 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic landslide susceptibility mapping over recent three decades to uncover variations in landslide causes in subtropical urban mountainous areas
Aug 23, 2023



Landslide susceptibility assessment (LSA) is of paramount importance in mitigating landslide risks. Recently, there has been a surge in the utilization of data-driven methods for predicting landslide susceptibility due to the growing availability of aerial and satellite data. Nonetheless, the rapid oscillations within the landslide-inducing environment (LIE), primarily due to significant changes in external triggers such as rainfall, pose difficulties for contemporary data-driven LSA methodologies to accommodate LIEs over diverse timespans. This study presents dynamic landslide susceptibility mapping that simply employs multiple predictive models for annual LSA. In practice, this will inevitably encounter small sample problems due to the limited number of landslide samples in certain years. Another concern arises owing to the majority of the existing LSA approaches train black-box models to fit distinct datasets, yet often failing in generalization and providing comprehensive explanations concerning the interactions between input features and predictions. Accordingly, we proposed to meta-learn representations with fast adaptation ability using a few samples and gradient updates; and apply SHAP for each model interpretation and landslide feature permutation. Additionally, we applied MT-InSAR for LSA result enhancement and validation. The chosen study area is Lantau Island, Hong Kong, where we conducted a comprehensive dynamic LSA spanning from 1992 to 2019. The model interpretation results demonstrate that the primary factors responsible for triggering landslides in Lantau Island are terrain slope and extreme rainfall. The results also indicate that the variation in landslide causes can be primarily attributed to extreme rainfall events, which result from global climate change, and the implementation of the Landslip Prevention and Mitigation Programme (LPMitP) by the Hong Kong government.
SwinGar: Spectrum-Inspired Neural Dynamic Deformation for Free-Swinging Garments
Aug 05, 2023



Our work presents a novel spectrum-inspired learning-based approach for generating clothing deformations with dynamic effects and personalized details. Existing methods in the field of clothing animation are limited to either static behavior or specific network models for individual garments, which hinders their applicability in real-world scenarios where diverse animated garments are required. Our proposed method overcomes these limitations by providing a unified framework that predicts dynamic behavior for different garments with arbitrary topology and looseness, resulting in versatile and realistic deformations. First, we observe that the problem of bias towards low frequency always hampers supervised learning and leads to overly smooth deformations. To address this issue, we introduce a frequency-control strategy from a spectral perspective that enhances the generation of high-frequency details of the deformation. In addition, to make the network highly generalizable and able to learn various clothing deformations effectively, we propose a spectral descriptor to achieve a generalized description of the global shape information. Building on the above strategies, we develop a dynamic clothing deformation estimator that integrates frequency-controllable attention mechanisms with long short-term memory. The estimator takes as input expressive features from garments and human bodies, allowing it to automatically output continuous deformations for diverse clothing types, independent of mesh topology or vertex count. Finally, we present a neural collision handling method to further enhance the realism of garments. Our experimental results demonstrate the effectiveness of our approach on a variety of free-swinging garments and its superiority over state-of-the-art methods.
StructuredMesh: 3D Structured Optimization of Façade Components on Photogrammetric Mesh Models using Binary Integer Programming
Jun 07, 2023The lack of fa\c{c}ade structures in photogrammetric mesh models renders them inadequate for meeting the demands of intricate applications. Moreover, these mesh models exhibit irregular surfaces with considerable geometric noise and texture quality imperfections, making the restoration of structures challenging. To address these shortcomings, we present StructuredMesh, a novel approach for reconstructing fa\c{c}ade structures conforming to the regularity of buildings within photogrammetric mesh models. Our method involves capturing multi-view color and depth images of the building model using a virtual camera and employing a deep learning object detection pipeline to semi-automatically extract the bounding boxes of fa\c{c}ade components such as windows, doors, and balconies from the color image. We then utilize the depth image to remap these boxes into 3D space, generating an initial fa\c{c}ade layout. Leveraging architectural knowledge, we apply binary integer programming (BIP) to optimize the 3D layout's structure, encompassing the positions, orientations, and sizes of all components. The refined layout subsequently informs fa\c{c}ade modeling through instance replacement. We conducted experiments utilizing building mesh models from three distinct datasets, demonstrating the adaptability, robustness, and noise resistance of our proposed methodology. Furthermore, our 3D layout evaluation metrics reveal that the optimized layout enhances precision, recall, and F-score by 6.5%, 4.5%, and 5.5%, respectively, in comparison to the initial layout.
