 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLOGIGEN: Logic-Driven Generation of Verifiable Agentic Tasks
Feb 28, 2026The evolution of Large Language Models (LLMs) from static instruction-followers to autonomous agents necessitates operating within complex, stateful environments to achieve precise state-transition objectives. However, this paradigm is bottlenecked by data scarcity, as existing tool-centric reverse-synthesis pipelines fail to capture the rigorous logic of real-world applications. We introduce \textbf{LOGIGEN}, a logic-driven framework that synthesizes verifiable training data based on three core pillars: \textbf{Hard-Compiled Policy Grounding}, \textbf{Logic-Driven Forward Synthesis}, and \textbf{Deterministic State Verification}. Specifically, a Triple-Agent Orchestration is employed: the \textbf{Architect} compiles natural-language policy into database constraints to enforce hard rules; the \textbf{Set Designer} initializes boundary-adjacent states to trigger critical policy conflicts; and the \textbf{Explorer} searches this environment to discover causal solution paths. This framework yields a dataset of 20,000 complex tasks across 8 domains, where validity is strictly guaranteed by checking exact state equivalence. Furthermore, we propose a verification-based training protocol where Supervised Fine-Tuning (SFT) on verifiable trajectories establishes compliance with hard-compiled policy, while Reinforcement Learning (RL) guided by dense state-rewards refines long-horizon goal achievement. On $τ^2$-Bench, LOGIGEN-32B(RL) achieves a \textbf{79.5\% success rate}, substantially outperforming the base model (40.7\%). These results demonstrate that logic-driven synthesis combined with verification-based training effectively constructs the causally valid trajectories needed for next-generation agents.
QianfanHuijin Technical Report: A Novel Multi-Stage Training Paradigm for Finance Industrial LLMs
Dec 30, 2025Domain-specific enhancement of Large Language Models (LLMs) within the financial context has long been a focal point of industrial application. While previous models such as BloombergGPT and Baichuan-Finance primarily focused on knowledge enhancement, the deepening complexity of financial services has driven a growing demand for models that possess not only domain knowledge but also robust financial reasoning and agentic capabilities. In this paper, we present QianfanHuijin, a financial domain LLM, and propose a generalizable multi-stage training paradigm for industrial model enhancement. Our approach begins with Continual Pre-training (CPT) on financial corpora to consolidate the knowledge base. This is followed by a fine-grained Post-training pipeline designed with increasing specificity: starting with Financial SFT, progressing to Finance Reasoning RL and Finance Agentic RL, and culminating in General RL aligned with real-world business scenarios. Empirical results demonstrate that QianfanHuijin achieves superior performance across various authoritative financial benchmarks. Furthermore, ablation studies confirm that the targeted Reasoning RL and Agentic RL stages yield significant gains in their respective capabilities. These findings validate our motivation and suggest that this fine-grained, progressive post-training methodology is poised to become a mainstream paradigm for various industrial-enhanced LLMs.
TOV: The Original Vision Model for Optical Remote Sensing Image Understanding via Self-supervised Learning
Apr 10, 2022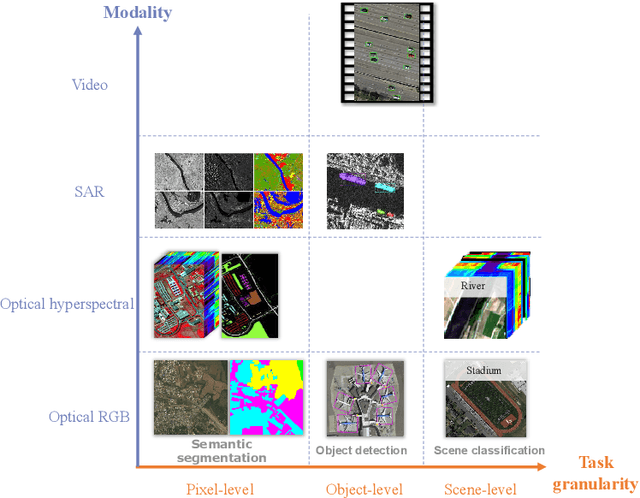

