 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetection of Chagas Disease from the ECG: The George B. Moody PhysioNet Challenge 2025
Oct 02, 2025Objective: Chagas disease is a parasitic infection that is endemic to South America, Central America, and, more recently, the U.S., primarily transmitted by insects. Chronic Chagas disease can cause cardiovascular diseases and digestive problems. Serological testing capacities for Chagas disease are limited, but Chagas cardiomyopathy often manifests in ECGs, providing an opportunity to prioritize patients for testing and treatment. Approach: The George B. Moody PhysioNet Challenge 2025 invites teams to develop algorithmic approaches for identifying Chagas disease from electrocardiograms (ECGs). Main results: This Challenge provides multiple innovations. First, we leveraged several datasets with labels from patient reports and serological testing, provided a large dataset with weak labels and smaller datasets with strong labels. Second, we augmented the data to support model robustness and generalizability to unseen data sources. Third, we applied an evaluation metric that captured the local serological testing capacity for Chagas disease to frame the machine learning problem as a triage task. Significance: Over 630 participants from 111 teams submitted over 1300 entries during the Challenge, representing diverse approaches from academia and industry worldwide.
InstInfer: In-Storage Attention Offloading for Cost-Effective Long-Context LLM Inference
Sep 08, 2024



The widespread of Large Language Models (LLMs) marks a significant milestone in generative AI. Nevertheless, the increasing context length and batch size in offline LLM inference escalate the memory requirement of the key-value (KV) cache, which imposes a huge burden on the GPU VRAM, especially for resource-constraint scenarios (e.g., edge computing and personal devices). Several cost-effective solutions leverage host memory or SSDs to reduce storage costs for offline inference scenarios and improve the throughput. Nevertheless, they suffer from significant performance penalties imposed by intensive KV cache accesses due to limited PCIe bandwidth. To address these issues, we propose InstInfer, a novel LLM inference system that offloads the most performance-critical computation (i.e., attention in decoding phase) and data (i.e., KV cache) parts to Computational Storage Drives (CSDs), which minimize the enormous KV transfer overheads. InstInfer designs a dedicated flash-aware in-storage attention engine with KV cache management mechanisms to exploit the high internal bandwidths of CSDs instead of being limited by the PCIe bandwidth. The optimized P2P transmission between GPU and CSDs further reduces data migration overheads. Experimental results demonstrate that for a 13B model using an NVIDIA A6000 GPU, InstInfer improves throughput for long-sequence inference by up to 11.1$\times$, compared to existing SSD-based solutions such as FlexGen.
Privacy-preserving Universal Adversarial Defense for Black-box Models
Aug 20, 2024



Deep neural networks (DNNs) are increasingly used in critical applications such as identity authentication and autonomous driving, where robustness against adversarial attacks is crucial. These attacks can exploit minor perturbations to cause significant prediction errors, making it essential to enhance the resilience of DNNs. Traditional defense methods often rely on access to detailed model information, which raises privacy concerns, as model owners may be reluctant to share such data. In contrast, existing black-box defense methods fail to offer a universal defense against various types of adversarial attacks. To address these challenges, we introduce DUCD, a universal black-box defense method that does not require access to the target model's parameters or architecture. Our approach involves distilling the target model by querying it with data, creating a white-box surrogate while preserving data privacy. We further enhance this surrogate model using a certified defense based on randomized smoothing and optimized noise selection, enabling robust defense against a broad range of adversarial attacks. Comparative evaluations between the certified defenses of the surrogate and target models demonstrate the effectiveness of our approach. Experiments on multiple image classification datasets show that DUCD not only outperforms existing black-box defenses but also matches the accuracy of white-box defenses, all while enhancing data privacy and reducing the success rate of membership inference attacks.
Progressive Domain Adaptation for Thermal Infrared Object Tracking
Jul 28, 2024



Due to the lack of large-scale labeled Thermal InfraRed (TIR) training datasets, most existing TIR trackers are trained directly on RGB datasets. However, tracking methods trained on RGB datasets suffer a significant drop-off in TIR data due to the domain shift issue. To this end, in this work, we propose a Progressive Domain Adaptation framework for TIR Tracking (PDAT), which transfers useful knowledge learned from RGB tracking to TIR tracking. The framework makes full use of large-scale labeled RGB datasets without requiring time-consuming and labor-intensive labeling of large-scale TIR data. Specifically, we first propose an adversarial-based global domain adaptation module to reduce domain gap on the feature level coarsely. Second, we design a clustering-based subdomain adaptation method to further align the feature distributions of the RGB and TIR datasets finely. These two domain adaptation modules gradually eliminate the discrepancy between the two domains, and thus learn domain-invariant fine-grained features through progressive training. Additionally, we collect a largescale TIR dataset with over 1.48 million unlabeled TIR images for training the proposed domain adaptation framework. Experimental results on five TIR tracking benchmarks show that the proposed method gains a nearly 6% success rate, demonstrating its effectiveness.