BCE-Net: Reliable Building Footprints Change Extraction based on Historical Map and Up-to-Date Images using Contrastive Learning
Apr 14, 2023Automatic and periodic recompiling of building databases with up-to-date high-resolution images has become a critical requirement for rapidly developing urban environments. However, the architecture of most existing approaches for change extraction attempts to learn features related to changes but ignores objectives related to buildings. This inevitably leads to the generation of significant pseudo-changes, due to factors such as seasonal changes in images and the inclination of building fa\c{c}ades. To alleviate the above-mentioned problems, we developed a contrastive learning approach by validating historical building footprints against single up-to-date remotely sensed images. This contrastive learning strategy allowed us to inject the semantics of buildings into a pipeline for the detection of changes, which is achieved by increasing the distinguishability of features of buildings from those of non-buildings. In addition, to reduce the effects of inconsistencies between historical building polygons and buildings in up-to-date images, we employed a deformable convolutional neural network to learn offsets intuitively. In summary, we formulated a multi-branch building extraction method that identifies newly constructed and removed buildings, respectively. To validate our method, we conducted comparative experiments using the public Wuhan University building change detection dataset and a more practical dataset named SI-BU that we established. Our method achieved F1 scores of 93.99% and 70.74% on the above datasets, respectively. Moreover, when the data of the public dataset were divided in the same manner as in previous related studies, our method achieved an F1 score of 94.63%, which surpasses that of the state-of-the-art method.
SuperpixelGraph: Semi-automatic generation of building footprint through semantic-sensitive superpixel and neural graph networks
Apr 12, 2023



Most urban applications necessitate building footprints in the form of concise vector graphics with sharp boundaries rather than pixel-wise raster images. This need contrasts with the majority of existing methods, which typically generate over-smoothed footprint polygons. Editing these automatically produced polygons can be inefficient, if not more time-consuming than manual digitization. This paper introduces a semi-automatic approach for building footprint extraction through semantically-sensitive superpixels and neural graph networks. Drawing inspiration from object-based classification techniques, we first learn to generate superpixels that are not only boundary-preserving but also semantically-sensitive. The superpixels respond exclusively to building boundaries rather than other natural objects, while simultaneously producing semantic segmentation of the buildings. These intermediate superpixel representations can be naturally considered as nodes within a graph. Consequently, graph neural networks are employed to model the global interactions among all superpixels and enhance the representativeness of node features for building segmentation. Classical approaches are utilized to extract and regularize boundaries for the vectorized building footprints. Utilizing minimal clicks and straightforward strokes, we efficiently accomplish accurate segmentation outcomes, eliminating the necessity for editing polygon vertices. Our proposed approach demonstrates superior precision and efficacy, as validated by experimental assessments on various public benchmark datasets. We observe a 10\% enhancement in the metric for superpixel clustering and an 8\% increment in vector graphics evaluation, when compared with established techniques. Additionally, we have devised an optimized and sophisticated pipeline for interactive editing, poised to further augment the overall quality of the results.
Semantic Image Translation for Repairing the Texture Defects of Building Models
Apr 01, 2023The accurate representation of 3D building models in urban environments is significantly hindered by challenges such as texture occlusion, blurring, and missing details, which are difficult to mitigate through standard photogrammetric texture mapping pipelines. Current image completion methods often struggle to produce structured results and effectively handle the intricate nature of highly-structured fa\c{c}ade textures with diverse architectural styles. Furthermore, existing image synthesis methods encounter difficulties in preserving high-frequency details and artificial regular structures, which are essential for achieving realistic fa\c{c}ade texture synthesis. To address these challenges, we introduce a novel approach for synthesizing fa\c{c}ade texture images that authentically reflect the architectural style from a structured label map, guided by a ground-truth fa\c{c}ade image. In order to preserve fine details and regular structures, we propose a regularity-aware multi-domain method that capitalizes on frequency information and corner maps. We also incorporate SEAN blocks into our generator to enable versatile style transfer. To generate plausible structured images without undesirable regions, we employ image completion techniques to remove occlusions according to semantics prior to image inference. Our proposed method is also capable of synthesizing texture images with specific styles for fa\c{c}ades that lack pre-existing textures, using manually annotated labels. Experimental results on publicly available fa\c{c}ade image and 3D model datasets demonstrate that our method yields superior results and effectively addresses issues associated with flawed textures. The code and datasets will be made publicly available for further research and development.
