 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLMD3: Language Model Data Density Dependence
May 10, 2024



We develop a methodology for analyzing language model task performance at the individual example level based on training data density estimation. Experiments with paraphrasing as a controlled intervention on finetuning data demonstrate that increasing the support in the training distribution for specific test queries results in a measurable increase in density, which is also a significant predictor of the performance increase caused by the intervention. Experiments with pretraining data demonstrate that we can explain a significant fraction of the variance in model perplexity via density measurements. We conclude that our framework can provide statistical evidence of the dependence of a target model's predictions on subsets of its training data, and can more generally be used to characterize the support (or lack thereof) in the training data for a given test task.
FLawN-T5: An Empirical Examination of Effective Instruction-Tuning Data Mixtures for Legal Reasoning
Apr 02, 2024Instruction tuning is an important step in making language models useful for direct user interaction. However, many legal tasks remain out of reach for most open LLMs and there do not yet exist any large scale instruction datasets for the domain. This critically limits research in this application area. In this work, we curate LawInstruct, a large legal instruction dataset, covering 17 jurisdictions, 24 languages and a total of 12M examples. We present evidence that domain-specific pretraining and instruction tuning improve performance on LegalBench, including improving Flan-T5 XL by 8 points or 16\% over the baseline. However, the effect does not generalize across all tasks, training regimes, model sizes, and other factors. LawInstruct is a resource for accelerating the development of models with stronger information processing and decision making capabilities in the legal domain.
Translation between Molecules and Natural Language
Apr 26, 2022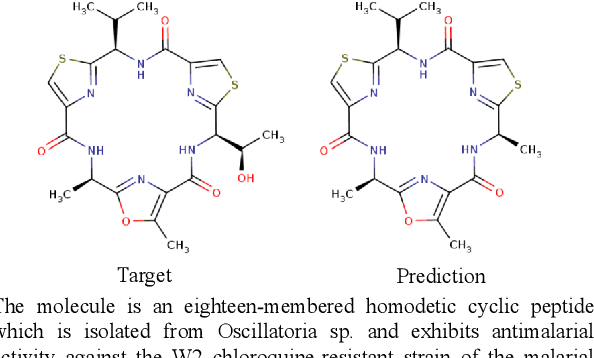
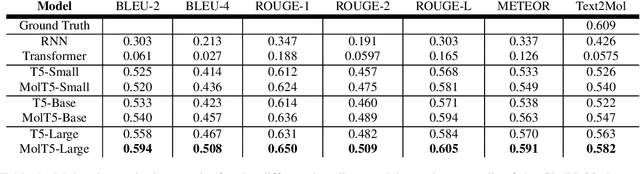
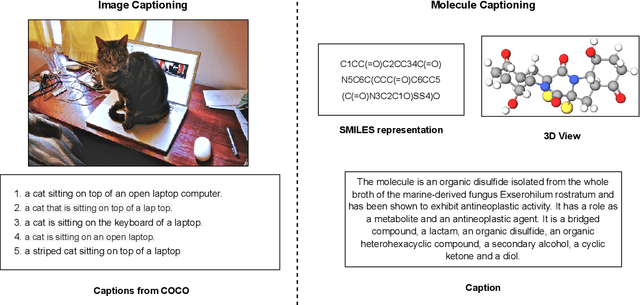
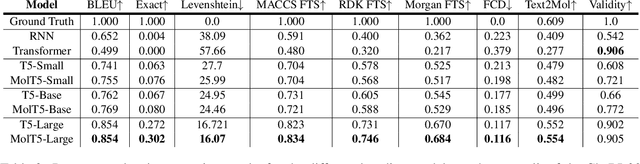
Joint representations between images and text have been deeply investigated in the literature. In computer vision, the benefits of incorporating natural language have become clear for enabling semantic-level control of images. In this work, we present $\textbf{MolT5}-$a self-supervised learning framework for pretraining models on a vast amount of unlabeled natural language text and molecule strings. $\textbf{MolT5}$ allows for new, useful, and challenging analogs of traditional vision-language tasks, such as molecule captioning and text-based de novo molecule generation (altogether: translation between molecules and language), which we explore for the first time. Furthermore, since $\textbf{MolT5}$ pretrains models on single-modal data, it helps overcome the chemistry domain shortcoming of data scarcity. Additionally, we consider several metrics, including a new cross-modal embedding-based metric, to evaluate the tasks of molecule captioning and text-based molecule generation. By interfacing molecules with natural language, we enable a higher semantic level of control over molecule discovery and understanding--a critical task for scientific domains such as drug discovery and material design. Our results show that $\textbf{MolT5}$-based models are able to generate outputs, both molecule and text, which in many cases are high quality and match the input modality. On molecule generation, our best model achieves 30% exact matching test accuracy (i.e., it generates the correct structure for about one-third of the captions in our held-out test set).