Unveiling Structural Memorization: Structural Membership Inference Attack for Text-to-Image Diffusion Models
Jul 18, 2024With the rapid advancements of large-scale text-to-image diffusion models, various practical applications have emerged, bringing significant convenience to society. However, model developers may misuse the unauthorized data to train diffusion models. These data are at risk of being memorized by the models, thus potentially violating citizens' privacy rights. Therefore, in order to judge whether a specific image is utilized as a member of a model's training set, Membership Inference Attack (MIA) is proposed to serve as a tool for privacy protection. Current MIA methods predominantly utilize pixel-wise comparisons as distinguishing clues, considering the pixel-level memorization characteristic of diffusion models. However, it is practically impossible for text-to-image models to memorize all the pixel-level information in massive training sets. Therefore, we move to the more advanced structure-level memorization. Observations on the diffusion process show that the structures of members are better preserved compared to those of nonmembers, indicating that diffusion models possess the capability to remember the structures of member images from training sets. Drawing on these insights, we propose a simple yet effective MIA method tailored for text-to-image diffusion models. Extensive experimental results validate the efficacy of our approach. Compared to current pixel-level baselines, our approach not only achieves state-of-the-art performance but also demonstrates remarkable robustness against various distortions.
Model Will Tell: Training Membership Inference for Diffusion Models
Mar 13, 2024



Diffusion models pose risks of privacy breaches and copyright disputes, primarily stemming from the potential utilization of unauthorized data during the training phase. The Training Membership Inference (TMI) task aims to determine whether a specific sample has been used in the training process of a target model, representing a critical tool for privacy violation verification. However, the increased stochasticity inherent in diffusion renders traditional shadow-model-based or metric-based methods ineffective when applied to diffusion models. Moreover, existing methods only yield binary classification labels which lack necessary comprehensibility in practical applications. In this paper, we explore a novel perspective for the TMI task by leveraging the intrinsic generative priors within the diffusion model. Compared with unseen samples, training samples exhibit stronger generative priors within the diffusion model, enabling the successful reconstruction of substantially degraded training images. Consequently, we propose the Degrade Restore Compare (DRC) framework. In this framework, an image undergoes sequential degradation and restoration, and its membership is determined by comparing it with the restored counterpart. Experimental results verify that our approach not only significantly outperforms existing methods in terms of accuracy but also provides comprehensible decision criteria, offering evidence for potential privacy violations.
A Data-Driven Gaussian Process Filter for Electrocardiogram Denoising
Jan 06, 2023



Objective: Gaussian Processes (GP)-based filters, which have been effectively used for various applications including electrocardiogram (ECG) filtering can be computationally demanding and the choice of their hyperparameters is typically ad hoc. Methods: We develop a data-driven GP filter to address both issues, using the notion of the ECG phase domain -- a time-warped representation of the ECG beats onto a fixed number of samples and aligned R-peaks, which is assumed to follow a Gaussian distribution. Under this assumption, the computation of the sample mean and covariance matrix is simplified, enabling an efficient implementation of the GP filter in a data-driven manner, with no ad hoc hyperparameters. The proposed filter is evaluated and compared with a state-of-the-art wavelet-based filter, on the PhysioNet QT Database. The performance is evaluated by measuring the signal-to-noise ratio (SNR) improvement of the filter at SNR levels ranging from -5 to 30dB, in 5dB steps, using additive noise. For a clinical evaluation, the error between the estimated QT-intervals of the original and filtered signals is measured and compared with the benchmark filter. Results: It is shown that the proposed GP filter outperforms the benchmark filter for all the tested noise levels. It also outperforms the state-of-the-art filter in terms of QT-interval estimation error bias and variance. Conclusion: The proposed GP filter is a versatile technique for preprocessing the ECG in clinical and research applications, is applicable to ECG of arbitrary lengths and sampling frequencies, and provides confidence intervals for its performance.