Self-supervised remote sensing feature learning: Learning Paradigms, Challenges, and Future Works
Nov 15, 2022Deep learning has achieved great success in learning features from massive remote sensing images (RSIs). To better understand the connection between feature learning paradigms (e.g., unsupervised feature learning (USFL), supervised feature learning (SFL), and self-supervised feature learning (SSFL)), this paper analyzes and compares them from the perspective of feature learning signals, and gives a unified feature learning framework. Under this unified framework, we analyze the advantages of SSFL over the other two learning paradigms in RSIs understanding tasks and give a comprehensive review of the existing SSFL work in RS, including the pre-training dataset, self-supervised feature learning signals, and the evaluation methods. We further analyze the effect of SSFL signals and pre-training data on the learned features to provide insights for improving the RSI feature learning. Finally, we briefly discuss some open problems and possible research directions.
TOV: The Original Vision Model for Optical Remote Sensing Image Understanding via Self-supervised Learning
Apr 10, 2022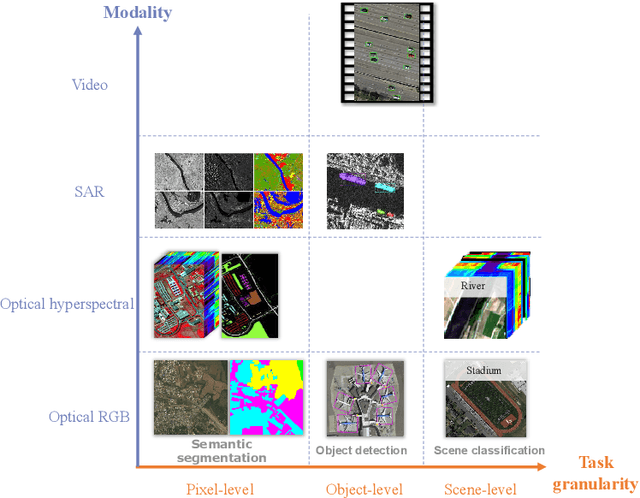

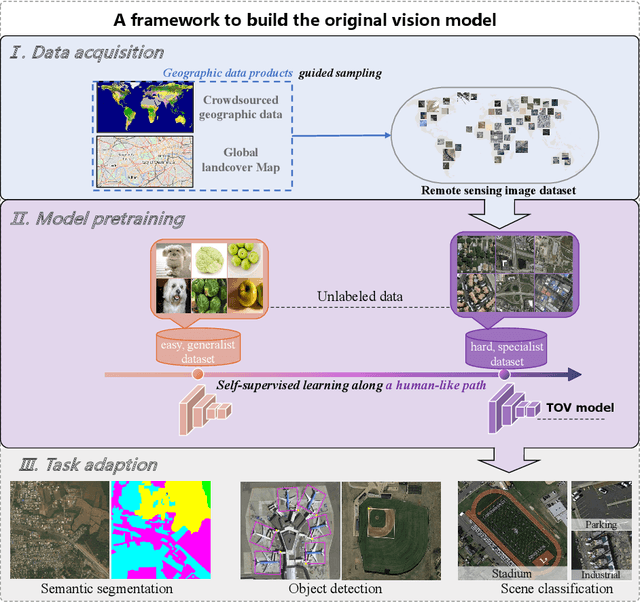

Do we on the right way for remote sensing image understanding (RSIU) by training models via supervised data-dependent and task-dependent way, instead of human vision in a label-free and task-independent way? We argue that a more desirable RSIU model should be trained with intrinsic structure from data rather that extrinsic human labels to realize generalizability across a wide range of RSIU tasks. According to this hypothesis, we proposed \textbf{T}he \textbf{O}riginal \textbf{V}ision model (TOV) in remote sensing filed. Trained by massive unlabeled optical data along a human-like self-supervised learning (SSL) path that is from general knowledge to specialized knowledge, TOV model can be easily adapted to various RSIU tasks, including scene classification, object detection, and semantic segmentation, and outperforms dominant ImageNet supervised pretrained method as well as two recently proposed SSL pretrained methods on majority of 12 publicly available benchmarks. Moreover, we analyze the influences of two key factors on the performance of building TOV model for RSIU, including the influence of using different data sampling methods and the selection of learning paths during self-supervised optimization. We believe that a general model which is trained by a label-free and task-independent way may be the next paradigm for RSIU and hope the insights distilled from this study can help to foster the development of an original vision model for RSIU.
