 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoSOTA: An End-to-End Automated Research System for State-of-the-Art AI Model Discovery
Apr 07, 2026Artificial intelligence research increasingly depends on prolonged cycles of reproduction, debugging, and iterative refinement to achieve State-Of-The-Art (SOTA) performance, creating a growing need for systems that can accelerate the full pipeline of empirical model optimization. In this work, we introduce AutoSOTA, an end-to-end automated research system that advances the latest SOTA models published in top-tier AI papers to reproducible and empirically improved new SOTA models. We formulate this problem through three tightly coupled stages: resource preparation and goal setting; experiment evaluation; and reflection and ideation. To tackle this problem, AutoSOTA adopts a multi-agent architecture with eight specialized agents that collaboratively ground papers to code and dependencies, initialize and repair execution environments, track long-horizon experiments, generate and schedule optimization ideas, and supervise validity to avoid spurious gains. We evaluate AutoSOTA on recent research papers collected from eight top-tier AI conferences under filters for code availability and execution cost. Across these papers, AutoSOTA achieves strong end-to-end performance in both automated replication and subsequent optimization. Specifically, it successfully discovers 105 new SOTA models that surpass the original reported methods, averaging approximately five hours per paper. Case studies spanning LLM, NLP, computer vision, time series, and optimization further show that the system can move beyond routine hyperparameter tuning to identify architectural innovation, algorithmic redesigns, and workflow-level improvements. These results suggest that end-to-end research automation can serve not only as a performance optimizer, but also as a new form of research infrastructure that reduces repetitive experimental burden and helps redirect human attention toward higher-level scientific creativity.
AIoT-based Continuous, Contextualized, and Explainable Driving Assessment for Older Adults
Feb 28, 2026The world is undergoing a major demographic shift as older adults become a rapidly growing share of the population, creating new challenges for driving safety. In car-dependent regions such as the United States, driving remains essential for independence, access to services, and social participation. At the same time, aging can introduce gradual changes in vision, attention, reaction time, and driving control that quietly reduce safety. Today's assessment methods rely largely on infrequent clinic visits or simple screening tools, offering only a brief snapshot and failing to reflect how an older adult actually drives on the road. Our work starts from the observation that everyday driving provides a continuous record of functional ability and captures how a driver responds to traffic, navigates complex roads, and manages routine behavior. Leveraging this insight, we propose AURA, an Artificial Intelligence of Things (AIoT) framework for continuous, real-world assessment of driving safety among older adults. AURA integrates richer in-vehicle sensing, multi-scale behavioral modeling, and context-aware analysis to extract detailed indicators of driving performance from routine trips. It organizes fine-grained actions into longer behavioral trajectories and separates age-related performance changes from situational factors such as traffic, road design, or weather. By integrating sensing, modeling, and interpretation within a privacy-preserving edge architecture, AURA provides a foundation for proactive, individualized support that helps older adults drive safely. This paper outlines the design principles, challenges, and research opportunities needed to build reliable, real-world monitoring systems that promote safer aging behind the wheel.
SwinGar: Spectrum-Inspired Neural Dynamic Deformation for Free-Swinging Garments
Aug 05, 2023



Our work presents a novel spectrum-inspired learning-based approach for generating clothing deformations with dynamic effects and personalized details. Existing methods in the field of clothing animation are limited to either static behavior or specific network models for individual garments, which hinders their applicability in real-world scenarios where diverse animated garments are required. Our proposed method overcomes these limitations by providing a unified framework that predicts dynamic behavior for different garments with arbitrary topology and looseness, resulting in versatile and realistic deformations. First, we observe that the problem of bias towards low frequency always hampers supervised learning and leads to overly smooth deformations. To address this issue, we introduce a frequency-control strategy from a spectral perspective that enhances the generation of high-frequency details of the deformation. In addition, to make the network highly generalizable and able to learn various clothing deformations effectively, we propose a spectral descriptor to achieve a generalized description of the global shape information. Building on the above strategies, we develop a dynamic clothing deformation estimator that integrates frequency-controllable attention mechanisms with long short-term memory. The estimator takes as input expressive features from garments and human bodies, allowing it to automatically output continuous deformations for diverse clothing types, independent of mesh topology or vertex count. Finally, we present a neural collision handling method to further enhance the realism of garments. Our experimental results demonstrate the effectiveness of our approach on a variety of free-swinging garments and its superiority over state-of-the-art methods.
Detail-aware Deep Clothing Animations Infused with Multi-source Attributes
Dec 15, 2021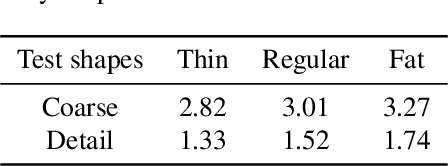
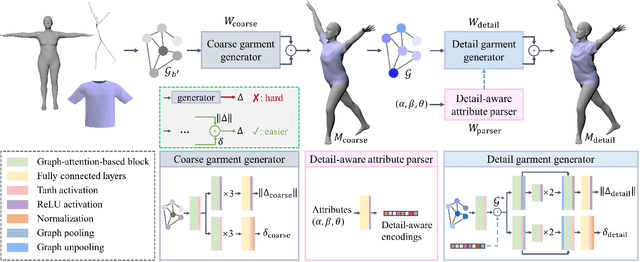
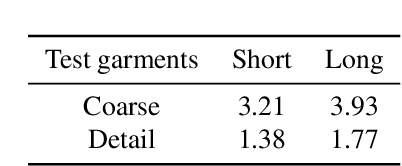
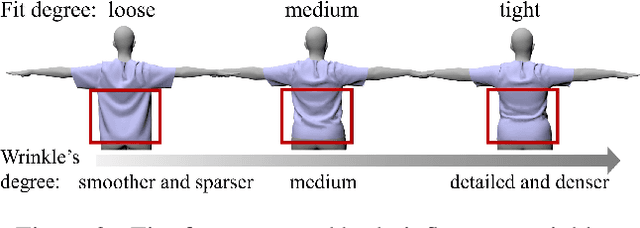
This paper presents a novel learning-based clothing deformation method to generate rich and reasonable detailed deformations for garments worn by bodies of various shapes in various animations. In contrast to existing learning-based methods, which require numerous trained models for different garment topologies or poses and are unable to easily realize rich details, we use a unified framework to produce high fidelity deformations efficiently and easily. To address the challenging issue of predicting deformations influenced by multi-source attributes, we propose three strategies from novel perspectives. Specifically, we first found that the fit between the garment and the body has an important impact on the degree of folds. We then designed an attribute parser to generate detail-aware encodings and infused them into the graph neural network, therefore enhancing the discrimination of details under diverse attributes. Furthermore, to achieve better convergence and avoid overly smooth deformations, we proposed output reconstruction to mitigate the complexity of the learning task. Experiment results show that our proposed deformation method achieves better performance over existing methods in terms of generalization ability and quality of details.