Using Convolutional Variational Autoencoders to Predict Post-Trauma Health Outcomes from Actigraphy Data
Nov 20, 2020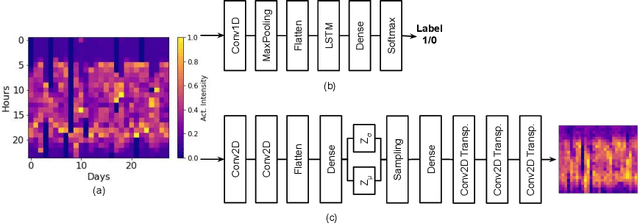
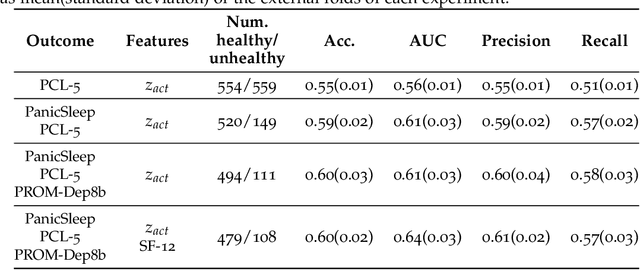
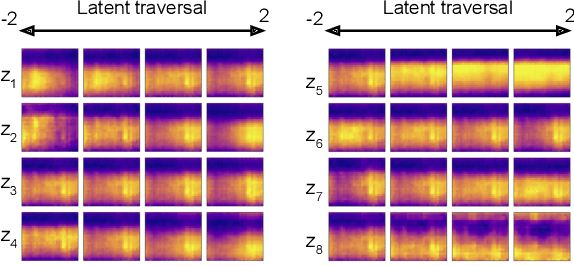
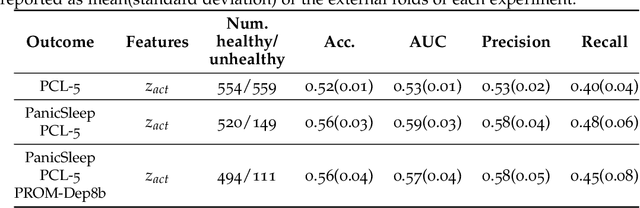
Depression and post-traumatic stress disorder (PTSD) are psychiatric conditions commonly associated with experiencing a traumatic event. Estimating mental health status through non-invasive techniques such as activity-based algorithms can help to identify successful early interventions. In this work, we used locomotor activity captured from 1113 individuals who wore a research grade smartwatch post-trauma. A convolutional variational autoencoder (VAE) architecture was used for unsupervised feature extraction from four weeks of actigraphy data. By using VAE latent variables and the participant's pre-trauma physical health status as features, a logistic regression classifier achieved an area under the receiver operating characteristic curve (AUC) of 0.64 to estimate mental health outcomes. The results indicate that the VAE model is a promising approach for actigraphy data analysis for mental health outcomes in long-term studies.