Semi-Supervised Adversarial Recognition of Refined Window Structures for Inverse Procedural Façade Modeling
Jan 22, 2022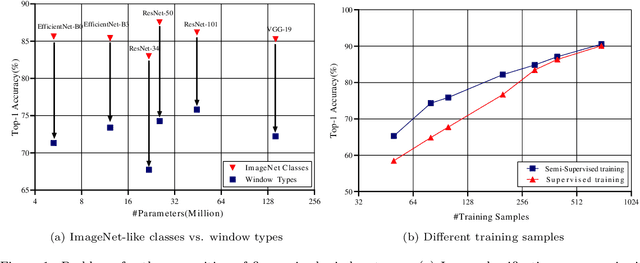

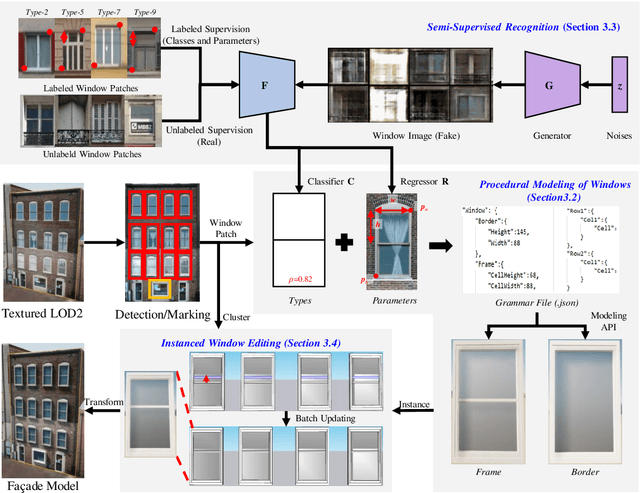
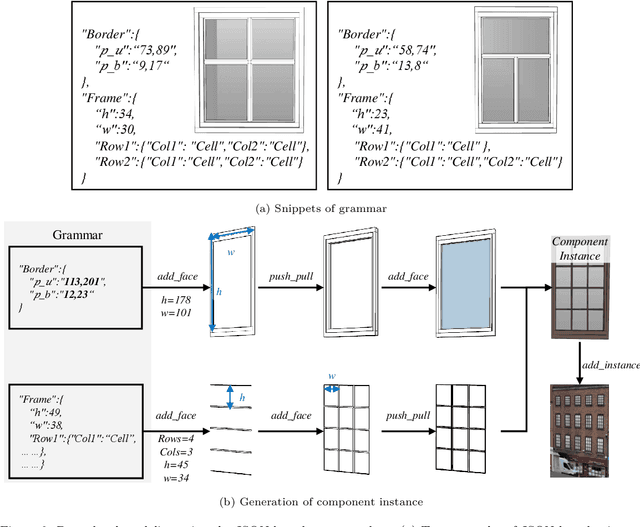
Deep learning methods are notoriously data-hungry, which requires a large number of labeled samples. Unfortunately, the large amount of interactive sample labeling efforts has dramatically hindered the application of deep learning methods, especially for 3D modeling tasks, which require heterogeneous samples. To alleviate the work of data annotation for learned 3D modeling of fa\c{c}ades, this paper proposed a semi-supervised adversarial recognition strategy embedded in inverse procedural modeling. Beginning with textured LOD-2 (Level-of-Details) models, we use the classical convolutional neural networks to recognize the types and estimate the parameters of windows from image patches. The window types and parameters are then assembled into procedural grammar. A simple procedural engine is built inside an existing 3D modeling software, producing fine-grained window geometries. To obtain a useful model from a few labeled samples, we leverage the generative adversarial network to train the feature extractor in a semi-supervised manner. The adversarial training strategy can also exploit unlabeled data to make the training phase more stable. Experiments using publicly available fa\c{c}ade image datasets reveal that the proposed training strategy can obtain about 10% improvement in classification accuracy and 50% improvement in parameter estimation under the same network structure. In addition, performance gains are more pronounced when testing against unseen data featuring different fa\c{c}ade styles.