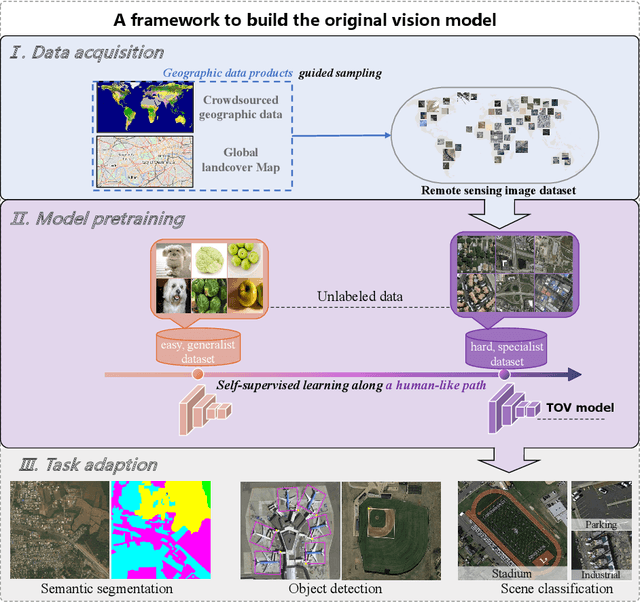

Do we on the right way for remote sensing image understanding (RSIU) by training models via supervised data-dependent and task-dependent way, instead of human vision in a label-free and task-independent way? We argue that a more desirable RSIU model should be trained with intrinsic structure from data rather that extrinsic human labels to realize generalizability across a wide range of RSIU tasks. According to this hypothesis, we proposed \textbf{T}he \textbf{O}riginal \textbf{V}ision model (TOV) in remote sensing filed. Trained by massive unlabeled optical data along a human-like self-supervised learning (SSL) path that is from general knowledge to specialized knowledge, TOV model can be easily adapted to various RSIU tasks, including scene classification, object detection, and semantic segmentation, and outperforms dominant ImageNet supervised pretrained method as well as two recently proposed SSL pretrained methods on majority of 12 publicly available benchmarks. Moreover, we analyze the influences of two key factors on the performance of building TOV model for RSIU, including the influence of using different data sampling methods and the selection of learning paths during self-supervised optimization. We believe that a general model which is trained by a label-free and task-independent way may be the next paradigm for RSIU and hope the insights distilled from this study can help to foster the development of an original vision model for RSIU.
Remote Sensing Image Scene Classification with Self-Supervised Paradigm under Limited Labeled Samples
Oct 02, 2020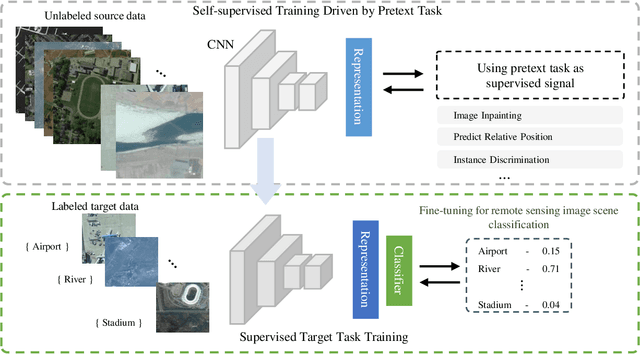
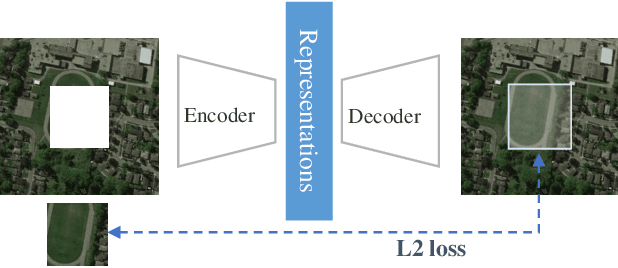

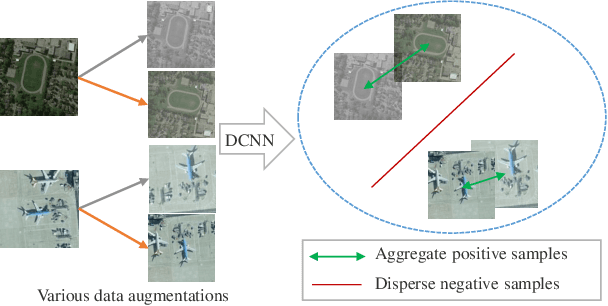
With the development of deep learning, supervised learning methods perform well in remote sensing images (RSIs) scene classification. However, supervised learning requires a huge number of annotated data for training. When labeled samples are not sufficient, the most common solution is to fine-tune the pre-training models using a large natural image dataset (e.g. ImageNet). However, this learning paradigm is not a panacea, especially when the target remote sensing images (e.g. multispectral and hyperspectral data) have different imaging mechanisms from RGB natural images. To solve this problem, we introduce new self-supervised learning (SSL) mechanism to obtain the high-performance pre-training model for RSIs scene classification from large unlabeled data. Experiments on three commonly used RSIs scene classification datasets demonstrated that this new learning paradigm outperforms the traditional dominant ImageNet pre-trained model. Moreover, we analyze the impacts of several factors in SSL on RSIs scene classification tasks, including the choice of self-supervised signals, the domain difference between the source and target dataset, and the amount of pre-training data. The insights distilled from our studies can help to foster the development of SSL in the remote sensing community. Since SSL could learn from unlabeled massive RSIs which are extremely easy to obtain, it will be a potentially promising way to alleviate dependence on labeled samples and thus efficiently solve many problems, such as global mapping.