Representation learning for improved interpretability and classification accuracy of clinical factors from EEG
Oct 30, 2020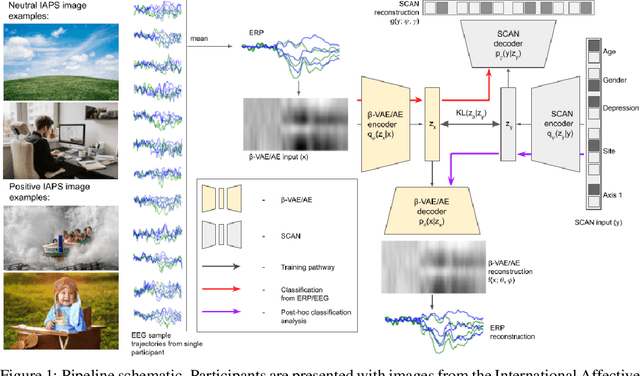
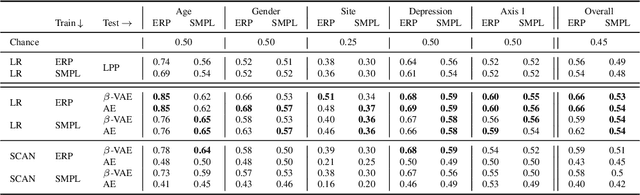
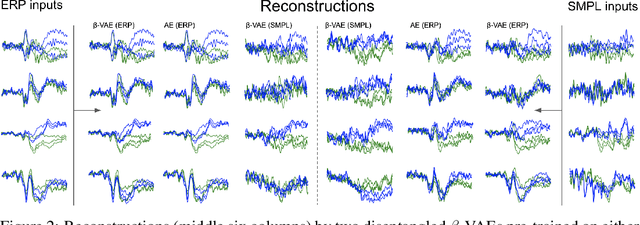

Despite extensive standardization, diagnostic interviews for mental health disorders encompass substantial subjective judgment. Previous studies have demonstrated that EEG-based neural measures can function as reliable objective correlates of depression, or even predictors of depression and its course. However, their clinical utility has not been fully realized because of 1) the lack of automated ways to deal with the inherent noise associated with EEG data at scale, and 2) the lack of knowledge of which aspects of the EEG signal may be markers of a clinical disorder. Here we adapt an unsupervised pipeline from the recent deep representation learning literature to address these problems by 1) learning a disentangled representation using $\beta$-VAE to denoise the signal, and 2) extracting interpretable features associated with a sparse set of clinical labels using a Symbol-Concept Association Network (SCAN). We demonstrate that our method is able to outperform the canonical hand-engineered baseline classification method on a number of factors, including participant age and depression diagnosis. Furthermore, our method recovers a representation that can be used to automatically extract denoised Event Related Potentials (ERPs) from novel, single EEG trajectories, and supports fast supervised re-mapping to various clinical labels, allowing clinicians to re-use a single EEG representation regardless of updates to the standardized diagnostic system. Finally, single factors of the learned disentangled representations often correspond to meaningful markers of clinical factors, as automatically detected by SCAN, allowing for human interpretability and post-hoc expert analysis of the recommendations made by the model.
Using Deep Networks and Transfer Learning to Address Disinformation
May 24, 2019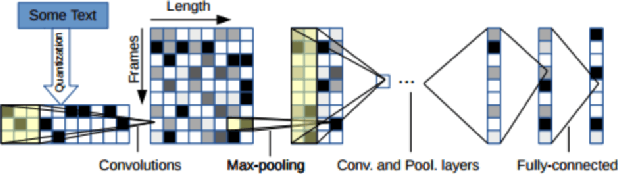
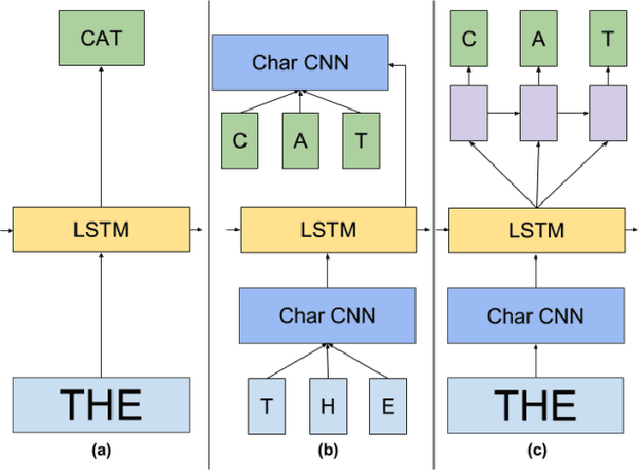
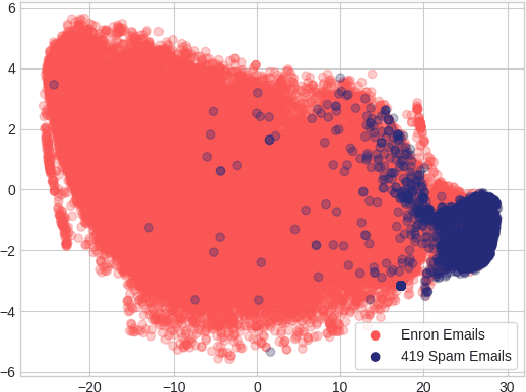
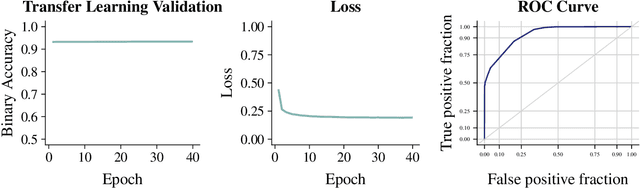
We apply an ensemble pipeline composed of a character-level convolutional neural network (CNN) and a long short-term memory (LSTM) as a general tool for addressing a range of disinformation problems. We also demonstrate the ability to use this architecture to transfer knowledge from labeled data in one domain to related (supervised and unsupervised) tasks. Character-level neural networks and transfer learning are particularly valuable tools in the disinformation space because of the messy nature of social media, lack of labeled data, and the multi-channel tactics of influence campaigns. We demonstrate their effectiveness in several tasks relevant for detecting disinformation: spam emails, review bombing, political sentiment, and conversation clustering.