Reviewing continual learning from the perspective of human-level intelligence
Nov 23, 2021
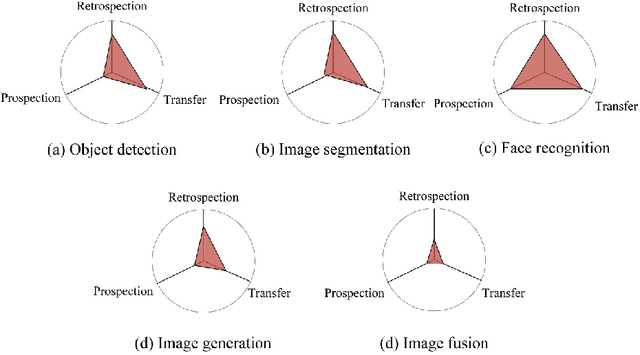
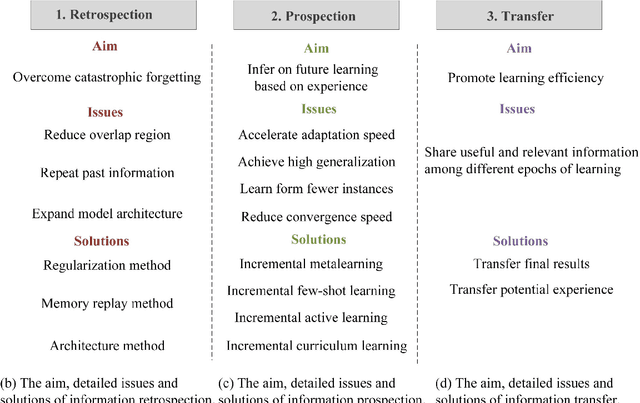
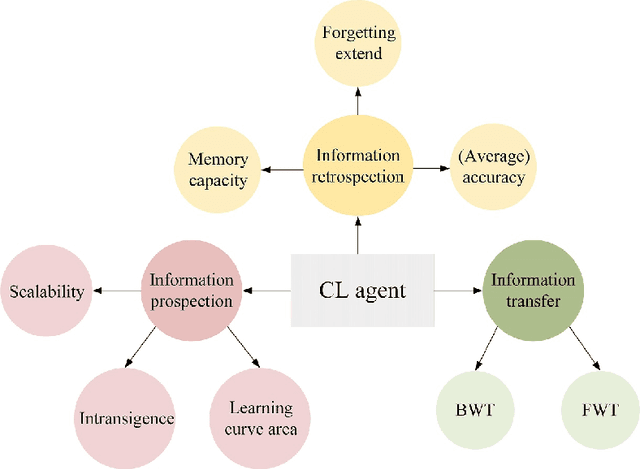
Humans' continual learning (CL) ability is closely related to Stability Versus Plasticity Dilemma that describes how humans achieve ongoing learning capacity and preservation for learned information. The notion of CL has always been present in artificial intelligence (AI) since its births. This paper proposes a comprehensive review of CL. Different from previous reviews that mainly focus on the catastrophic forgetting phenomenon in CL, this paper surveys CL from a more macroscopic perspective based on the Stability Versus Plasticity mechanism. Analogous to biological counterpart, "smart" AI agents are supposed to i) remember previously learned information (information retrospection); ii) infer on new information continuously (information prospection:); iii) transfer useful information (information transfer), to achieve high-level CL. According to the taxonomy, evaluation metrics, algorithms, applications as well as some open issues are then introduced. Our main contributions concern i) rechecking CL from the level of artificial general intelligence; ii) providing a detailed and extensive overview on CL topics; iii) presenting some novel ideas on the potential development of CL.