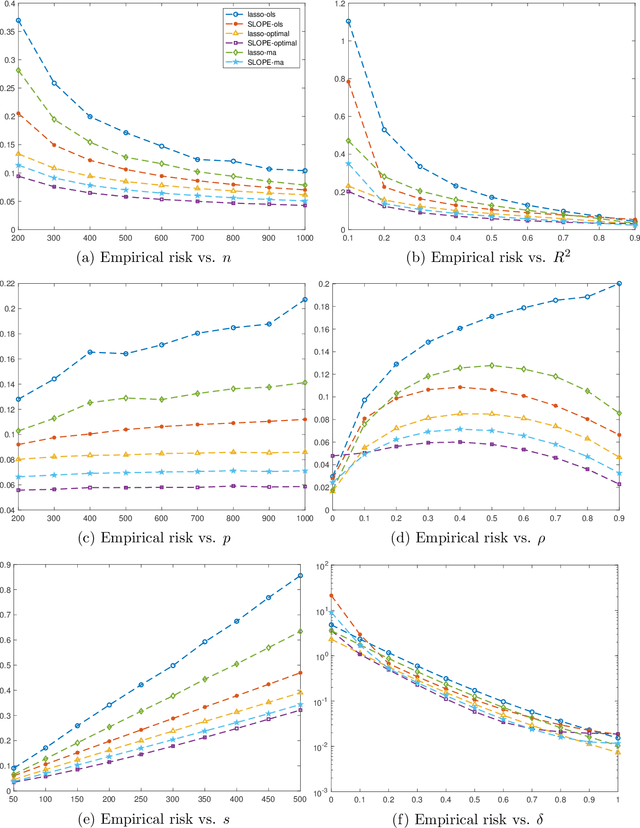
We study the nested model averaging method on the solution path for a high-dimensional linear regression problem. In particular, we propose to combine model averaging with regularized estimators (e.g., lasso and SLOPE) on the solution path for high-dimensional linear regression. In simulation studies, we first conduct a systematic investigation on the impact of predictor ordering on the behavior of nested model averaging, then show that nested model averaging with lasso and SLOPE compares favorably with other competing methods, including the infeasible lasso and SLOPE with the tuning parameter optimally selected. A real data analysis on predicting the per capita violent crime in the United States shows an outstanding performance of the nested model averaging with lasso.