Semantic Classification of Tabular Datasets via Character-Level Convolutional Neural Networks
Jan 24, 2019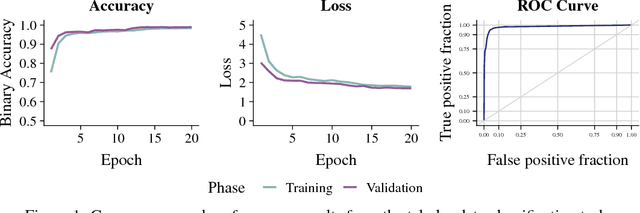
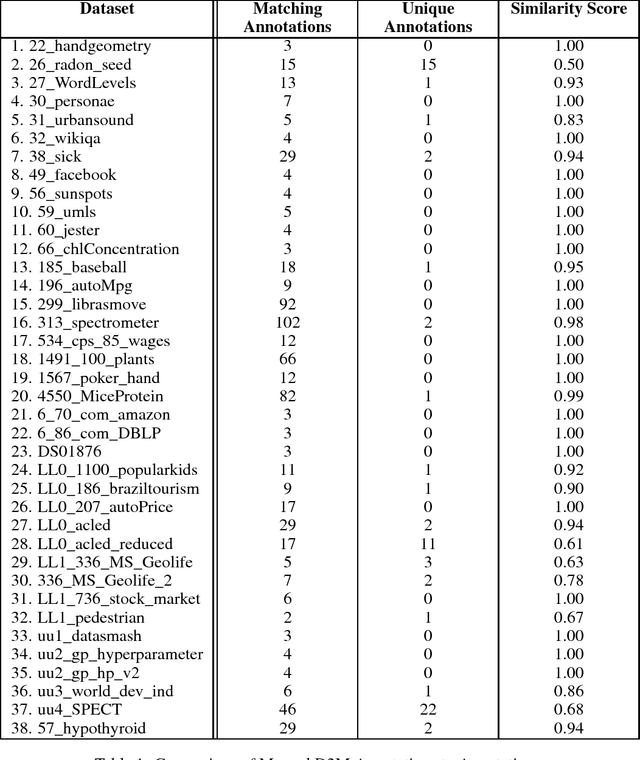
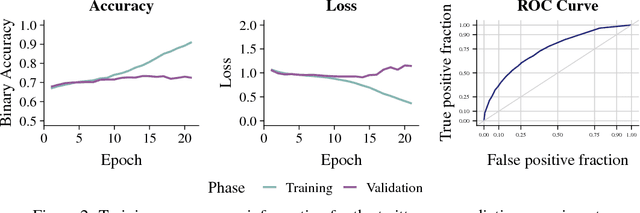
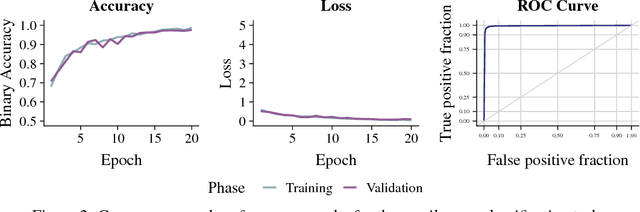
A character-level convolutional neural network (CNN) motivated by applications in "automated machine learning" (AutoML) is proposed to semantically classify columns in tabular data. Simulated data containing a set of base classes is first used to learn an initial set of weights. Hand-labeled data from the CKAN repository is then used in a transfer-learning paradigm to adapt the initial weights to a more sophisticated representation of the problem (e.g., including more classes). In doing so, realistic data imperfections are learned and the set of classes handled can be expanded from the base set with reduced labeled data and computing power requirements. Results show the effectiveness and flexibility of this approach in three diverse domains: semantic classification of tabular data, age prediction from social media posts, and email spam classification. In addition to providing further evidence of the effectiveness of transfer learning in natural language processing (NLP), our experiments suggest that analyzing the semantic structure of language at the character level without additional metadata---i.e., network structure, headers, etc.---can produce competitive accuracy for type classification, spam classification, and social media age prediction. We present our open-source toolkit SIMON, an acronym for Semantic Inference for the Modeling of ONtologies, which implements this approach in a user-friendly and scalable/parallelizable fashion.