Bayesian Nested Neural Networks for Uncertainty Calibration and Adaptive Compression
Jan 27, 2021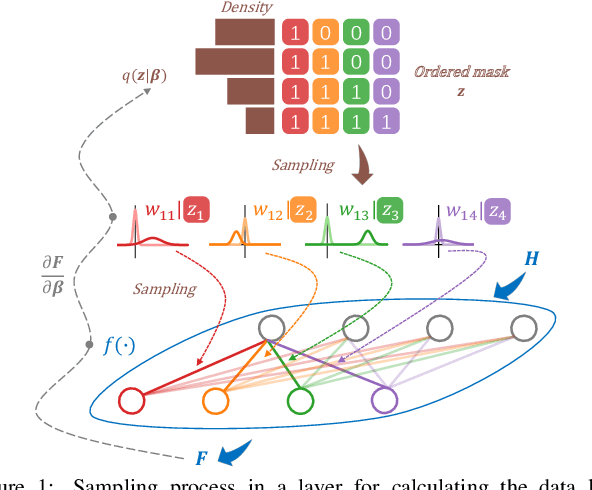
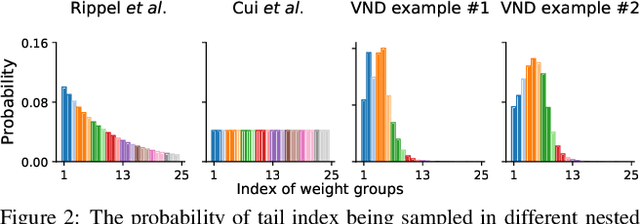
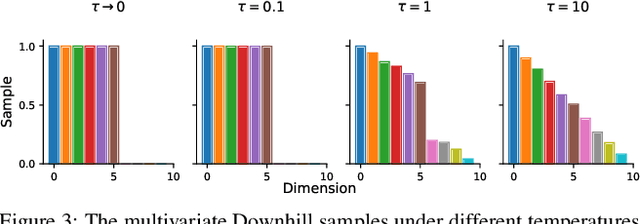
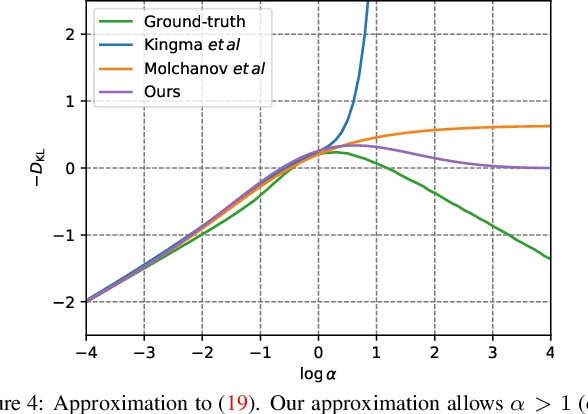
Nested networks or slimmable networks are neural networks whose architectures can be adjusted instantly during testing time, e.g., based on computational constraints. Recent studies have focused on a "nested dropout" layer, which is able to order the nodes of a layer by importance during training, thus generating a nested set of sub-networks that are optimal for different configurations of resources. However, the dropout rate is fixed as a hyper-parameter over different layers during the whole training process. Therefore, when nodes are removed, the performance decays in a human-specified trajectory rather than in a trajectory learned from data. Another drawback is the generated sub-networks are deterministic networks without well-calibrated uncertainty. To address these two problems, we develop a Bayesian approach to nested neural networks. We propose a variational ordering unit that draws samples for nested dropout at a low cost, from a proposed Downhill distribution, which provides useful gradients to the parameters of nested dropout. Based on this approach, we design a Bayesian nested neural network that learns the order knowledge of the node distributions. In experiments, we show that the proposed approach outperforms the nested network in terms of accuracy, calibration, and out-of-domain detection in classification tasks. It also outperforms the related approach on uncertainty-critical tasks in computer vision.