Abstractive Tabular Dataset Summarization via Knowledge Base Semantic Embeddings
Apr 05, 2018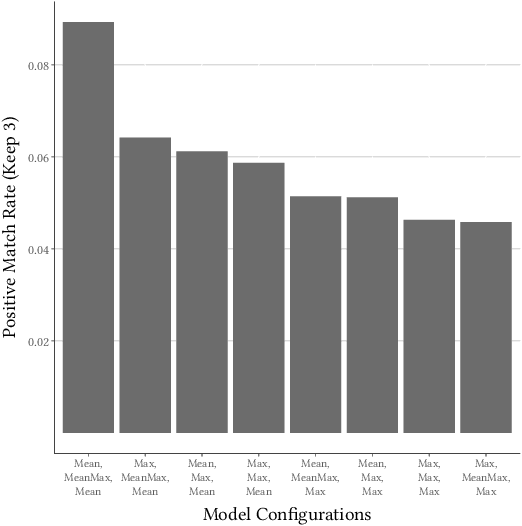
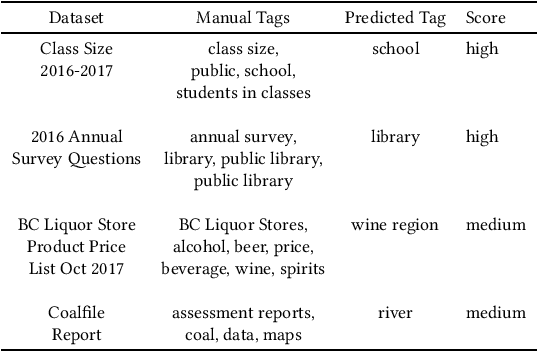
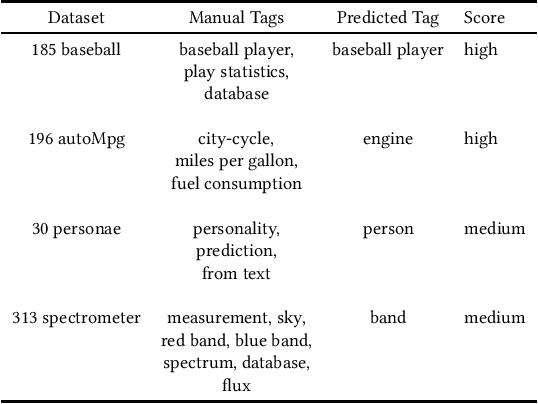
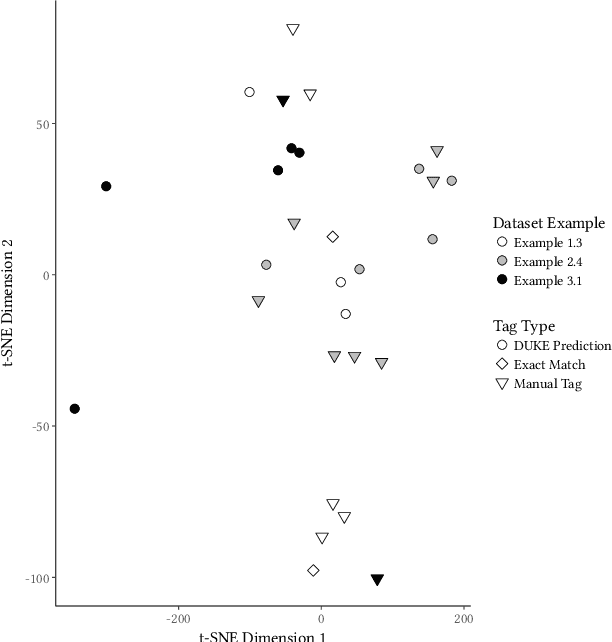
This paper describes an abstractive summarization method for tabular data which employs a knowledge base semantic embedding to generate the summary. Assuming the dataset contains descriptive text in headers, columns and/or some augmenting metadata, the system employs the embedding to recommend a subject/type for each text segment. Recommendations are aggregated into a small collection of super types considered to be descriptive of the dataset by exploiting the hierarchy of types in a pre-specified ontology. Using February 2015 Wikipedia as the knowledge base, and a corresponding DBpedia ontology as types, we present experimental results on open data taken from several sources--OpenML, CKAN and data.world--to illustrate the effectiveness of the approach.