Using Convolutional Variational Autoencoders to Predict Post-Trauma Health Outcomes from Actigraphy Data
Nov 20, 2020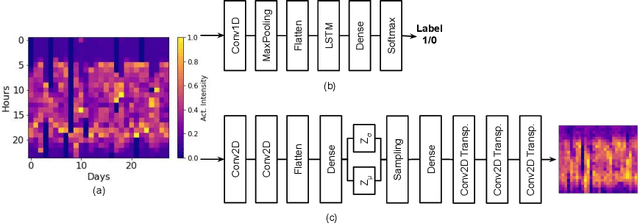
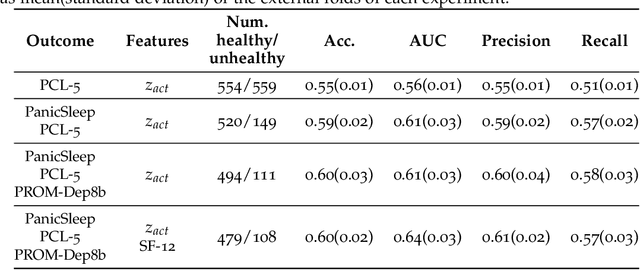
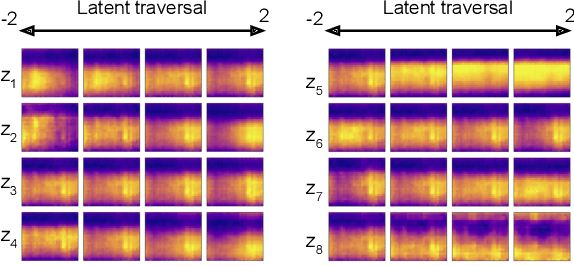
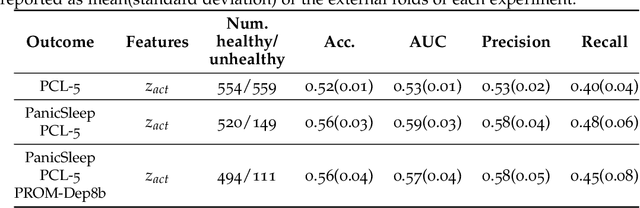
Depression and post-traumatic stress disorder (PTSD) are psychiatric conditions commonly associated with experiencing a traumatic event. Estimating mental health status through non-invasive techniques such as activity-based algorithms can help to identify successful early interventions. In this work, we used locomotor activity captured from 1113 individuals who wore a research grade smartwatch post-trauma. A convolutional variational autoencoder (VAE) architecture was used for unsupervised feature extraction from four weeks of actigraphy data. By using VAE latent variables and the participant's pre-trauma physical health status as features, a logistic regression classifier achieved an area under the receiver operating characteristic curve (AUC) of 0.64 to estimate mental health outcomes. The results indicate that the VAE model is a promising approach for actigraphy data analysis for mental health outcomes in long-term studies.
Fast Scenario Reduction for Power Systems by Deep Learning
Aug 30, 2019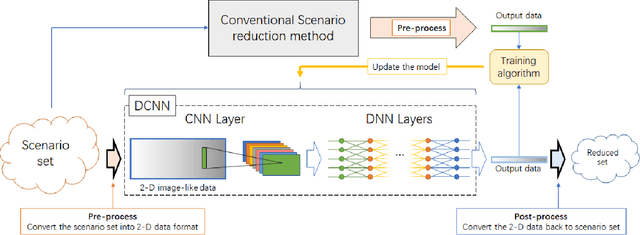

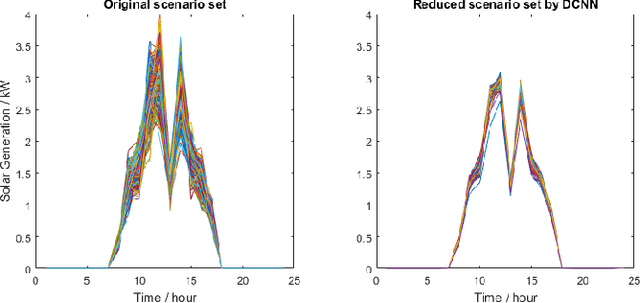
Scenario reduction is an important topic in stochastic programming problems. Due to the random behavior of load and renewable energy, stochastic programming becomes a useful technique to optimize power systems. Thus, scenario reduction gets more attentions in recent years. Many scenario reduction methods have been proposed to reduce the scenario set in a fast speed. However, the speed of scenario reduction is still very slow, in which it takes at least several seconds to several minutes to finish the reduction. This limitation of speed prevents stochastic programming to be implemented in real-time optimal control problems. In this paper, a fast scenario reduction method based on deep learning is proposed to solve this problem. Inspired by the deep learning based image process, recognition and generation methods, the scenario data are transformed into a 2D image-like data and then to be fed into a deep convolutional neural network (DCNN). The output of the DCNN will be an "image" of the reduced scenario set. Since images can be processed in a very high speed by neural networks, the scenario reduction by neural network can also be very fast. The results of the simulation show that the scenario reduction with the proposed DCNN method can be completed in very high speed.